一种SVM风电功率预测方法与流程
本发明属于风电
技术领域:
,特别涉及一种SVM风电功率预测方法。
背景技术:
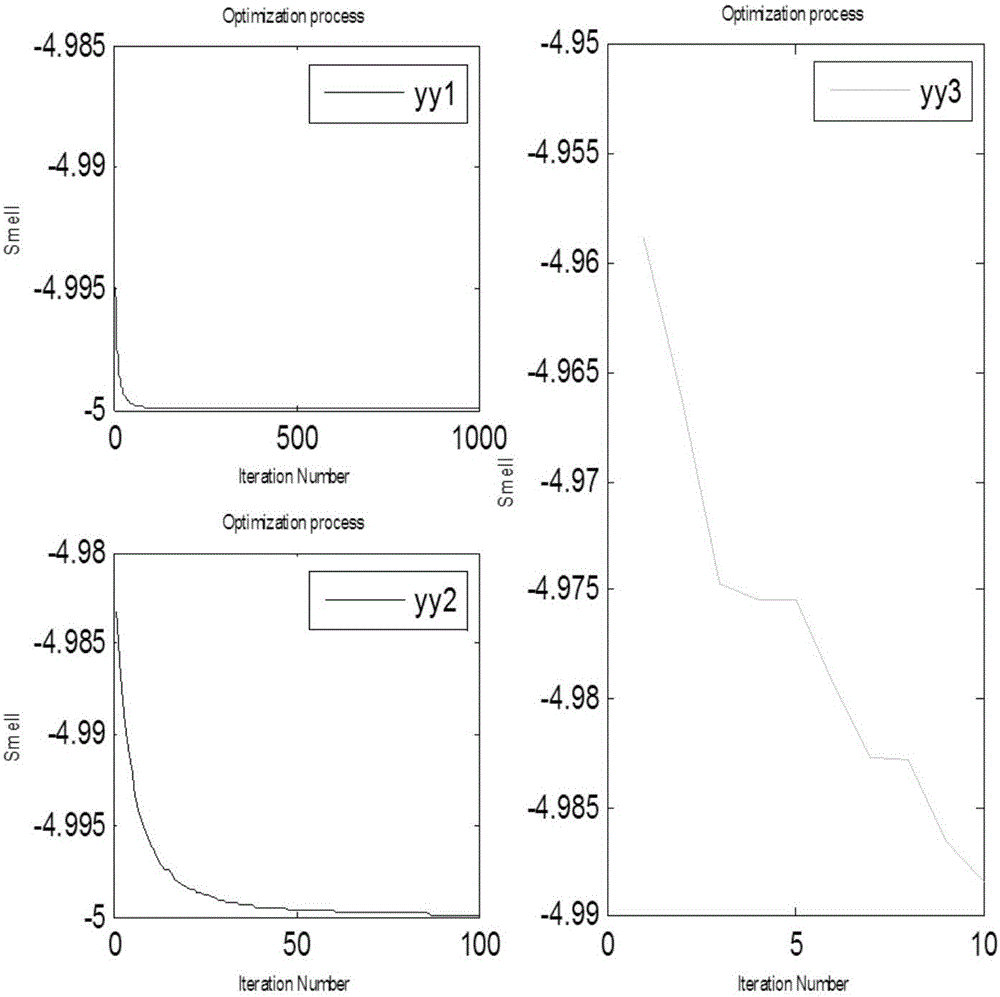
:现有技术中,有很多模型可用于风电功率预测之中。比如时间序列分析是采用模型对所观测到的有序的随机数据进行分析和处理的一种数据处理方法。BP神经网络虽然有很好的鲁棒性、泛化能力、容错能力。然而,时间序列分析对于模型阶数的不同会有很大差异。BP神经网络学习收敛速度慢,易陷入局部极小而得不到全局最优值等等。本发明涉及的参考文献包括:[1]冬雷,廖晓钟,王丽婕.大型风电场发电功率建模与预测[M].北京:科学出版社,2014:39[2]史洁.基于支持向量机的风电场功率短期预测方法研究[D].河北:华北电力大学,2009[3]Chi-HungWu,Gwo-HshiungTzeng.ANovelhybridgeneticalgorithmforkernelfunctionandparameteroptimizationinsupportvectorregression[J].ExpertSystemswithApplications,2009,(36):4725-4735.[4]张倩,杨耀权.基于支持向量机核函数的研究[J].电力科学与工程,2012,28(05):42-45.[5]潘文超.果蝇最佳化演算法[M].台湾:沧海书局,2011,12技术实现要素:本发明目的是提供一种SVM风电功率预测方法,提高风电功率预测精度。一种SVM风电功率预测方法,基于SVM,即支持向量机,采用基于改进果蝇算法的SVM模型(MFOA-SVM)对风电功率进行预测,其中包括以下步骤:第一步:确定所需要的适应度函数;第二步:初始化果蝇算法中种群大小和迭代次数,选择好SVM相关参数;第三步:建立SVM训练模型并进行预测,计算适应度函数(预测结果与实际值的均方根误差),得到每一代群组规模中最佳的参数值,并记录下来;第四步:更新果蝇群体位置,重复第二步直到达到最大迭代次数,输出最优值。建立SVM训练模型还包括步骤如下:1)对采集到的数据进行剔除、变换、补充;2)对数据进行分类,并进行归一化处理;3)初始化种群规模与迭代次数,训练SVM模型,确定最优参数c,g;4)将我们处理好的数据代入SVM模型进行预测;5)根据我们所需要的适应度函数来计算适应度值,每一代记录下最佳值,通过每一次迭代的比较,得出最优值,输出预测精度。本发明提出了一种改进的果蝇算法优化的支持向量机的预测方法。由于支持向量机的惩罚因子和核函数参数选择对预测精度有很大影响,因而利用改进的果蝇算法对支持向量机参数进行优化,用优化好的参数进行建模训练,然后把建好的模型应用于功率预测,最后对数据进行评估。附图说明图1现有技术中果蝇搜索食物示意图。图2本发明实施例中迭代步进值2*rand()-1时的优化结果。图3本发明实施例中迭代步进值20*rand()-10时的优化结果。图4本发明涉及的MFOA-SVM模型图。图5本发明的MFOA优化流程图。图6本发明实施例测试样本在MFOA-SVM优化前后数据的比较。图7本发明实施例测试目标MFOA-SVM优化前后数据的比较。图8本发明实施例测试目标预测后的平均相对误差。具体实施方式目前支持向量机[1]在风电功率预测中的应用越来越广泛,不过仍然有很多问题需要去改进。在文献[2]中结合风电机组功率特性曲线,基于支持向量机建立了分段混合预测模型,使平均预测精度提高了4.76%。由于模型建立过程中,训练数据对预测效果有着很大的影响,对此本发明对支持向量机的改进进行了研究。影响支持向量机模型的主要因素是惩罚系数c和核函数参数g。支持向量机中最优化问题为其中,||w||2称为结构风险,为经验风险,c为惩罚参数,ξi,为松弛变量,ε为估计精度,Φ(xi)将数据xi映射到高维特征空间,b是常值偏差。在支持向量机建模过程中,选择适当的核函数巧妙地解决了高维特征空间引起的维数灾难问题。在文献[3]和文献[4]中通过实验详细分析了核函数对于支持向量机的影响,选择正确的核函数能够降低训练误差。目前研究最多的核函数主要有三类:一是多项式核函数,二是RBF核函数,三是sigmoid函数,RBF核函数是一个适用广泛的核函数,与其他核函数相比,有以下几个优点:(1)RBF的参数较少,降低了模型的复杂程度。(2)RBF直接反映了两个数据的距离。(3)RBF更易于数值计算,不存在无穷大点和奇异点的问题。遂本发明采用RBF函数k(x,xi)=exp(-||x-xi||2/2σ2)(2)x,xi为数据点,σ为核参数。作为核函数,实验表明,预测效果较好。以下是关于改进的果蝇算法及其性能分析。基本的果蝇优化算法果蝇优化算法[5](FruitFlyOptimizationAlgorithm,FOA)是台湾的潘文超于2011年提出的一种基于果蝇觅食行为推演出寻求全局优化的新方法。其寻优步骤:(1)首先随机初始果蝇群体位置。InitX_axisInitY_axis//X,Y表示图1中的位置坐标(x,y)(2)给出果蝇个体利用嗅觉搜寻食物的方向与距离Xi=X_axis+RandomValue//向随机的方向和距离寻找到后目标的X坐标Yi=Y_axis+RandomValue//向随机的方向和距离寻找到后目标的Y坐标(3)由于无法得知食物位置,因此先估计与原点的距离(D),再计算味道浓度判定值(Si)。Di=(xi2+yi2);---(3)]]>Si=1/Di(4)(4)味道浓度判定值(s)代入味道浓度判定函数(或称为Fitnessfunction)求出该果蝇个体位置的味道浓度(Smelli).Smelli=Function(Si)(5)找出此果蝇群体的中味道浓度最高的果蝇[bestSmellbestIndex]=max(Smell)(6)保留最佳味道浓度值与x、y坐标,此时果蝇群体利用视觉往该位置飞去。Smellbest=bestSmell;X_axis=X(bestIndex);Y_axis=Y(bestIndex)(7)进入迭代寻优,重复执行步骤2-5,并判断味道浓度是否优于前一迭代味道浓度,若是则执行步骤(6),直到找到最佳味道浓度值。改进的果蝇算法对于果蝇算法的参数问题和早熟问题,提高果蝇算法的寻优能力,下面从改变种群大小、初始位置设定、迭代步进值来提高果蝇算法的搜寻能力。种群大小关系着FOA搜寻能力的高低,越多果蝇去寻找食物,就会越快发现食物的踪迹。选择适量的果蝇数目并设定果蝇合适的初始位置来提高解决问题的效率。同时选取不同的步长值影响果蝇算法的搜寻能力。程序如下:X_axis=50*rand();Y_axis=50*rand();%果蝇初始位置设定为50乘以1随机数值时搜寻极大值maxgen=10;%迭代次数Sizepop=20;%种群规模大小,不同的种群大小会有不同的结果Fori=1:sizepopX(i)=X_axis+20*rand()-10;%果蝇补偿值设定为20乘以随机数值再减10求极大值Y(i)=Y_axis+20*rand()-10;D(i)=(X(i)2+Y(i)2)1/2;S(i)=1/D(i);Smell(i)=fitness;End现在利用求解函数y=-5+x^2极小值来加以分析。种群数量分别为3只,10只,20只果蝇来搜寻,迭代次数分别10次,100次,1000次,迭代步进值设定为2*rand()-1和20*rand()-10。从图2和3中可以看出,不同的种群数量,迭代次数以及迭代步进值的不同对函数的收敛的程度是不一样的。yy1,yy2,yy3分别表示迭代次数1000次,100次,10次得到的函数极小值。横坐标代表迭代次数,纵坐标代表优化的最优值。改进果蝇算法的收敛性分析在实际计算中,果蝇的距离D是在很大的一个范围内随机取值,相应味道浓度判定值Si可能出现在很小的范围之内,从而FOA容易陷入局部极值,无法寻找全局极值。所以我们在改进的算法上在计算味道浓度判定值时加入一个跳脱参数Δ(即跳脱局部极值),通过此参数,式(4)为Sm=Si+Δ;Δ=Di×(0.5-δ);0≤δ≤1---(5)]]>这样一来,味道判定值Sm扩大了分布范围,当距离值D很大时,避免了Sm陷入极小值。此改进也称为修正型果蝇优化算法(MFOA)。证明:假设H={h(1),h(2),h(3),….h(t),h(t+1)}表示从第一代到底t+1代每代的最优值,则满足h(1)≤h(2)≤....≤h(t)≤h(t+1)(6)(1)当果蝇在有限的范围内寻找食物,由定理单调不升且有下界的数列必有极限,可以得出最优解一定收敛。(2)当果蝇的距离D是在很大的一个范围内随机取值时,加入参数Δ后,Sm=Si+Δ就不会陷入局部极值,最优解也将收敛于Δ。以下是关于基于改进果蝇算法的SVM模型(MFOA-SVM)模型建立首先对数据进行处理收集,选好样本集和测试集,采用果蝇算法对参数c,g进行优化,然后建立预测模型进行实验,统计分析预测误差。利用MFOA(修正型果蝇优化算法)选择最佳参数c,g本发明中的适应度函数是SVM对数据进行预测后的均方根误差,使目标最小化,适应度值越小,误差越小,SVM回归预测也就越好。具体操作步骤如下:第一步:确定所需要的适应度函数。第二步:初始化果蝇算法中种群大小和迭代次数,选择好SVM相关参数第三步:建立SVM训练模型并进行预测,计算适应度函数(预测结果与实际值的均方根误差),得到每一代群组规模中最佳的参数值,并记录下来第四步:更新果蝇群体位置,重复第二步直到达到最大迭代次数,输出最优值。具体流程如图5。关于MFOA-SVM在风电功率预测中的应用风电功率预测在整个风电场中扮演着不可或缺的角色,预测精度的准确性将直接对电网的供需平衡产生影响,对风资源能不能得到有效的利用有着决定性的影响。因此提高功率预测精度对整个风电场来说非常重要。鉴于功率预测的紧迫性以及支持向量机在样本回归中的优势,本文根据风电场的测试数据,基于支持向量机的功率预测模型进行预测,并使用果蝇算法对参数进行优化来提高预测精度。数据处理本发明实施例用某风电场拥有的GW82-1500km风机作为研究对象,利用平台MATLAB2009,运用支持向量机工具箱toolboxLibsvm-mat完成对数据样本的训练以及预测。数据采用该风电场10号风电机组十月运行的实测数据为例构建样本集,把该风电机组的功率值分为训练样本、训练目标、测试样本以及测试目标。把一个月的前20天的数据作为训练样本,后10天的数据作为测试样本,截取10月2日一天的720组数据进行实验。所选取的数据位于风机运行良好阶段,但仍会有故障机出现,对于一些风机较长时间停机而导致数据较多缺失的时刻,直接去掉,对于很少缺失数据或者没有缺少数据,只是变化很大的数据采用如下方法解决:如果则P(d,t)=[P(d,t-1)+P(d,t+1)]/2(8)其中P(d,t)表示第d天t时刻的功率值,P(d,t-1)表示第d天t-1时刻的值,P(d,t+1)表示第d天t+1时刻的值,表示阀值。表1部分训练样本表2部分训练目标TimePt(KM)Pt+1(KM)Pt+2(KM)Pt+3(KM)Pt+4(KM)4:00156.692682825.7842760767.37645933154.8993494389.04968015:0025.7842760767.37645933154.8993494389.0496801765.57501066:0067.37645933154.8993494389.0496801765.5750106892.1947317:00154.8993494389.0496801765.5750106892.194731950.68102438:00389.0496801765.5750106892.194731950.6810243999.20829699:00765.5750106892.194731950.6810243999.20829691163.49851610:00892.194731950.6810243999.20829691163.4985161158.94690811:00950.6810243999.20829691163.4985161158.9469081033.0620312:00999.20829691163.4985161158.9469081033.062031029.21581313:001163.4985161158.9469081033.062031029.215813563.741759414:001158.9469081033.062031029.215813563.7417594733.142107215:001033.062031029.215813563.7417594733.14210721104.43105416:001029.215813563.7417594733.14210721104.4310541455.43453417:00563.7417594733.14210721104.4310541455.4345341405.72085318:00733.14210721104.4310541455.4345341405.7208531421.18662表3部分测试样本TimePt(KW)Pt+1(KW)Pt+2(KW)Pt+3(KW)Pt+4(KW)0:00156.692682825.7842760767.37645933154.8993494389.04968011:00765.5750106892.194731950.6810243999.20829691163.4985162:001158.9469081033.062031029.215813563.7417594733.14210723:001104.4310541455.4345341405.7208531421.186621120.5280414:001050.0171511260.9482741297.9263941152.8928551393.26645:001164.5646651036.9267331352.435793803.862577800.43759146:001053.8179581288.9762311331.2321681477.4214621517.7278097:001512.9056211161.185766594.5951408886.67408281182.6274888:001230.5082921017.2302121413.5316381376.27854601.56493549:0013.6397841635.8952421990.80847403126.3859145114.418433710:00560.9812889235.74948681.6827965158.63971557194.51664111:0078.8821457577.2857308613.5223068860.96592242138.226796512:0086.3857713972.04039421252.1552083566.2647721548.501331213:00757.1951119754.8292096786.1590637386.0350354441.747154714:00722.0044186753.70796731425.0616541402.2247451467.582426表4部分测试目标TimePt(KW)Pt+1(KW)Pt+2(KW)Pt+3(KW)Pt+4(KW)5:001050.0171511260.9482741297.9263941152.8928551393.26646:001164.5646651036.9267331352.435793803.862577800.43759147:001053.8179581288.9762311331.2321681477.4214621517.7278098:001512.9056211161.185766594.5951408886.67408281182.6274889:001230.5082921017.2302121413.5316381376.27854601.5649354表1功率数据是部分训练样本,表2功率数据为部分训练目标,表3功率数据为部分测试样本,表4功率数据是部分测试目标。每一列数据比前一列数据晚1个时刻。本发明实施例中的实验设计根据模型图4进行模型建立并预测,参数选择按照流程图5进行选取,选择RBF核函数,其模型训练步骤具体如下:1)对采集到的数据进行剔除、变换、补充2)对数据进行分类,并进行归一化处理3)初始化种群规模与迭代次数,训练SVM模型,确定最优参数c,g4)将处理好的数据代入SVM模型进行预测5)根据所需要的适应度函数来计算适应度值,每一代记录下最佳值通过每一次迭代的比较,得出最优值,输出预测精度。实验结果及分析利用提供的数据将其分为训练样本和测试样本,并对数据进行归一化处理,通过MFOA-SVM模型进行训练,得到核函数参数:bestg=0.1687,bestc=3.3740,利用所得到的参数进行测试并反归一化处理,输出数据如图6,图7。从图6、图7可以看到经过改进后的MFOA-SVM优化过后预测效果显著,并通过修改种群数量,迭代次数和迭代步进值,不断实验,最终可以达到误差平均相对误差在0.1429,相对于没有采用MFOA优化时的误差0.1948明显提高了,而且其相关性从0.68提升到了0.84。从而预测精度得以提高。通过实验分析功率预测仿真的结果,采用改进的果蝇算法对SVM的参数进行寻优,建立了MFOA-SVM的预测模型,提高了预测精度,仿真结果表明果蝇算法作为一种比较新的优化算法应用在风电功率预测中也表现了很好的一面。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1