一种跨领域知识迁移的标签嵌入方法和装置与流程
本发明涉及贝叶斯网络及文本挖掘的应用领域,尤其涉及一种跨领域知识迁移的标签嵌入方法和装置。
背景技术:
近年来,随着大数据技术的飞速发展,各行各业越来越注重数据的价值,且各家积累的数据源和数据结构呈现出多样化的特点,其中文本数据的产生也越来越多,如各家线上媒体、电商评论、微博、在线广告等都会产生大量的文本数据,通过挖掘用户的这些历史行为数据中的信息,识别用户的兴趣,对各家企业十分重要。由于文本数据的特征表达多高维稀疏,且中文语义复杂,对这些文本进行语义解析和分类一直是一大难题,学术界和工业界产生了一些优秀的算法,如LDA、PLSA、深度学习分类等方法,在计算方法上也有分布式并行计算如hadoop、spark、参数服务器等进行模型训练和泛化的方式。
但是我们在实际使用和研究过程中发现,现有技术至少存在以下问题:现有技术是基于非监督学习的聚类分析方法或是依赖大量标注数据,不能满足业务人员的个性化需求。实际使用过程中经常由业务人员根据自身业务发展情况设计自上而下的标签体系,这种情况下采用非监督学习的聚类分析技术输出的结果与业务体系本身往往会有较大差异;若选择采用监督方法,如文本分类按照业务人员设计的体系对预料的语句进行标注,产生样本数据,而对语句或文章的标注对文本数据总体来说,耗时且耗费成本,而且标注的准确性也取决于参与标注人员的业务经验。
总之,现有技术中对文本数据进行标签标注的算法不能兼顾标注的准确性及高效率性,满足业务人员的业务需求。
技术实现要素:
为解决以上问题,本发明提供一种跨领域知识迁移的标签嵌入方法和装置,使其可以兼顾标注的准确性及高效率性,满足业务人员的业务需求。
本发明一种跨领域知识迁移的标签嵌入方法,包括以下步骤:获取源域和目标域的文本数据,对源域和目标域的文本数据进行分词处理和模型表征,求解源域和目标域中关键词的词向量参数,并进行从源域到目标域的关键词标签的迁移;采用随机森林最近邻方法获取源域与目标域中已标注的关键词的最近邻,将已标注的关键词的关键词标签赋权给最近邻的关键词,得到扩展后的关键词标签;根据抽取的用户级的文本数据,进行用户级关键词标签的标注;以关键词的词向量参数和用户级关键词标签为基础,根据用户的点击和/或访问数据信息,动态优化用户级关键词标签部分的参数;从目标域中获取新的用户级文本数据,进行用户级关键词标签的标注预测和排序,并输出结果。
作为进一步优化,所述对源域和目标域的文本数据进行模型表征,求解源域和目标域中关键词的词向量参数,包括:建立连接源域和目标域数据特征的综合似然损失函数,其中,所述综合似然损失函数由极大似然损失函数和共享正则函数构成;采用kernel-based高斯核算法模型度量共享正则函数;对极大似然损失函数进行转化;采用异步随机梯度下降算法对综合似然损失函数进行迭代优化求解,得到源域和目标域中关键词的词向量参数。
所述对极大似然损失函数进行转化,事先需要对源域和目标域中的关键词采用Huffman编码,编码后产生的路径节点的分支采用Logistic分类预测。
所述采用随机森林最近邻方法获取源域与目标域中已标注的关键词的最近邻,将已标注的关键词的关键词标签赋权给最近邻的关键词,得到扩展后的关键词标签,包括:以源域和目标域中的关键词的词向量参数为基础构建随机抽取向量组,根据随机抽取的关键词的词向量参数间的余弦值作为分支依据,构建随机森林;搜索每棵树上具有关键词标签的关键词的最近邻关键词,并将已标注的关键词的关键词标签赋权给最近邻的关键词;对所有树上具有相同关键词标签的关键词进行汇总和紧邻排序,得到扩展后的关键词标签及关键词标签所包含的关键词集合。
所述以关键词的词向量参数和用户级关键词标签为基础,根据用户点击和/或访问的数据信息,动态优化用户级关键词标签部分的参数,包括:以用户级关键词标签作为本步骤的一个输入源,以用户在线广告投放的点击反馈和广告或访问渠道的数据信息作为另一个输入源,将二者的概率分布进行联合,构建联合似然损失函数;采用随机梯度下降算法对所述联合似然损失函数进行迭代优化求解,获得用户级关键词标签部分的参数。
所述用户级关键词标签的标注服从多项分布,对应的关键词的词向量参数为其特征,所述用户在线广告投放的点击反馈服从二项分布,广告或访问渠道的数据信息为其对应的扩展特征。
此外,本发明还提供了一种应用上述方法的跨领域知识迁移的标签嵌入装置,包括:获取模块,用于获取源域和目标域的文本数据;分词模块,用于对获取的源域和目标域的文本数据进行分词处理;模型表征模块,用于求解源域和目标域中关键词的词向量参数;迁移模块,用于根据得到的源域和目标域中关键词的词向量参数,将源域中的关键词标签迁移至目标域;扩展模块,用于采用随机森林最近邻方法获取源域与目标域中已标注的关键词的最近邻,将已标注的关键词的关键词标签赋权给最近邻的关键词,得到扩展后的关键词标签;标注模块,用于根据抽取的用户级的文本数据,进行用户级关键词标签的标注;动态优化模块,用于以上述模块得到的关键词的词向量参数和用户级关键词标签为基础,根据用户的点击和/或访问数据信息,进行动态优化,调整用户级关键词标签的标注;标注预测模块,用于从目标域中获取新的用户级文本数据,进行用户级关键词标签的标注预测和排序,并输出结果。
本发明提供的一种跨领域知识迁移的标签嵌入方法和装置,针对源域和目标域的文本数据,进行从源域到目标域关键词标签的迁移和扩展的离线训练,然后结合用户在线广告投放的点击反馈和广告或访问渠道的数据信息,进行动态优化用户级关键词标签部分的参数的在线训练,构建关键词标签的标注模型,最终对目标域用户级文本数据进行标注预测。本方案实施例提供的上述方案与现有技术相比,有以下有益效果:
(1)跨领域的关键词标签的迁移和扩展、基于投放的动态优化,一方面可以在有限标注的情况下完成原来需要大量标注数据的模型训练任务,另一方面通过实际投放进行动态优化调整标签的权重和排序,在标注精度上也给予很大的提升,有效激活标注和实际业务的联系;
(2)本发明涉及的任务和计算较多,通过异步和同步分布式计算的结合,以及采用任务和服务的独立控制,有利于系统资源充分利用,避免程度重复开发,推进模型标准化以及自动化需要。
附图说明
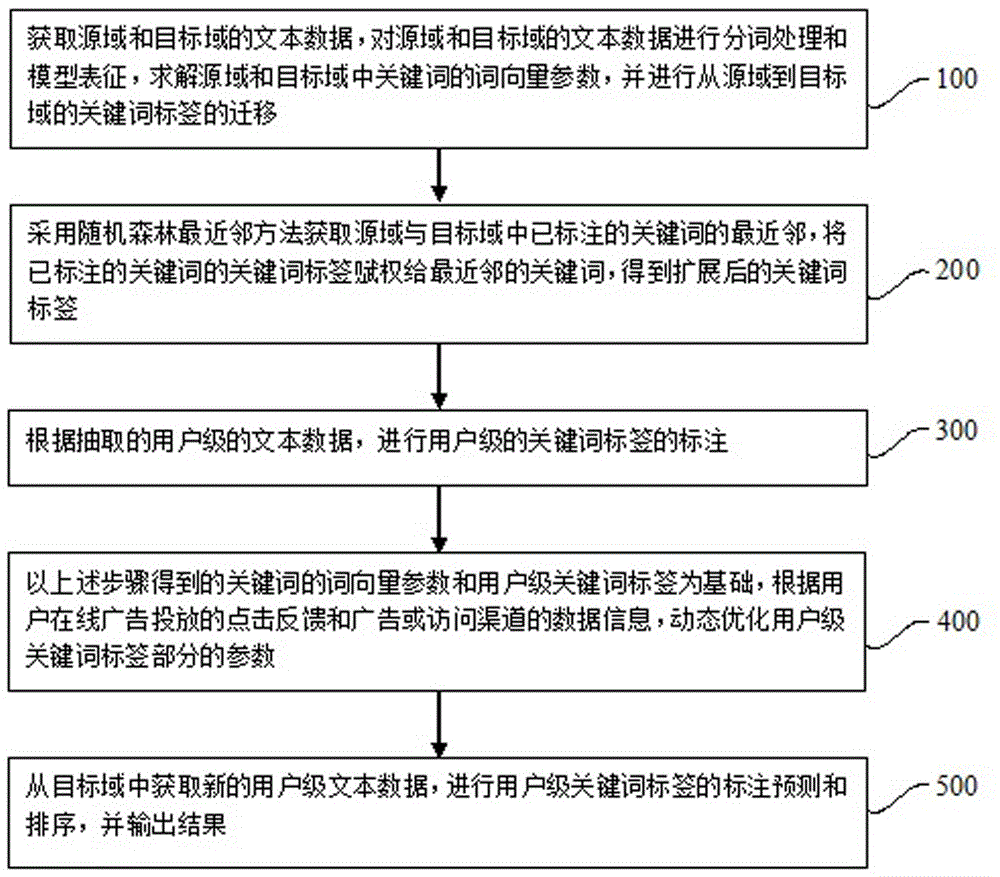
图1为本发明实施例提供的跨领域知识迁移的标签嵌入方法的流程图。
图2为本发明实施例提供的跨领域知识迁移的标签嵌入方法中通过模型表征求解关键词的词向量参数的流程图。
具体实施方式
为了满足业务人员的业务需要,本发明实施例提供一种可在较少人工标注样本的情况下,跨领域知识迁移的标签嵌入方法和装置。以下根据说明书附图所示实施例阐述本发明。此次公开的实施方式可以认为在所有方面均为例示,不具限制性。本发明的范围不受以下实施方式的说明所限,仅由权利要求书的范围所示,而且包括与权利要求范围具有同样意思及权利要求范围内的所有变形。
本发明提供一种跨领域知识迁移的标签嵌入方法,为三层结构模型的算法,包括:第一层,对源域和目标域的文本数据进行分词处理,基于关键词标签及分词处理产生的关键词,通过贝叶斯概率将源域和目标域建立连接,进行从源域到目标域的关键词标签的迁移;第二层,基于第一层训练得到的关键词的词向量参数,采用随机森林改进的最近邻算法进行关键词标签的扩展;第三层,将第一层训练得到的关键词的词向量参数和第二层扩展得到的扩展后的关键词标签作为一个输入源,以用户在线投放和展示的相关数据作为另一个输入源,在线训练和优化关键词标签标注模型。
下面结合附图,用具体实施例对本发明提供的方法及装置进行详细描述。
图1为本发明实施例提供的跨领域知识迁移的标签嵌入方法的流程图,具体包括如下处理步骤:
步骤100,获取源域和目标域的文本数据,对源域和目标域的文本数据进行分词处理和模型表征,求解源域和目标域中关键词的词向量参数,并进行从源域到目标域的关键词标签的迁移。
具体地,获取源域和目标域的文本数据,文本数据中包含的是语句内容,对源域和目标域的文本数据中语句内容进行分词处理,得到两个域中元素为关键词的两大集合,所采用的分词处理的方式,可以为现有技术中的各种方式,在此不再进行详细描述。由于这两大集合来自不同的数据源,因而具有不同的数据分布,但可以通过关键词,映射为中间的隐藏层,对源域和目标域建立连接。两个域中的关键词都是存在于各自文本数据的语句内容中,每个域的语句内容中每个关键词前后关键词的共现都以一定的概率分布出现,两个域分别建立关键词和语句之间的概率关系,两个域之间通过关键词的词向量参数和距离度量的正则项建立连接,构建综合似然损失函数并进行迭代优化求解,得到源域和目标域的关键词的词向量参数。然后,根据得到的源域和目标域中关键词的词向量,进行从源域到目标域的关键词标签的迁移。为了便于理解本步骤,下面通过图2描述本步骤中通过模型表征求解关键词的词向量参数的过程。
图2为本发明实施例提供的跨领域知识迁移的标签嵌入方法中通过模型表征求解关键词的词向量参数的流程图。
步骤101,如图2所示,建立连接源域和目标域数据特征的综合似然损失函数,其中,所述综合似然损失函数由极大似然损失函数和共享正则函数构成。
分别建立源域和目标域中关键词与语句内容之间的极大似然损失函数L,源域和目标域中关键词初始化为词向量参数,所述词向量参数分别从两个域中学习分布信息,建立两个域的分布信息的共享正则函数F,正则元素为两个域中关键词的词向量参数,最后联立极大似然损失函数L和共享正则函数F,得到综合似然损失函数Loss。该综合似然损失函数Loss的计算公式表示如下:
Loss=L+λF,
其中,Loss表示综合似然损失函数,L表示极大似然损失函数,F表示共享正则函数,λ表示正则化系数,取值范围为λ∈(0,1)。
共享正则函数F的表示如下:
其中,D表示源域,T表示目标域,VD和VT分别表示D域和T域中语句各自进行分词后形成的关键词的集合,wi和wj分别表示i域和j域中的关键词w,βD和βT分别表示D域和T域中关键词的词向量参数,sim(wi,wj)表示wi和wj的相似度系数,dis tan ce(βD,βT)表示βD和βT词向量参数间的距离。
基于概率分布,结合语句内容,极大似然损失函数L表示如下:
其中,wl表示l域的中的关键词w,l∈D∪T,h(wl)表示包含wl的语句内容。
步骤102,采用kernel-based高斯核算法模型度量共享正则函数,即源域和目标域中关键词的词向量参数的正则化。
Kernel-based高斯核算法模型的计算公式如下:
其中,p表示决定βT和相邻的βD之间的距离范围的窗口,其计算公式为:表示p的计算估计值,表示关键词的词向量参数的标准差,n为样本量。
结合上述Kernel-based高斯核算法模型的计算公式,共享正则函数F的计算公式表示如下:
其中,i表示D域中第i个关键词,j表示T域中第j个关键词,βtD表示D域中第i个关键词的词向量参数,表示T域中第j个关键词的词向量参数。
步骤103,对极大似然损失函数进行转化。
为了提高算法求解的效率,本发明中源域和目标域文本数据的关键词将采用Huffman方式进行编码,编码后产生的路径节点的分支采用Logistic分类预测。Logistic函数的定义如下:
其中,c表示l域中关键词w前后窗口长度,为自定义常数;β表示关键词w对应的词向量参数;εk表示窗口长度内关键词的词向量参数对应的隐藏层的词向量参数,表示隐藏层的2c个隐藏层词向量参数的累加和。另外,定义为关键词w在l域中Huffman编码的第j个路径节点;则极大似然损失函数L可转化为如下表示:
其中,表示l域中关键词的总个数,表示关键词w在l域中Huffman编码的第j-1个路径节点对应的词向量参数,表示对上述参数的转置。
步骤104,采用异步随机梯度下降算法对综合似然损失函数Loss进行迭代优化求解,得到源域和目标域中关键词的词向量参数。
定义学习速率函数表示如下:
其中,βtD表示对D域中关键词的词向量参数进行第t次迭代计算,同理,表示对T域中关键词的词向量参数进行第t次迭代计算;表示综合似然损失函数Loss对D域中关键词的词向量参数求导,表示综合似然损失函数Loss对T域中关键词的词向量参数求导;另外,综合似然损失函数Loss分别对D域和T域中关键词的词向量参数求导的计算表示式如下所示:
其中,表示综合似然损失函数Loss对D域中第k-1个关键词的词向量参数求导,表示综合似然损失函数Loss对T域中第k-1个关键词的词向量参数求导;表示D域中第k个关键词w所对应的词向量参数,表示T域中第k个关键词w所对应的词向量参数。根据以上多次迭代计算和最优化求解,得到D域和T域中关键词的词向量参数。
返回到图1中,根据得到的源域和目标域中关键词的词向量参数,将源域中的关键词标签迁移至目标域并保存。具体地,根据上述步骤得到的源域和目标域中关键词的词向量参数,对目标域中的关键词和源域中已标注的关键词标签进行匹配与映射,得到目标域中带关键词标签的关键词及其对应的词向量参数,保存上述通过模型表征得到的关键词的词向量参数及迁移得到的关键词标签等信息。
步骤200,采用随机森林最近邻方法获取源域与目标域中已标注的关键词的最近邻,将已标注的关键词的关键词标签赋权给最近邻的关键词,得到扩展后的关键词标签。
具体地,以源域和目标域中的关键词的词向量参数为基础构建随机抽取向量组,以目标域中已标注的关键词对应的关键词标签作为目标,可放回随机抽取源域和目标域中的关键词,以随机抽取的两个域中关键词的词向量参数的余弦值作为分支依据构建随机森林,然后将源域和目标域进行分词处理后产生的所有关键词进行排重处理,将排重后的关键词作为关键词的词典,遍历词典中具有关键词标签的关键词,搜索每棵树上具有关键词标签的关键词的k个最近邻关键词,并将已标注的关键词的关键词标签赋权给k个最近邻的关键词,对所有树上的具有同一关键词标签的关键词进行汇总和紧邻排序,可以根据汇总结果和实际需要设置新的k值以及余弦阈值作为最终的关键词标签的标注结果,保存扩展后关键词标签及关键词标签所包含的关键词集合。由于每棵树独立进行,所以该步骤可以采用同步分布式方式进行。
步骤300,根据抽取的用户级的文本数据,进行用户级关键词标签的标注。
具体地,随机抽取来自用户端或生产系统的用户行为数据或言论数据,如新浪微博、今日头条或媒体上抓取的数据等作为用户级的文本数据,对用户级的文本数据进行分词处理,获取每个用户的关键词的加权集合,即TFIDF权重,根据上述步骤中得到的关键词及关键词标签的标注结果,并结合贝叶斯公式,得到用户级关键词标签的标注结果,例如扩展前的某一关键词为key-old,其对应的标签有两个分别为label-key-old-k和label-key-old-m,相应的概率分别为p(label-key-old-k|key-old)、p(label-key-old-m|key-old),若有一个用户级关键词为key-new,其已知的概率有p(key-old|key-new),则由贝叶斯公式可以得到该用户关键词key-new对应的标签,即:
p(label-key-old-k|key-new)=p(label-key-old-k|key-old)*p(key-old|key-new);
p(label-key-old-m|key-new)=p(label-key-old-m|key-old)*p(key-old|key-new)。
步骤100-300为关键词嵌入迁移学习模型标注的具体过程。由于步骤100-300涉及到的关键词标签的迁移和扩展仅为从语义层面获取关键词标签与关键词的关系以及拓展这些关系,即为通过用户及其访问信息的具体内容做静态映射,然而对实际的在线业务是否真正起到关联和反馈作用需要在用户实时的实践中才能得到体现,故本发明在此基础上加了一层在线用户行为模型,即基于用户在线投放的点击反馈的动态优化调整部分,具体为以通过前述关键词嵌入迁移学习的模型表征和关键词标签的迁移等步骤得到的关键词标签为目标,建立以用户级的关键词为特征的多分类和广告反馈或购买反馈为基础的二项分布之间的联合似然损失函数。
步骤400,以上述步骤得到的关键词的词向量参数和用户级关键词标签为基础,根据用户在线广告投放的点击反馈和广告或访问渠道的数据信息,动态优化用户级关键词标签部分的参数。
在本步骤中,为了动态调整上述步骤中用户级关键词标签标注的准确性和排序,以步骤300的输出作为本步骤的一个输入源,以用户在线广告投放和展示的相关数据作为本步骤的另一个输入源,这个部分其实有两个目标,一个是基于用户关键词特征的用户级关键词标签多分类,一个是基于与用户兴趣相关的在线广告投放的点击反馈分类,由于两者有两层联系,一是用户级的关键词标签特征对用户在线广告投放的点击来说是特征,用户在线广告投放的点击与否又是用户级关键词标签特征有用与否的终极目标,即是优化用户级关键词标签的标注和排序的有效信息。
具体地,用户级关键词标签的标注服从多项分布,对应的关键词的词向量参数为其特征,用户在线广告投放的点击反馈行为服从二项分布,广告或访问渠道的数据信息为其对应的扩展特征,将二者的概率分布进行联合,构建联合似然损失函数,对用户级关键词标签部分的分类和排序进行优化,即采用异步随机梯度下降算法进行多次迭代优化,估计出用户级关键词标签部分的特征参数值,将此用户级关键词标签部分的特征参数保存,作为对后期新用户的用户级文本数据进行关键词标签标注预测的模型文件。
其中,联合似然损失函数Loss_ctr表示如下:
其中,Ψ表示用户级关键词标签部分的特征参数,也是我们最终想要的结果;Φ表示用户在线点击与展示部分的特征参数,即xfeat_ctr对应的系数,ytag表示用户级关键词标签部分的目标变量;yctr表示用户在线点击与展示部分的目标变量;xvec表示用户级关键词标签部分的特征,即其对应的关键词向量,xfeat_ctr表示用户在线点击与展示部分的相关数据的属性特征,Dtag,Dctr分别表示用户级关键词标签部分和用户在线点击与展示部分的数据分布信息。该函数中用户在线点击与展示部分的似然函数可以看成是对用户级关键词标签部分的正则,对用户级关键词标签部分的参数起到优化和调整的作用。
以上4个步骤是用户级关键词标签的标注模型的训练过程,接下来是根据前述步骤得到的用户级关键词标签的标注模型,对新的用户级文本数据进行关键词标签的标注预测过程。
步骤500,从目标域中获取新的用户级文本数据,进行用户级关键词标签的标注预测和排序,并输出结果。
从目标域的新数据中获取用户级的文本数据,进行分词处理,并根据每个用户关键词的TF-IDF权重进行排序,获取每个用户TopN的关键词,其中TopN的大小可根据实际需要进行自定义。从缓存中调用前述步骤中通过训练得到的关键词及其对应的关键词的词向量参数,对获取的每个用户TopN的关键词,进行匹配得到用户级的关键词的词向量参数的集合,其中,对于没有匹配到的关键词则直接舍弃,不进行本次迭代,而对匹配到的关键词,以其关键词的词向量参数为特征,从缓存中调用前述步骤中通过训练得到的用户级关键词标签部分的特征参数,通过相似度把已标注的关键词标签映射到没有标注的关键词上,即对匹配到的关键词进行关键词标签的标注预测,然后对标注预测的关键词标签进行加权和汇总,并根据标注预测后的关键词标签的加权和汇总结果对关键词标签进行排序,根据每个关键词标签加权汇总后的总权重设置阈值,输出大于阈值的对应的关键词标签的分类结果,即排除关键词标签分类中排序位置偏后的关键词。
步骤100-500为跨领域知识迁移的标签嵌入方法的整个过程,其中包括离线训练过程和在线训练过程,其中,步骤100-300为离线训练过程,步骤400-500为在线训练过程。离线训练过程包括关键词的词向量参数求解、关键词标签的迁移及扩展和用户级关键词标签的标注;在线训练过程包括用户级关键词标签分类参数的预估优化和用户级关键词标签的标注预测。由离线训练过程得到的关键词标签的标注为基于用户访问信息的静态语义信息的标注,可以看作隐性兴趣,这些信息是否会影响用户在业务上的贡献需要动态迭代优化并重新排序,即为在线训练过程的处理任务。离线训练过程和在线训练过程中函数模型为凸函数,存在一阶和二阶导数,在进行最优化求解时,采用泰勒展开和梯度下降进行迭代求参。
另外,针对在跨领域知识迁移的标签嵌入方法中涉及到的所有计算,通过调度与计算相结合的方式来进行快速部署和计算。对计算是否适合异步参数服务器计算模式和同步并行计算模式进行分割判断,判断的原则是是否需要传递参数进行迭代运算。若需要传递参数迭代的计算,如离线部分的关键词的词向量参数的迭代求解计算和在线部分的用户级关键词标签部分的参数迭代优化计算,则进行异步参数服务器计算模式;若不需要传递参数迭代的计算,如分词、TF-IDF权重的计算、关键词提取、最近邻计算等,则进行同步并行计算模式。两个部分的协调和优先级通过调度进行,具体地调度又分为任务和服务,任务部分负责具体模型计算队列的安排,服务部分负责队列任务所对应具体算法计算的调度,任务和服务进行独立控制。按照任务中设计的优先级、依赖关系以及算法类型,通过同步和异步渠道分别发送任务队列。
为实现上述实施例,本发明还提供了一种跨领域知识迁移的标签嵌入装置。
该跨领域知识迁移的标签嵌入系统包括获取模块10、分词模块20、模型表征模块30、迁移模块40、扩展模块50、标注模块60、动态优化模块70和标注预测模块80,其中:
获取模块10用于获取源域和目标域的文本数据。
分词模块20用于对获取的源域和目标域的文本数据进行分词处理,得到两个域中元素为关键词的两大集合。
模型表征模块30用于通过源域和目标域中关键词,对两个域建立连接,进行数学建模,求解源域和目标域中关键词的词向量参数。
具体地,模型表征模块30通过两个域中关键词和语句之间的概率关系、关键词的词向量参数和距离度量的正则项将两个域建立连接,即建立连接源域和目标域数据特征的综合似然损失函数,其中,所述综合似然损失函数由极大似然损失函数和共享正则函数构成。采用kernel-based高斯核算法模型度量共享正则函数,即源域和目标域中关键词的词向量参数的正则化。对源域和目标域中的关键词采用Huffman编码和Logistic分类预测,对极大似然损失函数进行转化。采用异步随机梯度下降算法对综合似然损失函数Loss进行迭代优化求解,得到源域和目标域中关键词的词向量参数。
迁移模块40用于根据得到的源域和目标域中关键词的词向量参数,将源域中的关键词标签迁移至目标域。
具体地,根据上述步骤得到的源域和目标域中关键词的词向量参数,对目标域中的关键词和源域中已标注的关键词标签进行匹配与映射,得到目标域中带关键词标签的关键词及其对应的词向量参数,保存上述通过模型表征得到的关键词的词向量参数及迁移得到的关键词标签等信息。
扩展模块50用于采用随机森林最近邻方法获取源域与目标域中已标注的关键词的最近邻,将已标注的关键词的关键词标签赋权给k个最近邻的关键词,得到扩展后的关键词标签。
具体地,以源域和目标域中的关键词的词向量参数为基础构建随机抽取向量组,以目标域中已标注的关键词对应的关键词标签作为目标,可放回随机抽取源域和目标域中的关键词,以随机抽取的两个域中关键词的词向量参数的余弦值作为分支依据构建随机森林,然后将源域和目标域进行分词处理后产生的所有关键词进行排重处理,将排重后的关键词作为关键词的词典,遍历词典中具有关键词标签的关键词,搜索每棵树上具有关键词标签的关键词的k个最近邻关键词,并将已标注的关键词的关键词标签赋权给k个最近邻的关键词,对所有树上的具有同一关键词标签的关键词进行汇总和紧邻排序,可以根据汇总结果和实际需要设置新的k值以及余弦阈值作为最终的关键词标签的标注结果,保存扩展后关键词标签及关键词标签所包含的关键词集合。由于每棵树独立进行,所以该步骤可以采用同步分布式方式进行。
标注模块60用于根据抽取的用户级的文本数据,进行用户级的关键词标签的标注。
具体地,随机抽取来自用户端或生产系统的用户行为数据或言论数据,如新浪微博、今日头条或媒体上抓取的数据等作为用户级的文本数据,对用户级的文本数据进行分词处理,获取每个用户的关键词的加权集合,根据上述步骤中得到的扩展后的关键词标签的标注结果,并结合贝叶斯公式,得到用户级关键词标签的标注结果。
动态优化模块70用于以上述步骤得到的关键词的词向量参数和用户级关键词标签为基础,根据用户在线广告投放的点击反馈和广告或访问渠道的数据信息,动态优化用户级关键词标签部分的参数。
具体地,用户级关键词标签的标注服从多项分布,对应的关键词的词向量参数为其特征,用户在线广告投放的点击反馈行为服从二项分布,广告或访问渠道的数据信息为其对应的扩展特征,将二者的概率分布进行联合,构建联合似然损失函数,对用户级关键词标签部分的分类和排序进行优化,即采用异步随机梯度下降算法进行多次迭代优化,估计出用户级关键词标签部分的特征参数值,将此用户级关键词标签部分的特征参数保存,作为对后期新用户的用户级文本数据进行关键词标签标注预测的模型文件。
标注预测模块80用于从目标域中获取新的用户级文本数据,进行用户级关键词标签的标注预测和排序,并输出结果。
具体地,从目标域的新数据中获取用户级的文本数据,进行分词处理,并根据每个用户关键词的TF-IDF权重进行排序,获取每个用户TopN的关键词,其中TopN的大小可根据实际需要进行自定义。从缓存中调用前述步骤中通过训练得到的关键词及其对应的词向量参数,对获取的每个用户TopN的关键词,进行匹配得到用户级的关键词的词向量参数集合,其中,对于没有匹配到的关键词则直接舍弃,不进行本次迭代,而对匹配到的关键词,以其词向量参数为特征,从缓存中调用前述步骤中通过训练得到的用户级关键词标签部分的参数,通过相似度把已标注的关键词标签映射到没有标注的关键词上,即对匹配到的关键词进行关键词标签的标注预测,然后对标注预测的关键词标签进行加权和汇总,并根据标注预测后的关键词标签的加权和汇总结果对关键词标签进行排序,根据每个关键词标签加权汇总后的总权重设置阈值,输出大于阈值的对应的关键词标签的分类结果,即排除关键词标签分类中排序位置偏后的关键词。
- 还没有人留言评论。精彩留言会获得点赞!