一种多词表达抽取方法及其装置与流程
本发明涉及统计机器翻译和跨语言信息检索技术领域,尤其是一种多词表达抽取方法及其装置。
背景技术:
多词表达是具有语法、语义或语用特性,并有意义完整的多个词组合。多词表达的识别能够很好的提升分词、词性标注以及机器翻译等工作的效率和准确性。在机器翻译中,正确识别源语言中的多词表达有助于选择合适的翻译,避免多个词分别翻译而导致的目标语言不自然甚至不能达意。
多词表达的抽取方法基本分为基于统计的方法和基于规则的方法。基于规则的方法一般是具体研究某一种类型如动词短语结构等或局限于某一个特定领域,基于统计的方法则可以抽取形式独立的多词表达,也就是利用统计信息无差别的抽取各种结构和领域的多词表达。然而,现有的统计方法面临的问题有:一维互信息需要人工设定阈值,对不同数据存在适应性问题,局限于多词的二元结构,无法一次获取多词组合的多词表达,且需分步实现,多词表达库建设的准确度低。
技术实现要素:
本发明的首要目的在于提供一种一次性获取多词组合的多词表达,无需分步实现,有效提高多词表达抽取利用率,提高了多词表达库建设的准确度。
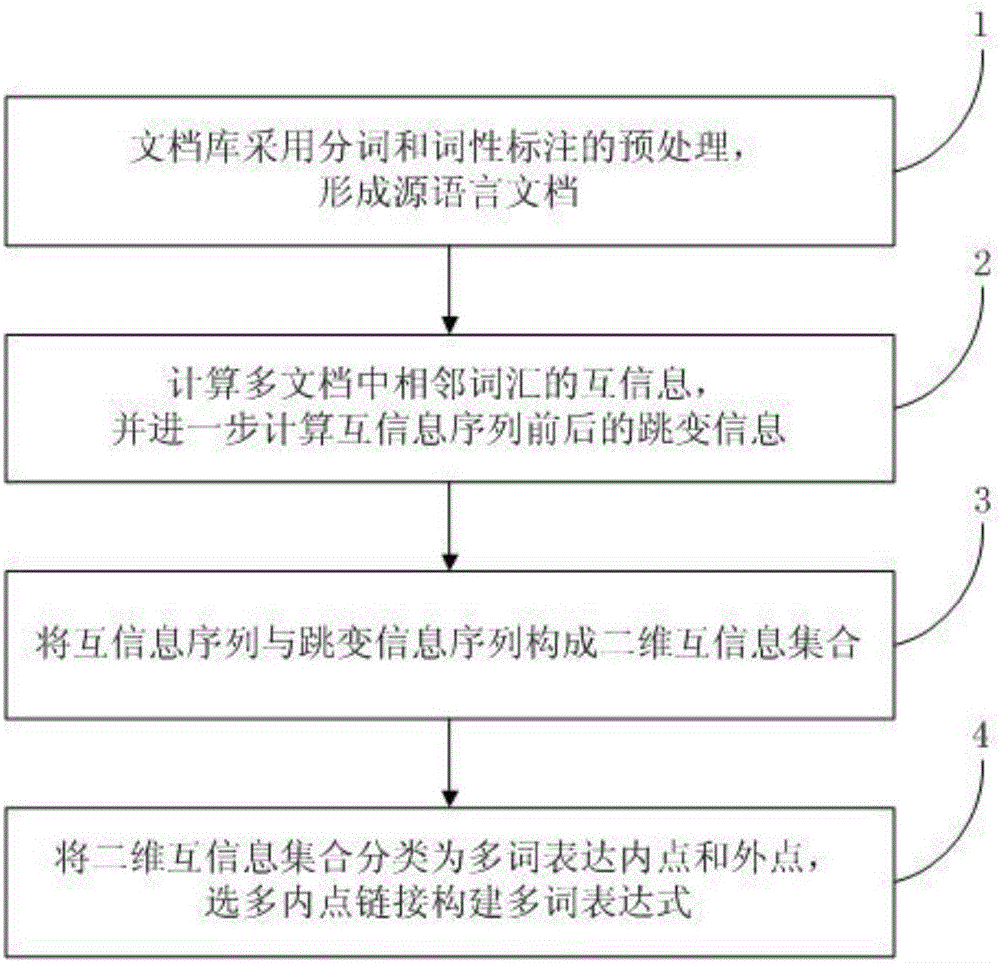
为实现上述目的,本发明采用了以下技术方案,一种多词表达抽取方法,该方法包括下列顺序的步骤:
(1)文档库采用分词和词性标注的预处理,形成源语言文档;
(2)计算多文档中相邻词汇的互信息,并进一步计算互信息序列前后的跳变信息;
(3)将互信息序列与跳变信息序列构成二维互信息集合;
(4)二维互信息集合采用分类器为多词表达内点和外点,选多内点链接构建多词表达。
进一步的,在所述步骤(1)中,针对收集文档库的所有文档进行中文分词、词性标注和命名实体识别、词性选择的预处理构成有特定次序的候选词汇集合。
进一步的,所述步骤(2)包括以下顺序的步骤:
(a)计算多文档中所有相邻词汇的互信息;
(b)计算互信息序列前后的跳变信息。
进一步的,所述步骤(3)中,根据互信息序列与跳变信息序列对应位置点,构建二维互信息(MIi,fi),多个二维互信息构成二维互信息集合。
进一步的,所述步骤(4)中,采用分类器将二维互信息集合中所有点,划分为多词表达内点和外点两类,将包含内点的相邻词汇链接构成多词表达。
进一步的,所述步骤(a)中,计算多文档中相邻词汇的互信息,构成互信息序列MI,其中相邻词汇x和y的互信息计算MIi(0≤i<len(MI)-α)如下式:
其中,x和y表示相邻词汇;MIi表示相邻词汇x和y构成的第i个互信息;len(MI)表示互信息序列MI的长度;α表示一个常量;M表示所有文档中词汇的总数;p(x,y)表示词汇x和y在所有文档中共现次数;p(x)表示词汇x在所有文档中出现次数;p(y)表示词汇y在所有文档中出现次数;N表示文档集中所有文档的个数;Nx,y表示包含x和y共现的文档个数。
进一步的,所述步骤(b)中,计算互信息序列前后的跳变信息,构成跳变信息序列f,其中的相邻互信息的跳变信息fi计算公式如下:
其中,fi表示互信息序列中当前互信息和后续互信息的跳变信息;||表示取绝对值。
进一步的,所述α为2。
本发明的另一目的在于提供一种多词表达抽取装置,包括:
候选词汇获取装置:针对收集文档库的所有文档进行中文分词、词性标注和命名实体识别、词性选择的预处理构成具有特定次序的候选词汇集合;
互信息和跳变信息获取装置:计算多文档中相邻候选词汇的互信息,并跟据相邻互信息计算互信息序列前后的跳变信息;
二维互信息获取装置:根据互信息序列与跳变信息序列位置对应的信息,选择互信息和跳变信息构成二维互信息;
分类筛选多词表达装置:采用分类器将二维互信息集合中所有点,分类为多词表达内点和外点两类,将有内点的相邻词汇链接构成多词表达。
由上述技术方案可知,本发明将相邻词汇间的互信息转变成二维互信息,聚类二维互信息筛选出多词表达,避免了一维互信息需要人工设定阈值,对不同数据的适应性问题,同时不局限于多词的二元结构,可一次获取多词组合的多词表达,且无需分步实现,有效提高多词表达的利用率,提高了多词表达库建设的准确度。
附图说明
图1是本发明方法的流程示意图;
图2是本发明装置的结构框图。
具体实施方式
一种多词表达抽取方法,该方法包括下列顺序的步骤:(1)文档库采用分词和词性标注等预处理,形成源语言文档;(2)计算多文档中相邻词汇的互信息,并进一步计算互信息序列前后的跳变信息;(3)将互信息序列与跳变信息序列构成二维互信息集合;(4)二维互信息集合采用分类器为多词表达内点和外点,筛选连续内点链接构建多词表达。如图1所示。
以下结合图1对本发明作进一步的说明。
在所述步骤(1)中,针对收集文档库的所有文本进行中文分词、词性标注和命名实体识别、词性选择的预处理构成有特定次序的候选词汇集合。
所述步骤(2)包括以下顺序的步骤:(a)计算多文档中所有相邻词汇的互信息;(b)计算互信息序列前后的跳变信息。
在所述步骤(a)中,计算多文档中相邻词汇的互信息,构成互信息序列MI,其中相邻词汇x和y的互信息计算MIi(0≤i<len(MI)-α)如下式:
其中,x和y表示相邻词汇;MIi表示相邻词汇x和y构成的第i个互信息;len(MI)表示互信息序列MI的长度;α表示一个常量;M表示所有文档中词汇的总数;p(x,y)表示词汇x和y在所有文档中共现次数;p(x)表示词汇x在所有文档中出现次数;p(y)表示词汇y在所有文档中出现次数;N表示文档集中所有文档的个数;Nx,y表示包含x和y共现的文档个数;常量α为2。
在所述步骤(b)中,计算互信息序列前后的跳变信息,构成跳变信息序列f,其中的相邻互信息的跳变信息fi计算公式如下:
其中,fi表示互信息序列中当前互信息和后续互信息的跳变信息;||表示取绝对值。
所述步骤(3)中,根据互信息序列与跳变信息序列对应位置点,构建二维互信息(MIi,fi),多个二维互信息构成二维互信息集合。
所述步骤(4)中,采用分类器将二维互信息集合中所有点,划分为多词表达内点和外点两类,将包含内点的相邻词汇链接构成多词表达。
如图2所示,本发明装置包括:候选词汇获取装置,针对收集文档库的所有文本进行中文分词、词性标注和命名实体识别、词性选择等预处理构成具有特定次序的候选词汇集合;互信息和跳变信息获取装置,计算多文档中相邻候选词汇的互信息,并跟据相邻互信息计算互信息序列前后的跳变信息;二维互信息获取装置,根据互信息序列与跳变信息序列位置对应的信息,选择互信息和跳变信息构成二维互信息;分类筛选多词表达装置,采用分类器将二维互信息集合中所有点,分类为多词表达内点和外点两类,将有内点的相邻词汇链接构成多词表达。
综上所述,本发明将相邻词汇间的互信息转变成二维互信息,聚类二维互信息筛选出多词表达,避免了一维互信息需要人工设定阈值,对不同数据的适应性问题,同时不局限于多词的二元结构,可一次获取多词组合的多词表达,且无需分步实现,有效提高多词表达的利用率,提高了多词表达库建设的准确度。
- 还没有人留言评论。精彩留言会获得点赞!