一种加密云数据下基于Simhash的模糊排序搜索方法与流程
本发明涉及模糊排序搜索领域,特别是涉及一种加密云数据下基于Simhash的模糊排序搜索方法。
背景技术:
云计算的发展使得越来越多的用户将自己的数据外包给云服务器,并享受方便快捷的服务。但云服务器不是完全可信的,可能会对用户的数据隐私产生很大的威胁。为了保障敏感数据不被泄露,用户会先对数据进行加密,再将数据存储到云服务器。然而数据加密使得高效的数据利用成为挑战,如何在密文数据中检索用户感兴趣的资料成为亟待解决的问题。可搜索加密技术就是为了解决密文检索的难题而提出的。该技术是指用户将加密后的数据存储到云服务器中,云服务器可以根据用户提交的关键词陷门进行搜索,并返回相关文档给用户,而不泄露相关的明文信息。
最早提出的可搜索加密方案,为解决密文检索的问题提供了思路,引起了学术界的普遍关注。随后提出为文档创建索引来提高检索效率,每个索引中包含了一篇文档的关键词陷门信息;以及构造了加密的哈希表索引,表中包含关键词陷门和关键词的文档标识集合;以及提出了关键词排序搜索方案,主要通过对相关度分数进行保序加密,实现对搜索结果的精确排序;并引入向量空间模型和安全KNN(secure k-nearest neighbor)方法,提出了多关键词排序可搜索加密方案,通过矩阵对索引向量进行加密,对索引向量和搜索向量计算内积相似度,实现了对搜索结果的排序;再通过引入双线性对的方式,提出了公钥可搜索加密方案,利用公钥可以加密文档并生成索引,私钥拥有者可以生成关键词陷门并进行搜索。
然而以上方案只支持关键词精确搜索,在实际应用中,用户输入的搜索请求经常会出现拼写错误或格式不匹配的情况。随后提出了密文关键词模糊搜索,主要是利用通配符构造关键词模糊集合;随后提出了更加节省存储空间的克方法来构造模糊集合,并引入符号索引树提高搜索效率;通过基于字典的模糊集构造方案,虽然减少了模糊集的存储开销,但是却降低了搜索精确度;通过提取索引树结构的路径信息,实现了可验证的模糊搜索方案。然而在这些模糊搜索方案中,需要对每个关键词构造模糊集合,这些模糊集合将占用云服务器大量的存储空间。例如,在基于通配符的模糊集构造方法中,随着编辑距离的增加,模糊集合的大小会呈指数增长,因此构造模糊集合会耗费大量的计算和存储开销。并且这些方案只能通过编辑距离对搜索结果进行排序,排序效果比较粗糙,无法返回精确的搜索结果。虽然在一些方案中提到引入布隆过滤器可以有效减少存储空间,但由于针对模糊集合中的每个关键词,都需要用多个哈希函数来将其插入到布隆过滤器中,因此会增加计算开销。
起先Simhash算法这个技术运用于海量网页的去重,随后也被运用到可搜索加密领域,但主要是针对整篇文档生成指纹索引。由于该指纹索引是由文档的多个关键词映射得到的,因此如果只用一个或者少量关键词进行查询会出现较大误差,所以并不适用于关键词搜索。
技术实现要素:
有鉴于此,本发明的目的是提供一种加密云数据下基于Simhash的模糊排序搜索方法,可以减少索引存储空间,并实现精确排序的密文关键词模糊搜索。
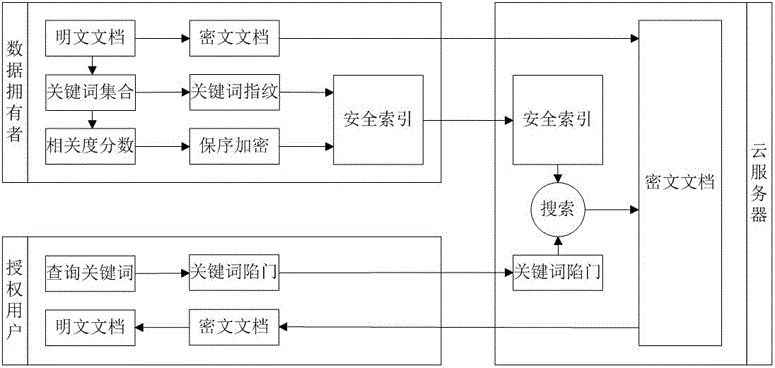
本发明采用以下方案实现:一种加密云数据下基于Simhash的模糊排序搜索方法,所述方法中包括数据拥有者,授权用户和云存储服务器,具体模糊排序搜索方法包括以下步骤:
步骤S1:输入一个安全参数λ,生成文档加密密钥sk、单向哈希函数h的密钥hk;将密钥sk、hk发送给授权用户;
步骤S2:数据拥有者从文档集合F=(f1,f2,…,fm)中抽取关键词集合W=(w1,w2,…,wn),通过基于Simhash的关键词指纹生成算法sim(hk,wi),生成每个关键词wi∈W对应的指纹Si,并为每篇文档创建唯一的文档标识符FIDj,(1≤j≤m);计算关键词在文档中的相关度分数Scorej,并对其进行保序加密OPE(ek,Scorej);
步骤S3:每一个授权用户都能够获得数据拥有者分发的密钥hk;当授权用户需要搜索感兴趣的关键词w时,首先通过关键词指纹生成算法sim(hk,w)计算关键词w的指纹值,该指纹值即陷门Tw;然后将产生的陷门Tw提交至云存储服务器进行查询;
步骤S4:云存储服务器在接收到授权用户的搜索请求后,根据双因子排序方法对搜索结果进行排序,将top-k篇密文文档的集合C'=(c1,c2,…,ck)返回给用户;
步骤S5:授权用户使用密钥sk,将返回的top-k篇密文文档C'=(c1,c2,…,ck)进行解密,获得所需的明文文件集。
进一步地,所述步骤S2中,对所有所述关键词创建倒排索引每个包含两部分内容,第一部分是关键词wi的指纹值Si;第二部分是含有关键词wi的文档的信息集合,这些信息包括文档的标识符与保序加密后的相关度分数,表示为(1≤i≤n)(1≤j≤m),则每个关键词对应索引即包含指纹Si和j篇文档的相关信息;最后将倒排索引I、密文文档集C=(c1,c2,…,cm)上传至云服务器端。
进一步地,所述步骤S2,所述关键词指纹生成算法sim(hk,w)具体包括以下步骤:
步骤S21:输入需要处理的关键词w,并将一个τ维的向量V初始化为0,一个τ维的向量S初始化为0,τ的值与哈希函数h产生哈希值的位数相同;
步骤S22:将关键词w做n-gram处理,获得关键词w的多个特征;
步骤S23:使用带密钥的单向哈希函数h,对gramset中的每个元素计算哈希值;
步骤S24:将每个元素的哈希值逐个映射到向量V,如果哈希值的第i位为1,则向量V的第i位加1,如果哈希值的第i位为0,则向量V的第i位减1;
步骤S25:将向量V映射到向量S,如果向量V的第i位大于0,则向量S第i位的值为1,如果向量V的第i位小于0,则向量S第i位的值为0;
步骤S26:输出S作为这个关键词的指纹。
进一步地,当所述w为encrypt时,经过2-gram处理得到gramset={en,nc,cr,ry,yp,pt},gramset中的各个元素即为关键词w的特征。
进一步地,所述哈希函数h选择使用Hmac-SHA1或Hmac-MD5,不同的h产生不同位数的哈希值。
进一步地,所述步骤S2中,基于tf-idf权值计算方法计算关键词在文档中的相关度分数Scorej,具体为:
首先计算词频权重wft,f:
再计算逆文档频率idft:
最后计算关键词在文档中的相关度分数Scorej,(1≤j≤m):Scorej=wft,f×idft。
进一步地,所述步骤S4中,所述双因子排序方法根据汉明距离和相关度分数进行排序选择,具体包括以下步骤:
步骤S41:计算搜索陷门Tw和关键词索引中的指纹值Si之间的汉明距离
步骤S42利用对搜索结果进行初步排序,得到粗糙的排序结果集合且集合I'中的是按照汉明距离从小到大排序的;
步骤S43:对每个中各自的进行排序;
步骤S44:按照优先,次之的设定,从排序结果中选出前k篇文档返回给用户。
在本发明中,针对目前的密文关键词模糊搜索方案中,索引结构计算和存储开销大,排序结果不够精确等问题,设计了基于Simhash的关键词指纹生成算法,实现了模糊搜索的功能,并极大减少了索引的计算和存储开销;通过引入相关度分数,提高了排序结果的准确性,并使用保序加密保障相关度分数的隐私;通过双因子排序方法能够对搜索结果进行排序优化,提高了搜索结果的正确率与召回率。本发明的用途如下:由于公有云服务器不是完全可信的第三方,因此为了保障数据安全和个人隐私,用户会将部分敏感数据,例如私密邮件、个人电子医疗记录、公司财务报表等,加密后再存储到云服务器。当需要使用这些数据时,用户可以使用本发明对云端数据进行密文关键词检索。即使用户输入的搜索请求出现拼写错误或格式不匹配的情况,也能搜索到相关数据并且排序后返回给用户。
与现有技术相比,本发明的显著优点在于:
(1)高效的模糊关键词索引存储:本发明改进了Simhash算法,能够针对关键词(而不是文档)生成指纹索引,使得该索引结构适用于关键词搜索。通过对关键词做n-gram处理,再利用Simhash的降维思想,能够将关键词处理成Simhash指纹。由于Simhash指纹本身的特性,授权用户在拼写错误的情况下也可以匹配到正确的关键词,从而实现了密文模糊检索。不同于传统模糊搜索方案,本发明无需构造庞大的关键词模糊集合,而只需要将一个关键词处理为一个对应的指纹,再构造成索引存储在云服务器即可,因此极大减少了计算和存储开销。
(2)精确返回排序结果:本发明通过结合汉明距离和相关度分数,设计了高效的双因子排序方法,云服务器能够对搜索结果进行精确的排序并返回给搜索用户。
(3)相关度分数的隐私保护:引入保序加密方法对相关度分数进行加密,既保护了相关度分数的隐私安全,又能够将排序操作交给云服务器完成,减少了用户查询文档的时间开销,节约了带宽资源。
附图说明
图1为本发明的方法系统框图。
图2为本发明中关键词指纹生成算法的示意图。
图3为本发明中双因子排序方法的流程示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
本实施例提供一种加密云数据下基于Simhash的模糊排序搜索方法,如图1所示,所述方法中包括数据拥有者,授权用户和云存储服务器,具体模糊排序搜索方法包括以下步骤:
步骤S1:输入一个安全参数λ,生成文档加密密钥sk、单向哈希函数h的密钥hk;将密钥sk、hk发送给授权用户;
步骤S2:数据拥有者从文档集合F=(f1,f2,…,fm)中抽取关键词集合W=(w1,w2,…,wn),通过基于Simhash的关键词指纹生成算法sim(hk,wi),生成每个关键词wi∈W对应的指纹Si,并为每篇文档创建唯一的文档标识符FIDj,(1≤j≤m);计算关键词在文档中的相关度分数Scorej,并对其进行保序加密OPE(ek,Scorej);
步骤S3:每一个授权用户都能够获得数据拥有者分发的密钥hk;当授权用户需要搜索感兴趣的关键词w时,首先通过关键词指纹生成算法sim(hk,w)计算关键词w的指纹值,该指纹值即陷门Tw;然后将产生的陷门Tw提交至云存储服务器进行查询;
步骤S4:云存储服务器在接收到授权用户的搜索请求后,根据双因子排序方法对搜索结果进行排序,将top-k篇密文文档的集合C'=(c1,c2,…,ck)返回给用户;
步骤S5:授权用户使用密钥sk,将返回的top-k篇密文文档C'=(c1,c2,…,ck)进行解密,获得所需的明文文件集。
在本实施例中,所述步骤S2中,对所有所述关键词创建倒排索引每个包含两部分内容,第一部分是关键词wi的指纹值Si;第二部分是含有关键词wi的文档的信息集合,这些信息包括文档的标识符与保序加密后的相关度分数,表示为(1≤i≤n)(1≤j≤m),则每个关键词对应索引即包含指纹Si和j篇文档的相关信息;最后将倒排索引I、密文文档集C=(c1,c2,…,cm)上传至云服务器端。
在本实施例中,所述步骤S2中,如图2所示,所述关键词指纹生成算法sim(hk,w)具体包括以下步骤:
步骤S21:输入需要处理的关键词w,并将一个τ维的向量V初始化为0,一个τ维的向量S初始化为0,τ的值与哈希函数h产生哈希值的位数相同;
步骤S22:将关键词w做n-gram处理,获得关键词w的多个特征;
步骤S23:使用带密钥的单向哈希函数h,对gramset中的每个元素计算哈希值;
步骤S24:将每个元素的哈希值逐个映射到向量V,如果哈希值的第i位为1,则向量V的第i位加1,如果哈希值的第i位为0,则向量V的第i位减1;
步骤S25:将向量V映射到向量S,如果向量V的第i位大于0,则向量S第i位的值为1,如果向量V的第i位小于0,则向量S第i位的值为0;
步骤S26:输出S作为这个关键词的指纹。
在本实施例中,当所述w为encrypt时,经过2-gram处理得到gramset={en,nc,cr,ry,yp,pt},gramset中的各个元素即为关键词w的特征。
在本实施例中,所述哈希函数h选择使用Hmac-SHA1或Hmac-MD5,不同的h产生不同位数的哈希值,这会对最后搜索的精确度造成影响,位数越多精确度越高。
在本实施例中,所述步骤S2中,基于tf-idf权值计算方法计算关键词在文档中的相关度分数Scorej,具体为:
首先计算词频权重wft,f:
再计算逆文档频率idft:
最后计算关键词在文档中的相关度分数Scorej,(1≤j≤m):Scorej=wft,f×idft。
其中,为了减轻用户在本地的计算压力,进而提高搜索效率,让排序操作全部由云服务器完成会更加符合用户需求,引入非线性保序加密对Scorej进行加密操作OPE(ek,Scorej)。
在本实施例中,为了减少排序时间和提高搜索效率,所述步骤S4中,所述双因子排序方法根据汉明距离和相关度分数进行排序选择,如图3所示,具体包括以下步骤:
步骤S41:计算搜索陷门Tw和关键词索引中的指纹值Si之间的汉明距离
步骤S42利用对搜索结果进行初步排序,得到粗糙的排序结果集合且集合I'中的是按照汉明距离从小到大排序的;
步骤S43:由于同一个关键词可能会被多篇文档所包含,此时的排序结果还不能够将包含相同关键词的文档区分开来,需要利用相关度分数进行更精确的排序,对每个中各自的进行排序;
步骤S44:按照优先,次之的设定,从排序结果中选出前k篇文档返回给用户。
其中,详细的步骤参考算法一。
在本实施例中,针对目前的密文关键词模糊搜索方案中,索引结构计算和存储开销大,排序结果不够精确等问题,设计了基于Simhash的关键词指纹生成算法,实现了模糊搜索的功能,并极大减少了索引的计算和存储开销;通过引入相关度分数,提高了排序结果的准确性,并使用保序加密保障相关度分数的隐私;通过双因子排序方法能够对搜索结果进行排序优化,提高了搜索结果的正确率与召回率。本发明的用途如下:由于公有云服务器不是完全可信的第三方,因此为了保障数据安全和个人隐私,用户会将部分敏感数据,例如私密邮件、个人电子医疗记录、公司财务报表等,加密后再存储到云服务器。当需要使用这些数据时,用户可以使用本发明对云端数据进行密文关键词检索。即使用户输入的搜索请求出现拼写错误或格式不匹配的情况,也能搜索到相关数据并且排序后返回给用户。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!