一种基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法与流程
本发明涉及一种生物学信息学、智能优化、计算机应用领域,尤其涉及的是,一种基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法。
背景技术:
生物细胞中包含许多由20多种氨基酸所形成的长链折叠而成的蛋白质,蛋白质结构预测问题是当今计算生物学领域中的研究热点,不仅具有非常重要的理论机制,而且对新蛋白的设计、蛋白质之间相互作用建模、药物标靶蛋白的设计具有十分重要的指导意义。目前,最常用的蛋白质结构实验测定方法包括X-晶体衍射和核磁共振,但是上述两种蛋白质结构测定方法存在一定的缺陷,无法满足所有蛋白质结构预测的需求。例如,对于一些不易结晶的蛋白,无法使用X-晶体衍射方法进行测定;使用核磁共振房产测定一个蛋白的结构费用较大(大约15万美元),并且极其费时(大约需要半年)。因此,如何以计算机为工具,运用适当的算法,从氨基酸序列出发直接预测蛋白质的三维结构,成为当前生物信息学中一种重要的研究课题。
1965年,Anfinsen等提出了蛋白质的一级结构完全决定了其三维空间结构的著名论断,这一论断使得根据蛋白质得氨基酸序列从理论上预测其相应的空间结构成为了现实。从热力学角度来看,也就是说蛋白质的天然态结构通常对应着能量最低的构象。因此,从氨基酸序列出发,以能量函数来衡量构象的质量,采用适当的算法搜索能量模型中最小能量构象,从而预测蛋白质的天然态结构,已成为计算生物信息学中重要的研究课题之一。目前,最常用的预测方法可以划分为以下三类:针对高相似序列的同源建模方法;针对较低相似性序列的折叠识别方法;以及不依赖模板的从头预测方法(ab initio或de novo)。经过20多年的发展历程表明,对于序列相似度较高的情况(>50%),TBM预测精度能够达到左右;然而,序列相似度<30%的情况下并不理想;对于序列相似度<20%或寡肽(<10个残基的小蛋白)来说,从头预测方法是唯一的选择。
从头预测方法直接基于Anfinsen假说建立蛋白质物理或知识能量模型,然后设计适当优化算法求解最小能量构象。可以看出,从头预测方法必须考虑以下两个因素:(1)知识能量的构建;(2)构象空间搜索方法。第一个因素本质上属于分子力学问题,主要是为了能够计算得到每个蛋白质结构对应的能量值。第二个因素本质上属于全局优化问题,通过选择一种合适的优化方法,对构象空间进行快速搜索,得到能量最低构象。其中,蛋白质构象空间优化属于一类非常难解的NP-Hard问题。群体进化类算法是研究蛋白质分子构象优化的重要方法,主要包括差分进化算法(DE)、遗传算法(GA)、粒子群算法(PSO),这些算法不仅结构简单,易于实现,而且鲁棒性强,因此,经常被用于从头预测方法中的全局最小能量构象搜索。然而,对于上述群体算法,新构象生成策略的选择至关重要,不恰当的策略会导致算法搜索效率低、收敛速度慢,甚至陷入局部最优,出现早熟收敛现象,从而影响预测精度。
因此,现有的构象空间优化方法在搜索效率和预测精度方面存在着缺陷,需要改进。
技术实现要素:
为了克服现有的群体蛋白质结构预测方法在预测精度和搜索效率方面的不足,本发明提出一种预测精度高、搜索效率高的基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法,所述方法包括以下步骤:
1)选取蛋白质力场模型,即能量函数E(X),并输入待测蛋白质的序列信息;
2)初始化:设置种群规模NP,交叉概率CR,增益常数F,支撑面斜率控制因子M和最大迭代次数Gmax;根据输入的序列信息生成初始构象种群并计算每个构象个体的能量值f(Xi)=E(Xi),i=1,2,…,NP,其中,N表示维数,表示第i个构象个体Xi的第N维元素,并初始化迭代次数G=0;
3)对种群中的每个构象Xi,i∈{1,2,…,NP}作如下处理:
3.1)从当前种群中随机选取四个互不相同的构象个体Xa,Xb,Xc,Xd,其中a≠b≠c≠d≠i;
3.2)根据变异操作V1i=Xa+F(Xb-Xc)生成变异构象个体V1i;
3.3)根据变异操作生成变异构象个体
3.4)根据能量值对当前种群中的构象个体进行升序排列,找出能量最低的构象个体Xbest;
3.5)根据变异操作生成变异构象个体
3.6)分别对变异构象个体V1i、和执行交叉操作生成新构象个体和其中m=1,2,3,j=1,2,…,N,表示新构象个体的第j维元素,表示变异构象个体的第j维元素,表示目标构象个体Xi的第j维元素,R1表示0和1之间的随机小数,R2表示1和N之间的随机整数;
3.7)根据如下操作分别计算新构象个体和的能量估计值:
3.7.1)计算当前种群中每个构象个体到新构象个体之间的距离表示第i个构象个体到第1个新构象个体之间的距离;
3.7.2)根据距离对所有构象个体进行升序排列,选取距离最小的两个构象个体并记为并计算其抽象凸下界估计支撑面:
其中,为所选构象个体的能量函数值,n=1,2,…,N+1为所选构象个体的第n维元素,为辅助变量,M为支撑面斜率控制因子;
3.7.3)计算新构象个体的能量估计值其中max表示求最大值,min表示求最小值,为支
撑向量lt的第j维元素;
3.7.4)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.7.5)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.8)比较新构象个体和的能量估计值,并选出能量估计值最小的新构象个体,并记为Umin;
3.9)计算构象Umin的能量函数值f(Umin)=E(Umin),如果f(Umin)小于当前目标构象个体Xi的能量函数值f(Xi),则构象Umin替换构象Xi;
4)判断是否满足终止条件,若满足则输出结果并退出,否则返回步骤3)。
进一步,所述步骤4)中,对种群中的每个构象个体都执行完步骤3)以后,迭代次数G=G+1,终止条件为迭代次数G达到预设最大迭代次数Gmax。
本发明的技术构思为:首先,根据随机选择的构象个体、当前目标构象个体和能量值最低的构象构体生成三个不同的新构象个体;然后,分别计算当前种群中各构象个体到各新构象个体的距离,并根据距离进行升序排列;其次,计算离各新构象个体最近的部分构象个体的抽象凸支撑面,从而计算各新构象个体的能量估计值;最后,比较各新构象个体能量估计值,从而选取能量估计值最低的新构象个体进行能量函数评价。
本发明的有益效果表现在:一方面,根据不同的策略生成多个不同的新构象个体,避免因策略选择不恰当而引起的早熟收敛,从而提高预测精度;另一方面,根据新构象个体的抽象凸能量估计值选择新构象构体,减少能量函数平均,从而降低计算代价,提高搜索效率。
附图说明
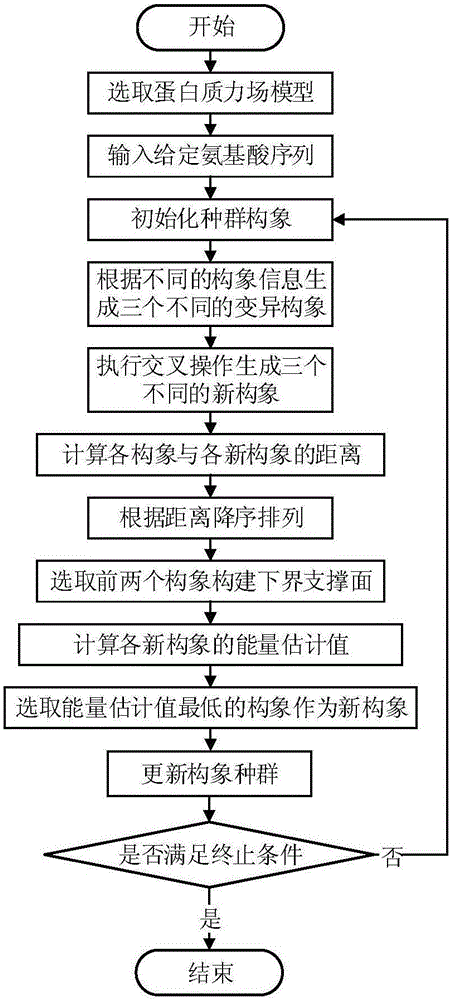
图1是基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法的流程图。
图2是基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法对蛋白质1AIL进行结构预测时的构象更新示意图。
图3是基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法对蛋白质1AIL进行结构预测时得到的构象分布图。
图4是基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法对蛋白质1AIL进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图4,一种基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法,包括以下步骤:
1)选取蛋白质力场模型,即能量函数E(X),并输入待测蛋白质的序列信息;
2)初始化:设置种群规模NP,交叉概率CR,增益常数F,支撑面斜率控制因子M和最大迭代次数Gmax;根据输入的序列信息生成初始构象种群并计算每个构象个体的能量值f(Xi)=E(Xi),i=1,2,…,NP,其中,N表示维数,表示第i个构象个体Xi的第N维元素,并初始化迭代次数G=0;
3)对种群中的每个构象Xi,i∈{1,2,…,NP}作如下处理:
3.1)从当前种群中随机选取四个互不相同的构象个体Xa,Xb,Xc,Xd,其中a≠b≠c≠d≠i;
3.2)根据变异操作V1i=Xa+F(Xb-Xc)生成变异构象个体V1i;
3.3)根据变异操作生成变异构象个体
3.4)根据能量值对当前种群中的构象个体进行升序排列,找出能量最低的构象个体Xbest;
3.5)根据变异操作生成变异构象个体
3.6)分别对变异构象个体V1i、和执行交叉操作生成新构象个体和其中m=1,2,3,j=1,2,…,N,表示新构象个体的第j维元素,表示变异构象个体的第j维元素,表示目标构象个体Xi的第j维元素,R1表示0和1之间的随机小数,R2表示1和N之间的随机整数;
3.7)根据如下操作分别计算新构象个体和的能量估计值:
3.7.1)计算当前种群中每个构象个体到新构象个体之间的距离表示第i个构象个体到第1个新构象个体之间的距离;
3.7.2)根据距离对所有构象个体进行升序排列,选取距离最小的两个构象个体并记为并计算其抽象凸下界估计支撑面:
其中,为所选构象个体的能量函数值,n=1,2,…,N+1为所选构象个体的第n维元素,为辅助变量,M为支撑面斜率控制因子;
3.7.3)计算新构象个体的能量估计值其中max表示求最大值,min表示求最小值,为支撑向量lt的第j维元素;
3.7.4)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.7.5)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.8)比较新构象个体和的能量估计值,并选出能量估计值最小的新构象个体,并记为Umin;
3.9)计算构象Umin的能量函数值f(Umin)=E(Umin),如果f(Umin)小于当前目标构象个体Xi的能量函数值f(Xi),则构象Umin替换构象Xi;
4)判断是否满足终止条件,若满足则输出结果并退出,否则返回步骤3)。
进一步,所述步骤4)中,对种群中的每个构象个体都执行完步骤3)以后,迭代次数G=G+1,终止条件为迭代次数G达到预设最大迭代次数Gmax。
本实施例序列长度为73的α折叠蛋白质1AIL为实施例,一种基于局部抽象凸支撑面的多策略群体蛋白质结构预测方法,其中包含以下步骤:
1)选取蛋白质Rosetta Score3力场模型,即Rosetta Score3能量函数E(X),并输入待测蛋白质的序列信息;
2)初始化:设置种群规模NP=50,交叉概率CR=0.5,增益常数F=0.5,支撑面斜率控制因子M=1000,最大迭代次数Gmax=10000;根据输入的序列信息生成初始构象种群并计算每个构象个体的能量值f(Xi)=E(Xi),i=1,2,…,NP,其中,N表示维数,表示第i个构象个体Xi的第N维元素,并初始化迭代次数G=0;
3)对种群中的每个构象Xi,i∈{1,2,…,NP}作如下处理:
3.1)从当前种群中随机选取四个互不相同的构象个体Xa,Xb,Xc,Xd,其中a≠b≠c≠d≠i;
3.2)根据变异操作V1i=Xa+F(Xb-Xc)生成变异构象个体V1i;
3.3)根据变异操作生成变异构象个体
3.4)根据能量值对当前种群中的构象个体进行升序排列,找出能量最低的构象个体Xbest;
3.5)根据变异操作生成变异构象个体
3.6)分别对变异构象个体V1i、和执行交叉操作生成新构象个体和其中m=1,2,3,j=1,2,…,N,表示新构象个体的第j维元素,表示变异构象个体的第j维元素,表示目标构象个体Xi的第j维元素,R1表示0和1之间的随机小数,R2表示1和N之间的随机整数;
3.7)根据如下操作分别计算新构象个体和的能量估计值:
3.7.1)计算当前种群中每个构象个体到新构象个体之间的距离表示第i个构象个体到第1个新构象个体之间的距离;
3.7.2)根据距离对所有构象个体进行升序排列,选取距离最小的两个构象个体并记为并计算其抽象凸下界估计支撑面:
其中,为所选构象个体的能量函数值,n=1,2,…,N+1为所选构象个体的第n维元素,为辅助变量,M为支撑面斜率控制因子;
3.7.3)计算新构象个体的能量估计值其中max表示求最大值,min表示求最小值,为支撑向量lt的第j维元素;
3.7.4)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.7.5)根据步骤3.7.1)-3.7.3)计算新构象个体的能量估计值
3.8)比较新构象个体和的能量估计值,并选出能量估计值最小的新构象个体,并记为Umin;
3.9)计算构象Umin的能量函数值f(Umin)=E(Umin),如果f(Umin)小于当前目标构象个体Xi的能量函数值f(Xi),则构象Umin替换构象Xi;
4)对种群中的每个构象个体都执行完步骤3)以后,迭代次数G=G+1,判断迭代次数G是否大于最大迭代次数Gmax,若G大于Gmax,则输出预测结果并退出,否则返回步骤3)。
以序列长度为73的α折叠蛋白质1AIL为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为平均均方根偏差为预测结构如图4所示。
以上说明是本发明以1AIL蛋白质为实例所得出的优化效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!