基于谱聚类的音频数据聚类方法与流程
本发明涉及一种音频数据聚类方法,具体地涉及一种基于谱聚类的音频数据聚类方法。
背景技术:
近二十年,因互联网惊人的发展速度,海量信息不断涌现。如何从海量信息中找到有用的信息,已经成为各大网络数据公司面临的主要问题。传统的统计和计算已经不能满足于公众和各大公司的需求,源自数据挖掘、机器学习等领域的方法迅速发展。通过设置一定的规则和条件,能够快速有效地找出海量数据中的有用信息。
网易云音乐已经收录了3500万的不同歌曲和音乐,同时,在美国,每周会有大约50张专辑发布,平均每张专辑会有12首左右的音乐。如何快速对这些数量众多的音乐和歌曲进行分类成为了难题。而且音乐的分类方法又各有各的不同,可以按照音乐的情感分类,也可以按照演奏方式分类,有时,摇滚音乐下面就可以被细分为上百种类型,电子音乐甚至可以被细分为超过500种类型。而早期的音乐分类方式往往是唱片公司人为的添加类型标签供买家选择,而有时又是由专门收录音乐的网站添加标签,不同的人对同一首音乐的感受往往各不相同,因此也极有可能添加了不同的标签。因此,由计算机对音频数据识别后进行分类得到的结果更方便我们对音乐不同类型的区别进行研究,也可以方便我们直接将同类型的音乐推荐给用户。
聚类分析将数据元素在无监督的环境下进行自动划分并从中找出隐含规律的科学研究方法。聚类过程即根据不同的特征以及不同的统计量将数据分别划分到不同的簇的过程。通常情况下,在每个独立的类中,数据元素应有较大的相似性,而不同的簇间的元素则应有比较大的差异性。在统计学上,可以通过数学建模去简化数据进行聚类分析找到隐藏的信息,在机器学习中,通过对簇的分析可以找到簇间和簇内的隐藏模式。无监督的学习并不依赖于预先带有标记的任何数据集,只需要通过聚类学习算法来自动的确定数据集的标记和类型。
技术实现要素:
针对上述技术问题,本发明目的是:提供一种基于谱聚类的音频数据聚类方法,与其他音频数据聚类方法不同,本发明以帧频谱图峰值最大处的频率序列方差为横轴、以每帧功率和的序列方差的对数值为纵轴、以功率和的平均值为Z轴,构建音频三维坐标系,得到三维音频向量,根据音频向量间的距离计算音频数据相似度,利用谱聚类方法对音频数据进行聚类。从而达到为海量的音乐自动分类的目的,并且能精准的推荐给不同的用户增强用户体验。
本发明的技术方案是:
一种基于谱聚类的音频数据聚类方法,其特征在于,包括以下步骤:
S01:计算音频数据的音频周期,按照音频周期进行分帧处理,提取音频特征;
S02:以帧频谱图峰值最大处的频率序列方差为横轴、以每帧功率和的序列方差的对数值为纵轴、以功率和的平均值为Z轴,构建音频三维坐标系,得到三维音频向量,然后根据音频向量间的距离计算相似度,得到音频数据的相似度矩阵S;
S03:利用谱聚类方法对音频数据进行聚类。
优选的,所述步骤S01提取音频特征之前还包括:
对每帧音频数据进行傅立叶变换,取幅值最高的频率保存在一个频率序列中,然后对该频率序列进行自相关运算。
优选的,所述步骤S03包括以下步骤:
S11:首先构建拉普拉斯矩阵Lrw=I-D-1S,其中I为单位矩阵,D为对角度矩阵,S为相似度矩阵;
S12:求解Lrw的前k个最小特征值对应的特征向量u1…uk,并构建矩阵Uk=[u1…uk];
S13:使用K均值算法对Uk的行聚类,得到k个簇。
与现有技术相比,本发明的优点是:
1、以帧频谱图峰值最大处的频率序列方差为横轴、以每帧功率和的序列方差的对数值为纵轴、以功率和的平均值为Z轴,构建音频三维坐标系,从而获得了更加有效的音频数据表示模型。
2、利用谱聚类方法对音频数据进行聚类,对音频数据的聚类效果更加优越。
附图说明
下面结合附图及实施例对本发明作进一步描述:
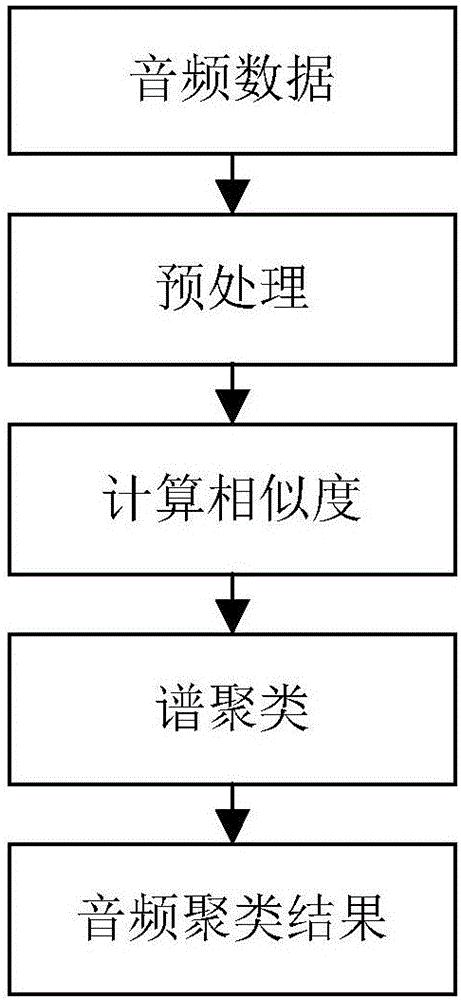
图1为本发明基于谱聚类的音频数据聚类方法的流程图;
图2为本发明基于谱聚类的音频数据聚类方法的音频数据三维分布图;
图3为本发明基于谱聚类的音频数据聚类方法的谱聚类方法的流程图;
图4为本发明基于谱聚类的音频数据聚类方法的音频数据聚类结果。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例:
如图1所示,一种基于谱聚类的音频数据聚类方法,首先对音频数据进行预处理;计算音频数据的音频周期,按照音频周期进行分帧处理,提取音频特征;以帧频谱图峰值最大处的频率序列方差为横轴、以每帧功率和的序列方差的对数值为纵轴、以功率和的平均值为Z轴,构建音频三维坐标系,得到三维音频向量,然后根据音频向量间的距离计算相似度,得到音频数据的相似度矩阵S;最后设计谱聚类方法获得音频数据聚类结果。
1.音频数据预处理
要得到一个理想的聚类结果,预处理方法极其关键,不仅需要大量的先验知识,还需要根据聚类的对象特征选择不同的算法。本发明的音频数据预处理包括音频周期的计算和音频特征的提取。
首先对音频数据进行分帧处理,对每帧音频数据进行傅立叶变换取得幅值最高的频率保存在一个频率序列中,然后对该频率序列做自相关运算。考虑到对每一帧做傅立叶变换需要的时间非常长,本发明对每帧的功率和进行自相关运算,从而更快地提取音频特征。自相关函数定义如下:
其中N为功率序列的长度,x(m)表示在时刻m时的功率,k为延时量,x(m+k)表示在时刻m+k时的功率,mean(x)表示求序列x的均值,sum(x2)表示求功率序列的平方和。从公式上看出,自相关函数是存在衰减的,即k值越大,R(k)越趋近于0。另外,在序列足够长的情况下多次求解自相关函数不会影响周期波峰位置,而且还有一定的去噪功能。
2.计算相似度
通过对音频周期的提取,我们可以对音频信号按照音频周期进行分帧处理,对每一帧提取频率和功率和,构成音乐旋律,接下来就可以对这些序列进行相似度计算。
如图2所示。本发明将纵轴的影响因素归为每帧功率和的序列方差的对数值,横轴的影响因素归为帧频谱图峰值最大处的频率序列方差。即:A=log(var(w)),V=var(fd),其中w为每帧的功率和序列,fd为两帧频谱的差序列中最大值对应的频率序列,var为方差函数。此处fd取频率的差值作为主要特征主要是考虑到人对变化的频率比不变的频率更敏感,例如,在听歌时,往往会忽略背景音乐中的鼓点部分,而专注于歌曲中变化的部分。另外,本发明增加了一个Z轴,Z=log(mean(w)),即功率和的平均值作为影响音频的第三个特征,因此,每首音乐可表示为向量(v,a,z)。对于496首原音频类型为网易云音乐的歌单类型,例如,某歌单被命名为轻音乐,则将该歌单的所有音乐都设置为轻音乐类型,如果歌单类型为摇滚则将该歌单的所有歌曲均设为摇滚。据此画出496首音乐的三维分布图像,如图2所示。
可以看出,左上部分频率变化很小,而功率变化很大,此类音频可以归为摇滚,慢摇等类别。而左下部分频率变化很小且功率变化也很小,此类音频可以归为轻音乐,纯音乐等类别。而右上部分则属于频率变化很大且功率变化也很大的音频,这类音频属于DJ,电音等类别。通过求解每个音频对应的三维向量之间的距离,即可获得音频数据之间的相似度,显然,距离越小,相似度越高;距离越大,相似度越低。
3.谱聚类
获得了音频数据的相似度矩阵之后,本发明提出谱聚类方法对音频数据进行聚类,谱聚类方法流程图如图3所示。首先构建拉普拉斯矩阵Lrw=I-D-1S,其中I为单位矩阵,D为对角度矩阵,S为相似度矩阵;然后求解Lrw的前k个最小特征值对应的特征向量;构建矩阵Uk;最后使用K均值算法对Uk的行聚类,得到k个簇。
因为摇滚和电音的相似特性,可将其归为一类,这样原始音频数据可以看成是包含2个簇(k=2)。对前述的496首音频数据进行谱聚类,聚类结果如图4所示。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!