一种社交媒体中企业硬件设施敏感信息防护方法与流程
本发明涉及一种社交媒体中企业硬件设施敏感信息防护方法,属于隐私保护
技术领域:
。
背景技术:
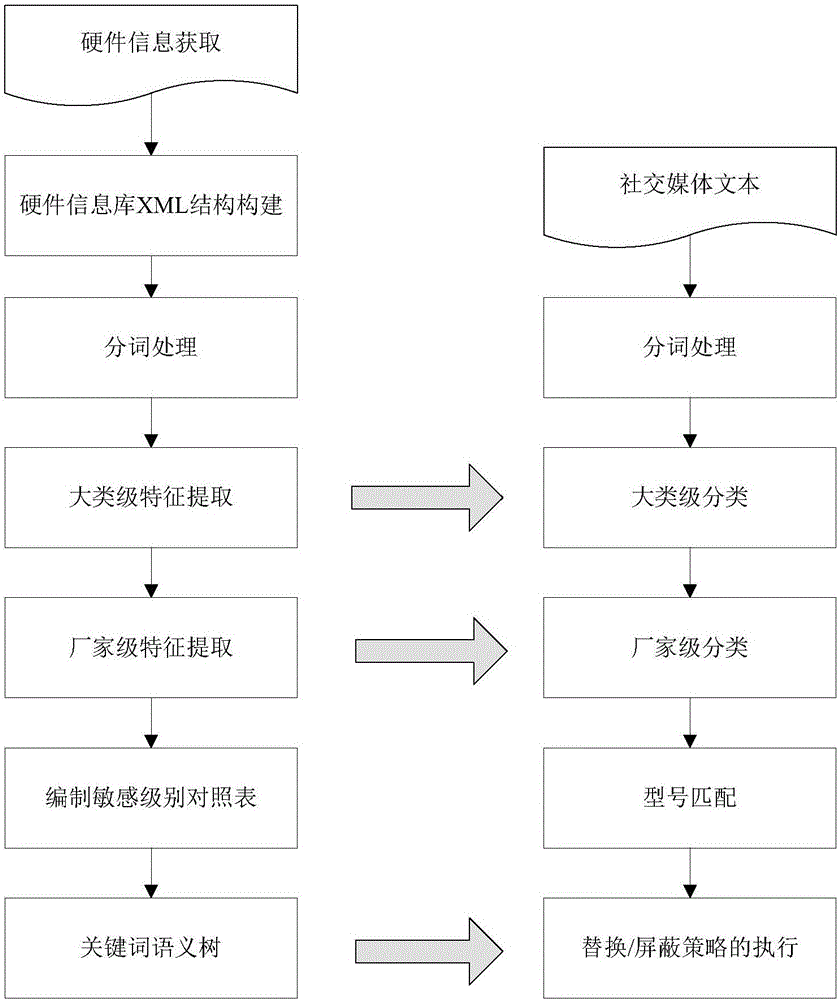
:伴随着微博、网络论坛等传统的社交媒体以及微信、Facebook、Twitter等新兴的社交媒体的出现,人们进入了社交媒体时代。社交媒体的快速兴起加速了信息的流动,使得人与人之间的沟通变得越来越便捷。但不可忽视的是,社交媒体的广泛使用也带来了安全上的隐患,社交媒体用户也在有意或无意地对企业或机构的机密敏感信息造成了威胁,这些信息如果被商业机构或一些不法分子非善意获取、整合和利用,就会导致个人或机构隐私泄露[1]。移动设备用户可以很方便地依靠基于位置的服务获得自己的位置和相关的服务信息。尽管基于位置的服务为用户提供了极大的方便,但基于位置的服务需要先获取移动用户的位置信息才能对用户提供相应的服务,而基于位置的服务系统并不能保证服务器不泄露或非法使用用户的位置信息。因此基于位置的服务给用户的位置隐私保护带来了极大的挑战[2]。另外随着近年来大数据技术的兴起,基于大数据技术的隐私保护技术也越来越多,但总体上来说,当前国内外针对大数据安全与隐私保护的相关研究还不充分,只有通过技术手段与相关政策法规等相结合,才能更好地解决大数据安全与隐私保护问题[3]。随着互联网的广泛应用,国内外关于隐私保护或商业机密保护的研究也越来越多。隐私保护的主要研究方向包括通用的隐私保护技术、面向数据挖掘的隐私保护技术、基于隐私保护的数据发布原则、隐私保护算法等。通用的隐私保护技术致力于在较低应用层次上保护数据的隐私,一般通过引入统计模型和概率模型来实现;面向数据挖掘的隐私保护技术主要解决在高层数据应用中,如何根据不同数据挖掘操作的特性,实现对隐私的保护;基于隐私保护的数据发布原则是为了提供一种在各类应用可以通用的隐私保护方法,进而使得在此基础上设计的隐私保护算法也具有通用性。作为新兴的研究热点,隐私保护技术不论在理论研究还是实际应用方面,都具有非常重要的价值[4]。传统的敏感信息防护方法主要是基于关键词匹配的过滤方法,但这种方法忽视了上下文的语义环境,准确性较低,并且难以抵抗人工干扰,需要维护大量的关键词词典,人工成本较高。新兴的敏感信息防护方法包括基于自然语言处理和人工智能的防护方法,但这些技术尚处于研究阶段,并不能满足实际情况下对于过滤准确性的要求。技术实现要素:本发明不从宏观的角度对敏感信息的防护进行研究,而是选取隐私或商业机密保护的某一具体方面,即社交媒体中企业硬件信息保护进行研究,给出了相应的信息保护方法。如前所述,社交媒体用户在发表言论的时候有可能导致隐私信息的泄露,同样地,当企业内部人员在微博或论坛等社交媒体上发表言论时也有可能导致企业内部硬件型号、配置等敏感信息的泄露。为了解决上述技术问题,本发明提出了一个新的角度,即结合了文本分类和语义替换的策略进行信息防护。其基本思路是首先通过分类确定信息发布者所描述的硬件类别和型号,然后从已经建立的硬件信息库中查找该型号硬件的所有属性信息,并根据该属性信息中的关键词去屏蔽或替换发布者所发布的硬件描述信息中的关键词。本发明的主要创新点在于构建了硬件信息库、设计了硬件信息分类模型和硬件型号匹配算法、给出了关键敏感词替换方法;本发明的技术方案具体介绍如下。本发明提供一种社交媒体中企业硬件设施敏感信息防护方法,具体步骤如下:步骤一、构建模型(1)硬件信息库的构建获取硬件信息,提取包括硬件大类、厂家和型号在内的多个层级、属性和属性值信息,组织成XML层次结构,构建硬件信息库;(2)对硬件信息库中的硬件描述信息进行中文分词(3)构建硬件分类模型和硬件型号匹配算法对硬件信息库中的硬件描述信息进行分词后,首先提取大类的特征信息,再在大类分类的基础上,提取厂家的特征信息,构建厂家分类模型;最后通过大类和厂家的类别信息,构建硬件型号匹配算法,确定硬件的型号;(4)构建关键词屏蔽替换模型针对每一个硬件大类,对硬件描述信息中出现的属性关键词进行敏感级别划分,并对不同敏感级别的关键词采取不同的处理方式,构建关键词屏蔽替换模型;其中,敏感级别划分为0、1、2、3和4;对于敏感级别为0的关键词不作处理,对于敏感级别为4的关键词直接用星号屏蔽,对于敏感级别为1、2、3的关键词通过关键词语义树进行处理;所述关键词语义树由硬件信息库中不同层级上的关键词按照XML结构关系构建;关键词语义树有四层,基于关键词语义树的替换策略如下:对于敏感级别为1的关键词,采用其父节点进行替换;对于敏感级别为2的关键词,采用其父节点的父节点进行替换;对于敏感级别为3的关键词直接利用根节点进行替换;步骤二、检测防护对输入的社交媒体内容进行分词处理后,根据步骤一中的硬件分类模型和硬件型号匹配算法确定归属大类、归属厂家和归属型号;确定型号后,再利用步骤一中构建的关键词屏蔽替换模型,将分词后的社交媒体内容中的属性关键词,利用对应的敏感级别和处理方式执行相应的动作,即屏蔽、替换和不作处理。本发明中,硬件分类模型中通过特征选择算法和分类算法对硬件大类和硬件厂家进行分类。本发明中,进行硬件大类的分类时,特征选择算法采用改进的信息增益的方法;具体计算公式如下:其中,t是特征,c表示类别,k表示类别个数,dis(t)表示特征t在类间的分布,它是特征t出现的样本数和所有样本总数的比值,P(t)表示特征出现的概率,P(c)表示类别出现的概率,P(c,t)表示特征和类别共同出现的概率,表示特征不出现的概率,表示特征不出现样本属于类别c的概率。分类算法采用改进的KNN的方法,其中的距离计算公式如下:其中,x代表未分类样本,y代表已分类样本,它们都是n维向量,向量中的每一维代表一个特征值,IG’(ti)代表第i个特征ti的信息增益值,x=(x1,x2,…,xn),y=(y1,y2,…,yn),d(x,y)表示x和y之间的距离,xiyi表示样本的第i个特征值。本发明中,进行硬件厂家的分类时,特征选择算法采用采用特征相似度的方法进行特征选择;采用类之间在特征上的相似度来选择特征,定义p个类之间在特征ti上的相似度,令这p个类分别是c1,c2,…,cp,定义这p个类在特征ti上的相似度为任意两个类在ti上的相似度和的平均值,即:如果则认为特征ti在这p个类之间相似度过大,不适合作为分类的特征,反之则可以作为分类的特征;分类算法采用改进的KNN的方法,其选择相似度的倒数作为特征的权重参与到KNN算法的计算中,以下是具体的KNN的距离计算公式:其中,ci表示第i个类别,p是类别总数,ti表示第i个特征,n为特征总数,x=(x1,x2,…,xn),y=(y1,y2,…,yn)分别表示未分类样本和已分类样本,它们具有n个特征值xiyi。本发明中,硬件型号匹配算法采用基于硬件型号集合的方法,即将相同属性值的硬件型号放到一个集合中,通过确定待匹配硬件在某些属性上的属性值,从而确定该硬件所属的型号集合,然后求这些集合的交集,得到该硬件所属的型号。本发明中,关键词语义树的最底层的叶子结点是硬件信息库中XML结构的最内层属性关键词的子特征词,语义树的倒数第二层对应的是硬件信息库中XML结构的最内层属性关键词,语义树的倒数第三层是XML结构的第二层属性关键词,第四层为根结点,根节点为硬件大类的名称。和现有技术相比,本发明具有实质性特点和显著进步:(1)可以用于发现社交媒体内容发布时所存在的可能泄露企业硬件信息的敏感内容,提供了细粒度的内容控制方法,相比于现有方法只能对整个内容进行控制的粗粒度方式具有一定先进性,尽可能地保留了社交媒体内容共享的本质需要。(2)设计了基于大类、厂家和型号三个层次的分类和匹配方法,可以充分利用同类别的词汇、属性等信息,提高检测的召回率,避免硬件敏感的泄露。同时在匹配时缩小搜索范围,只需要在同一个厂家的信息库中进行匹配,提高了匹配效率。(3)在硬件信息库结构、特征选择、分类器构建以及防护方法上提出了新的思路和实现方法,设计了XML的结构形式,改进了信息增益计算方法,设计了基于厂家类别特征相似度的特征选择方法,构建了关键词语义树,给出了具体的防护策略。附图说明图1是本发明的总体流程图。图2是硬件厂家的分类流程示意图。图3是硬件型号匹配方法的流程示意图。图4是关键词屏蔽替换方法的流程图。图5是硬件信息库(XML结构)图。图6是实施例中语义树的每层关键词和XML每层关键词之间的对应关系图。图7是实施例中建立的语义树的最终样例图。具体实施方式下面结合附图和实施例对本发明的技术方案进行详细说明。本发明的总体流程见图1所示,具体包含了图1中左边的构建模型流程和右边的检测防护流程,其中模型构建流程在三个环节的处理结果为检测防护流程提供必要的基础数据。本发明的主要工作包括:(1)硬件信息库的构建;(2)对硬件描述信息进行中文分词;(3)构建硬件分类模型和硬件型号匹配算法;(4)构建关键词屏蔽替换方法。下面依次对上述过程中所涉及的关键技术进行详细解释。1、硬件信息库的构建实施例中,针对某大型电脑网,设计了网络爬虫程序,自动爬取了36个大类上万种型号的硬件信息,包括手机、笔记本、交换机、路由器等。将这些硬件信息组织成XML文件的形式,其中XML的每一个标签代表该硬件的属性,标签所对应的文本描述内容代表该硬件的属性值。通过XML本身的结构描述能力,构造了树形硬件信息库。该硬件信息库构成了后续处理流程所需要的基本信息源。构建的硬件信息库(XML结构)如图5所示。2、对硬件信息进行中文分词虽然在第1步的工作中已经获得了所有型号的硬件信息,但这些信息不能直接用于计算机处理,需要进行中文分词,去掉辅助词,提取出其中的关键词,然后利用提取出的关键词进行后续的分类处理等工作。目前常见的分词方法都可以用于该步骤,例如中国科学院计算技术研究所研制的基于层次隐马尔科夫模型的汉语词法分析系统ICTCLAS等,支持用户词典和多种编码格式,分词正确率高达97.5%。3、构建硬件分类模型和硬件型号匹配算法在分词的基础上,本发明通过构建分类模型和硬件型号匹配算法来确定硬件描述信息所描述的硬件型号。而硬件分类模型包括两个子分类过程,分别是硬件大类的分类和硬件厂家的分类,其中硬件厂家的分类是在硬件大类分类的基础上进行的。经过这两个步骤就可以确定硬件所属的类别和厂家,最后通过硬件型号匹配方法就可以确定该硬件所属的型号,下面就对这三个过程的基本思路进行描述。(1)硬件大类的分类硬件大类的分类借鉴了文本分类中的KNN分类方法,首先通过特征选择选出那些对分类贡献较大的特征词,然后通过分类算法对硬件进行分类。本发明的特征选择算法和分类算法分别借鉴了信息增益的方法和KNN的方法,但针对硬件信息库的特点进行了改进,有助于提高分类的准确性。传统的信息增益方法只考虑了特征词是否出现对全局信息熵的影响,而没有考虑特征词在类内和类间出现的频率问题,本发明对传统的信息增益方法进行了改进,考虑了特征词在类间的频率,提高了特征选择的效果。改进的信息增益方法的计算公式如下:其中,dis(t)表示特征t在类间的分布,它是特征t出现的样本数和所有样本总数的比值。之所以选择作为调整系数是基于以下两个原因,首先,是dis(t)的减函数,即特征t在类间的分布值很小的时候,比较大,这正好符合要求;其次,选择为调整系数可以平衡传统的信息增益值IG(t)和特征t的类间分布值dis(t)之间的权重,使计算结果不致过多依赖某一方。同样地,本发明对传统的KNN算法进行了改进,改进之处在于考虑了不同的特征对分类的影响不同,利用特征选择的信息增益值作为KNN算法的权重,一个特征的信息增益值代表该特征对信息熵的影响大小,如果信息增益值越大,则该特征对分类的结果的影响越大,所以直接利用特征的信息增益值作为该特征在KNN算法中的权重,这样就可以体现不同信息增益值的特征对分类的贡献度。下面给出了改进后的KNN算法中距离的计算公式。其中,x代表未分类样本,y代表已分类样本,它们都是n维向量,向量中的每一维代表一个特征值。IG(ti)代表第i个特征ti的信息增益值。x=(x1,x2,…,xn),y=(y1,y2,…,yn)。(2)硬件厂家的分类硬件大类的分类之后,硬件厂家的分类是确定硬件在该类别下的某个厂家。同样地,在这一步的分类中需要进行特征选择和利用合适的分类算法进行分类。本发明所采用的特征选择算法是基于特征相似度的计算方法,即针对每个特征,考察它们在不同厂家类别之间的特征相似度,如果该特征相似度大于或等于某个阈值,则认为该特征在不同厂家之间过于相似,不适合作为分类的特征,反之则可以作为分类的特征。同样地,在这一部分的分类中继续采用改进的KNN分类算法,只是将特征的权重改为特征相似度的倒数的对数,具体如下介绍。在硬件信息库中,每一个硬件特征可能会包含多个子特征,如“外形尺寸”这一特征的特征值包含长、宽、高三个维度值。在这里,长度、宽度、高度就是“外形尺寸”这一特征的三个子特征。假定特征ti由n个子特征组成,即ti=(ti1,ti2,…,tin)。某一个样本在特征ti上的特征值为另外一个样本在特征ti上的特征值为则定义和之间的相似度为:即利用向量之间夹角的余弦来定义两个特征之间的相似度。由于所要考察的不同特征可能包含不同的子特征个数,即不同的维数,所以这样做的目的是可以忽略向量的维数,着重从两个向量夹角的角度考察两个向量之间的相似度,当两个向量,即两个特征相似时,夹角的余弦值较大,反之则较小。定义完单个特征的相似度之后,接下来给出两个类之间在某个特征上的相似度的计算方法。由于每个类可能包含多个样本,所以假定两个类c1和c2包含的样本数分别是m1和m2,则定义这两个类在特征ti上的相似度计算如下:由上式可以看出,对两个类在特征ti上的相似度定义是直接取两个类所有样本对在特征ti上相似度的均值,这样做可以把两个类之间所有样本对在特征ti上的相似度均考虑进去。在两个类之间在特征ti上的相似度计算基础上,下面定义p个类之间在特征ti上的相似度。令这p个类分别是c1,c2,…,cp,定义这p个类在特征ti上的相似度为任意两个类在ti上的相似度和的平均值,即:如果这p个类在特征ti上的相似度大于或等于某一阈值δ,即则认为特征ti在这p个类之间相似度过大,不适合作为分类的特征,反之则可以作为分类的特征。在个步骤的分类仍然采用改进的KNN算法进行分类,只是在这里特征的权重要发生改变,不再是信息增益值,而是特征的相似度的倒数。之所以选择选择特征相似度的倒数作为特征的权重是基于这样的原因,特征相似度代表不同类别之间在该特征上的相似程度,对于相似度较高的特征,它们对分类的贡献不大,应当赋予较小的权重,而对于相似度较低的特征则对分类的贡献较大,应当赋予较高的特征,所以本发明选择相似度的倒数作为特征的权重参与到KNN算法的计算中是合理的,以下是具体的KNN的距离计算公式:硬件厂家的分类流程如下,图2展示了相应的流程图。1)从硬件信息库中选择某一类别下不同厂家的样本;2)针对不同的特征计算该特征在不同厂家之间的特征相似度;3)如果该特征的特征相似度小于某个阈值,则将该特征作为分类特征,否则返回2),选择下一个特征继续计算特征相似度;4)利用选出的特征和改进的KNN算法进行分类,得到相应的厂家类别。(3)硬件型号的匹配在确定了硬件的类别和该类别下的厂家之后,本发明通过构建硬件型号匹配算法来确定该硬件在该厂家下的型号。本发明所采用的硬件型号匹配算法是基于硬件型号集合的方法,即将相同属性值的硬件型号放到一个集合中,当需要确定某个硬件的型号时,只需要确定该硬件在某些属性上的属性值,这样就可以确定该硬件所属的型号集合,然后求这些集合的交集就可以得到该硬件所属的型号。这种硬件型号匹配方法相对于逐次进行硬件型号比对来说在效率上具有很大的优势,能够大大减少比对的次数。在进行硬件型号匹配的时候并不是把所有的产品逐一比对一遍,而是建立了一个新的算法使比对有更高的效率。具体来说,假如该类别的产品具有n个属性(t1,t2,…,tn),每一个属性ti都包含ai个子特征,即把该厂家生产的产品中在属性ti上相同的产品划归到一个集合中去。并且由于某种型号的产品可能在不止一个属性上和其他产品相同,所以该型号的产品可能在不同的集合中都会出现,也即各个集合之间可能互有交集。假如该硬件的描述信息中出现了p个属性,分别是属性的特征值是则硬件型号匹配的算法描述如下:1)将属性ti上具有相同属性值的硬件型号放在同一个集合中;2)令i=1,C=Ω,其中Ω表示全集;3)寻找和属性具有相同属性值的集合4)5)如果C只包含一个元素或者i>p,则进行6),否则i=i+1,并返回3);6)返回集合C,集合C便是最终的硬件型号比对结果。图3展示了硬件型号匹配方法的具体的流程图,主要步骤说明如下。1)针对每一属性构建具有相同属性值的硬件型号集合;2)取出某一属性,考察该硬件在该属性上的属性值,得到该属性值对应的硬件型号集合;3)将该硬件型号集合和已经得到的硬件型号集合取交集,如果交集只包含一个元素或者属性已经取完则停止,交集中的元素即为该硬件所属的型号,否则返回2);4、构建关键词屏蔽替换模型本发明通过设计关键词屏蔽替换模型对硬件描述信息中所出现的有可能泄露硬件敏感信息的关键词进行屏蔽替换。其针对不同的关键词划分不同的敏感级别,并对不同敏感级别的关键词采取不同的处理方式。(1)关键词敏感级别划分针对每一个硬件大类,事先建立所有的属性值关键词的5个敏感级别,分别用数字0、1、2、3、4表示,它们的敏感程度依次上升,具体见表1所示。表1敏感级别对照表敏感级别01234意义不敏感稍微敏感一般敏感比较敏感十分敏感处理方式不作处理替换替换替换屏蔽对不同敏感级别的关键词采取不同的处理方式。其中,对于敏感级别为0的关键词不作处理,对于敏感级别为4的关键词直接用星号屏蔽,对于敏感级别为1、2、3的关键词通过构建语义树的方式进行处理。(2)关键词语义树的构造通过构建语义树的方式对敏感级别为1、2、3的关键词进行替换。语义树中叶节点是语义最具体的关键词,随着节点层次的上升,语义逐渐模糊,根结点是语义最模糊的节点。对于硬件描述信息而言,其语义树总共有4层,基于语义树的替换策略如下:对于敏感级别为1的关键词,采用其父节点进行替换;对于敏感级别为2的关键词,采用其父节点的父节点进行替换;对于敏感级别为3的关键词直接利用根节点进行替换。在硬件信息库中每一个型号硬件的XML文档是一个层次结构,并且上层的属性关键词比下层的属性关键词的在语义上更加模糊,所以可以利用该XML文档去建立的关键词语义树。本发明建立语义树的方法是这样的,最底层的叶子结点是最内层属性关键词的子特征词。语义树的倒数第二层对应的是硬件信息库中XML结构的最内层属性关键词,它们在语义上要比各自的子特征词更加模糊。语义树的倒数第三层是XML结构的第二层属性关键词,由于XML文档的第一层是该硬件的具体型号,这是十分敏感的信息,所以语义树的倒数第四层并不对应XML文档的第一层,而是采取了比倒数第三层语义上更加模糊的硬件大类的名称作为该层的关键词,由于倒数第四层已经上升到了硬件大类的名称,所以该层也是整个语义树的第一层,即根结点。图6展示了语义树的每层关键词和XML每层关键词之间的对应关系,图7展示了建立的语义树的最终样例,样例中的“第二层属性关键词”和“第三层属性关键词”均是指XML文档中的第二层和第三层属性关键词。应用实例由于互联网社交媒体上可得的与企业IT硬件设施相关的信息内容还不是很多,搜集起来比较困难。这里的实例验证中,首先从硬件信息库中提取了5000条硬件描述的部分信息,并将这些描述信息整理成文本文档,每一条描述信息对应一个文本文档。所用的分词后的关键词样本(经过随机删除一些关键词)与从社交媒体获取的内容处理之后是一致的,因此经过处理后的数据可以近似模拟社交媒体中的硬件描述信息样本。从每一大类中任选60个样本作为训练样本,总的训练样本有2160个,而每一类剩余的40个样本则作为待分类样本进行测试,总共有1440个测试样本,得到分类性能与k值的关系如表2所示。表2不同k值条件下硬件大类的正确分类比例和F1平均值参数k151015202530正确分类比例80.1%72.8%69.3%67.3%65.7%63.8%60%F1平均值0.8050.7340.7060.6890.6760.6630.639在硬件厂家分类中,以“手机”这一硬件大类为例对硬件的厂家进行分类,选取手机的八个厂家,分别是三星、苹果、华为、OPPO、vivo、魅族、联想、酷派。测试了不同k值条件下正确分类样本的比例和F1平均值,得到的验证结果如表3所示。表3不同k值条件下厂家的正确分类样本的比例和F1平均值参数k15101520253035正确分类比例42.4%36.0%34.7%35.6%31.8%35.6%33.5%31.4%F1平均值0.4220.3500.3390.3280.2950.3190.2990.281随机选出手机类别下的200个文本,将各个子特征值根据其对应的子特征词的敏感级别进行相应的处理,最终的统计数据如表4所示。表4部分关键词屏蔽替换的性能数据子特征词全网通移动4G联通4G电信4G横向子特征词个数20897641138正确处理的个数20897641138正确率100%100%100%100%100%参考文献[1]郭晴.社交媒体使用中用户信息隐私及保护[J].中国信息安全,2014,(7):90-93.[2]魏琼,卢炎生.位置隐私保护技术研究进展[J].计算机科学,2008,35(9):21-25.[3]冯登国,张敏,李昊.大数据安全与隐私保护[J].计算机学报,2014,37(1):246-258.[4]周水庚,李丰,陶宇飞,肖小奎.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-861。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1