基于宠物日常数据分析的宠物喂养方法及系统与流程
本发明涉及宠物智能喂养领域,具体涉及一种基于宠物日常数据分析的宠物喂养方法及系统。
背景技术:
随着国民经济的快速发展,宠物作为一种情感寄托越来越成为人们乐意选择的一种方式。但如果仅仅使用缺乏科学依据的个人经验对宠物进行喂养,其不合理的喂养方案可能会使宠物缺乏营养导致疾病或富营养化以致肥胖,都达不到我们预想的目标,间接造成大量的精力损失和金钱浪费。
目前,亟需解决的问题是建立一套全面的宠物喂养模型,并将宠物生理指标、饮食情况反馈给用户,让用户能及时对宠物喂食方案做出调整。影响宠物健康程度的各个因素之间往往体现出高度的复杂性和非线性,采用常规预测、分析方法存在一定难度。
技术实现要素:
本发明通过提供一种基于宠物日常数据分析的宠物喂养方法及系统,以解决现有宠物喂养过程中因缺乏喂养经验,无法掌控最优的喂食方案而导致宠物饥饿或不健康的问题。
为解决上述问题,本发明采用以下技术方案予以实现:
一方面,本发明提供的基于宠物日常数据分析的宠物喂养方法,包括:
步骤S1:采集宠物的种类、性别、年龄、心跳频率、血压、体温、活动量、喂食类型、喂食量,当前图像、当前体重构成影响因素矩阵X,并上传至服务器;其中,喂食类型和喂食量构成决策变量;
步骤S2:在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型;
步骤S3:利用NSGA-Ⅱ算法对宠物喂养模型进行优化,获得决策变量的一组最优解;
步骤S4:将决策变量的该组最优解作为宠物的推荐决策X*通过服务器下发至用户的终端设备进行显示;
步骤S5:用户根据终端设备显示的推荐决策X*喂食宠物。
另一方面,本发明提供的基于宠物日常数据分析的宠物喂养系统,包括:
数据采集单元,用于采集宠物的种类、性别、年龄、心跳频率、血压、体温、活动量、喂食类型、喂食量,当前图像、当前体重构成影响因素矩阵X,并上传至服务器;其中,喂食类型和喂食量构成决策变量;
宠物喂养模型建立单元,用于在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型;
决策变量最优解获取单元,用于利用NSGA-Ⅱ算法对宠物喂养模型进行优化,获得决策变量的一组最优解,并将决策变量的该组最优解作为宠物的推荐决策X*;
推荐决策下发单元,用于通过服务器将宠物的推荐决策X*下发至用户的终端设备进行显示。
与现有技术相比,本发明提供的基于宠物日常数据分析的宠物喂养方法及系统的优点是:利用Elman神经网络建立宠物喂养模型,再利用NSGA-Ⅱ算法优化宠物喂养模型,确定了宠物喂食量、食品类型的最优值,并将宠物喂食量、食品类型的最优值构成宠物喂食方案即时反馈给用户,让用户随时 随地都能了解宠物的当前状况,为宠物营造了更好的生活环境。
附图说明
图1为根据本发明实施例的基于宠物日常数据分析的宠物喂养方法的流程示意图;
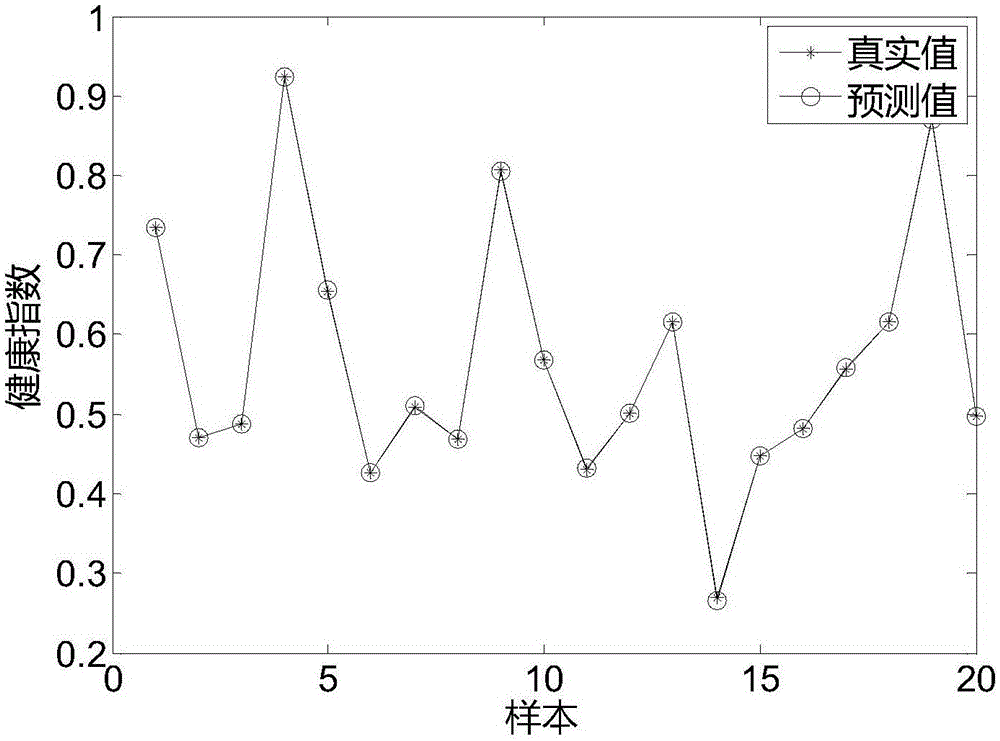
图2为根据本发明实施例的健康指标预测结果图;
图3为根据本发明实施例的健康指标预测误差图;
图4为根据本发明实施例的用户界面示意图。
具体实施方式
图1示出了根据本发明实施例的基于宠物日常数据分析的宠物喂养方法的流程。
如图1所示,本发明的基于宠物日常数据分析的宠物喂养方法,包括:
步骤S1:采集宠物的种类、性别、年龄、心跳频率、血压、体温、活动量、喂食类型、喂食量,当前图像、当前体重构成影响因素矩阵X,并上传至服务器;其中,喂食类型和喂食量构成决策变量。
通过统计得到对宠物的健康程度y1影响最大的变量为:宠物种类x1、年龄x2、心跳频率x3、血压x4、活动量x5、体温x6、当前图像x7、性别x8、当前体重x9、喂食量x10、食物类型x11,共11个变量;其中,心跳频率x3、血压x4、活动量x5、体温x6由对应的传感器测量数据;当前图像x7由摄像头采集,宠物种类x1、年龄x2、性别x8、当前体重x9为固有属性,由用户输入;喂食量x10、食物类型x11构成决策变量。
宠物的体温x6通过温度传感器采集获得;宠物的心跳频率x3通过心率传感器采集获得;宠物的血压x4通过血压传感器采集获得;宠物的活动量x5通过计步器采集获得;利用采样电路分别与温度传感器、心率传感器、血压传 感器、计步器、重量传感器进行连接,并将温度传感器、心率传感器、血压传感器、计步器分别采集到的宠物的体温、心跳频率、血压、活动量转换成数字信号。
宠物在当前时刻的图像信息通过摄像头采集获得,摄像头将图像信息转换成数字信号。
在本发明中,服务器优选为云服务器。
步骤S2:在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型。
设置Xk=[xk1,xk2,L,xkM](k=1,2,L,S)为输入矢量,N为训练样本个数,
为第g次迭代时输入层M与隐层I之间的权值矢量,WJP(g)为第g次迭代时隐层J与输出层P之间的权值矢量,WJC(g)为第g次迭代时隐层J与承接层C之间的权值矢量Yk(g)=[yk1(g),yk2(g),L,ykP(g)](k=1,2,L,S)为第g次迭代时网络的实际输出,dk=[dk1,dk2,L,dkP](k=1,2,L,S)为期望输出,迭代次数g为500。
利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型的过程,包括:
步骤S21:初始化,设迭代次数g初值为0,分别赋给WMI(0)、WJP(0)、WJC(0)一个(0,1)区间的随机值;
步骤S22:随机输入样本Xk;
步骤S23:对输入样本Xk,前向计算Elman神经网络每层神经元的实际输出Yk(g);
步骤S24:根据期望输出dk和实际输出Yk(g),计算误差E(g);
步骤S25:判断误差E(g)是否小于预设的误差值,如果大于或等于,进入步骤S26,如果小于,则进入步骤S29;
步骤S26:判断迭代次数g+1是否大于最大迭代次数,如果大于,进入步骤S29,否则,进入步骤S27;
步骤S27:对输入样本Xk反向计算Elman神经网络每层神经元的局部梯度δ;
步骤S28:计算权值修正量ΔW,并修正权值;令g=g+1,跳转至步骤S23;
其中,ΔWij=η·δij,η为学习效率;Wij(g+1)=Wij(g)+ΔWij(g);
步骤S29:判断是否完成所有样本的训练;如果是,完成建模;如果否,跳转至步骤S22。
在Elman神经网络设计中,隐层节点数的多少是决定Elman神经网络模型好坏的关键,也是Elman神经网络设计中的难点,这里采用试凑法来确定隐层的节点数。
式中,p为隐层神经元节点数,n为输入层神经元数,m为输出层神经元数,k为1-10之间的常数。Elman神经网络的设置参数如下表1所示。
表1 Elman神经网络设置参数
通过上述过程,可得到Elman神经网络预测效果如图2-3所示。智能宠物喂养的基础是模型的建立,模型精度直接影响输出结果。通过对图2-3分析可知,健康指数预最大测误差为3.5%,模型预测精度高,满足建模要求。
步骤S3:利用NSGA-Ⅱ算法(Non-dominated Sorting Genetic Algorithm-Ⅱ,带精英策略的非支配排序的遗传算法)对宠物喂养模型进行优化,获得决策变量的一组最优解。
获得决策变量的一组最优解,也就是获得宠物的浇水量、施肥量、施肥类型的一组最优值。
利用NSGA-Ⅱ算法对所述宠物喂养模型进行优化的步骤包括:
步骤S31:初始化系统参数;其中,系统参数包括种群规模N、最大遗传代数G、交叉概率P和变异概率Q。
步骤S32:将第t代产生的新种群Qt与其父代种群Pt合并组成种群Rt,种群Rt的大小为2N;若是第一代种群,则将第一代种群作为种群Rt。
步骤S33:对种群Rt进行非支配排序,获得一系列的非支配集Zi,并计算非支配集Zi中每个个体的拥挤度,产生新的父代种群Pt+1。
步骤S33的具体过程如下:
步骤S331:利用适应度函数判断种群Rt中的所有个体之间的相互支配关系;其中,D(i).n表示支配第i个个体的个体数量,D(i).p表示被第i个个 体支配的个体集合;若个体i支配j,则将个体j放入D(i).p集合,D(j).n的值加1;依次操作,获得种群Rt中的所有个体D(i).n与D(i).p的信息。
步骤S332:将种群Rt中所有D(i).n值为0的个体,即该类个体不被其他个体支配,放入非支配层的第一层,将D(i).n值为1的个体放入非支配层的第二层,依次操作,直到将所述种群Rt中所有个体放入不同非支配层为止;同一层数内的个体共享相同的虚拟适应度值,级数越小,虚拟适应度值越低,该层内个体越优,将非支配层的层数按从小到大的顺序进行排序。
步骤S333:由于每一层内所有个体共享同一虚拟适应度值,当需要在同一层内选择更优个体时,计算其拥挤度。
每个点的拥挤度id初始值置为0;针对每个目标,对所述种群Rt进行非支配排序,令所述种群Rt边界的两个个体的拥挤度为无穷,对所述种群Rt中其他的个体进行拥挤度的计算:
其中,id表示i点的拥挤度,fji+1表示i+1点的第j个目标函数值,fji-1表示i-1点的第j个目标函数值。
步骤S334:经过快速非支配排序和拥挤度计算之后,种群Rt中的每个个体i都拥有两个属性:非支配排序决定的非支配序irank和拥挤度id。依据这两个属性,可以定义拥挤度比较算子:个体i与个体j进行比较,如果个体i所处的非支配层优于个体j所处的非支配层,即irank<jrank,或者,个体i与个体j有相同的等级,且个体i比个体j的拥挤距离长,即irank=jrank且id>jd,则个体i获胜。
步骤S335:由于子代种群的个体和父代种群Pt+1的个体都包含在种群Rt中,则经过非支配排序以后的非支配集Z1中包含的个体是Rt中最好的,所以先将非支配集Z1放入父代种群Pt+1;如果父代种群Pt+1的个体数量未超出种群规模N,则将下一级的非支配集Z2放入父代种群Pt+1,直到将非支配集Z3放入父代种群Pt+1时,父代种群Pt+1的个体数量超出种群规模N,对非支配集Z3中的个体使用拥挤度比较算子进行比较,取前{num(Z3)-(num(Pt+1)-N)}个个体,使父代种群Pt+1的个体数量达到种群规模N。
步骤S34:对父代种群Pt+1进行交叉、变异遗传操作获得子代种群Qt+1。
对父代种群Pt+1进行交叉遗传操作的过程为:
将父代种群Pt+1内的所有个体随机搭配成对,对每一对个体,生成一个随机数,若某一对个体的随机数小于交叉概率P,则交换该对个体之间的部分染色体。
对父代种群Pt+1进行变异遗传操作的过程为:
对父代种群Pt+1中的每一个个体,生成一个随机数,若某个个体的随机数小于变异概率Q,则改变该个体的某一个或某一些基因座上的基因值为其他基因值。
步骤S35:遗传代数加1,判断遗传代数是否达到最大遗传代数G,如果是,输出当前全局最优解;如果否,跳转至步骤S32进行重复计算,直到遗传代数达到最大遗传代数G为止。
步骤S4:将决策变量的该组最优解作为宠物的推荐决策X*通过服务器下发至用户的终端设备进行显示。
各类传感器每2小时采集一次数据上传至服务器,服务器接数据并通过 宠物喂养模型给出宠物当前推荐的喂食量和食物类型。
步骤S5:用户根据终端设备显示的推荐决策喂养宠物。
用户可以在终端设备上打开智能宠物喂养界面(如图4所示),界面显示该宠物的简要信息,宠物的简要信息包括宠物的图像、当前健康指数,用户可在界面设置宠物的理想健康指数,由服务器下发推荐的喂食类型和喂食量。
宠物的当前健康指数由基于NSGA-Ⅱ算法对宠物喂养模型进行优化得到,宠物的当前健康指数与决策变量的一组最优解相对应。
本发明提供的基于宠物日常数据分析的宠物喂养方法,首先,利用传感器、摄像头等硬件采集宠物的生理指标参数、宠物图像、喂食量、食物类型;然后,将采集到的数据上传至服务器进行存储,在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型,在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型,利用NSGA-Ⅱ算法对宠物喂养模型进行优化,得到各决策变量的一组最优值,并将这组最优解作为推荐决策下发至用户的PC或APP终端,最后,用户可根据推荐决策决定宠物的喂食量和食物类型。该方法能够确定最优的宠物喂养方案,为宠物营造了更好的生活环境。
与上述方法相对应,本发明还提供一种基于宠物日常数据分析的宠物喂养系统。
本发明提供的基于宠物日常数据分析的宠物喂养系统,包括:
数据采集单元,用于采集宠物的种类、性别、年龄、心跳频率、血压、体温、活动量、喂食类型、喂食量,当前图像、当前体重构成影响因素矩阵X, 并上传至服务器;其中,喂食类型和喂食量构成决策变量。数据采集单元采集数据的具体过程参考上述步骤S1。
宠物喂养模型建立单元,用于在服务器内利用Elman神经网络建立影响因素矩阵X与宠物健康指数之间的复杂非线性关系,获得宠物喂养模型。宠物喂养模型建立单元建立宠物喂养模型的具体过程参考上述步骤S2。
决策变量最优解获取单元,用于利用NSGA-Ⅱ算法对宠物喂养模型进行优化,获得决策变量的一组最优解,并将决策变量的该组最优解作为宠物的推荐决策X*。决策变量最优解获取单元获取决策变量的最优解具体过程参考上述步骤S3。
推荐决策下发单元,用于通过服务器将宠物的推荐决策X*下发至用户的终端设备进行显示。
用户根据终端设备显示的推荐决策X*对宠物进行喂食。
应当指出的是,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的普通技术人员在本发明的实质范围内所做出的变化、改性、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!