一种基于深度模型的合成孔径雷达图像目标识别方法与流程
本发明涉及机器学习、深度学习应用技术,特别涉及深度学习方法在合成孔径雷达图像目标识别中的应用。
背景技术:
合成孔径雷达(Synthetic Aperture Radar,以下简称SAR)能够在全气候条件下全天提供高分辨率图像。当前SAR图像目标识别系统的主要方法是利用图像目标的特征训练分类器,通过分类器实现SAR图像目标识别,因此分类器的性能决定了识别系统的识别能力。
特征的选择和提取对分类器的设计和性能有很大的影响。模式识别就是将具体事物归到具体的某一类别的过程,也就是先用一定数量的样本,根据它们之间的相似性进行分类器设计,而后用所设计的分类器对待识别的样本进行分类决策。分类的过程既可以在原始数据空间中进行,也可以对原始数据进行变换,将数据映射到特征空间中进行。相比而言,后者使得决策机器的设计变得更为容易,它通过更为稳定的特征表示,提高了决策机器的性能,删去了多余的或者不相关的信息,并且更加容易发现研究对象之间的固有联系。因而,特征是决定样本之间的相似性和分类器设计的关键。当分类的目的决定之后,如何找到合适的特征是识别的核心问题。
SAR图像成像方式非常特殊,相比较光学图像而言,它表现为稀疏的散射中心分布,而且对成像的方位角很敏感,环境噪声复杂,容易出现不同程度的畸变。因此,针对SAR图像的显式特征提取并不容易,在一些应用问题中也并非总是可靠的。同时,特征的数量影响着识别系统的复杂度,大量的特征并不能确保获得到好的识别效果因为特征之间并不是独立的,而具有相关性,不好的特征可能大大损害系统的工作;使用较少的特征可以减少计算时间,这对于实时应用非常重要,但是可能导致基于特征的分类器训练不充分而不够成熟,大大降低识别性能。对于需要通过训练阶段才能进行的特征选择,如果选择的特征过多就意味着用更复杂的模型去拟合训练样本。由于训练样本可能存在着各种噪声,复杂的模型可能会产生对训练样本的过拟合情况,使模型敏感于噪声,失去了概括能力,也就不能很好地识别目标。以上种种原因,使得在SAR目标识别系统中,特征的选择与提取成为难度最大的问题。
技术实现要素:
本发明的发明目的在于:为了克服现有技术中对SAR图像目标识别的不足之处,以达到SAR图像目标识别更高准确度,特提供一种基于深度模型的SAR图像目标识别方法。
深度模型是一种多层感知器,它具有多个层级结构,每个层级选择以及提取的特征是通过其自身高度匹配与训练得到,因此所提取的特征可以看作是目标的高度表征。这种高度特征表达能力是基于其自身强大的学习能力,将图像样本直接作为输入数据,因此能够大大地降低在图像预处理过程中特征选择与提取所需要的开销。同时,深度模型具有良好的并行处理能力和学习能力,可以处理SAR图像环境信息复杂的问题,甚至允许样本有较大的位移、拉伸、旋转等。
步骤1:输入作为训练样本的SAR图像(记训练样本数为M),其中训练样本应该包括不同类别的识别目标,用T标识训练样本的类别数。
作为训练样本的SAR图像的获取方式可以是,对成孔径雷达获取的原始SAR图像以目标为中心进行切割,每一张切割后的SAR图像包含完整的识别目标。保证分割后的SAR图像中识别目标方位角以及俯仰角的多样性有助于在训练阶段获得更加成熟的深度模型。
步骤2:构建深度模型:
步骤201:构建卷积神经网络模块:
构建由卷积滤波器与池化滤波器级联的卷积神经网络模块,其中卷积滤波器用于对输入数据进行滑窗卷积得到卷积输出;池化滤波器用于对输入数据(即卷积输出)进行降维处理,得到卷积神经网络模块的卷积层输出,其中降维处理为:对卷积输出进行最大值滤波处理,用滤波区域的局部最大值替代滤波区域整体;
步骤202:设置H层的深度模型,深度模型的第1~H-1层为级联的H-1个卷积神经网络模块,第1层的输入为训练样本,第2~H-1层的输入为上一层的卷积层输出,且第1~H-1层的卷积滤波器的尺寸逐渐变小。池化滤波器的尺寸为预设值,可根据实际应用需求进行对应设置,每层的池化滤波器的尺寸可设置为相同,也可设置为不相同。
深度模型的第H层包括卷积滤波器,用于对输入数据进行卷积(非滑窗)滤波,第H层的卷积滤波器的输入为第H-1层的卷积层输出,且卷积滤波器的尺寸等于第H-1层的卷积神经网络模块的输出特征图尺寸。
本发明的深度模型层级结构能够提取不同深度的图像目标特征,主要通过尺寸大小为ω的卷积滤波器对图像进行卷积运算提取输入图像的特征作为输出。
卷积运算可用公式表示为:即以预设步长s1(该公式中的s1=1)的滑窗方式对输入Sij(i,j为图像坐标)进行卷积得到对应位置的输出Si′j′′,wnm代表卷积滤波器第n行第m列参数;调整ω的大小控制卷积滤波器的尺寸;随着深度结构的深入,特征图像的尺寸逐渐减小,ω的尺寸随之适当减小,卷积滤波器的数量适当增加。
将卷积滤波器直接作用于图像,提取图像特征。由于深度模型层级结构能够实现自主的学习更新,系统的输出将反馈作用于每一层级的网络参数(卷积滤波器参数),高斯随机初始化的卷积滤波器在该反馈作用下,参数进行自主修正,最终成为能够提取高度表征目标特征的特征提取滤波器,该特征的选择与提取过程由系统自主完成,省去了传统目标识别的图像特征提取等预处理过程,大大降低了实现目标识别的开销,不仅如此,所有的特征提取滤波器均经过高度匹配训练得到,得到的深层特征更加有利于系统进行目标识别。
对每一卷积神经网络模块,其卷积层(卷积滤波器)输出的特征图尺寸为:ho1=(hi-ω)/s1+1,其中h01、hi、ω分别表示输出特征图尺寸、输入特征图尺寸以及卷积滤波器的尺寸。步长s1可以有效地减少对重复区域的卷积运算,提高深度模型的工作速度。随着深度结构的深入,特征图像的尺寸逐渐减小,卷积滤波器的数量适当增加以保证层级结构提取特征的多样性。
为了提取目标的深层特征,深度模型具有复杂的层级结构以及数量较多的卷积滤波器,因此会产生大量的参数,增加了识别处理的负担。不仅如此,不同的卷积滤波器只对特定的特征敏感,这也意味着卷积层后的特征图经过特征提取后将产生大量的冗余信息,导致后续层级将耗费大量资源在这些冗余信息的处理上。为了实现对深度模型参数数量的控制,以及剔除冗余信息,在每一卷积神经网络模块,需要利用池化方法通过滑窗的方式(步长设置为s2)对卷积滤波器的卷积输出即用当前滤波区域(当前窗口)的局部最大值替代当前滤波区域整体作为输出:其中eij代表图像第i行第j列像素值,ei+nj+n的含义与eij相通,eo为输出像素值。
池化滤波器输出的特征图尺寸为:ho2=(hi-ωd)/s2+1,其中ωd代表池化滤波器的尺寸,stride设置了相邻池化滤波器的间隔,对每一卷积神经网络模块,其输出特征图的尺寸即为池化滤波器输出的特征图尺寸ho2。
深度学习一个明确的目标就是从原始数据中提取出关键因子,而原始数据通常缠绕着高密集的特征向量,这些特征向量是相互关联的,一个关键因子可能缠绕着几个甚至大量的特征向量,为了进一步剔除冗余信息,而近似程度最大地保留数据特征,可以通过大多数元素为0的稀疏矩阵来实现,如通过Sigmod激活函数f(x)=(1+e-x)-1、双曲正切函数f(x)=tanh(x)、f(x)=|tanh(x)|以及校正线性单元(Rectified Linear Unit)f(x)=max(0,x)等修正处理函数,其中x表示卷积输出的单个元素。
本发明的修正处理函数优选f(x)=max(0,x),即对于卷积输出的每个元素,取其与0中的最大项作为修正结果。由此引入修正线性单元,即在深度模型的每层设置修正线性单元,用于对卷积滤波器的输出进行修正处理。对卷积神经网络模块,则先进行修正处理后,再进行池化滤波,对深度模型的第H层,将修正处理后的卷积输出作为深度模型的最终输出。
深度模型的底层(第H层)采用全连接输出,即对第H-1层输出的每一幅特征图(尺寸大小为L×W)中的元素进行加权求和得到和值其中xi的下标用于标识同一训练样本的不同特征图(也对应第H层的不同卷积滤波器标识),knm为第H层的卷积滤波器第n行第m列的参数,enm为特征图第n行第m列的元素,将得到的同一训练样本在第H层的所有特征图的和值xi组合形成输出特征矩阵,即训练样本的特征向量矩阵X=[x1x2x3...xp]T,其中p表示每个训练样本在第H层的特征图数目。
步骤3:深度模型训练:
步骤301:初始化化迭代次数d=0,初始化学习率α为预设值;
步骤302:从训练样本样本集中随机选择N幅图像作为子训练样本集,输入到深度模型的第1层,基于深度模型的第H层输出得到每个训练样本的特征向量矩阵X;
逐级计算各级卷积滤波器的误差值δ:第H层卷积滤波器的误差值为F-X,期望输出F为预设值;第1~H-1层卷积滤波器的误差值为则基于上一层的误差值与卷积滤波器的参数wnm的乘积得到,下标n=1,2…,ω,m=1,2…,ω,ω表示卷积滤波器的尺寸;根据各级卷积滤波器的误差值更新参数wnm:wnm=wnm-Δwnm,其中
若在识别处理时,采用Softmax回归模型计算待识别图像的特征向量矩阵分别属于T类目标的分类概率。则在步骤302中,还需要基于特征向量矩阵X对Softmax回归模型参数θj(j=1,2,…,T)进行迭代更新学习:
基于Softmax回归模型可得到每个特征向量矩阵X的类别概率矩阵hθ(X):
其中向量θ=(θ1,θ2,…,θT),其初始值为随机初始化,y表示类别识别结果,e表示自然底数,表示关于θj的矩阵转置。
当前迭代的N个训练样本表示为:(X(1),y(1)),(X(2),y(2)),(X(3),y(3))...(X(N),y(N)),其中X(i)表示第i个训练样本的特征向量矩阵(由深度模型的最终输出得到),y(i)表示对应X(i)的类别标识,即y(i)=1,2,…,T,基于N个(X(i),y(i))计算似然函数以及对数似然函数:
似然函数其中P(y(i)|X(i),θ)表示X(i)分类为j的概率;对数似然函数其中I{·}为指示函数,若{·}为真,则I{·}=1;若{·}为真假,则I{·}=0;
对数似然函数l(θ)的代价函数通过梯度下降算法实现J(θ)的最小化:
将与学习率α的乘积作为回归模型参数修正量:即在下次迭代时,将上一次的修正量作为当前迭代的回归模型参数;
最后,更新迭代次数d=d+1。
步骤303:判断迭代次数是否达到结束阈值,若是,则执行步骤304;否则,再判断迭代次数是否达到调整阈值,若是,则降低学习率α,并基于更新后的各级卷积滤波器的参数wnm执行步骤302;若否,则直接基于更新后的各级卷积滤波器参数wnm执行步骤302;
步骤304:基于各级卷积滤波器的当前参数wnm得到训练完成的深度模型,并将最后一次迭代的修正量作为最终的回归模型参数,用于对待识别图像的识别处理。
步骤4:输入待识别SAR图像,以待识别目标为中心进行图像切割,得到与训练样本相同尺寸的待识别图像;将带识别图像输入训练完成的深度模型,得到待识别图像的特征向量分别属于T类目标的分类概率,以最大概率对应的类别作为目标识别结果。
步骤4:输入待识别SAR图像,以待识别目标为中心进行图像切割,得到与训练样本相同尺寸的待识别图像;
将待识别图像输入训练完成的深度模型,输出待识别图像的特征向量矩阵;
步骤5:计算待识别图像的特征向量矩阵分别属于T类目标的分类概率,以最大概率对应的类别作为目标识别结果。若采用Softmax回归模型,则基于步骤3得到的最终的回归模型参数,计算待识别图像的特征向量矩阵分别属于T类目标的分类概率,以最大概率对应的类别作为目标识别结果。
综上所述,本发明的有益效果是:能够直接处理目标识别的SAR图像,有效地减少在目标识别任务中特征选择与提取的预处理过程所需工作量,提取高度匹配识别目标的深层特征,提升目标识别的准确度。
附图说明
图1为深度模型结构示意图。
图2为卷积滤波原理图。
图3为最大值池化原理图。
图4为MSTAR坦克原始图像。
图5为深度模型的滤波器以及各层输出特征图示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
采用如图1所示的4层深度模型结构实现本发明,其中第1~3层分别包括卷积滤波器、修正线性单元和池化滤波器,第4层为全连接层,其包括卷积滤波器和修正线性单元。深度模型的输入(input)为训练样本、测试样本。第1~3层的卷积滤波器以预设步长s=1的滑窗方式对输入数据(如图2‐a所示)进行卷积得到卷积输出,如图2‐b所示;池化滤波器对卷积输出进行降维处理:用滤波区域的局部最大值替代滤波区域整体,如图3所示。
本实施例中,训练样本的提取来源为MSTAR图像数据(对每辆车都能提供72个不同视角和不同方向的样本)。如图4所示的大小为128*128的SAR图像,图中包含3个区域:坦克、阴影和背景,并且图像中有比较严重的相干斑噪声。
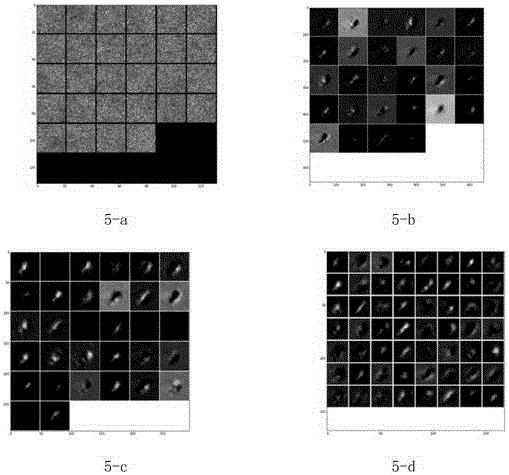
基于采集的训练样本集,结合图1所示的深度模型,可以得到一次模型迭代训练过程中,深度模型的各层滤波器以及各层输出的特征图,如图5所示,其中5-a为深度模型的第1层卷积层滤波器,5-b为SAR原始图像经过第1层卷积滤波、修正和降维处理后输出的特征图,定义为第1层特征特征图,图5-c为第1层特征图经过第2层卷积滤波、修正和降维处理后输出的特征图,定义为第2层特征图,图5-d为第2层池化输出后经过第3层卷积滤波及修正处理后输出的特征图。
基于训练完成的深度模型,分别对不同的测试样本(参见表1)进行目标识别处理,本实施例中,采用Softmax回归模型计算深度模型输出的待识别图像的特征向量矩阵分别属于T类目标的分类概率,以最大概率对应的类别作为目标识别结果。针对MSTAR数据集十类车辆目标:2S1、BMP-2、BRDM_2、BTR60、BTR70、D7、T62、T72、ZIL_131和ZSU_23_4能够达到93.99%的识别率。
表1
表2给出了本发明方法与现有方法IGT(iterative graph thickening on discriminative graphical models)、EMACH(扩展最大平均相关高度滤波器)、SVM(支持向量机)、Cond Gauss(条件高斯模型)和Adaboost(feature fusion via boosting on individual neural net classifies)的平均准率对比表:
表2
其中,现有方法IGT、EMACH、SVM、Cond Gauss和Adaboost使用姿态矫正算法提高性能,在没有在台矫正的情况下,上述方法的准确率下降至88.60%,SVM83.90%、Cond Gauss86.10%、Adaboost87.20%,尽管本发明的卷积神经网络在没有任何图像预处理的情况下进行训练,但相比较以上大部分经过姿态矫正的方法,其仍旧具有非常出众的性能,只有经过姿态矫正的IGT方法比本发明(不需要姿态矫正)的识别准确度高1%,相比较其他方法,本发明能够节省大量在图像预处理方面所花费的资源和时间成本,工作开销低。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!