一种基于概率潜在语义分析的行人异常识别方法与流程
技术背景:
人体行为识别是近几年来计算机视觉领域的重大热点之一,其在运动捕获视频监控等多领域获得了初步的应用,并具重大的应用前景。由于人体运动的多变性和多样性,背景的嘈杂以及背景运动等多方面的因素严重影响人体运动的识别效果,实现人体行为识别是计算机视觉领域长期存在的问题。
在人体行为识别问题中,研究者常对图像强度值在局部范围内有显著变化的像素点感兴趣,这些“兴趣点”通常被称为时空兴趣点(Space-Time Interest Points,STIP)。Harris角点就是一种常用的兴趣点,2003年,Laptev等人最先将空间域的Harris角点检测推广到时空域,得到3D-Harris角点。该方法较好的克服了尺度、速度、视角等变化,但检测到的时空角点过于稀疏。2005年,Dollar等人提出了Cuboids检测算法,在空间2D高斯滤波器的基础上引入时间Gabor滤波器,将相应函数高于某一阈值的区域定义为时空兴趣点,使提取的兴趣点更为稠密。然而Dollar方法不具有尺度不变性,2008年,Willems等人提出了基于三维Hessian矩阵的兴趣点检测方法,在保证兴趣点稠密性的同时具有尺度不变性。在以上时空兴趣点的检测方法中,一旦背景中有其他微小运动目标,时空兴趣点同样会记录这些微小运动。
检测出兴趣点后,需要选择合适的局部特征描述子对兴趣点进行特征表示。Laptev等人采用基于HOG和HOF的特征描述子对3D-Harris角点表示,Dollar等人采用Cuboid描述子表示兴趣点。Klaser等人将HOG推广到时空维,得到3D-HOG描述子,其考虑了是将方向的梯度信息。同样的,Willems等人将SURF描述子推广到三维空间,得到ESURF描述子。以上描述例子中,有的只考虑梯度信息,有的只考虑光流信息,当联合考虑时有只在空间域与时间域内单独考虑。Wang等人比较了各种局部描述算子,并发现在大多数情况下整合了梯度和光流信息的描述算子其效果最好。
在分类器的选择方面,Laptev和Dollar等人都采用K均值聚类对描述子聚类,后采用SVM对行为分类。检测结果较优,但是该方法忽略了动作之间的关联性以及时空上下文特征。2005年Li FeiFei首次将Bag of word模型应用于场景图像的表示,并通过主题模型实现对多种场景的分类李,使得主题模型进行人体行为分类被广泛接受。其应用Cuboid检测子从视频序列中提取兴趣点,利用HOG描述子描述提取到的兴趣点,生成视觉单词,应用pLSA(Probabilistic Latent Semantic Analysis)学习和分类人体行为,该方法不仅可以识别多个单动作视频序列,而且可以识别一个长视频中的多个动作。但这些早期的研究还只是局限于受限场景下的人体动作识别,比如特定的视角、动作人、背景和光照,在自然场景下,取消上述种种限制的情况下,该方法的性能急剧下降甚至不再适用。
技术实现要素:
:
本发明针对现有基于视频的人体行为识别方法存在的不足,提出一种基于概率潜在语义分析的行人异常识别方法,以提高特征的表征能力和行为识别率。
为实现上述目的,该发明具体包括以下步骤:
步骤A、取一个视频样本,采用混合高斯背景建模算法提取前景目标,对该视频每一帧生成仅含人体目标的二值掩码图片,通过掩码图片生成仅含人体目标的视频;
读取视频前n帧,建立背景模型,对新读取的每一帧,分割出包含人体的二值图片。将该二值图像与原图像做掩膜操作,生成仅含人体目标的灰度图像,通过一系列灰度图像生成仅含前景人体的视频。
步骤B、采用基于三维Hessian矩阵检测生成视频的时空兴趣点;
该步骤的具体实现方法是:
三维Hessian矩阵定义为
其中,σ、τ分别为空间和时间尺度,ξ、η分别表示x、y或t,g(.;σ2,τ2)为高斯平滑函数,
在该尺度下,对每一个像素计算Hessian矩阵行列式,得到兴趣点响应函数S=|det(H)|,
在时间、空间和尺度(x,y,t,σ,τ)上采用非最大值抑制选择局部最大值作为兴趣点的位置。
在计算中,对极值点尺度归一化,并采用积分视频和盒滤波器加速计算。
步骤C、采用HOG3D/HOF描述子计算步骤B中检测到的时空兴趣点,获得相应的特征向量;
将兴趣点周围的视频块划分为不同子块,每一子块又划分为不同的元胞。每个元胞的直方图qj由元胞的平均梯度经正多面体量化得到,每个子块分别用直方图hi表示,则子块直方图hi由元胞直方图qj累加得到,再将所有子块直方图hi连接得到视频块直方图ds,进行二范数归一化最终生成HOG3D特征向量。
以人体活动时空兴趣点p为中心,将局部时空小块按x,y,t方向均分成nx×ny×nt个小格,将0度至360度的光流方向划分5个方向;采用LK光流法计算每个像素位置的光流,之后在这5个方向做量化和直方图统计,得到每个小格的统计结果为一个五维向量,将每个小格按x,y,t的顺序顺次连接可得到一个5×nx×ny×nt维的光流直方图HOF特征。
将HOG3D与HOF特征级联生成该时空兴趣点的HOG3D/HOF特征向量。
步骤D、采用K-means对训练数据集中提取出的特征集合进行聚类,建立所有时空单词组成的集合W={w1,ww,…,wm}。对于不同的动作视频,视频中的每个兴趣点被划分为不同类别的单词,这样,一段视频可以看成是由这些单词(兴趣点特征)构成的一篇文档,而动作可以类比成主题。
步骤E、采用概率潜在语义分析模型训练视频集,进行行人异常识别;
概率潜在语义分析模型用D={d1,d2,…,dn}表示文档,W={w1,w2,…,wm}表示单词,Z={z1,z2,…,zk}表示潜在的主题集合,N={nij|nij=n(di,wj),i≤N,j≤M}表示文档和单词的共生矩阵,其中n(di,wj)表示单词wj在文档di中出现的频率,W×D的联合概率可表示为p(di,wj)=p(di)p(wj|di),其中,p(di)表示文档di出现的概率,p(wj|di)表示单词在文档上的分布概率,p(zk|di)表示隐含主题在文档上的分布概率。PLSA模型待求参数为p(wj|di)和p(zk|di)。通过极大似然估计进行求解:
利用EM算法求解该模型,可得p(zk)、p(zk|di)和p(wj|zk)。
对于待识别视频,同样采用EM算法,保持p(wj|zk),对p(zk|di)和p(zk)进行迭代,可得
即为测试视频中的主题分布,最终动作类别取决于arg max kp(zk|dtest)。
本发明的有益效果:
1.本发明在提取时空兴趣点之前采用混合高斯背景建模的方法提取前景目标,生成了只具有前景目标的动作视频,剔除了与人体运动无关、位于运动背景上的时空兴趣点,克服了现有技术中行为特征的提取受背景环境影响的问题,使本发明对复杂背景具有更强的适应性。
2.本发明采用HOG3D/HOF特征描述子,克服了现有技术中提取行为特征不够全面的问题。传统的行为特征只包含三维梯度信息或只包含二维梯度与光流信息,本发明能更有效地表征运动特征,提升行为识别的准确率。
3.本发明采用词袋模型与概率潜在语义分析的方法对行为进行分类。该方法可离线训练,训练完成后就可以完成识别,该模型比传统分类方法更加准确,很大程度提高的识别的正确率。
附图说明:
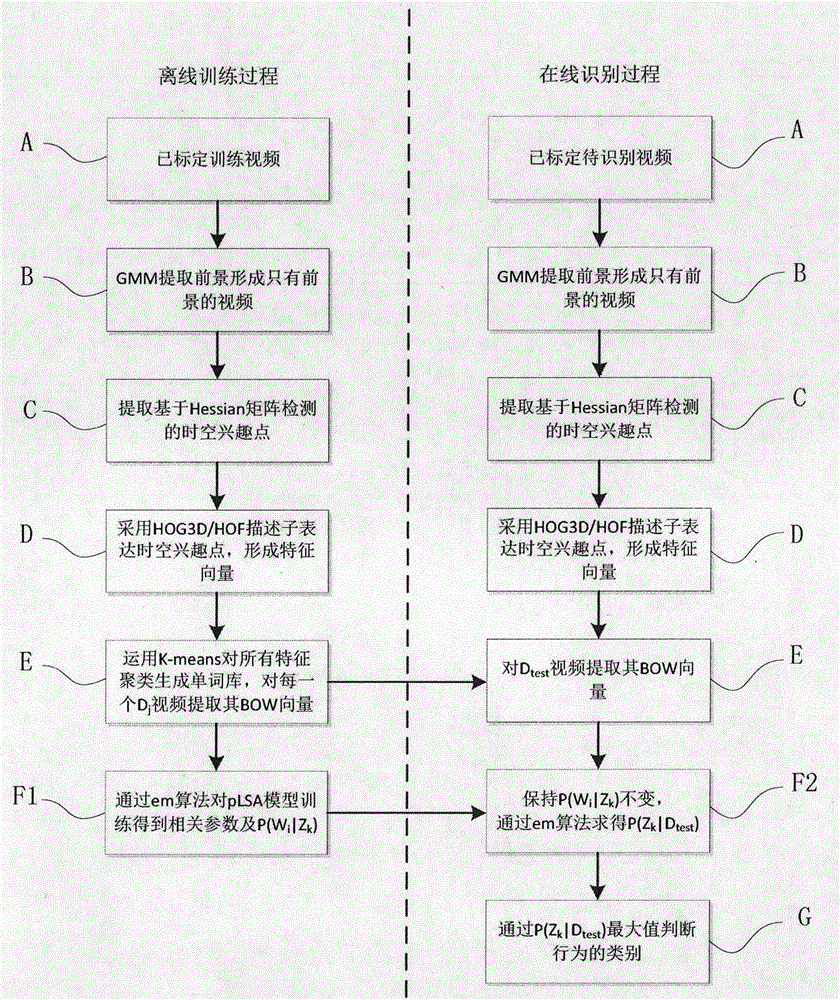
图1为本发明流程图。
具体实施方式:
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图与实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了提高动作识别的准确率,本发明实例提供了一种基于概率潜在语义分析的行人异常识别方法,详见下文描述:
步骤A,建立数据库。
本方法所用测试数据库为CASIA(中国科学院自动化研究所)行为分析数据库,由由室外环境下分布在三个不同视角的摄像机拍摄而成,为行为分析提供实验数据。数据分为单人行为和多人交互行为,单人行为包括走、跑、弯腰走、跳、下蹲、晕倒、徘徊和砸车,每类行为有24人参与拍摄,每人4次左右。多人交互行为有抢劫、打斗、尾随、赶上、碰头、会合和超越,每两人1次或2次。数据库中共用1446条视频数据,所有视频都是由分布在水平视角、斜视角和俯视角的三个未标定的静止的摄像机同时拍摄的,帧率为25fps,采用huffyuv编码压缩,分辨率为320*240,以avi文件形式存在,每段视频持续时间因行为类别而异,5秒到30秒不等。本方法将数据库按照5∶1分成两个数据集:训练样本集X和测试样本集T,其中训练集包括1205段,测试样本集包括241段。
步骤B,对训练样本集X中视频,采用混合高斯背景建模算法提取前景目标,对该视频每一帧生成仅含人体目标的二值掩码图片,通过掩码图片生成只有人体目标的视频;
B1、读取视频前n帧,用混合高斯模型建立背景模型,对每一帧不断更新背景模型;
B2、每读取新的一帧,通过步骤B1所得背景分割出仅含人体的二值图像;
B3、将二值图像与原图像做掩膜操作,生成只包含人体目标的灰度图像;
B4、将这一系列的灰度图像合并成只有前景人体的视频;
步骤C,对训练样本集X中视频,采用基于三维Hessian矩阵检测生成视频的时空兴趣点;;
C1、三维Hessian矩阵定义为
其中,σ、τ分别为空间和时间尺度,ξ、η分别表示x、y或t,g(.;σ2,τ2)为高斯平滑函数,在该尺度下,对每一个像素计算Hessian矩阵行列式,得到兴趣点响应函数S=|det(H)|,在时间、空间和尺度(x,y,t,σ,τ)上采用非最大值抑制选择局部最大值作为兴趣点的位置。
C2、时空兴趣点局部极值所在尺度和真实尺度(σ0,τ0)之间的关系为:也就是说在5维空间(x,y,t,σ,τ)中,将极值点处的尺度乘以得到兴趣点尺度。计算过程采用积分视频和盒滤波器进行加速。
步骤D、采用HOG3D/HOF描述子计算检测到的时空兴趣点,获得相应的特征向量;
D1、将兴趣点周围的视频块划分为不同子块,每一子块又划分为不同的元胞。每个元胞的直方图qj由元胞的平均梯度经正多面体量化得到,每个子块分别用直方图hi表示,则子块直方图hi由元胞直方图qj累加得到,再将所有子块直方图hi连接得到视频块直方图ds,进行二范数归一化最终生成HOG3D特征向量。
D2、平均梯度的计算过程:元胞的平均梯度由积分视频计算得到,给定一个视频v(x,y,t),它沿不同的方向的偏导分别为对的积分视频定义为对于一个边长分别为w,h,l视频块j=(x,y,t,w,h,l)T,,平均梯度则为其中定义为
对以此类推。
D3、平均梯度的量化过程:通常使用正多面体进行量化,本专利中使用正二十面体。设P为所有n个面的中心p1,…,pn组成的矩阵P=(p1,…,pn)T,其中pi=(xi,yi,ti)T,的在P下的映射为元胞中的直方图由各方向的幅值决定,可得元胞梯度直方图通过元胞梯度直方图的累加与子块直方图级联生成HOG3D特征。
D4、所述计算彩色图像序列中光流直方图HOF特征的方法为:以人体活动时空兴趣点p为中心,将局部时空小块按x,y,t方向均分成nx×ny×nt个小格,将0度至360度的光流方向划分成0度至90度、90度至180度、180度至270度和270度至360度这四个主方向,外加一个光流量为零的方向;采用LK光流法计算每个像素位置的光流向量之后在这五个方向做量化和直方图统计,得到每个小格的统计结果为一个五维向量,将每个小格按x,y,t的顺序顺次连接可得到一个5×nx×ny×nt维的光流直方图HOF特征。
D5、将HOF与HOG3D特征级联形成该时空兴趣点的特征向量。以nx=ny=3,nt=2为例,即局部时空小块按x,y,t方向均分成3×3×2个小格,HOG3D特征的维数为3×3×2×9=162维,HOF特征的维数为3×3×2×5=90,即HOG3D/HOF特征为252维。
步骤E、采用K-mean聚类算法对视频的特征向量集合建立视频图像的词袋模型;
引入文本分类中“词袋”的思想,即在得到时空兴趣点特征向量的基础上,采用K-means对训练数据集中提取出的特征集合进行聚类,生成码本。所有时空单词组成的集合W={w1,w2,…,wm}称为时空词典,其中m为聚类中心的个数。对于不同的动作视频,视频中的每个兴趣点通过聚类被划分为不同类别的单词,这样,一段视频可以看成是由这些单词(兴趣点特征)构成的一篇文档,而动作可以类比成主题。
步骤F、采用概率潜在语义分析模型训练视频集,进行人体行为识别;
F1、概率潜在语义分析模型用D={d1,d2,…,dn}表示文档,W={w1,w2,…,wm}表示单词,Z={z1,z2,…,zk}表示潜在的主题集合,N={nij|nij=n(di,wj),i≤N,j≤M}表示文档和单词的共生矩阵,其中n(di,wj)表示单词wj在文档di中出现的频率,W×D的联合概率可表示为p(di,wj)=p(di)p(wj|di),其中,p(di)表示文档di出现的概率,p(wj|di)表示单词在文档上的分布概率,p(zk|di)表示隐含主题在文档上的分布概率。PLSA模型待求参数为p(wj|di)和p(zk|di)。通过极大似然估计进行求解:
利用EM算法求解该模型,可得p(zk)、p(zk|di)和p(wj|zk)。
F2、运用上述模型,判断测试集T人体运动行为。
按照上述步骤B到步骤D处理测试集T,同样采用EM算法,保持p(wj|zk),最对p(zk|di)和p(zk)进行迭代,可得
即测试视频中主题分布。最终动作类别取决于arg max kp(zk|dtest)。
步骤G、实验评价
G1、本发明采用留一法进行交叉验证从而评价分类结果。所谓留一法就是从N个样本中选取出N-1个样本作为训练样本训练分类器,留一个样本作为测试样本检验分类器的性能。这样重复N次,检验N次,统计错误分类的样本总数K,用K/N作为错误率的估计值,则正确率的估计值为1-K/N。其优点是有效地利用了N个样本,比较适用于样本数N较小的情况。选取交叉验证实验中分类准确率最高的样本作为最优测试样本X′;
G2、将X′用于步骤F1中用于概率潜在语义分析模型中训练参数;
G3、将剩余的视频集作为测试集T′,得到各类运动的预测结果。
- 还没有人留言评论。精彩留言会获得点赞!