面向RFID的复杂事件规则动态调度与数据恢复方法与流程
本发明涉及RFID,复杂事件处理,分布式实时计算,尤其涉及复杂事件规则的动态调度方法以及规则数据自动恢复方法的设计与实现。
背景技术:
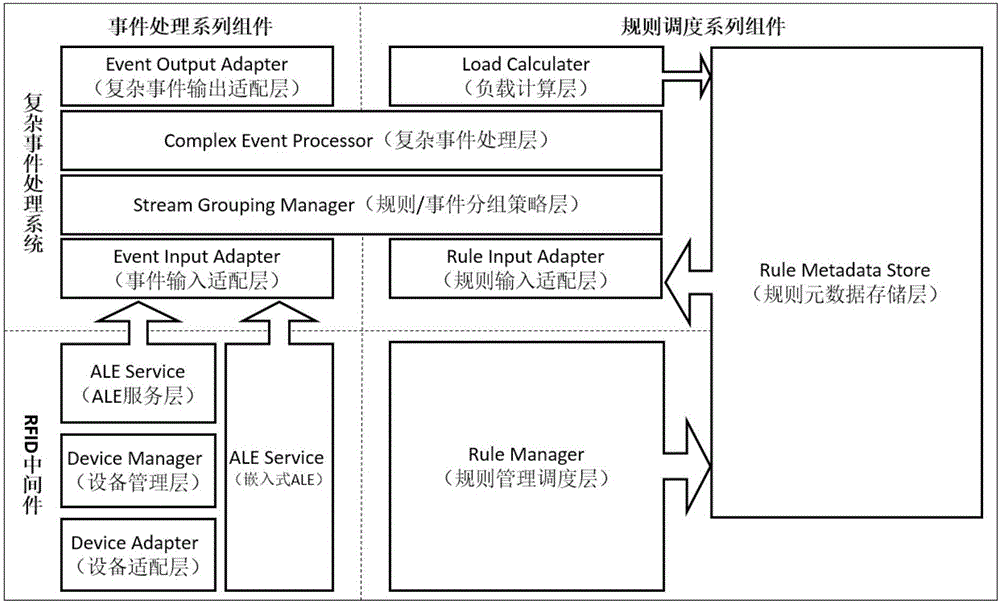
:RFID(无线射频识别)技术是目前物联网数据采集技术中发展较为成熟的方案之一,其应用范围遍及制造、物流、医疗、运输、零售、国防等各行各业。在物流供应链领域,随着RFID标签成本的下降,RFID技术越来越多的应用在生产、运输、库存管理、零售的各个环节。在RFID应用环境中,单个阅读器每秒钟可以产生200~400条数据,随着RFID技术的推广和应用在应用环境中会产生海量的RFID数据,如何在产生数据的同时实时地、高效得处理这些数据变得非常重要。复杂事件处理技术作为一种基于内存的事件驱动计算方式,在很多对实时性要求比较严格的领域有着广泛的应用,它提供了一种通用的方法来定义和描述各种事件之间的关系,并且可以利用事件间的关系实时地检测出更加复杂的业务事件。复杂事件处理技术主要包括复杂事件描述和复杂事件检测两个方面,其中复杂事件描述的形式化语言包括主要成果ZStream、SASE以及基于SASE改进的SASE+等,复杂事件检测的常用模型包括基于匹配树的处理模型,基于Petri网的处理模型,基于有向图的处理模型以及基于NFA非确定有限状态自动机的处理模型等。目前复杂事件处理技术在RFID领域的应用通常基于处理引擎实现,但是目前开源的复杂事件处理引擎并没有提供分布式解决方案,这使得在实时处理海量RFID数据时可扩展性不是很好。分布式实时计算框架可以解决实时处理海量数据的可扩展性问题,但是并不提供具体的业务逻辑实现,目前成熟的分布式实时计算框架包括S4、Storm、Puma等。将复杂事件处理引擎与分布式实时计算框架相结合可以为处理海量RFID数据、实时检测复杂的业务模式提供有效的解决途径。技术实现要素:本发明提供了一种分布式环境下面向RFID的复杂事件规则动态调度与数据恢复方法,具体包括分布式系统运行时复杂事件规则的动态调度方法,以及节点故障重启后规则数据的自动恢复方法。面向RFID的复杂事件规则动态调度与数据恢复方法,包括分布式系统中复杂事件规则的动态调度过程,以及节点故障重启后规则数据的自动恢复过程;复杂事件规则的动态调度是指:系统在处理源源不断的RFID原子事件过程中,无需停止应用即能动态地加入或删除规则,并最终将规则调度到合适的处理节点中进行添加或者删除;规则调度以减少集群中各个节点无效的原子事件和均衡各个节点的负载为目标,将规则分配到合适的规则组中,或者从规则组中找出特定的规则进行删除;将规则组信息以及规则组与集群中节点的对应关系作为元数据存储在Zookeeper服务器中,当有规则添加或者删除时根据规则调度算法更新元数据信息,并将更改的规则信息推送至添加了监听器的StormSpout节点中,最终根据自定义的流分组策略调度到最终的处理节点;规则数据的自动恢复指的是节点出现故障后能够自动重新启动,并且能够重新实例化Esper引擎并加载故障前的规则数据。进一步地,所述将规则组信息以及规则组与集群中节点的对应关系作为元数据存储在Zookeeper服务器中,规则调度算法不直接更新节点中Esper引擎的规则信息,而只是更新Zookeeper中规则组的元数据信息,当元数据信息发生变化时推送规则调度信息到添加了监听器的StormSpout节点中。进一步地,规则调度算法中,当需要增加新规则时,在规则组对应的节点不超过负载阈值的前提下,新增规则的关联阅读器集合与最终匹配的规则组的关联阅读器集合满足并集最小,交集最大的基本原则;当需要删除规则时,首先查找出该规则对应的规则组,然后将规则删除;规则的关联阅读器集合指的是EPL规则中出现的阅读器ID的并集,规则组的关联阅读器集合是规则组中所有规则的关联阅读器集合的并集。进一步地,StormSpout节点收到规则添加或者删除的消息后,根据自定义的流分组策略将规则调度到真正负责复杂事件处理的Bolt节点,并在其Esper引擎实例中添加或者删除规则。进一步地,所述规则数据的自动恢复过程中,在Storm集群中复杂事件处理的Bolt节点在发生故障后能够自动重启,并且节点故障前加载的规则数据也可以自动恢复。进一步地,所述恢复过程扩展了Storm本身的容错机制,Storm集群中的节点出现故障后能自动重启,但是之前保存的状态信息会丢失,而规则数据的自动恢复利用存储在Zookeeper服务器上的元数据信息,在节点重新启动进行初始化时通过规则集合以及规则集合与节点ID的对应关系,将之前的规则信息重新加载到Esper引擎中。进一步地,通过将规则元数据存储Zookeeper服务器的方式,实现分布式环境下规则的动态调度与规则数据的自动恢复,提高了分布式环境下面向RFID数据的复杂事件处理系统的吞吐量和稳定性。与现有技术相比,本发明具有如下优点和技术效果:(1)在支持事务的基础上设计Topology,保证事件的统计操作完全正确Strom框架虽然提供了一个通用的分布式计算模型,可是具体的计算过程仍然需要通过自行设计Topology来实现,而且Storm的Topology只能保证每个原子事件至少被处理一次,对于有统计相关的业务规则,如果事件由于中间节点故障而重新处理,则会导致基于数量统计的校验发生错误,因此需要使用基于Storm扩展的TridentTopology(支持事务的拓扑)来保证每个原子事件仅被处理一次。(2)实现Topology中各个节点相应的功能,保证系统的高容错和可扩展Spout节点分为两类:RFIDSpout和RuleSpout;Bolt节点主要分为四类:SchedulerBolt、EsperBolt、OutputAdapterBolt以及LoadCalculatorBolt,具体各个节点的功能可以参考3.3.1节的内容。此外,为提高整个系统的处理系统,负责执行复杂事件检测的EsperBolt会存在多个实例,需要提供相应的扩展性机制。最后,需要对Storm本身的容错机制进行改进,实现有状态的节点在故障恢复后,之前内容中的状态也能够恢复。(3)设计RFID中间件ALE层与拓扑的通信模型,保证通信的效率和可靠性传统基于WebService方式进行通信的方式,由于其通信协议SOAP以HTTP协议为基础来实现,当面对大量消息的实时处理时,其通信的效率和可靠性都不能得到很好的保障。因此在对RFID中间件与复杂事件处理系统进行集成时其通信模型需要基于底层的TCP协议并长连接的方式实现,以减少每次通信建立连接和释放连接的开销。(4)设计动态的规则调度算法,并基于该算法实现规则管理调度引擎Storm通过数据流分组(StreamGrouping)来定义一个数据流中的Tuple分发给哪些后续的Bolt处理节点。为了抬高整个系统的处理性能,对于RFID原子事件流的分发需要满足两个条件:第一需要保证分发时不会产生的过多的噪声数据;第二需要保证多个复杂事件处理节点的负载相对均衡。RFID原子事件流依赖于规则进行分组,因此需要以上述两点为目标设计优秀的规则调度算法,而规则管理调度引擎需要根据调度算法将规则分配到合适的处理节点。附图说明图1为系统功能架构图图2为实例中规则组元数据存储结构图。图3为RFID原子事件UML类图。图4为RFID原子事件与EPL规则的关系图。图5为动态的规则调度算法流程图。图6为Storm集群拓扑结构图。图7为面向规则的输入流适配器工作流程图。图8为规则调度信息UML类图。图9为RFID原子事件与EPL规则调度关系示意图。图10为流分组策略层工作原理图。图11为策略集合StrategyMapUML类图。图12为规则RuleUML类图。图13为流分组策略层工作流程图。图14为规则的动态加载和数据恢复流程图。具体实施方式为了使本发明的技术方案及优点更加清楚明白,下面结合附图,进行进一步的详细说明,但本发明的实施和保护不限于此,需指出的是,以下文字或附图中若有未特别详细说明之处如字符均是本领域及人员可参照现有技术理解或实现的。整个系统的总体架构如图1所示,其中RFID中间件由设备适配层、设备管理层和ALE服务层以及规则管理层组成,复杂事件处理系统由事件输入适配层、规则输入适配层、流分组策略层、复杂事件处理层、输出适配层以及负载计算层组成。RFID阅读器采集的数据经由ALE服务层进行预处理,以ECReport的形式传递给输入适配层,输入适配层将数据转换为原子事件并通过事件流分组策略层交给合适的后续处理节点。而规则管理层通过与规则元数据存储层的交互,最终通过规则输入适配层将规则调度元数据推送到事件分组策略层,流分组策略层将规则及其操作信息(增加或者删除)发送给合适的复杂事件处理单元,实现在运行时新规则的加载以及旧规则的卸载。分布式系统基于实时计算框架ApacheStorm实现,复杂事件规则采用Esper引擎的EPL语言进行描述,RFID中间件作为RFID原子事件发生器产生RFID原子事件,系统中的每个节点对应一个Executor线程,每个线程对应一个Esper引擎实例负责检测复杂事件,每个Esper引擎的实例维护一个规则组对输入的RFID原子事件进行处理,各个规则组的交集为空。规则动态调度方法将规则组中的信息以及规则组与集群中处理节点的对应关系作为元数据保存在Zookeeper服务器中,并以减少系统中各个节点的无效原子事件和均衡各个节点的负载为目标,将新加入系统的规则调度到Zookeeper中对应的规则集合中,Zookeeper将规则调度信息推送到Storm集群中规则对应的Spout节点,该Spout节点通过自定义的流分组策略最终将规则调度到合适的处理节点,并根据调度信息在Esper引擎中添加或者删除规则。规则调度的过程中系统可正常接收和处理RFID原子事件,RFID原子事件通过自定义的流分组策略到达最终负责处理的节点。Storm提供的容错机制使得在节点故障后可以自动重新启动,但是并不能恢复故障前的状态信息,规则数据的自动恢复方法在节点重新启动后重新实例化Esper引擎,并通过Zookeeper中的规则组和节点ID的对应关系加载规则组中的规则数据到引擎实例中。1.规则组元数据存储结构本方法涉及的规则组数据以及规则组与集群中节点的对应关系在Zookeeper服务器中的存储结构如图2所示,具体包含两个根节点:RuleZnode和MatchZnode,其中虚线表示该节点在创建后,内容会发生变化,实线表示节点创建后,节点内容不会发生变化,并且只有叶子节点才可以在操作过程中被删除。(1)RuleZnodeRuleZnode是规则调度算法的计算结果,它存放着对新增加规则或者待删除规则的调度信息,其中的根节点为rule_znode,它的子节点rule_group节点表示各个规则组,每一个规则组和一个具体执行复杂事件处理逻辑的节点相对应。每个rule_group创建时其下都包含了四个子节点,其中rule_list下存放着具体的规则,其中描述规则的EPL语句和自然语句以“#”分隔;current_rule存放的是当前增加或者要删除的规则对应的EPL语句以及自然语言描述;current_operation节点存放的是当前要进行的操作是新增还是删除,其值为“add”或者“delete”;reader_set下存放着该规则组的关联阅读器集合,每个阅读器名称之间用逗号分隔。(2)MatchZnodeMatchZnode的根节点是match_znode,它的子节点rule_group与rule_znode一样都是在通过RuleManager增加新的规则组group_name时生成,同时rule_group的两个子节点也被初始化,这两个子节点分别代表着对应的复杂事件处理节点的ID,以及该节点的负载。在初始化时,没有为规则组分配相应的处理节点时,esper_task_id和load子节点的默认值分别为-1和0。2.RFID原子事件与EPL规则系统接收的RFID原子事件是一个Bean对象,其UML类图如图3所示,其中epc表示RFID标签的EPC码,type表示RFID标签对应的实体类型,time表示RFID标签读取的时间,reader表示读取标签的阅读器ID,otherAttrs表示可扩展的其他属性,如表1。一个RFID原子事件的示例如下所示,它表示客户编号31782324且SKU为151387产品在2016年3月30日下午15点10分出现在01号入库大门处。表1属性名称属性值epc31782324.1513877.0000000007type31782324.1513877.*time1459321802readerReader_Indoor_01otherAttrsnull复杂事件规则采用Esper引擎的EPL语言进行描述,RFID原子事件与EPL规则的关系如图4所示,图中EPL规则的关联阅读器集合为{Reader_Check_01,Reader_Outdoor_01},而event1表示标签被阅读器Reader_Check_01读到,因此对于规则是有效的,而event2被阅读器Reader_Indoor_02读到,与规则没有关系,对于该规则来说是无效事件。3.动态的规则调度规则调度算法以减少集群中各个节点无效的原子事件和均衡各个节点的负载为目标,将规则添加到合适的规则组中,或者找到规则对应的规则组将规则从中删除。一个节点的无效原子事件数指的是一段时间内规则组中所有规则对应的无效事件的总和,每个节点的负载指的是一段时间内规则组中每条规则处理的原子事件总和。规则调度的具体算法流程如图5所示,其中对于新增规则的调度来说,该算法的核心思想是:在规则组不超过负载阈值的情况下,新增规则的关联阅读器集合与最终匹配的规则组的关联阅读器集合满足并集最小,且交集最大的基本原则,其中主要分为四种情况:(1)新增规则的关联阅读器集合是某个规则组关联阅读器集合的子集,如果有至少一个规则组满足要求,选择并集最小的规则组,如果有多个规则组满足并集最小的情况,选择负载最小的规则组;(2)新增规则的关联阅读器集合与某些规则组的关联阅读器集合存在交集,且新增规则的关联阅读器集合不是子集,如果有至少一个规则组满足要求,优先选择并集最小的规则组,这个基础上如果有多个规则组满足要求,选择交集最小的规则组,这个基础上如果还有多个规则组满足要求,选择负载最小的规则组;(3)所有规则组的关联阅读器集合都是新增规则关联阅读器集合的子集,选择并集最小的规则组,如果有多个规则组满足情况,选择负载最小的规则组;(4)新增规则关联阅读器集合与所有规则组的关联阅读器集合都没有交集,选择负载最小的规则组。4.Storm集群的拓扑结构Storm集群的拓扑结构如图6所示,其中数据流包含两类:一类是事件流,另外一类是规则流,而拓扑中的处理节点包含RFIDSpout、RuleSpout、SchedulerBolt、EsperBolt、EventOutputAdapterBolt以及LoadCalculatorBolt。RFIDSpout接收来自RFID中间件的RFID原子事件;RuleSpout接收规则调度服务器Zookeeper推送的规则调度元数据信息,其中包含了规则描述信息、规则操作信息(新增还是删除)、规则组信息;SchedulerBolt分别实现了针对规则调度元数据和RFID原子事件的的流分组策略;EsperBolt的每个节点都对应一个Storm的Executor线程实例,这些实例分布在不同的Worker进程中,每个Executor实例拥有一个Esper引擎的引用,每一个Esper引擎加载一个规则组中的规则并处理接收的原子事件,检测复杂的业务模式;EventOutputAdapterBolt接收来自各个EsperBolt的复杂事件流,对检测出的复杂事件进行进一步分组、统计、校验等处理;LoadCalculatorBolt用来统计各个EsperBolt节点的负载,并定时更新Zookeeper中的负载信息。4.1面向规则的输入流适配器面向规则的输入流适配器RuleSpout接收Zookeeper服务器推送的规则调度元信息,并将其包装成流分组策略层可以处理的规则调度信息,其工作流程图如图7所示。规则调度信息ScheduledRule的UML类图如图8所示,其中epl属性指的是用EsperEPL语言描述的规则;operarion属性的值为“add”或者“delete”,表示该次调度是向相应的处理节点新增规则还是删除规则;属性groupName指的是规则组的名称,groupName最终会被发送到后续的SchedulerBolt,并且在SchedulerBolt中建立起与后续EsperBolt节点一一对应的关系,EsperBolt的taskId与gropuName的对应关系会被更新到Zookeepr的MatchZnode节点中;属性connectedReaderSet是规则EPL关联的阅读器集合;而description属性是用自然语言描述的EPL规则对应的复杂事件。其中属性groupName以及属性connectedReaderSet是对数据流进行分组的重要依据。4.2流分组策略层流分组策略层包含了Storm拓扑中的SchedulerBolt节点,它接收RFIDSpout节点传来的RFID原子事件流,以及RuleSpout传来的规则调度信息ScheduledRule对象,并根据自定义的流分组策略将数据发送到合适的复杂事件处理节点EsperBolt。分组策略包含了两类:面向规则的分组策略以及面向RFID事件流的分组策略。规则调度信息经过流分组策略层只能够到达一个处理节点,而RFID原子事件经过流分组策略层可以到达多个符合要求的处理节点,其关系如图9所示。流分组策略层以StrategyMap为核心,同时调度RFID原子事件和规则信息,在调度规则时根据ScheduledRule对象转换为Rule对象进行调度,具体的关系如图10所示。其中StrategyMap的UML类图如图11所示,Rule的UML类图如图12所示,流分组策略层的工作流程如图13所示。5.规则的动态加载和数据恢复规则的动态加载在Storm集群中复杂事件处理层中的各个节点中实现,每个EsperBolt节点作为一个Executor线程拥有一个Esper引擎的实例,Esper引擎通过为加载的每个规则维护一个非确定有限状态自动机来实现复杂事件的检测,当又复杂事件发生时通过触发监听器将检测到的复杂事件发送到下游处理节点。当处理节点接收的Tuple元组为RFID原子事件时,会将原子事件直接输入到引擎实例中进行处理,当接收的Tuple元组为规则时,按照operation属性从引擎实例中加载或者卸载规则。如果处理节点出现故障,Storm集群通过Supervisor进程重新启动节点,之后实例化Esper引擎,并根据Zookeeper服务器中规则组与处理节点的对应关系重新加载规则,规则加载完成后接收故障期间没有处理的RFID原子事件。复杂事件处理层动态加载规则和恢复数据的工作流程如图14所示。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1