基于CBR有限元模板的检索方法与流程
本发明涉及一种基于CBR有限元模板的检索方法。
背景技术:
现有技术中,随着计算机广泛应用和发展,越来越多的大型工程软件得到了广泛的应用,特别是在工业方面,近些年制造业发展迅速,特别是德国提出工业4.0以后,世界工业的发展正在向更高的水准发展,为了应对发展形势,我国也相应提出了中国制造2025,在这个大的发展趋势背景下,产品设计分析类软件,如有限元分析的应用将会有爆炸性的需求,对设计类人才的数量也将增多;然而,有限元分析类软件属于大型工程型软件,学习困难、人才培养周期长等缺点,在上述背景下,提出一种基于CBR有限元模板的检索方法,服务于一种CAE智能辅助系统。
技术实现要素:
本发明的目的是提供一种使有限元分析过程中更好地进行案例检索匹配,得出精确的求解方案的基于CBR有限元模板的检索方法。
本发明为实现上述目的所采用的技术方案是:一种基于CBR有限元模板的检索方法,包括以下步骤:
A、通过语义标注源案例,生成相应的XML文件;
B、根据语义标注信息,进行案例三级检索;
C、根据步骤B的检索顺序进行直接相似度计算;
D、根据步骤B的检索顺序进行间接相似度计算;
E、根据步骤C、步骤D计算综合语义相似度;
F、根据步骤B的检索顺序,设定检索内容的权重;
G、根据步骤E、F计算全局相似度,即为源案例与目标案例的相似度;
H、根据步骤G的结果,进行全局相似度排序;
I、根据步骤H的排序结果,找出最匹配案例。
所述步骤B中的三级检索,首先根据案例分析信息检索,缩小检索范围,再依据模型特征信息进行检索,再次缩小检索范围,最后再依据模型属性信息进行检索,使检索范围再次缩小,然后结合上述检索确定的范围,进行交集运算,源案例与交集里的目标案例集分别进行相似比较。
本发明一种基于CBR有限元模板的检索方法,使有限元分析过程中更好地进行案例检索匹配,得出精确的求解方案。
附图说明
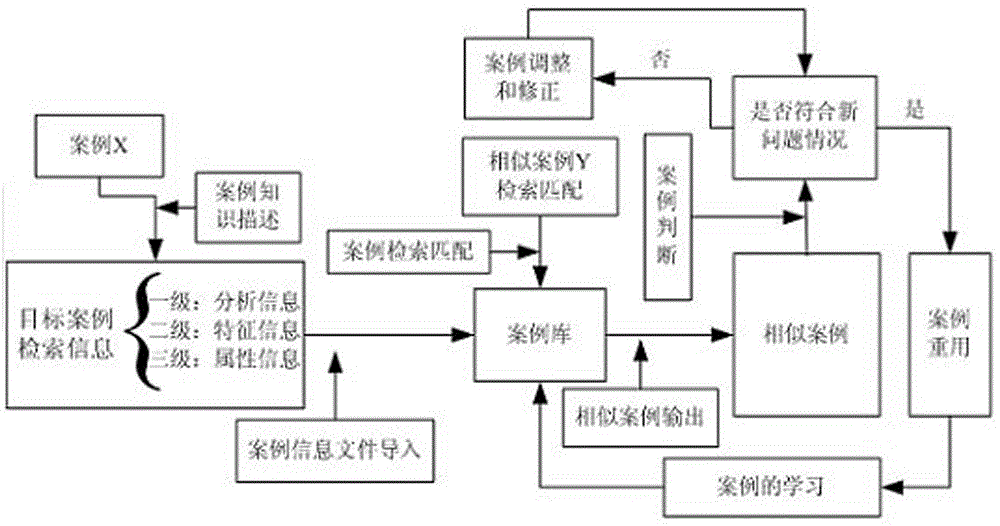
图1是本发明一种基于CBR有限元模板的检索方法的案例检索匹配流程图。
图2是本发明一种基于CBR有限元模板的检索方法的分析意图本体语义树。
图3是本发明一种基于CBR有限元模板的检索方法的优先级检索过程图。
图4是本发明一种基于CBR有限元模板的检索方法的建模特征语义树。
图5是本发明一种基于CBR有限元模板的检索方法的XML映射树匹配原理图。
具体实施方式
如图1至图5所示,基于CBR有限元模板的检索方法,包括以下步骤:A、通过语义标注源案例,生成相应的XML文件;B、根据语义标注信息,进行案例三级检索,首先根据案例分析信息检索,缩小检索范围,再依据模型特征信息进行检索,再次缩小检索范围,最后再依据模型属性信息进行检索,使检索范围再次缩小,然后结合上述检索确定的范围,进行交集运算,源案例与交集里的目标案例集分别进行相似比较;C、根据步骤B的检索顺序进行直接相似度计算;D、根据步骤B的检索顺序进行间接相似度计算;E、根据步骤C、步骤D计算综合语义相似度;F、根据步骤B的检索顺序,设定检索内容的权重;G、根据步骤E、F计算全局相似度,即为源案例与目标案例的相似度;H、根据步骤G的结果,进行全局相似度排序;I、根据步骤H的排序结果,找出最匹配案例。
本发明的基于CBR有限元模板的检索方法,使有限元分析过程中更好地进行案例检索匹配,得出精确的求解方案,根据有限元的本体语义知识建立有限元案例库;用XML标注案例的分析意图信息,建立本体语义案例库,存储以往成功解决的相关案例。本体语义树的每一个节点都带有相应的领域信息。同时,源案例也用XML标记过,使源案例与目标案例具有相同的表达形式,在进行比较相似性,根据检索信息检索要求确定检索优先级,并定义相关的权重;由于该种方法主要服务于智能有限元分析系统,在进行案例检索时,以案例有限元分析信息作为优先检索信息,其次为模型建模特征信息,再次是材料属性信息。按照优先级的不同,根据每类信息对检索结果的影响程度,定义相应的检索权重,权重信息将在下文给出,根据本体语义树定义语义相似度,包括直接相似性和间接相似性;直接相似性,即是语义树中计算两个语义节点的相似度;定义1、语义节点在语义本体树中的层次称为语义深度,记为f,语义树的最大深度记为m,语义树中连结两语义节点的最短路径所经过的有向线段的数量叫语义距离,记为d,两节点c1,c2语义深度记为f(c1), f(c2);语义距离记为d(c1,c2);定义2、语义树中,根据语义距离越大相似性越小,深度差越小相似度越大,定义节点c1和c2的直接相似度为:
a>0 (1)
间接相似度,把要比较的节点的上位节点进行相似比较,而得到的相似度。
定义3 语义节点的上层节点称为父节点,间接相似度就是指语义节点的上层节点相似度,记做Sf, 具体算法可以根据公式(1)进行计算。定义节点c1和c2的间接相似度为:
a>0 (2)
定义4,由于语义相似度既要满足直接相似度,又要满足间接相似度,根据概率论的原则,两者条件都满足的概率等于两者概率的乘机,所以综合直接相似度和间接相似度可以得到语义相似度,用Sc,所以定义两个节点C1,C2,之间的相似度为:
Sc(c1,c2)=St(c1.c2)*Sf(c1,c2) (3)
根据直接相似性、间接相似性以及相应的权重得出全局相似性,定义5,全局相似度是在局部相似度的基础上根据不同的权重影响计算而得,给定有限元分析的两个案例X和Y,且案例X={Px, Qx, Fx}, Y={Py, Qy, Fy};其中P代表案例的分析信息,Q代表案例的模型特征信息,F案例的属性信息,Px代表案例X的m个分析信息,Px{Px1….Pxi…Pxm}, Py代表案例Y的n个分析信息,Py{Py1…Pyi…Pyn}, 同理模型特征信息与属性信息表达形式类似,则案例X,Y的全局相似度就是S(X,Y),即案例相似度,利用加权平均值,定义公式为:
(4)
XPi代表案例X的第i类分析信息,式中,wi为分析信息的权重;wj为建模特征信息权重;wk为属性信息权重;根据案例检索的优先级wi>wj>wk;,
表示案例X,Y的第i类分析信息的局部相似度;
表案例X,Y的第j类特征信息的局部相似度;
表示案例X,Y的第k类属性信息的局部相似度;根据全局相似性的大小找出匹配案例,并输出结果,根据直接相似度,间接相似度,局部相似度,间接相似度的综合计算,得出源案例与目标案例的相似度值,从而可以找到最匹配案例,并调取匹配案例的解,经过一定的修正赋予源案例。
- 还没有人留言评论。精彩留言会获得点赞!