基于智能眼镜的视障辅助中文文本阅读系统的制作方法
本发明属于模式识别与人工智能技术领域,特别是涉及基于智能眼镜的视障辅助中文文本阅读系统。
背景技术:
以智能眼镜为代表的可穿戴设备极大拓宽了消费电子产品市场的规模。谷歌公司于2012年发布的谷歌眼镜受到了业界的广泛关注,极大激发了业界对可穿戴设备的兴趣,掀起了可穿戴技术革新的浪潮。众多科技龙头企业和初创团队纷纷紧跟潮流,Facebook以20亿美元的天价并购了Oculus,三星内部将Gear glass视为重点项目,微软在2015年1月发布的Hololens更将智能眼镜的发展推向了又一个高潮,该款全息眼镜将虚拟与现实有机结合,实现了更丰富的交互性。预计在未来的几年内,智能眼镜将成为可穿戴设备市场中应用最为广泛的产品之一。对智能眼镜来说,目前最大的挑战是如何实现更好的交互性能,能否有效提升交互效率,直接关系着智能眼镜能否大规模进入消费市场。以语音控制为例,开发者必须考虑可能出现的各种情况,例如不同语种和方言的差异。随着种类丰富的可穿戴产品的不断推出,可穿戴设备市场的规模不断扩大,产业的活跃度得到了极大提升。在可预见的未来,可穿戴产品极有可能成为继平板电脑和智能手机后,全球科技产业新的爆发增长点。
技术实现要素:
本发明旨在提升视力不佳者的生活质量,借助智能眼镜实现包括文本识别、语音传输在内的多种功能,提供基于智能眼镜的视障辅助中文文本阅读系统。该系统采用高清摄像头进行文本图像采集,能够快速、精确地提取和识别文字信息,并且将识别出来的文本信息用语音方式反馈给使用者。
本发明采用的技术方案如下。
基于智能眼镜的视障辅助中文文本阅读系统,其包括高清摄像头、扬声器、蓝牙、安卓手机、头戴式微型显示屏、条状电脑处理器、高性能大容量电池和太阳能电池;所述包括高性能大容量电池、太阳能电池、高清摄像头、扬声器、蓝牙、头戴式微型显示屏均位智能眼睛中并分别与条状电脑处理器连接,安卓手机通过自身的蓝牙功能与所述蓝牙连接,高性能大容量电池和太阳能电池为系统的各构成部分供电;所述高清摄像头用于实现自然场景图像的采集,并将图像传输到智能眼镜中保存;使用者只需带上眼镜,打开眼镜开关,由智能眼镜的图像采集模块触发摄像头,进行自然场景图像采集;
所述蓝牙实现与手机的短距离通信,使用者打开手机蓝牙模块,与智能眼镜的蓝牙配对,通过手机端App发送操作命令给智能眼镜;所述扬声器实现将场景文本识别结果传输给使用者;所述安卓手机实现对智能眼镜的控制,通过发送指令操作智能眼镜;所述头戴式微型显示屏,实现对处理后信息的投放,便于使用者观看;所述条状电脑处理器,对图像信息进行处理并控制系统中各构成部分的工作。
进一步地,所述安卓手机包括App控制模块、图像文字识别模块、语言传输模块和蓝牙传输模块;通过手机上的蓝牙模块与智能眼镜进行通信,其中App控制模块上的功能包括开启、关闭智能眼镜和选择省电模式、工作模式;安卓手机的图像文字识别模块对自然场景图像中的文本进行处理;图像文字识别模块采用了端对端的文本识别方法进行自然场景文本的识别,其中端对端是针对场景文字识别中文本检测与字符识别的关系而言;图像文字识别模块首先基于滑动窗口对图像进行分割,利用卷积神经网络CNN模型进一步识别分割区域中是否包含文本信息,图像文字识别模块还对输入的原图像进行归一化和随机变形处理,用以增强定位效果,将处理后的图像输入卷积神经网络CNN模型,该卷积神经网络CNN模型结构为:第一层卷积层,采用5*5大小的卷积核;第一max_pooling层,采用2*2的核,第二层卷积层,采用3*3的卷积核;第二max_pooling层,采用2*2的核,随后的三、四、五卷积层,都采用3*3的卷积核;第五max_pooling层,采用2*2的核;第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入;第二层全连接:4096维;最后Softmax层:输出为1000;若分割区域中包含文本信息,则判断其周围是否也含有文本信息,将文本信息合并起来,然后使用另一个训练好的CNN卷积模型识别定位的文本区域,该CNN模型与文本定位过程使用的CNN模型相似,最后将识别结果信息返回保存;
所述语言传输模块将识别出来的文本用语音的方式传递给使用者,或当使用者开启导航模式时,实时推送给使用者;语言传输模块接入百度语音API,使用中文描素使用者看到的文本;若使用者觉得语音模块意义不大,那也能在App上关闭语音功能或者在智能眼睛上关闭语音功能按钮;
手机的蓝牙传输模块通过对系统的蓝牙进行数据传输,完成与手机的通信功能。
进一步地,使用者将通过安卓手机App控制模块或者操作智能眼镜来选择模式,模式有两种状态,一种是待机模式,就是会关闭所有的智能功能,在这种状态下,智能眼镜和普通镜一样;当选择在工作模式的状态下,使用者能自主选择关闭或者打开智能眼镜的任何一个功能;然后系统根据使用者的选择,调整智能眼镜的功能,智能眼镜对外部输入的信息进行处理,处理的信息包括图像信息、位置信息;信息处理完成后,把输出的结果呈现给使用者。
进一步地,图像处理模块接收到自然场景图像后,将利用滑动窗口分割图像、滑动窗口的大小为16*16,对整张图片从起点开始进行分割,利用训练好的文本定位模型对图像进行识别,判断是否含有文本信息,如果有,再对相邻区域进行判断,如果有,就对这两个图像信息进行合并,直至合并区域超过阈值。然后借助之前训练的识别模型对合并后的区域进行,最后将结果输出给使用者。
本发明与现有智能眼镜的设计相比,具有如下优点:
(1)利用高清摄像头进行自然场景图像的采集,蓝牙传输,系统结构简单,使用方便,硬件成本低。不同的智能眼镜有其相应的配套功能,同时,为了保证系统运行速度,同种智能眼镜在不同工作模式下可移除不必要的功能触发和后台运行,有效减少系统功耗,增强系统使用效率。
(2)由于加入了图像文本识别模块,本发明在特定的场合应用具有极大的优势,视力不佳者使用这样的发明,可直接以语音方式获取识别结果,或者借助本发明来实现环境感知及定位,为出行带来极大的便利。
(3)本发明具备价格低廉、性价比高、实用性强、适应性广等特点,在可穿戴产品市场上具备一定的竞争力,能够推动可穿戴设备进一步发展。
附图说明
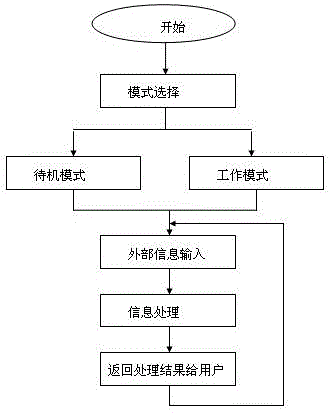
图1是实例中基于智能眼镜的视障辅助中文文本阅读系统的工作流程图。
图2是实例中的文本识别流程图。
具体实施方式
下面结合附图对本发明作进一步具体地描述,但本发明的实施方式不限于此。
基于智能眼镜的视障辅助中文文本阅读系统,包括高清摄像头、扬声器、蓝牙、安卓手机、头戴式微型显示屏、条状电脑处理器、高性能大容量电池和太阳能电池;所述包括高性能大容量电池、太阳能电池、高清摄像头、扬声器、蓝牙、头戴式微型显示屏均位智能眼睛中并分别与条状电脑处理器连接,安卓手机通过自身的蓝牙功能与所述蓝牙连接,高性能大容量电池和太阳能电池为系统的各构成部分供电。
所述高清摄像头实现自然场景图像的采集,并将图像传输到高性能智能眼镜中保存。使用者只需带上眼镜,打开眼镜开关,由图像采集模块触发摄像头,进行自然场景图像采集,并保存到系统中。
所述蓝牙实现与手机的短距离通信,使用者打开手机蓝牙模块,与智能眼镜的蓝牙配对,通过手机端App发送相关的操作给智能眼镜。所述扬声器实现将场景文本识别结果传输给使用者。所述安卓手机实现对智能眼镜的控制,通过发送指令操作智能眼镜。所述头戴式微型显示屏,实现对处理后信息的投放,便于使用者观看。
所述为高性能大容量电池+太阳能电池,为整个硬件设备提供电源供电。在阳光充足的情况下,备用太阳能电池的配合充电,可有效地增加智能眼镜的供电时间,从而降低主电池的容量和体积,在阴雨天气的时候,可以借助于高性能大容量电池来供电。
通过手机上的蓝牙模块与智能眼镜进行通信,其中App控制模块上的功能包括开启、关闭智能眼镜和选择工作模式(省电模式、工作模式)。
手机的图像文字识别模块对自然场景图像中的文本进行处理。传统的自然场景文本识别系统采取矫正、定位、分割、识别四步实现功能,在文本的定位上存在一定的缺陷,为了改善这一缺陷,图像文字识别模块采用了端对端的文本识别系统进行自然场景文本的识别。其中端对端是针对场景文字识别中文本检测与字符识别的关系而言,强调字符识别系统功能的完整性。系统首先基于滑动窗口对图像进行分割,利用CNN进一步识别分割区域中是否包含文本信息,此处系统对输入的原图像进行归一化和随机变形处理,用以增强定位效果,将处理后的图像输入CNN模型,该模型结构为:第一层卷积层,采用5*5大小的卷积核,第一层max_pooling层,采用2*2的核,第二层卷积层,采用3*3的卷积核,第二层max_pooling层,采用2*2的核,随后的三、四、五卷积层,都采用3*3的卷积核,第五层max_pooling层,采用2*2的核,第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。第二层全连接:4096维,最后Softmax层:输出为1000。若分割区域中包含文本信息,则判断其周围是否也含有文本信息,将文本信息合并起来,然后使用另一个训练好的CNN卷积模型识别定位的文本区域,该CNN模型与文本定位过程使用的CNN模型相似,最后将识别结果信息返回保存。
所述语言传输模块需要将识别出来的文本用语音的方式传递给使用者,或当使用者开启导航模式时,实时推送给使用者。该发明接入百度语音API,使用中文描素使用者看到的文本。若使用者觉得语音模块意义不大,那也可在App上关闭语音功能或者在智能眼睛上关闭语音功能按钮。
手机的蓝牙传输模块通过对系统的蓝牙进行数据传输,完成与手机的通信功能。首先开启蓝牙的可检测功能,用手机搜索蓝牙设备,并创建蓝牙socket,由socket获取device,然后进行数据通信,不使用蓝牙时关闭蓝牙模块,以免耗电过大。
图1是本文本阅读辅助系统的工作流程示意图。由图1可知,工作流程为:使用者启动硬件和软件系统后,系统处于选择模式状态,使用者通过操作手机App或智能眼镜来选择模式,待机模式会关闭所有的智能功能,在这种状态下,智能眼镜和普通眼睛一样;工作模式下,使用者可以自主选择关闭或者打开智能眼镜的任何一个功能。系统根据使用者的选择,调整智能眼镜的功能,智能眼镜在对外部输入信息进行处理后,将输出结果呈现给使用者。
图2为本实例的自然场景文本识别模块的流程图。由图2可知,图像自然场景文本识别模块的工作流程为:在图像处理模块接收到自然场景图像后,将利用滑动窗口分割图像、滑动窗口的大小为16*16,对整张图片从起点开始进行分割,利用训练好的文本定位模型对图像进行识别,判断是否含有文本信息,如果有,再对相邻区域进行判断,如果有,就对这两个图像信息进行合并,直至合并区域超过阈值。然后借助之前训练的识别模型对合并后的区域进行,最后将结果输出给使用者。
上述实例为本发明较佳的实施例子,但本发明的实施方式并不受上述实例的限制,其他的任何未背离本发明的精神与技术下所作的改变、修饰或替代,均应为等效的置换,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!