一种多用户并发式远程编译引擎架构的制作方法
本发明涉及一种多用户并发式远程编译引擎架构,属于计算机技术领域。
背景技术:
要将源语言转换为目标程序,必需使用开发环境对代码或工程进行编译。大多数开发环境随着版本的升级,其自身功能不断完善,安装体积越来越大,耗资源越来越多,对电脑性能要求越来越高,同时导致编译时间不断增加,在团队项目开发中,设备性能对开发的效率的影响日益突出,而且团队成员都需要安装相同的开发环境,并且大多数开发环境会通过证书文件或绑定MAC对使用人数进行限制,这对资源是一种巨大浪费。如何尽可能减小设备性能对开发效率的影响,且避免大型开发软件的重复安装,突破软件对使用者的数量限制,达到一处安装到处可用的效果,是亟需解决的问题。
技术实现要素:
本发明提出了一种多用户并发式远程编译引擎架构,用以解决团队开发中设备性能对开发效率的影响,以及大型开发软件需要重复安装的问题。
为实现上述目的,本发明设计了一种多用户并发式远程编译系统,
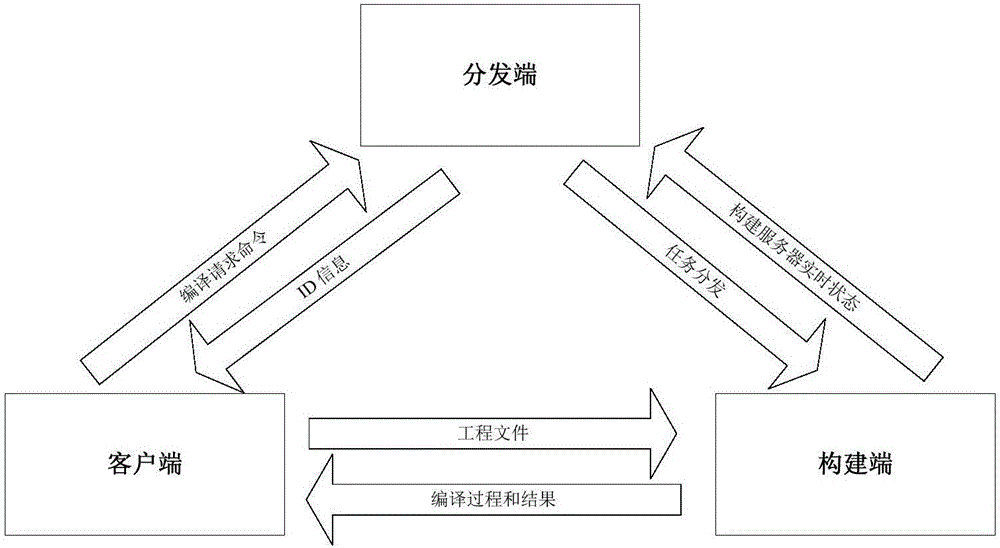
包括:客户端、分发端和构建端;客户端发起编译请求,分发端接收到编译请求后,根据实时监控的构建端状态信息为客户端分配合适的构建端,并将分配的构建端的ID信息发送给客户端,客户端根据分配的构建端ID信息将工程文件发送给对应的构建端,构建端将收到的工程文件进行编译,并将编译过程和结果反馈给发起编译请求的客户端。
本发明还提供了一种客户端,所述客户端向分发端发起编译请求,并接收分发端分配的构建端的ID信息,向对应的构建端发送工程文件,并接收构建端对工程文件的编译过程和结果。
还提供了一种分发端,所述分发端实时监控构建端的状态信息,接收到客户端发起的编译请求后,根据构建端的状态信息分配合适的构建端,将分配的构建端ID信息发送给客户端。
还提供了一种构建端,所述构建端将发起编译请求的客户端发送的工程文件进行编译,并将编译过程和编译结果反馈给发起编译请求的客户端。
本发明设计的多用户并发式远程编译引擎架构,只需安装简单的客户端界面,利用构建端对客户端发送的工程文件进行编译,避免了软件的重复安装;
客户端与服务器建立连接即可完成程序的编译工作,并且服务器可以同时处理多个编译请求,突破了实用者数量的限制,从而提高了开发效率
附图说明
图1是本发明的总体架构图;
图2是本发明的工作流程图;
图3是本发明客户端的示意图;
图4是本发明分发端的示意图;
图5是本发明构建端的示意图;
图6是本发明的网络拓扑图。
具体实施方式
本发明是一种多用户并发式远程编译引擎架构,其核心思想是将开发环境部署在服务器端,当有编译请求到来时,通过分发端选择合适的构建端进行编译工作,用户只需在本地安装通用的客户端即可实现程序的远程编译。
本发明的技术方案为:本发明的多用户并发式远程编译引擎架构包括:客户端、分发端和构建端;所述客户端向分发端发送一个或多个用户编译请求,并接收分发端分配的进行编译的构建端的ID信息,再向构建端发送工程文件,并接收构建端对工程文件的编译过程和编译结果;所述分发端接收客户端发送的编译请求后分配合适的构建端,将分配合适的构建端ID信息发送给客户端,并实时监视和更新构建端信息;所述构建端根据分发端的分配将客户端发送的工程文件进行编译,并向客户端传输编译过程和编译结果。
下面结合附图对本发明作进一步说明:
本发明的总体架构图如图1所示,客户端是编译任务的发起者,其以界面形式展现给用户,它负责编译请求的发送、源文件的发送和编译结果的接收;分发端是连接客户端和构建端的桥梁,负责接收编译请求后使用负载均衡算法选择合适的构建端进行编译,并实时监控和更新构建端信息;构建端是编译任务的执行者,主要负责完成编译任务和编译结果文件的传输。
所述的总体架构的工作流程如图2所示,客户端发起编译请求,分发端接收到后对报文进行解析,获取客户端ID、版本号、客户端IP和端口号等信息;分发端监听构建端相的工况信息,记录其工作状态、内存使用率、构建端的IP和端口号等,并实时进行更新;分发端根据更新的构建端工况信息为客户端分配合适的构建端,如果选择成功,则并将分配结果返回给客户端,同时将编译请求信息更新后转发给构建端,如果选择失败则直接提示选择失败信息给客户端;客户端和构建端建立连接,如果客户端请求的编译环境和版本与构建端安装的环境和版本匹配,则构建端向客户端发送上传文件请求消息后,随后客户端向构建端发送源文件,如果匹配失败则直接提示失败原因信息给客户端;构建端接收源文件结束,进行编译,编译完成后向发送编译请求的客户端回传编译结果文件。
客户端,所述客户端向分发端发起编译请求,并接收分发端分配的构建端的ID信息,向对应的构建端发送工程文件,并接收构建端对工程文件的编译过程和结果。
如图3所示,所述的客户端的组成结构主要由编译请求模块、ID管理模块、文件传输模块和文件压缩模块组成。编译请求模块实现了向分发端发送编译请求功能。ID管理模块负责工程ID的记录管理工作,ID是为了系统亲和性考虑,每个工程分配一个系统唯一的ID编号,当工程第二次请求编译时,分发端会根据ID号分配上次编译过此工程的构建端,并筛选出变化的文件进行传输,以减少重复传输工程文件时间,提高系统效率。文件传输模块和文件压缩模块联合完成了文件发送及文件接收的操作。
分发端,所述分发端实时监控构建端的状态信息,接收到客户端发起的编译请求后,根据构建端的状态信息分配合适的构建端,将分配的构建端ID信息发送给客户端。
本实施例的分发端的具体结构如图4所示,它主要由心跳处理模块、选择模块、ID生成模块和队列共享模块构成。心跳处理模块接收构建端定时发送的状态信息,并把其更新到本地存储的构建端列表中。选择模块是分发端的核心模块,实现了系统的亲和性功能和负载均衡算法,首先根据工程ID选择编译过的构建端,如果是新建工程或原构建端不在编译等待状态,则根据其他构建端的工作状态,以及CPU占用率为条件选择合适的构建端分配编译任务。ID生成模块生成系统唯一的工程ID,此ID在分发端接收到编译请求时返回给客户端由客户端更新到ID记录文件中,同时分配完构建端后,分发端会把ID记录到相应构建端状态列表中,以供下次分配时查询。队列共享模块避免了网络拥塞时编译请求的丢失,其会对不同时刻到来的编译请求进行缓存,当先到的编译请求还未处理完毕,后面的编译请求将按时间进行排队处理。
构建端,所述构建端将发起编译请求的客户端发送的工程文件进行编译,并将编译过程和编译结果反馈给发起编译请求的客户端。
本实施例的构建端的具体结构如图5所示,它主要由心跳模块、代码编译模块、文件传输模块和文件压缩模块组成。为了一个构建端能够同时完成多个编译任务,避免资源的浪费,构建端采取多任务并发模式实现。每个构建端可创建多个独立的构建进程,每个进程根据IP地址和端口号区分,可独立完成编译任务。心跳模块功能是向分发端提供自身的工况,包括IP地址、端口号、进程号、工作状态,以让分发端根据自身工况抉择是否分配编译任务。代码编译模块处理客户端发送的源文件,其编译原理是将编译环境的编译功能以动态库的方式封装,或利用其支持命令行的原理直接采用命令行编译方式,编译模块接到编译任务后调用动态库或命令行进行编译,并实时将编译过程回传到客户端。文件传输模块和文件压缩模块复用了客户端的相应模块,完成文件的压缩传送和文件接收功能。
如图6所示为基于本架构的网络拓扑图。本方法适用于局域网中,能最大限度减少网速对编译速度的影响。分发端是唯一的,客户端和构建端都要连接到分发端才能正常完成各自功能。客户端可以由多个运行客户端程序的电脑构成,支持同时向分发端请求编译。构建端也可由多台构建服务器组成,每台服务器又能同时并发多个编译任务,这样的设计能满足大量的编译任务同时运行。
本发明提供的多用户并发式程序远程编译方法,将编译环境部署到服务器端,用户只需安装简单的客户端界面,与服务器建立连接即可完成程序的编译工作。并且服务器可以同时处理多个编译请求,只需保证服务器的性能且合理设置每台服务器的构建服务进程数,就可有效缩减编译的时间,突破使用者数量限制,从而提高开发效率。
本领域技术人员在本发明技术构想的启发下,在不脱离本发明内容的基础上,还可以对上述方法做出各种改进,这仍落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!