基于卷积神经网络的高光谱数据转灰度图的高光谱数据分类方法与流程
本发明涉及高光谱数据分类方法,特别涉及基于卷积神经网络的谱数据转灰度图的高光谱数据分类方法。
背景技术:
高光谱数据分类是高光谱遥感的一项应用,是利用所有物体都具有光谱特性,光谱分辨率在10l数量级范围内的光谱图像称为高光谱图像(Hyperspectral Image)。且在同一光谱区物体反应的情况不同,同一物体对不同光谱的反应也有明显差别这一特点来对高光谱遥感数据进行分类。过去的高光谱数据分类方法主要通过以下两个思路:基于光谱匹配的影像分类、基于数据统计特性的分类。虽然通过这两个思路有很多的分类方法可以应用在高光谱遥感图像上,但是,在实际的应用和操作中,仍然显示了很多不足的方面,如训练成本高、高分辨率信息浪费、现有的高谱维的图像分析和识别精确度与实际应用的需求不匹配、数学模型不符合实际地物分布规律欠缺逻辑等问题。尤其是光谱维度的不断增加,使得现有的数据分析能力逐渐跟不上高谱维信息量的脚步。
技术实现要素:
本发明的目的是为了解决现有的高谱维的图像分析和识别精确度与实际应用的需求不匹配、数学模型不符合实际地物分布规律且欠缺逻辑等问题,而提出的基于卷积神经网络的高光谱数据转灰度图的高光谱数据分类方法。
上述的发明目的是通过以下技术方案实现的:
步骤一、对高光谱原始数据进行预处理得到高光谱的谱向量,将高光谱的谱向量数据转换成为灰度图像数据;
步骤一一、对高光谱原始数据进行逐层归一化,得到归一化后的高光谱数据;
步骤一二、抽取归一化后的高光谱数据中每一个像元的全波段值,将每一个像元的全波段值组成一维向量数据
步骤一三、在归一化后的高光谱数据中其他像元重复步骤一二遍历,共提取出W×L个1×H的一维像元波谱向量即得到高光谱的谱向量;
步骤一四、将高光谱的谱向量中每一个像元的波谱向量即1×H的一维向量均转置成为二维矩阵得到W×L个二维矩阵,并将W×L个二维矩阵保存成为含有W×L张灰度图片的样本集即灰度图像数据;
步骤二、通过卷积分类模型自主学习样本集中样本的纹理特征,对灰度图像数据样本进行分类。
发明效果
本发明是基于卷积神经网络的谱数据转灰度图的高光谱数据分类方法,在高光谱图像分类任务中引入卷积神经网络的理论和模型,将光谱维向量数据转换成为灰度图形式的二维数据,并试图用图像化的语言去理解高光谱数据所携带的丰富信息量,对高光谱数据进行分类。该方法分类正确率高,对于充分利用高光谱信息和自主学习其抽象特征并进行分类有着重要的意义。
将谱信息转换成为灰度图片信息可以将传统的向量形式的数据转换成为具有纹理特征的二维图像,其丰富的纹理特征可以很好的反应高光谱数据谱段间的数据变化,同时,将向量数据转换成为二维图像数据,可以避免为减少数据量所进行的降维操作。另一方面,利用卷积网络对转换后的纹理信息进行处理,可以通过多层卷积网络自主地学习数据所携带的抽象特征。此方法有助于在实现高光谱数据的正确分类的同时,提高分类的正确率、高光谱所携带的丰富信息的利用率。
表4分别在KSC、Pavia U数据上使用CNN-灰度图、CNN-波形图、线性核支持向量机、RBF核支持向量机、PCA变换支持向量机、自动编码与逻辑回归SAE-LR方法进行分类,并对比分类结果。以上两个表格中给出了每一种方法分类的平均正确率和总体正确率,并分别给出了两个数据集中所有细分种类的分类正确率,为了使结果更清晰,在发明提出的分类方法取得最佳结果处用粗体进行显示。
基于卷积神经网络的谱信息灰度图像的分类方法在Pavia U数据集上取得的正确率超越了基于支持向量机的分类方法;然而,在KSC数据集上的表现却差强人意,究其原因,在于所选择的网络层数和参数都是基于最稳定均衡来考虑,而不是在每一个数据集下取得的最优结果的网络层数和参数。另外,卷积神经网络是一个概率模型,其分类正确率大体随着分类种类的增加而减少。
设计的优势
(1)将一维数据转换成二维数据,可以容纳更大的数据量和光谱维度。
(2)通过此方法,提高了高光谱图像的分类正确率。
(3)利用GPU缩短了分类过程所用的时间。
(4)利用深度卷积网络自主学习数据的抽象特征,避免使用欠缺逻辑的数据模型。
本发明利用Matlab对数据进行预处理,将一维数据转换成为二维灰度图片数据,通过Caffe平台和Linux操作系统实现卷积神经网络模型对变换后的高光谱数据进行分类, 并利用了GPU对实验进行加速,以减少庞大计算量带来的运算时间消耗,缩短分类所用时间。
附图说明
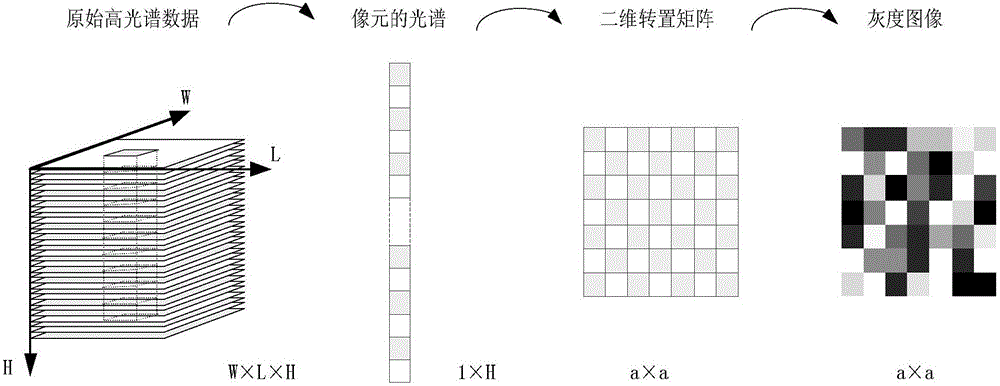
图1为具体实施方式一提出的基于谱信息灰度图分类方法的数据预处理过程示意图;其中,W为高光谱原始数据的宽度;L为高光谱原始数据的长度;H为高光谱原始数据的深度;a为二维矩阵的宽度;
图2为实施例提出的各种方法在KSC数据集上的总体正确率随训练样本数变化折线图;
图3为实施例提出的各种方法在Pavia U数据集上的总体正确率随训练样本数变化折线图;
图4(a)为实施例提出的以Indianpines数据集为例,1号Alfalfa(紫花苜蓿)灰度图的可视化结果图;
图4(b)为实施例提出的以Indianpines数据集为例,4号Corn(玉米)灰度图的可视化结果图;
图4(c)为实施例提出的以Indianpines数据集为例,5号Grass-pasture(基层农场)灰度图的可视化结果图;
图4(d)为实施例提出的以Indianpines数据集为例,6号Grass-trees(草-树木)灰度图的可视化结果图;
图4(e)为实施例提出的以Indianpines数据集为例,7号Grass-pasture-mowed(草木草割)灰度图的可视化结果图;
具体实施方式
具体实施方式一:本实施方式的基于卷积神经网络的高光谱数据转灰度图的高光谱数据分类方法,具体是按照以下步骤制备的:
步骤一、对高光谱原始数据进行预处理得到高光谱的谱向量,将高光谱的谱向量数据转换成为灰度图像数据;(卷积神经网络的输入需要二维图像数据),为将卷积神经网络应用在高光谱数据分类任务中;
下面通过对数据预处理过程的解读来介绍基于卷积神经网络的谱信息转换成灰度图像的分类方法。数据预处理过程如图1所示:
步骤一一、对高光谱原始数据进行逐层归一化,得到归一化后的高光谱数据;
步骤一二、抽取归一化后的高光谱数据中每一个像元的全波段值,将每一个像元的全波段值组成一维向量数据
步骤一三、在归一化后的高光谱数据中其他像元重复步骤一二遍历,共提取出W×L个1×H的一维像元波谱向量即得到高光谱的谱向量;
高光谱图像数据分类是以像素为目标进行的,提取出的一维向量即代表了某像元在全波谱段的数据信息。
步骤一四、将高光谱的谱向量中每一个像元的波谱向量即1×H的一维向量均转置成为二维矩阵得到W×L个二维矩阵,并将W×L个二维矩阵imwrite(imwrite是matlab中的一个函数)保存成为含有W×L张灰度图片的样本集即灰度图像数据,样本集中每一张图片代表了某像元的全波谱段信息,单张图片的某个像素点代表着该像元在特定波段下的数据值表征。整张图片的纹理特征极为明显,足以对该目标像元的数据信息进行表达,且其纹理特征也反应出了数据层间信息的变化;
步骤二、通过卷积分类模型自主学习样本集中样本的纹理特征,对灰度图像数据样本进行分类。
本实施方式效果:
本实施方式是基于卷积神经网络的谱数据转灰度图的高光谱数据分类方法,在高光谱图像分类任务中引入卷积神经网络的理论和模型,将光谱维向量数据转换成为灰度图形式的二维数据,并试图用图像化的语言去理解高光谱数据所携带的丰富信息量,对高光谱数据进行分类。该方法分类正确率高,对于充分利用高光谱信息和自主学习其抽象特征并进行分类有着重要的意义。
将谱信息转换成为灰度图片信息可以将传统的向量形式的数据转换成为具有纹理特征的二维图像,其丰富的纹理特征可以很好的反应高光谱数据谱段间的数据变化,同时,将向量数据转换成为二维图像数据,可以避免为减少数据量所进行的降维操作。另一方面,利用卷积网络对转换后的纹理信息进行处理,可以通过多层卷积网络自主地学习数据所携带的抽象特征。此方法有助于在实现高光谱数据的正确分类的同时,提高分类的正确率、高光谱所携带的丰富信息的利用率。
表4分别在KSC、Pavia U数据上使用CNN-灰度图、CNN-波形图、线性核支持向量机、RBF核支持向量机、PCA变换支持向量机、自动编码与逻辑回归SAE-LR方法进行分类,并对比分类结果。以上两个表格中给出了每一种方法分类的平均正确率和总体正确率,并分别给出了两个数据集中所有细分种类的分类正确率,为了使结果更清晰,在发明提出的分类方法取得最佳结果处用粗体进行显示。
基于卷积神经网络的谱信息灰度图像的分类方法在Pavia U数据集上取得的正确率超越了基于支持向量机的分类方法;然而,在KSC数据集上的表现却差强人意,究其原因, 在于所选择的网络层数和参数都是基于最稳定均衡来考虑,而不是在每一个数据集下取得的最优结果的网络层数和参数。另外,卷积神经网络是一个概率模型,其分类正确率大体随着分类种类的增加而减少。
设计的优势
(1)将一维数据转换成二维数据,可以容纳更大的数据量和光谱维度。
(2)通过此方法,提高了高光谱图像的分类正确率。
(3)利用GPU缩短了分类过程所用的时间。
(4)利用深度卷积网络自主学习数据的抽象特征,避免使用欠缺逻辑的数据模型。
本实施方式利用Matlab对数据进行预处理,将一维数据转换成为二维灰度图片数据,通过Caffe平台和Linux操作系统实现卷积神经网络模型对变换后的高光谱数据进行分类,并利用了GPU对实验进行加速,以减少庞大计算量带来的运算时间消耗,缩短分类所用时间。
具体实施方式二:本实施方式与具体实施方式一不同的是:步骤一一中所述对高光谱原始数据进行预处理具体为:对高光谱原始数据进行逐层归一化:
式中,为归一化后的高光谱数据;为第k层(i,j)位置的高光谱原始数据;W为高光谱原始数据的宽度;L为高光谱原始数据的长度;H为高光谱原始数据的深度;W、L、H取值为正整数;
本发明的归一化方式选择逐层内部线性归一化,原因有二:其一,将数据归一化0~1范围内,便于后续将数据imwrite成图片;其二,由于高光谱的成像原理,不同谱段的数据范围差异过大,在抽取像元波谱并转置成图像后,会导致部分谱段信息被忽略。其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:步骤一二中组成一维向量数据具体为:
其中,为深度H在(i,j)位置的高光谱原始数据;为归一化后的高光谱数据中位于(i,j)位置像元的波谱向量。其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:步骤二中对灰度图像数据样本进行分类具体为:
利用卷积神经网络(CNN)来对灰度图像的小样本数据进行分类;对分类效果进行分析,最后完成基于CNN的光谱图像分类与其他方法的比较;样本数据包括小样本数据和大样本数据。其它步骤及参数与具体实施方式一至三之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例基于卷积神经网络的高光谱数据转灰度图的高光谱数据分类方法,该方法具体是按照以下步骤制备的:
步骤一、对高光谱原始数据进行预处理得到高光谱的谱向量,将高光谱的谱向量数据转换成为灰度图像数据;(卷积神经网络的输入需要二维图像数据),为将卷积神经网络应用在高光谱数据分类任务中;
下面通过对数据预处理过程的解读来介绍基于卷积神经网络的谱信息转换成灰度图像的分类方法。数据预处理过程如图1所示:
步骤一一、对高光谱原始数据进行逐层归一化,得到归一化后的高光谱数据;
所述对高光谱原始数据进行预处理具体为:对高光谱原始数据进行逐层归一化:
式中,为归一化后的高光谱数据;为第k层(i,j)位置的高光谱原始数据;W为高光谱原始数据的宽度;L为高光谱原始数据的长度;H为高光谱原始数据的深度;W、L、H取值为正整数;
本发明的归一化方式选择逐层内部线性归一化,原因有二:其一,将数据归一化0~1范围内,便于后续将数据imwrite成图片;其二,由于高光谱的成像原理,不同谱段的数据范围差异过大,在抽取像元波谱并转置成图像后,会导致部分谱段信息被忽略。
步骤一二、抽取归一化后的高光谱数据中每一个像元的全波段值,将每一个像元的全波段值组成一维向量数据具体为:
其中,为深度H在(i,j)位置的高光谱原始数据;为归一化后的高光谱数据中位于(i,j)位置像元的波谱向量。
步骤一三、在归一化后的高光谱数据中其他像元重复步骤一二遍历,共提取出W×L个1×H的一维像元波谱向量即得到高光谱的谱向量;
高光谱图像数据分类是以像素为目标进行的,提取出的一维向量即代表了某像元在全波谱段的数据信息。
步骤一四、将高光谱的谱向量中每一个像元的波谱向量即1×H的一维向量均转置成为二维矩阵得到W×L个二维矩阵,并将W×L个二维矩阵imwrite(imwrite是matlab中的一个函数)保存成为含有W×L张灰度图片的样本集即灰度图像数据,样本集中每一张图片代表了某像元的全波谱段信息,单张图片的某个像素点代表着该像元在特定波段下的数据值表征。整张图片的纹理特征极为明显,足以对该目标像元的数据信息进行表达,且其纹理特征也反应出了数据层间信息的变化;
步骤二、通过卷积分类模型自主学习样本集中样本的纹理特征,对灰度图像数据样本进行分类;
利用卷积神经网络(CNN)来对50~200个灰度图像的小样本数据进行分类;对分类效果进行分析,最后完成基于CNN的光谱图像分类与其他方法的比较。
实验方案及数据预处理结果
实验部分拟用到的高光谱数据库分别为:KSC、Pavia U、Indianpines。
利用本发明介绍的基于CNN的高光谱数据分类方法,本实施例通过在小训练样本时基于CNN方法的分类正确率与KNMF、RBF SVM方法进行比较,分析基于CNN的方法在小训练样本时的表现情况。之后采取6:2:2数据样本划分比例进行试验,通过对比实验进行基于CNN方法在高光谱数据分类方面的分类能力的研究,实验中所有生成的训练集、验证集、测试集中的图片均为随机分配。
经过一系列预处理得到的灰度图像具有明显的纹理特征和波动特征,以Indianpines数据集的预处理结果为例,其灰度图的可视化结果如图4(a)~(e):
小样本分析
为了分析基于卷积神经网络的分类模型对训练样本数量的敏感性,进行下列实验。首先比较基于CNN的两种方法与KNMF、RBF SVM等方法在小训练样本时的表现情况,实验在上文提到过的Pavia U数据集与KSC数据集上进行,每个类别的训练样本个数选为50,100,150,200个进行试验。KSC实验结果如表1所示,将其绘制成折线图为图2。Pavia U实验结果如表2所示,将其绘制成折线图为图3。
表1 KSC数据上CCN与各方法的总体正确率对比
表2 Pavia U数据上CNN与各方法的总体正确率对比
从表1和图2中可以看到在KSC数据集上CNN的两种方法、KNMF、RBF-SVM的总体正确率都随着训练样本的增加而增加。在这之中当训练样本为50时RBF-SVM的效果依然是最好的,CNN的灰度图法,KNMF与RBF-SVM的训练结果随着训练样本的增大,其上升的趋势基本相同,其每一种训练样本个数均相差无几,这是因为虽然这时每一类训练样本单独来看很少,但KSC数据集本身有效样本就很少,在每一类取200为训练样本时,其占总体比例已经很大,所以这时与RBF-SVM等方法相差无几。
从表2和图3可以看到在Pavia U数据集上,CNN,KNMF与RBF-SVM方法的总体正确率都随着训练样本的增加而增加。在这之中当训练样本为50时CNN灰度图法的效果是最好的,但RBF-SVM的训练结果随着训练样本的增大上升的最快,当训练样本增大到100时RBF SVM的总体正确率已经与CNN灰度图持平。在下一节Pavia U数据集采用6:2:2的方式划分时由于训练样本已经很大,可以看到CNN的方法将会超过RBF-SVM的方法。
综合以上实验,由于CNN是以概率模型为基础的,比起采取小样本数据,采取大的样本数据量、增加输入信息量才更能发挥基于卷积神经网络的高光谱分类方法的优势。
与传统分类方法对比
为了进行对比实验,在最终选择的五层网络的基础上调整网络的各项参数,经过训练得到一个有稳定性能的CNN分类模型,将其分别与在高光谱图像分类表现较好的线性核 SVM、近期提出的基于自动编码机模型SAE-LR、RBF核的支持向量机模型RBF-SVM等分类方法进行对比。CNN分类模型将通过20000次迭训练后对测试数据进行分类。
表3 KSC数据集上各种分类算法正确率统计
表3、表4分别在KSC、Pavia U数据上使用CNN-灰度图、CNN-波形图、线性核支持向量机、RBF核支持向量机、PCA变换支持向量机、自动编码与逻辑回归SAE-LR方法进行分类,并对比分类结果。以上两个表格中给出了每一种方法分类的平均正确率和总体正确率,并分别给出了两个数据集中所有细分种类的分类正确率,为了使结果更清晰,在发明提出的分类方法取得最佳结果处用粗体进行显示。
表4 Pavia U数据集上各种分类算法正确率统计
基于卷积神经网络的谱信息灰度图像的分类方法在Pavia U数据集上取得的正确率超越了基于支持向量机的分类方法;然而,在KSC数据集上的表现却差强人意,究其原因,在于所选择的网络层数和参数都是基于最稳定均衡来考虑,而不是在每一个数据集下取得的最优结果的网络层数和参数。另外,卷积神经网络是一个概率模型,其分类正确率大体随着分类种类的增加而减少。
设计的优势
(1)将一维数据转换成二维数据,可以容纳更大的数据量和光谱维度。
(2)通过此方法,提高了高光谱图像的分类正确率。
(3)利用GPU缩短了分类过程所用的时间。
(4)利用深度卷积网络自主学习数据的抽象特征,避免使用欠缺逻辑的数据模型。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!