一种词袋模型优化和图像识别的方法及装置与流程
本发明涉及图像识别领域,具体涉及一种词袋模型优化和图像识别的方法及装置。
背景技术:
现今,图像识别技术图像识别技术是人工智能的一个重要领域,为了编制模拟人类图像识别活动的计算机程序,提出了不同的图像识别模型,大部分图像识别模型均是基于深度学习算法,但深度学习是一种特殊的神经网络,网络层次较多,每层的节点也较多,因此深度学习模型的参数较多,大多数为百万,甚至千万级别。为了训练一个好的深度学习模型,避免过拟合,需要大量的数据做支撑。类比一下就是要解一个具有一百万个变量的方程组,需要有一百万个方程,训练样本数量巨大,训练时需要读入大量的训练数据,并反复优化模型的参数,运算复杂度较高,同时训练完成后的模型具有复杂的网络结构,同时有大量的参数,使得包含这些网络结构和所有参数数值的模型体积庞大,故在进行图像识别时,时间复杂度较高,且现有大部分图像识别模型能识别的类别固定、扩展不方便,需要在训练时指定待分类的类别,如果后期需要增加额外的训练数据或者额外的类别时,往往需要重新训练整个模型,由此可见,现有的利用神经网络模型进行图像识别的方式的识别效率较低且扩展能力较差。
技术实现要素:
因此,本发明要解决的技术问题在于现有图像识别方法识别效率低与模型扩展能力差。
有鉴于此,本发明提供一种词袋模型优化方法,包括:获取每一个词袋模型中的聚类词汇;将所述聚类词汇进行聚类,得到聚类中心,其中所述聚类中心的数量等于所述词袋模型的个数;统计每一个所述聚类中心下的所述聚类词汇隶属于的所述词袋模型的数量;根据所述聚类词汇隶属于的所述词袋模型的数量,计算所述词袋模型中的所述聚类词汇的权重。
优选地,所述获取每一个词袋模型中的聚类词汇的步骤,包括:
获取多个训练图像并进行分类,构成多个训练集;
提取每一个训练集中的所述训练图像的所有局部特征向量;
将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇;
重复所述提取每一个训练集中的所述训练图像的所有局部特征向量至所述将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇的步骤,直至获得每一个所述词袋模型的所述聚类词汇。
优选地,所述计算所述词袋模型中的所述聚类词汇的权重的步骤,包括:所述聚类词汇的权重等于其所属的所述聚类中心的权重。
优选地,所述聚类中心的权重为:
其中,Wj为所述聚类中心的权重;Mj为第j个聚类中心下的词汇所属的图像类别的数量;M为所有Mj的和;N为聚类中心的数量。
优选地,所述计算所述词袋模型中的所述聚类词汇的权重的步骤,包括:将所述词袋模型中的所述聚类词汇的权重进行归一化计算。
相应地,本发明提供一种图像识别方法,包括:获取待测试图像的局部特征向量;将所述局部特征向量输入到利用上述所述的方法优化后的词袋模型中;根据所述词袋模型中的聚类词汇以及所述聚类词汇的权重计算所述待测试图像在每一个所述词袋模型中的编码残差;将所述多个词袋模型的所述编码残差进行排序,根据所述编码残差的大小,判断所述待测试图像的类别。
优选地,所述计算所述测试图像在每一个词袋模型中的编码残差的步骤,包括:分别获取所述每一个词袋模型的聚类词汇以及所述聚类词汇的权重;在所述每一个所述词袋模型中,将所述待测试图像的每一个局部特征向量聚类到最接近的聚类词汇;计算所述每一个局部特征向量与所述聚类词汇的二范数,并将所述二范数乘以所述聚类词汇的权重,得到所述每一个局部特征向量的编码残差;累加所述每一个所述局部特征向量的编码残差。
相应地,本发明还提供一种词袋模型优化装置,包括:
聚类词汇获取单元,用于获取每一个词袋模型中的聚类词汇;
聚类中心获取单元,用于将所述聚类词汇进行聚类,得到聚类中心,其中所述聚类中心的数量等于所述词袋模型的个数;
统计单元,用于统计每一个所述聚类中心下的所述聚类词汇隶属于的所述词袋模型的数量;
权重计算单元,用于根据所述聚类词汇隶属于的所述词袋模型的数量,计算所述词袋模型中的所述聚类词汇的权重。
相应地,本发明还提供一种图像识别装置,包括:
获取单元,用于获取待测试图像的局部特征向量;
输入单元,用于将所述局部特征向量输入到利用上述所述的方法优化后的词袋模型中;
计算单元,用于根据所述词袋模型中的聚类词汇以及所述聚类词汇的权重计算所述待测试图像在每一个所述词袋模型中的编码残差;
判断单元,用于将所述多个词袋模型的所述编码残差进行排序,根据所述编码残差的大小,判断所述待测试图像的类别。
优选地,所述计算单元,包括:聚类词汇获取子单元,用于分别获取所述每一个词袋模型的聚类词汇以及所述聚类词汇的权重;聚类子单元,用于在所述每一个所述词袋模型中,将所述待测试图像的每一个局部特征向量聚类到最接近的聚类词汇;编码残差计算子单元,用于计算所述每一个局部特征向量与所述聚类词汇的二范数,并将所述二范数乘以所述聚类词汇的权重,得到所述每一个局部特征向量的编码残差;累加子单元,用于累加所述每一个所述局部特征向量的编码残差。
本发明技术方案具有以下优点:
本发明提供的一种词袋模型优化方法,通过获得词袋模型的聚类词汇的聚类中心,并计算出聚类中心下的聚类词汇隶属于的训练集的数量,根据聚类词汇隶属于的训练集的数量,计算词袋模型中的聚类词汇的权重,继而获得聚类词汇具有权重的词袋模型,该模型可以用于对图像进行识别,本方法不需要大量训练样本图像就能获得很好的识别准确率,同时解决了大部分图像识别模型扩展能力差的问题;
本发明提供的一种图像识别方法,通过设置多个词袋模型,将待测试图像的局部特征输入到多个词袋模型,并通过计算并排序编码残差,根据编码残差的大小判断待测试图像的类别,利用多个词袋模型识别图像种类,提高了词袋模型进行图像识别的准确性。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例1提供的一种词袋模型优化方法的流程图;
图2是本发明实施例2提供的一种图像识别方法的流程图;
图3是本发明实施例3提供的一种词袋模型优化装置的结构示意图;
图4是本发明实施例4提供的一种图像识别装置的结构示意图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
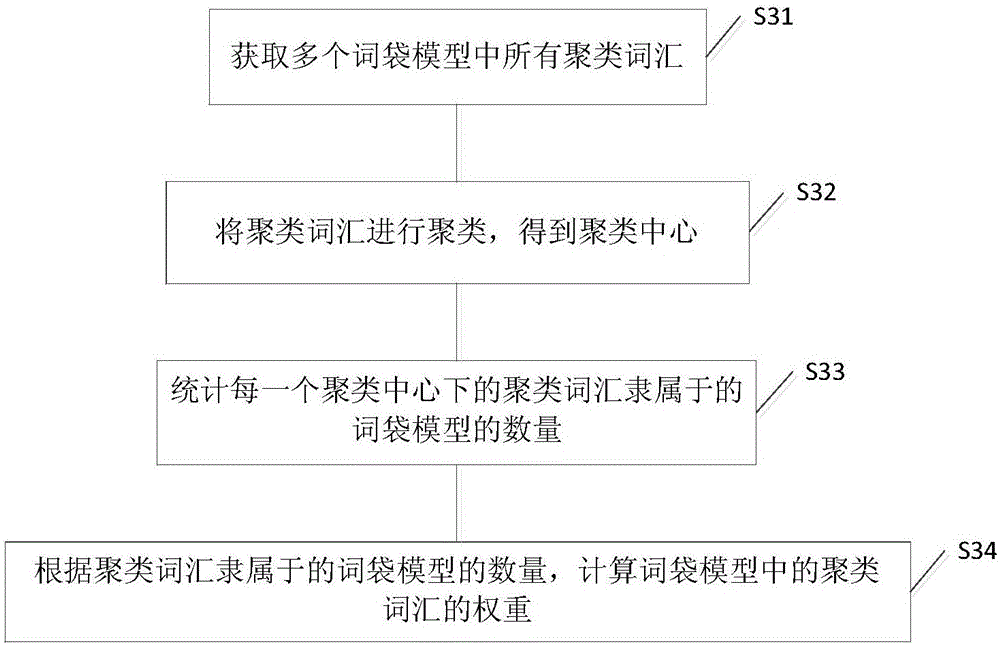
本发明实施例提供的一种词袋模型优化方法,如图1所示,包括:
S31,获取每一个词袋模型中的聚类词汇。
S32,将所述聚类词汇进行聚类,得到聚类中心,其中所述聚类中心的数量等于所述词袋模型的个数,词袋模型的数量根据获得的训练图像的类别数。
S33,统计每一个所述聚类中心下的所述聚类词汇隶属于的所述词袋模型的数量。例如,统计聚类中心A下的聚类词汇来源于X个词袋模型中,聚类中心B下的聚类词汇来源于Y个词袋模型中,当X小于Y时,则聚类中心A的权重大于聚类中心B的权重,即所述聚类词汇隶属于的词袋模型的数量越大,则对应的聚类中心的权重越小。
S34,根据所述聚类词汇隶属于的所述词袋模型的数量,计算所述词袋模型中的所述聚类词汇的权重。获得所述聚类词汇具有权重的词袋模型,在获得词袋模型中聚类词汇的权重后,优选地,将词袋模型中的聚类词汇的权重进行归一化计算,保证每一个词袋模型下的聚类词汇的权重系数为1。
在一个可选的实施例中,上述步骤S31可以进一步包括如下步骤:
获取多个训练图像并进行分类,构成多个训练集;
提取每一个训练集中的所述训练图像的所有局部特征向量;
将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇,其中,词袋模型的个数可以根据需要改变,词袋模型个数的选取可以通过提取数据库中的数据的种类确定,即当数据库中的类别增加时,词袋模型的个数也可随之增加,其中,可以通过K-means聚类方法对提取局部特征进行聚类;
重复所述提取每一个训练集中的所述训练图像的所有局部特征向量至所述将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇的步骤,直至获得每一个所述词袋模型的所述聚类词汇。
上述实施例方法,通过建立多个训练集并训练得到多个词袋模型,使得词袋模型的训练是分布式的训练方式,便于训练的部署与加速。
在一个可选的实施例中,上述步骤S34中计算所述词袋模型中的所述聚类词汇的权重的步骤,可以进一步包括:聚类词汇的权重等于其所属的所述聚类中心的权重,其中,所述聚类中心的权重为:
其中,Wj为所述聚类中心的权重;Mj为第j个聚类中心下的词汇所属的图像类别的数量;M为所有Mj的和;N为聚类中心的数量,在计算出Wj后,第j个聚类中心下所有的聚类词汇的权重均为Wj,当加入一个新的类别时,首先得到此类别的词汇,然后将每一个词汇分配到和它最相似的聚类中心下,分配完之后,重新计算Wj,最后在每一类中,重新归一化权重。
本发明提供的一种词袋模型优化方法,通过获得词袋模型的聚类词汇的聚类中心,并计算出聚类中心下的聚类词汇隶属于的训练集的数量,根据聚类词汇隶属于的训练集的数量,计算词袋模型中的聚类词汇的权重,继而获得聚类词汇具有权重的词袋模型,该模型可以用于对图像进行识别,提高了词袋模型进行图像识别的准确性,同时通过图像类别建立多个词袋模型,减少了训练样本数与训练时间,提高了运行效率,便于类别扩展。
实施例2
本发明实施例提供的一种图像识别方法,如图2所示,包括:
S11,获取待测试图像的局部特征向量。其中,优选利用DSIFT方法进行局部特征向量的提取;
S12,将局部特征向量输入到优化后词袋模型中。将所述局部特征向量输入到利用实施例1所述的方法优化后的词袋模型中;
S13,计算待测试图像在每一个词袋模型中的编码残差。根据所述词袋模型中的聚类词汇以及所述聚类词汇的权重,计算所述待测试图像在每一个所述词袋模型中的编码残差;
在一个可选的实施例中,上述步骤S13计算待测试图像在每一个词袋模型中的编码残差,可以进一步包括如下步骤:
分别获取所述每一个词袋模型的聚类词汇以及所述聚类词汇的权重;
将每一个局部特征向量聚类到最接近的聚类词汇;
计算每一个局部特征向量与聚类词汇的二范数,并将二范数乘以聚类词汇对应的权重,得到每一个所述局部特征向量的编码残差,其中聚类词汇对应的权重等于聚类词汇所属的聚类中心的权重;通过累加每一个所述局部特征向量的编码残差,继而得到每一个词袋模型中的编码残差;
S14,将多个词袋模型的编码残差进行排序。根据编码残差的大小,判断待测试图像的类别,本实施例优选编码残差最小的词袋模型为待测试图像的类别,通过排序过程得到的其他排序结果还可以为其他图像识别过程提供参考。
具体地,由于图像识别的过程是将图像的局部特征向量依次输入到不同的词袋模型中,使得图像的识别阶段是分布式的,便于图像识别过程的部署与加速。
本发明提供的一种图像识别方法,通过设置多个词袋模型,将待测试图像的局部特征输入到多个词袋模型,并通过计算并排序编码残差,根据编码残差的大小判断待测试图像的类别,利用多个词袋模型识别图像种类,提高了图像识别的准确性。
实施例3
本发明实施例提供的一种词袋模型优化装置,如图3所示,包括:聚类词汇获取单元41、聚类中心获取单元42、统计单元43以及权重计算单元44,其中,
聚类词汇获取单元41,用于获取每一个词袋模型中的聚类词汇;
聚类中心获取单元42,用于将所述聚类词汇进行聚类,得到聚类中心,其中所述聚类中心的数量等于所述词袋模型的个数;
统计单元43,用于统计每一个所述聚类中心下的所述聚类词汇隶属于的所述词袋模型的数量;例如,统计聚类中心A下的聚类词汇来源于X个词袋模型,聚类中心B下的聚类词汇来源于Y个词袋模型,当X小于Y时,则聚类中心A的权重大于聚类中心B的权重,即所述聚类词汇隶属于的词袋模型的数量越大,则对应的聚类中心的权重越小。
权重计算单元44,用于根据所述聚类词汇隶属于的所述词袋模型的数量,计算所述词袋模型中的所述聚类词汇的权重。获得所述聚类词汇具有权重的词袋模型,在获得词袋模型中聚类词汇的权重后,优选地,将词袋模型中的聚类词汇的权重进行归一化计算,保证每一个词袋模型下的聚类词汇的权重系数为1。
在一个可选的实施例中,上述聚类词汇获取单元41可以进一步用于:
获取多个训练图像并进行分类,构成多个训练集;
提取每一个训练集中的所述训练图像的所有局部特征向量;
将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇,其中,词袋模型的个数可以根据需要改变,词袋模型个数的选取可以通过提取数据库中的数据的种类确定,即当数据库中的类别增加时,词袋模型的个数也可随之增加,其中,可以通过K-means聚类方法对提取局部特征进行聚类;
重复所述提取每一个训练集中的所述训练图像的所有局部特征向量至所述将所述局部特征向量进行聚类,得到所述词袋模型,并获取所述词袋模型的聚类词汇,直至获得每一个所述词袋模型的所述聚类词汇。
在一个可选的实施例中,上述权重计算单元44进一步用于计算所述词袋模型中的所述聚类词汇的权重,其中聚类词汇的权重等于其所属的所述聚类中心的权重,所述聚类中心的权重为:
其中,Wj为所述聚类中心的权重;Mj为第j个聚类中心下的词汇所属的图像类别的数量;M为所有Mj的和;N为聚类中心的数量,在计算出Wj后,第j个聚类中心下所有的聚类词汇的权重均为Wj,当加入一个新的类别时,首先得到此类别的词汇,然后将每一个词汇分配到和它最相似的聚类中心下,分配完之后,重新计算Wj,最后在每一类中,重新归一化权重。
本发明提供的词袋模型优化装置,通过聚类词汇获取单元获得词袋模型的聚类词汇的聚类中心,并计算出聚类中心下的聚类词汇隶属于的训练集的数量,根据聚类词汇隶属于的训练集的数量,计算词袋模型中的聚类词汇的权重,继而获得聚类词汇具有权重的词袋模型,该模型可以用于对图像进行识别,提高了词袋模型进行图像识别的准确性,同时通过图像类别建立多个词袋模型,减少了训练样本数与训练时间,提高了运行效率,便于类别扩展。
实施例4
本发明实施例提供的一种图像识别装置,如图4所示,包括:获取单元21、输入单元22、计算单元23以及判断单元24,其中,
获取单元21,用于获取待测试图像的局部特征向量;
输入单元22,用于将所述局部特征向量输入到利用实施例1所述的方法优化后的词袋模型中;
计算单元23,用于根据所述词袋模型中的聚类词汇以及所述聚类词汇的权重计算所述待测试图像在每一个所述词袋模型中的编码残差;
判断单元24,用于将多个词袋模型的编码残差进行排序,根据编码残差的大小,判断待测试图像的类别。
优选地,本发明实施例提供的图像识别装置中,计算单元23包括:
聚类词汇获取子单元,用于分别获取所述每一个词袋模型的聚类词汇以及所述聚类词汇的权重;
聚类子单元,用于在所述每一个所述词袋模型中,将所述待测试图像的每一个局部特征向量聚类到最接近的聚类词汇;
编码残差计算子单元,用于计算所述每一个局部特征向量与所述聚类词汇的二范数,并将所述二范数乘以所述聚类词汇的权重,得到所述每一个局部特征向量的编码残差;
累加子单元,用于累加所述每一个所述局部特征向量的编码残差。
上述实施例提供的图像识别装置,通过获取单元获取待测试图像的局部特征向量并将局部特征向量输入到已训练好的多个词袋模型并通过计算并排序测试图像在每一个词袋模型中的编码残差,继而判断待测试图像的类别,提高了图像识别的准确性。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!