一种分布式存储系统NoSQL搜索缓存的优化方法和系统与流程
本发明属于计算机技术领域,尤其是涉及一种分布式存储系统NoSQL搜索缓存的优化方法和系统。
背景技术:
单个分布式存储系统已无法满足现在大规模海量数据的存储、管理和搜索的需求。目前分布式存储系统和多数据中心存储是满足EB级数据存储需求的关键的技术途径。如何从大规模的数据集中快速地搜索满足用户要求的数据是当前跨数据中心存储系统亟待解决的问题,特别是SSD等新型存储介质的出现以其优良的性能对分布式存储系统的搜索带来深远的影响,因此为了提高搜索效率,需要突破基于SSD和负载局部性特征的搜索技术的瓶颈问题。
相对传统机械硬盘,固态硬盘SSD在性能上具有非常大的优势。SSD有极高的性能,非常适合要求较快响应时间和每秒读写次数高的请求。目前SSD在大规模存储系统中应用分为SSD分层存储技术和SSD缓存技术。SSD分层存储技术通过分层存储的方法能够存储系统的高吞吐量和低存取响应时间,但是采用分层技术的方法的困难是如何判定不同的存储数据和文件的价值从而获得良好的吞吐率和低时延,同时分层tier方法需要更多的SSD,也即需要更高的存储成本;SSD缓存技术是根据数据访问的时间局部性和空间局部性采用SSD作为存储系统的缓存技术。
目前常见的以BigTable为代表的NoSQL存储系统,包括HBase、Cassandra等,底层采用LSM树的方式组织数据,数据写入不再更改。但是针对SSD的缓存存储等通用解决方案,并没有针对上层具体的负载特征建立具体的SSD缓存方法,也没有针对上述写一次读多次的NoSQL系统建立数据搜索的缓存方法,尤其是在跨数据中心环境中异地环境条件下对于分布式存储系统NoSQL的数据访问。对应的,导致其数据搜索效率较低,有较大的提供改进空间。
技术实现要素:
有鉴于此,本发明实施例提供一种分布式存储系统NoSQL搜索缓存的优化方法和系统,以解决现有技术没有针对上层具体的负载特征以及分布式存储系统NoSQL写一次读多次的特征的缓存方法导致数据搜索效率较低的技术问题,达到提高数据搜索效率的目的。
本发明提供的技术方案如下:
一种分布式存储系统NoSQL搜索缓存的优化方法,包括:
步骤S101,在HBase客户端中,预先设置本地SSD作为只读缓存;
步骤S102,当HBase客户端读取目标数据时,判断目标数据是否位于所述本地SSD上,如果是,则进入步骤S104;如果否,则进入步骤S103;
步骤S103,从HDFS集群中读取目标数据并缓存到所述本地SSD上;
步骤S104,所述本地SSD返回所述目标数据。
较佳的,所述步骤S102之前,还包括:
HBase客户端将读取请求发送至对应的HRegionServe;
HRegionServer根据接收到的读取请求,判断目标数据是否位于本地内存中,如果是,则从本地内存中返回所述目标数据,如果否,则进入步骤S102。
较佳的,所述步骤S104包括:
所述本地SSD返回所述目标数据到所述本地内存,并且所述本地内存返回所述目标数据。
较佳的,所述步骤S103之前,还包括:
判断所述本地SSD的剩余存储空间是否满足预设要求,如果是,则进入步骤S103;如果否,则执行替换算法,用读取的目标数据替换所述本地SSD中的已有数据。
较佳的,所述方法还包括:
HBase客户端生成Compact操作请求,判断Compact操作请求对应的目标HFile文件是否位于所述本地SSD上,如果是,则执行Compact操作;如果否,则从HDFS集群中读取目标HFile文件缓存到所述本地SSD上并执行Compact操作,Compact操作完成后,将原HFile文件从本地SSD中删除,并将新生成的HFile文件写入HDFS集群以及缓存到本地SSD中。
较佳的,所述方法还包括:
HBase客户端生成Split操作请求,判断Split操作请求对应的目标HFile文件是否位于所述本地SSD上,如果是,则执行Split操作;如果否,则从HDFS集群中读取目标HFile文件缓存到所述本地SSD上并执行Split操作,Split操作完成后,将原HFile文件从本地SSD中删除。
相应于上述方法,本发明还提供了一种分布式存储系统NoSQL搜索缓存的优化系统,包括:
本地SSD,用于作为只读缓存设置在HBase客户端中;
第一判断模块,用于在HBase客户端读取目标数据时,判断目标数据是否位于所述本地SSD上;
数据读取模块,用于在目标数据不位于所述本地SSD上时,从HDFS集群中读取目标数据并缓存到所述本地SSD上;
数据返回模块,用于在目标数据位于所述本地SSD上时,从所述本地SSD返回所述目标数据。
较佳的,所述的系统,还包括:
第二判断模块,用于判断所述本地SSD的剩余存储空间是否满足预设要求;
替换模块,用于在所述本地SSD的剩余存储空间不满足预设要求时,执行替换算法,用读取的目标数据替换所述本地SSD中的已有数据。
较佳的,所述的系统,还包括:
Compact模块,用于当目标HFile文件位于所述本地SSD上时,执行Compact操作,将原HFile文件从本地SSD中删除,并将新生成的HFile文件写入HDFS集群以及缓存到本地SSD中。
较佳的,所述的系统,还包括:
Split模块,用于当目标HFile文件位于所述本地SSD上时,执行Split操作,将原HFile文件从本地SSD中删除。
采用上述技术方案,本发明至少可取得下述技术效果:
本发明提供的技术方案,引入本地SSD提供只读缓存功能,充分发挥SSD的随机读取性能,在SSD中缓存相关文件,因访问的数据具有局部性,通过在SSD缓存的文件可以有效的减少读取HDFS的I/O数目,从而提高分布式存储系统的性能,达到提高数据搜索效率的等目的。
上述技术方案在应用中,针对HBase采用LSM树的方式组织数据以及上层读数据多的负载,把本地SSD作为HBase集群的只读缓存功能,充分利用HBase本身的特点,尤其适用于上层遥感卫星等应用对于数据访问读多写少的负载特征。
附图说明
图1为实施例一提供的分布式存储系统NoSQL搜索缓存的优化方法流程图;
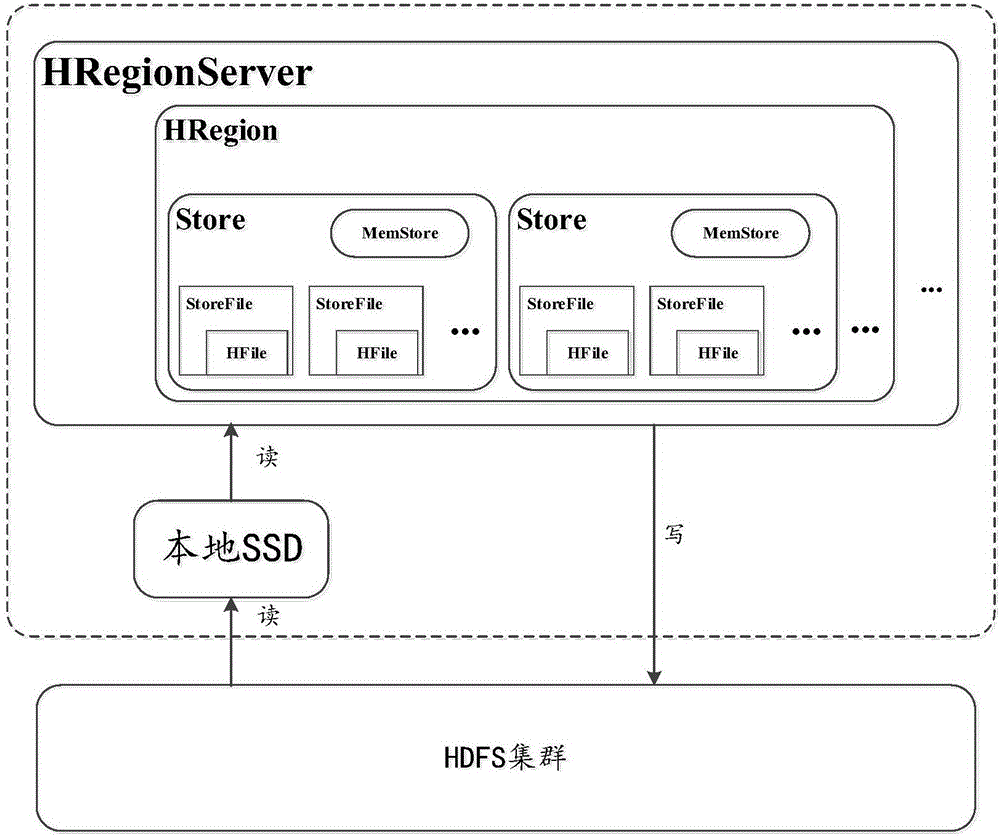
图2为实施例一提供的加入本地SSD后的分布式存储系统后HBase的HRregionServer架构示意图;
图3为实施例二提供的Compact操作方法流程图;
图4为实施例三提供的Split操作方法流程图;
图5为实施例四提供的分布式存储系统NoSQL搜索缓存的优化系统组成图。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面将结合附图对本发明实施例的技术方案作进一步的详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。需要说明的是,本发明以以下实施例为例对本发明的技术方案进行说明,但并非以此作为限制。本领域技术人员能够明了,本发明所提出的钱分布式存储系统NoSQL搜索缓存的优化方法和系统除用于分布式存储系统之外,还可以广泛应用于其他相同或相近领域中,并取得类似的技术效果。
在跨数据中心环境条件下,底层的数据库系统采用的技术方案是HBase分布式存储系统,HBase是一个采用LSM的方式组织底层数据的存储系统,且跨数据中心环境条件下,遥感卫星等应用呈现数据访问局部性以及写入一次读取多次等特征。
以下对实施例中用到的HBase存储系统相关技术术语进行说明:
(1)HBase组件:在HBase存储系统中包括HMaster,HRegionServer和Client。其中HMaster负责HBase存储系统中数据表的创建、删除等操作。HRegionServer上存储具体表的数据,包括表的多个HRegion。
(2)HRegion:每个表分成多个HRegion,每个HRegion包含多个Store,每个Store对应于一个列簇(column family),每个Store包含一个MemStore和多个StoreFile。
(3)Compact和Split:在HBase系统运行过程中,会产生多个HFile文件,当HFile文件个数超过一定数目的时候,HBase集群会执行Compact。当HFile文件大小超过一定的阀值时执行Split操作。
HBase存储系统的一个重要的特性是一旦HFile文件写入HDFS集群中时,HFile文件不再改变。
实施例一:
图1为是本实施例提供的分布式存储系统NoSQL搜索缓存的优化方法流程图。参考图1所示,该方法包括如下步骤:
步骤S101,在HBase客户端中,预先设置本地SSD作为只读缓存;
如图2所示的HBase客户端(分布式存储系统集群)中设置本地SSD作为只读缓存后的架构示意图。其中本地SSD可以加入HRegionServer中。
步骤S102,当HBase客户端读取目标数据时,判断目标数据是否位于所述本地SSD上,如果是,则进入步骤S104;如果否,则进入步骤S103;
本步骤之前,HBase客户端根据需求产生Get/Scan操作请求,根据操作的目标数据,HBase客户端将Get/Scan等操作请求发送至对应的HRegionServe,HRegionServer根据接收到的读取请求,判断目标数据是否位于本地内存中,其中假设需要读取HFile文件,定位具体的HFile文件,判断所述HFile文件中的数据库是否在本地内存中,如果是,则从本地内存中返回所述目标数据,如果否,即对应的HFileBlock数据块不在本地内存中,则进入步骤S102。
步骤S103,从HDFS集群中读取目标数据并缓存到所述本地SSD上;
其中,在步骤S103之前还可以包括:判断所述本地SSD的剩余存储空间是否满足预设要求,如果是,则进入步骤S103;如果否,则执行替换算法如LRU(Least Recently Used,最近最少使用)算法,用读取的目标数据替换所述本地SSD中的已有数据,如用读取到的HFile文件替换掉本地SSD中的旧HFile文件。
步骤S104,所述本地SSD返回所述目标数据。
对应的,所述步骤S104具体可以包括:所述本地SSD返回所述目标数据到所述本地内存,并且所述本地内存返回所述目标数据。
此外,上述实施例中,当写入数据的时候可以直接写入到底层文件系统,在所述本地SSD中不进行缓存。
在大规模海量数据环境下,通过NoSQL存储系统存储数据对于快速查找提出了低时延要求。而目前以BigTable为代表的NoSQL系统普遍采用LSM树的方式在组织半结构化数据,用于写入一次读多次的特征。
而本实施例提供的技术方案,引入本地SSD提供只读缓存功能,充分发挥SSD的随机读取性能,在SSD中缓存相关文件,因访问的数据具有局部性,通过在SSD缓存的文件可以有效的减少读取HDFS的I/O数目,从而提高分布式存储系统的性能,达到提高数据搜索效率的等目的。
上述技术方案在应用中,针对HBase采用LSM树的方式组织数据以及上层读数据多的负载,把本地SSD作为HBase集群的只读缓存功能,充分利用HBase本身的特点,尤其适用于上层遥感卫星等应用对于数据访问读多写少的负载特征。
实施例二:
在HBase存储系统运行过程中,会产生多个HFile文件,当HFile文件个数超过一定数目的时候,HBase集群需要执行Compact操作,以减少HFile文件数目。本实施例在实施例一的分布式存储系统NoSQL搜索缓存的优化方法的基础上,提供了一种在HBase集群执行Compact操作方法,如图3所述为该方法的流程示意图,具体包括以下步骤:
步骤S301,HBase客户端生成Compact操作请求;
步骤S302,判断Compact操作请求对应的目标HFile文件是否位于所述本地SSD上,如果是,则进入步骤S304;如果否,则进入步骤S303;
步骤S303,从HDFS集群中读取目标HFile文件缓存到所述本地SSD上;
步骤S304,执行Compact操作;
步骤S305,Compact操作完成后,将原HFile文件从本地SSD中删除;
步骤S306,将新生成的HFile文件写入HDFS集群以及缓存到本地SSD中。
通过本实施例提供的方法,可以在当HFile文件个数超过一定数目的时候,执行Compact操作,以减少HFile文件数目。
实施例三:
在HBase存储系统运行过程中,会产生多个HFile文件,当HFile文件大小超过一定的阀值时,HBase集群需要执行Split操作以减小HFile文件大小。本实施例在实施例一的分布式存储系统NoSQL搜索缓存的优化方法的基础上,提供了一种在HBase集群执行Split操作方法,如图4所述为该方法的流程示意图,具体包括以下步骤:
步骤S401,HBase客户端生成Split操作请求;
步骤S402,判断Split操作请求对应的目标HFile文件是否位于所述本地SSD上,如果是,则进入步骤S304;如果否,则进入步骤S303;
步骤S403,从HDFS集群中读取目标HFile文件缓存到所述本地SSD上;
步骤S404,执行Split操作;
步骤S405,Split操作完成后,将原HFile文件从本地SSD中删除。
通过本实施例提供的方法,可以在当HFile文件大小超过一定的阀值时,执行Split操作,以减小HFile文件大小。
实施例四:
相应于上述方法,本实施例还提供了一种分布式存储系统NoSQL搜索缓存的优化系统,如图5所示的该系统架构示意图,包括:
本地SSD501,用于作为只读缓存设置在HBase客户端中;
第一判断模块502,用于在HBase客户端读取目标数据时,判断目标数据是否位于所述本地SSD上;
数据读取模块503,用于在目标数据不位于所述本地SSD上时,从HDFS集群中读取目标数据并缓存到所述本地SSD上;
数据返回模块504,用于在目标数据位于所述本地SSD上时,从所述本地SSD返回所述目标数据。
此外,所述系统,还可以包括:
第二判断模块,用于判断所述本地SSD的剩余存储空间是否满足预设要求;
替换模块,用于在所述本地SSD的剩余存储空间不满足预设要求时,执行替换算法,如LRU(Least Recently Used,最近最少使用),用读取的目标数据替换所述本地SSD中的已有数据,如用读取到的HFile文件替换掉本地SSD中的旧HFile文件。
在HBase存储系统运行过程中,会产生多个HFile文件,当HFile文件个数超过一定数目的时候,HBase集群需要执行Compact操作,以减少HFile文件数目。因此所述系统,还可以包括:
Compact模块,用于当目标HFile文件位于所述本地SSD上时,执行Compact操作,将原HFile文件从本地SSD中删除,并将新生成的HFile文件写入HDFS集群以及缓存到本地SSD中。
当HFile文件大小超过一定的阀值时,HBase集群需要执行Split操作以减小HFile文件大小。因此所述的系统,还可以包括:
Split模块,用于当目标HFile文件位于所述本地SSD上时,执行Split操作,将原HFile文件从本地SSD中删除。
本实施例提供的技术方案,引入本地SSD提供只读缓存功能,充分发挥SSD的随机读取性能,在SSD中缓存相关文件,因访问的数据具有局部性,通过在SSD缓存的文件可以有效的减少读取HDFS的I/O数目,从而提高分布式存储系统的性能,达到提高数据搜索效率的等目的。
上述技术方案在应用中,针对HBase采用LSM树的方式组织数据以及上层读数据多的负载,把本地SSD作为HBase集群的只读缓存功能,充分利用HBase本身的特点,尤其适用于上层遥感卫星等应用对于数据访问读多写少的负载特征。
本发明在软件上,操作系统优选为Linux系统,运行在Linux机群中提供文件IO服务的软件之上,如HDFS、GFS等分布式文件系统和HBase等NoSql分布式数据库系统,并且HDFS分布式文件系统配置多个DataNode。
以上实施例提供的技术方案中的全部或部分内容可以通过软件编程或专用硬件设备实现,其中软件程序存储在可读取的存储介质中,存储介质例如:计算机中的硬盘、光盘或软盘;专用硬件设备可以是ASIC、FPGA、SoC、或具有相应电路的IP Core。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!