一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法与流程
本发明属于电磁信号处理领域,涉及一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法。
背景技术:
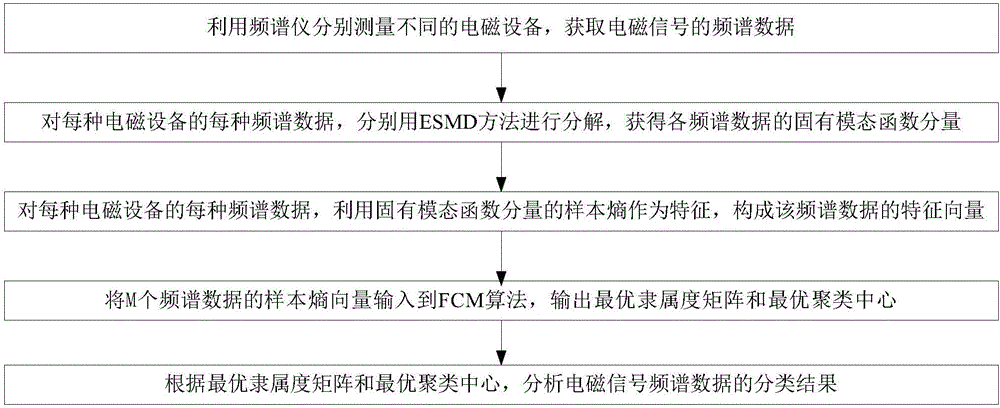
:电子信息技术的发展极大地促进了科技的进步,但是日益增多的电子设备同时也造成了严重的电磁干扰问题,导致环境中电子设备正常的工作性能下降。为了减轻电磁干扰,一般设计电磁兼容,找出电磁信号频谱中的各类数据。通过对电磁信号频谱数据进行分类,分析电磁干扰的来源,具有良好的辅助作用。当前,电磁信号的分类主要针对时域的数据,直接用来分析频谱数据具有一定的局限性。关于数据的提取,文献[1]:广州:华南理工大学,曾作钦.基于奇异值分解的信号处理方法及其在机械故障诊断中的应用[D]中将Hankel矩阵的奇异值作为数据的特征,取得了一定的效果。但是该方法中对嵌套窗口的选择偏主观,不同的选择结果差异较大。文献[2]:震动与冲击,2012,31(19):21-25.黄林洲等.EMD近似熵结合支持向量机的心音号识别研究[J].中选择近似熵作为数据特征。但是近似熵几乎完全依赖于信号数据的长度,会导致前后不一致的计算结果。相比,固有模态函数的样本熵(SampleEntropy)能够全面地刻画出电磁信号频谱数据的内在复杂性特征。提取了数据特征之后,建立信号数据特征空间的基础,将提取的数据特征输入分类算法,利用分类算法依据不同的数据特征进行分类。现有的分类算法中,K均值算法简单易行,但是如果它的初始值选得不恰当,将很难获得理想的聚类结果。人工神经网络方法能够在短时间内确定最优分类结果,但是其需要充分多的样本,这个条件往往在实际中难以得到满足。相比目前比较成功的对数据进行分类的经典方法:模糊C均值(FCM)算法,通过极小化数据点与各个聚类中心的欧氏距离及模糊隶属度的加权和,将具有相似特征的数据样本聚为一类。极值点对称模态分解方法(ESMD)能够自适应地分解非线性非稳定的电磁频谱数据,克服了传统方法如小波分解方法仅适用于线性数据的缺点。将ESMD样本熵结合FCM算法结合起来对非线性非稳定的电磁信号频谱数据进行分类,能够克服传统分类方法只适用于线性稳定数据的缺点,能够根据已提取出的频谱数据特征客观地给出分类结果。技术实现要素:本发明针对现有的电磁信号频谱数据分类方法的不足,提出一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法。具体步骤如下:步骤一、利用频谱仪分别测量不同的电磁设备,获取电磁信号的频谱数据;每种电磁设备的频谱数据均包括设备正线和设备负线两种数据;所有的频谱数据数量为M。步骤二、对每种电磁设备的每种频谱数据,分别用ESMD方法进行分解,获得各频谱数据的固有模态函数分量;具体为:步骤201、针对某种频谱数据s,获取全部极大值点和极小值点,并用直线连接相邻的极大值点和极小值点,得到一系列极值点的中点;频谱数据s中的数据点数量为N;中点为相邻极大值点和极小值点的中间值;步骤202、针对所有中点进行三次样条插值得到均值曲线X*;步骤203、判断均值曲线X*的幅值|X*|是否小于给定精度τ,如果是,进入步骤204,否则进入步骤205;步骤204、X*为频谱数据s的一个固有模态函数分量;X*的数据点数量为N;步骤205、计算s*=s-X*作为新的频谱数据,返回步骤201,重新获取固有模态函数分量;最终频谱数据s得到的固有模态函数分量为L个,L≤log2N。步骤三、对每种电磁设备的每种频谱数据,利用固有模态函数分量的样本熵作为特征,构成该频谱数据的特征向量;具体步骤如下:步骤301、针对频谱数据s中,某个固有模态函数分量X*的所有数据点,构成r维数据点列集合Q(I);r是指每维数据点列Q(i)的长度,也就是每个Q(i)中的数据点个数。数据点列集合Q(I)的数据点列个数为N-r+1。步骤302、依次选取数据点列集合Q(I)中的数据点列Q(i)作为当前数据点列,分别与其余所有数据点列一一做差;当前数据点列Q(i)初始值为Q(1);步骤303、将每次作差的两个数据点列作为一组,将该组中的数据点分别一一对应作差,并选择最大差值作为当前两个数据点列之间的距离;当前两个数据点列分别为Q(i)和Q(j)时的距离d(Q(i),Q(j))计算公式如下:d(Q(i),Q(j))=maxk∈[0,r-1](|P(i+k)-P(j+k)|)步骤304、确定与当前数据点列Q(i)的距离d(Q(i),Q(j))≤d0的Q(j)数目Ki;1≤Ki≤N-r;步骤305、计算所有Ki与N-r+1的比值并计算平均值Rr(d0);步骤306、利用平均值Rr(d0)计算该固有模态函数分量X*的样本熵SP(r,d0,N);步骤307、重复上述步骤,计算频谱数据s的所有固有模态函数分量的样本熵向量SE作为频谱数据s的特征向量;SE=[SP1,...,SPL]步骤四、将M个频谱数据的样本熵向量SamEn=[SE1,...,SEM]输入到FCM算法,输出最优隶属度矩阵和最优聚类中心;步骤五、根据最优隶属度矩阵和最优聚类中心,分析电磁信号频谱数据的分类结果。本发明具有以下显著优点:1)、一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法,对提取的电磁信号频谱数据进行ESMD分解,而获得各个固有模态函数;与EMD方法相比,ESMD方法具有更好的自适应性。2)、一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法,利用固有模态函数的样本熵作为频谱数据的特征,能充分地度量出频谱数据的复杂程度;与近似熵相比,样本熵具有更加一致的计算结果。3)、一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法,FCM算法能有效地建立频谱数据对类别的不确定性描述,与K均值算法和人工神经网络算法相比能够更加客观地对频谱数据进行分类。附图说明图1为本发明一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法的流程图;图2为本发明对频谱数据用ESMD方法分解得到固有模态函数分量的流程图;图3为本发明利用固有模态函数分量的样本熵作为特征构成特征向量的流程图;图4为本发明笔记本电脑负线的电磁频谱数据的各个固有模态函数。具体实施方式下面将结合附图对本发明作进一步的详细说明。本发明一种ESMD样本熵结合FCM的电磁信号频谱数据分类方法,利用ESMD方法首先分解电磁信号的频谱数据获得固有模态函数,再计算出固有模态函数的样本熵作为数据的特征,最后利用FCM产生分类结果;如图1所示,具体步骤如下:步骤一、利用频谱仪分别测量不同的电磁设备,获取电磁信号的频谱数据;每种电磁设备的频谱数据均包括设备正线和设备负线两种数据;所有的频谱数据数量为M。步骤二、对每种电磁设备的每种频谱数据,分别用ESMD方法进行分解,获得各频谱数据的固有模态函数分量;如图2所示,具体为:步骤201、针对某种频谱数据s,获取全部极大值点和极小值点,并用直线连接相邻的极大值点和极小值点,得到一系列极值点的中点;频谱数据s中的数据点数量为N;极大值点或极小值点用Gi(1≤i≤N)表示,中点Mi(1≤i≤N-1)为相邻极大值点和极小值点的中间值;步骤202、针对所有中点,构造三次样条插值曲线X1,...,Xn及均值曲线X*;X*=(X1+...+Xn)/n;n≥1步骤203、判断均值曲线X*的幅值|X*|是否小于给定精度τ,如果是,进入步骤204,否则进入步骤205;步骤204、X*为频谱数据s的一个固有模态函数分量;X*的数据点数量为N;步骤205、计算s*=s-X*作为新的频谱数据,返回步骤201,重新获取固有模态函数分量;最终得到频谱数据s的固有模态函数分量为L个;L≤log2N。步骤三、对每种电磁设备的每种频谱数据,利用固有模态函数分量的样本熵作为特征,构成该频谱数据的特征向量;对于任意固有模态函数分量X*,设其数据点为{P(i),1≤i≤N};如图3所示,样本熵的计算步骤如下:步骤301、针对频谱数据s中,某个固有模态函数分量X*的所有数据点,构成r维数据点列集合Q(I);数据点列集合Q(I)的数据点列个数为N-r+1;1≤i≤N-r+1;r是指每维数据点列Q(i)的长度,也就是每个Q(i)中的数据点个数。步骤302、依次选取数据点列集合Q(I)中的数据点列Q(i)作为当前数据点列,分别与其余所有数据点列一一做差;当前数据点列Q(i)初始值为Q(1);步骤303、将每次作差的两个r维向量数据点列作为一组,将该组中的数据点分别一一对应作差,并选择最大差值作为当前两个数据点列之间的距离;当前两个数据点列分别为Q(i)和Q(j)时的距离d(Q(i),Q(j))计算公式如下:d(Q(i),Q(j))=maxk∈[0,r-1](|P(i+k)-P(j+k)|)步骤304、确定与当前数据点列Q(i)的距离d(Q(i),Q(j))≤d0的Q(j)数目Ki;针对数据点列Q(i),当Q(i)与其余所有数据点列一一做差后,寻找差值距离小于等于给定距离常量d0的数据点列组,得到数目Ki;1≤Ki≤N-r;N-r+1个数据点列的所有数目集合为:[K1,K2,...Ki,...KN-r+1]。步骤305、计算所有Ki与N-r+1的比值并计算平均值Rr(d0);步骤306、利用平均值Rr(d0)计算该固有模态函数分量X*的样本熵SP(r,d0,N);步骤307、重复上述步骤,计算频谱数据s的所有固有模态函数分量的样本熵向量SE作为频谱数据s的特征向量;SE=[SP1,...,SPL]第四步:将M个频谱数据的样本熵向量SamEn=[SE1,...,SEL]输入到FCM算法,输出最优隶属度矩阵和最优聚类中心;具体步骤为:步骤401、初始化频谱数据的分类数目、迭代精度和权重比例,每类频谱数据的聚类中心和隶属度矩阵;频谱数据的分类数目为k,迭代精度为ε和权重比例为ω;每类频谱数据的聚类中心Cm(1≤m≤k);利用0和1之间的随机数初始化隶属度矩阵H=[hmn],其中hmn是第n个特征向量xn隶属于第m类的隶属度,且步骤402、更新隶属度矩阵H和聚类中心Cm;dmn=||Cm-xn||表示第m个聚类中心Cm和第n个特征向量xn之间的欧几里得距离;Ct为第t个聚类中心;是隶属度hmn的ω次方。步骤403、根据更新的隶属度矩阵H和聚类中心Cm计算目标函数Jz(H,C):z表示优化迭代的第z步。步骤404、判断相邻优化迭代的目标函数之间的差是否满足:|Jz(H,C)-Jz-1(H,C)|<ε,如果是,则第z步结果为迭代的最优解,输出最优隶属度矩阵H*和最优聚类中心矩阵C*。否则,返回步骤402直到满足迭代终止条件。第五步:根据FCM算法产生的最优隶属度矩阵H*和最优聚类中心,分析电磁信号频谱数据的分类结果。【实施例】第一步:利用频谱仪分别测量实际电磁环境中的4种设备,获得8组长度均为1024的电磁信号频谱数据,实测设备电磁信号的频谱数据如表1所示。表1电磁设备频谱数据笔记本电脑负线s1笔记本电脑正线s2台式电脑负线s3台式电脑正线s4吹风机负线s5吹风机正线s6打印机负线s7打印机正线s8第二步:对每种频谱数据分别进行ESMD分解,获得各频谱数据的固有模态函数分量;对以上8组电磁信号的频谱数据分别进行ESMD分解,得到8组固有模态函数,每组均包含10个固有模态函数分量。频谱数据s1的10个固有模态函数分量如图4所示;第三步:对4种电磁设备的8种频谱数据,分别计算每种频谱数据的固有模态函数分量的样本熵构成8种频谱数据的特征向量;从图4可以看出,其主要特征体现在前6个固有模态函数分量中;因此只计算前6个固有模态函数分量的样本熵来构成各个电磁信号频谱数据的特征向量。分别计算每种电磁信号频谱数据的前6个固有模态函数(IMF)分量的样本熵,结果如表2所示。表2第四步:将8种频谱数据固有模态函数分量的特征向量,输入FCM算法进行分类,输出分类结果;电磁信号频谱数据的分类结果如表3所示;表3设备第1类第2类第3类第4类第5类笔记本电脑负线0.01010.96350.01550.00320.0077笔记本电脑正线0.00930.95980.02520.00460.0011台式电脑负线0.00890.00310.00210.00470.9812台式电脑正线0.00860.00300.00280.00230.9833吹风机负线0.95990.00670.00950.00610.0178吹风机正线0.96050.00780.00620.00800.0175打印机负线0.01010.01180.00190.97040.0058打印机正线0.00960.01230.00260.97300.0025第五步:结果分析:根据FCM算法的基本原理,表中的元素越接近于1,表明该元素所在行对应的频谱数据与其所在列对应的类别相关程度越高。表3表明,笔记本电脑的正负线与第2类的相关程度分别为0.9598和0.9635,十分接近于1,因此将其归为第1类频谱数据。类似地,表3给出了其他3类频谱数据的对应关系。此方法的分类结果与电磁信号频谱数据的情况完全吻合。因此,本发明的方法能够有效地对电磁信号的频谱数据进行分类。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1