一种基于卷积神经网络的汉字识别方法与流程
本发明涉及图像处理技术领域,尤其涉及一种基于卷积神经网络的汉字识别方法。
背景技术:
利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。人们在生产和生活中,要处理大量的文字、报表和文本。为了减轻人们的劳动,提高处理效率,50年代开始探讨一般文字识别方法,并研制出光学字符识别器。60年代出现了采用磁性墨水和特殊字体的实用机器。60年代后期,出现了多种字体和手写体文字识别机,其识别精度和机器性能都基本上能满足要求。如用于信函分拣的手写体数字识别机和印刷体英文数字识别机。70年代主要研究文字识别的基本理论和研制高性能的文字识别机,并着重于汉字识别的研究。
文字识别可应用于许多领域,如阅读、翻译、文献资料的检索、信件和包裹的分拣、稿件的编辑和校对、大量统计报表和卡片的汇总与分析、银行支票的处理、商品发票的统计汇总、商品编码的识别、商品仓库的管理,以及水、电、煤气、房租、人身保险等费用的征收业务中的大量信用卡片的自动处理和办公室打字员工作的局部自动化等。以及文档检索,各类证件识别,方便用户快速录入信息,提高各行各业的工作效率。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种基于卷积神经网络的汉字识别方法。
本发明解决其技术问题所采用的技术方案是:一种基于卷积神经网络的汉字识别方法,包括以下步骤:
1)采集训练用的文本图像;
2)图像预处理:首先对图像进行非均匀光照调整,然后将图像转换为灰度图像
3)对预处理的图像进行特征提取:
采用Gabor滤波器提取图像八个方向的Gabor特征,八个方向分别是0°,22.5°,45°,67.5°,90°,112.5°,135°,157.5°;
其中Gabor滤波器的公式如下所示:
其中,σ=π,M为方向数目,ι表示波长,表示方向;
4)通过训练获得最终识别模型:将经过预处理的图像和经过Gabor特征提取的图像一起作为输入,输入卷积神经网络,所述卷积神经网络结构包括两层卷积层,一层多卷积层的神经网络,并在神经网络的输入层和隐藏层,均使用Dropout技术;
选取测试识别正确率最高的卷积神经网络模型,作为最终识别模型;
5)文字识别:对待识别的文本图像进行如步骤2)的图像预处理,采用训练所得的卷积神经网络模型进行识别,输出类别,匹配标签中汉字类别,输出汉字识别结果。
按上述方案,所述步骤2)中利用公式对图像进行非均匀光照调整;公式中,I'是进行调整后该点的像素值,C是图像中心位置的像素值,BG是进行中值滤波后的图像中该点的像素值,I是原始图像在该点的像素值。
按上述方案,所述步骤4)中,在神经网络的输入层和隐藏层,均使用Dropout技术。
本发明产生的有益效果是:
(1)本发明中,在图像预处理过程中,调整图像背景,减少因为光照不均匀,造成的识别错误的情况。
(2)本发明中,将提取方向特征图作为先验知识,和原始图像一起作为输入层的数据输入,以增强神经网络的识别性能,提高了汉字的识别率;且最终模型较小,计算速度快。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
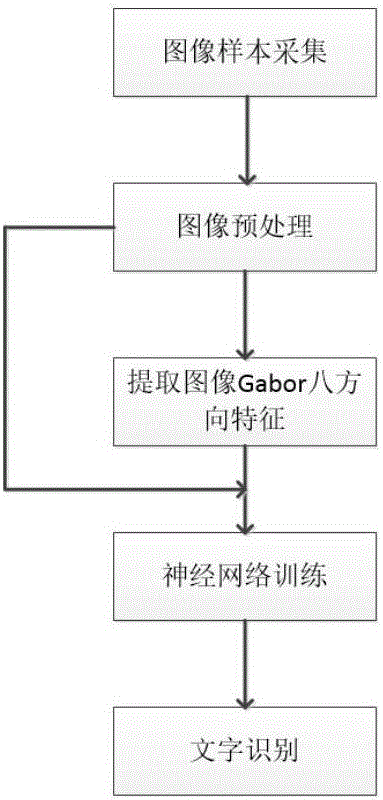
图1是本发明实施例的方法流程图;
图2是本发明实施例的神经网络的具体结构图;
图3是本发明实施例的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,一种基于卷积神经网络的汉字识别的方法,包括以下步骤:
1)采集训练用的的文本图像;
2)图像预处理:利用公式对图像进行非均匀光照调整、将图像转换为灰度图像;公式中,I'是进行调整后该点的像素值,C是图像中心位置的像素值,BG是进行中值滤波后的图像中该点的像素值,I是原始图像在该点的像素值。
3)对预处理的图像进行特征提取:
采用Gabor滤波器提取图像八个方向的Gabor特征,充分显示了Gabor滤波器的多分辨性。八个方向分别是0°,22.5°,45°,67.5°,90°,112.5°,135°,157.5°;波长为
其中Gabor滤波器的公式如下所示:
其中,σ=π,M为方向数目,ι表示波长,表示方向;
4)将经过预处理的图像和经过Gabor特征提取的图像一起作为输入,输入卷积神经网络,所述卷积神经网络结构包括两层卷积层,一层多卷积层的神经网络,并在输入层和隐藏层,均使用Dropout技术。如图2,本实施例中神经网络的具体结构如下:
48*48-20C5-MP2-50C5-MP2-96C3-128C3-MP2-3500
48为输入图像尺寸;例:20C5中20表示该层特征图数量,C表示为该层为卷积层,5表示该层卷积核大小;MP2中,MP表示该层为池化层,2表示该层卷积核大小;3500表示该层为3500类的分类层。
参数调整方法:
根据输入图像的数量及电脑配置,调整每批次处理图片的数量,调整迭代次数。
训练结束判断:
当误差值loss收敛且测试识别正确率出现小范围波动时,即可停止训练,选取测试识别正确率最高的模型,作为最终识别模型。
5)文字识别:对待识别的文本图像进行如步骤2)的图像预处理,采用训练所得的卷积神经网络模型进行识别,输出类别,匹配标签中汉字类别,输出汉字识别结果。
为了验证本发明,进行了实验案例的检测。本文将Gabor特征提取与原始图像结合,同时进行卷积神经网络训练。将原始图像直接放入卷积神经网络进行训练作为对比实验1。将梯度特征和原始图像结合,同时进行卷积神经网络训练,作为对比试验2。
表1不同特征提取与神经网络的识别结果
由表1可知,Gabor特征有效的反应了汉字的特征信息,弥补了部分CNN自学习中所丢失的特征,提升了识别率。
Dropout技术是在模型训练时随机让网络某些隐含层节点输出值为零,这种如同在图像中加入噪声的方式能防止模型在训练过程中出现过拟合,提高神经网络的泛化能力。对于每次输进来的样本,由于其Dropout的随机性,每个样本对应的网络结构都不相同,这些不同的网络结构同时又共享隐含节点的权值,使得不同的样本对应不同的模型。本文对输入层和所有的隐藏层都采用了Dropout技术。如图3所示,深色的神经元表示被随机选为Dropout的节点单位。
为了研究在不同网络层上进行Dropout的效果,本发明设置如下实验:
以0.4作为Dropout率,分别在输入层,隐藏层,以及输入层和隐藏层进行Dropout,实验结果如表2所示
表2为在不同层使用dropout的结果
当同时对输入层和所有的隐藏层使用Dropout技术时,效果比仅仅在输入层或仅仅在隐藏层使用Dropout要好,相比于没有使用Dropout的网络,准确率大约高出3%。为了最大限度地优化网络的泛化性能,本发明对输入层和所有的隐藏层使用Dropout技术。
综上所述,本发明将Gabor特征提取与原始图像放入输入层和隐藏层均使用Dropout技术的神经网络中训练,得到了98.2%的识别率。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!