一种基于词向量语义分析的海量短文本聚类方法与流程
本发明涉及语义分析领域,更具体地,涉及一种基于词向量语义分析的海量短文本聚类方法。
背景技术:
传统的文档空间向量模型(VSM)中,文档被表示成由特征词出现概率组成的多维向量,但还存在不少问题。0-1向量空间模型:将每个词的出现与否作为其值,过于简单暴力,忽略了单词出现的频率、顺序等问题,同时中文的切词难以规范也是很大问题。词袋模型考虑了单词出现的次数,词频逆文档tfidf模型,同时兼顾了单词在所有文档中出现的频率而计算单词的“重要度”,但对同义词都完全无法处理。如“奥巴马来了北京发表讲话”与“美国总统到了中国首都演讲”,传统的词向量空间模型将会看成完全不相同的两句话。传统的向量空间模型与概率模型构建的“文档——单词”矩阵,由于单词表巨大,一般都接近10万级别,而短文本会真正会出现的单词极少,因此,会出现向量化后的文本矩阵中出现大量未0的稀疏性问题,和维度太大计算量大的“维度爆炸”的问题。
PLSA等概率模型,在词与文本引入了“主题”(topic)中间概念,考虑了单词在所有文本中的分布,一定程度上解决了近义词的问题,但实现困难,计算复杂度大,对与几十到上百字的短文本效果也很差。因此,对于日益增长的海量的短文本数据不太实用。
在聚类算法方面,传统的K-Means算法简单方便,效果良好,但存在初始值需要聚类的簇数目K难以确定和计算时需要两两比较,复杂度大两个缺点。
技术实现要素:
本发明提供一种基于词向量语义分析的海量短文本聚类方法,该方法聚类效果好,聚类速度快。
为了达到上述技术效果,本发明的技术方案如下:
一种基于词向量语义分析的海量短文本聚类方法,包括以下步骤:
S1:收集海量文本数据,并对每一文本数据进行预处理;
S2:对预处理后的文本进行word2vec模型训练得到词向量模型;
S3:将待处理的文本利用得到的词向量模型处理得到该待处理的文本的向量;
S4:对待处理的文本的向量利用K-Means聚类算法或Dbscan聚类算法进行聚类处理得到聚类结果。
进一步地,所述步骤S1的具体过程是:
对收集的文本数据采用基于知识库的方法对部分词语进行消歧,包括常规的高频词、停用词、标点符号、表情符号、简繁体转换的去除处理。
进一步地,所述步骤S3的具体过程如下:
将待处理的文本利用得到的词向量模型处理得到若干个单词的词向量,对每一个单词的词向量进行tfidf值计算,以计算出的tfidf值作为word2vec处理的权重,对每一个单词的词向量进行word2vec处理并加权求和得到待处理文本的256维度的向量:
其中,doc表示文本向量,Token表示文本的每个单词的词向量,n为文本中单词个数,m为文本词向量的具体维度为256,Wk,j为第i个单词在文档j中的tfidf值。
进一步地,所述步骤S4的具体过程如下:
1)从n个单词中数随机动态选取k个词向量作为初始聚类中心;
2)分别计算未选中的词向量与这k个聚类中心的距离,根据最小距离对这些词向量进行划分得到新的聚类;
3)计算第2)中得到的聚类的每一个词向量的均值作为聚类中心;
4)迭代计算标准测度函数,如当迭代次数达到一定阈值,或者标准测度函数收敛K值不再变化时,算法终止,否则跳转至步骤2)。
进一步地,所述将待处理的文本利用得到的词向量模型处理得到若干个单词的词向量的过程是:对预处理后的文本作为word2vec模型的输入,词向量维度设为256,上下窗口为5,利用连续空间词向量技术CBOW方法进行训练得到文本的单词的词向量。
与现有技术相比,本发明技术方案的有益效果是:
本发明针对海量短文本提供一种基于词向量语义分析的聚类方法。首先利用使用海量文本数据进行word2vec的训练,将文本单词映射到256维的向量空间,然后对需要聚类的文本进行单词tfidf值的计算作为权重,将预处理后的文本进行加权求和,将短文本的向量化,相对于传统的tfidf模型,加入了word2vec训练好的词向量语义信息。得到更高质量的“文本向量”,从而提高聚类效果,采用大数据实时流处理框架Spark进行K-means或Dbscan算法进行聚类,加速得到聚类结果。
附图说明
图1为本发明方法流程图;
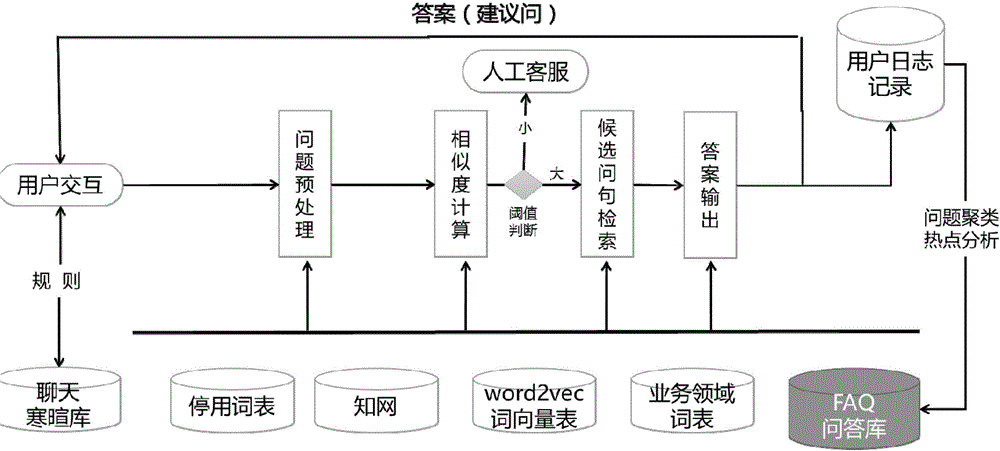
图2为本发明方法在实施例1中的问答系统中的应用流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种基于词向量语义分析的海量短文本聚类方法,包括以下步骤:
S1:收集海量文本数据,并对每一文本数据进行预处理;
S2:对预处理后的文本进行word2vec模型训练得到词向量模型;
S3:将待处理的文本利用得到的词向量模型处理得到该待处理的文本的向量;
S4:对待处理的文本的向量利用K-Means聚类算法或Dbscan聚类算法进行聚类处理得到聚类结果。
步骤S1的具体过程是:
对收集的文本数据采用基于知识库的方法对部分词语进行消歧,包括常规的高频词、停用词、标点符号、表情符号、简繁体转换的去除处理。
步骤S3的具体过程如下:
将待处理的文本利用得到的词向量模型处理得到若干个单词的词向量,对每一个单词的词向量进行tfidf值计算,以计算出的tfidf值作为word2vec处理的权重,对每一个单词的词向量进行word2vec处理并加权求和得到待处理文本的256维度的向量:
其中,doc表示文本向量,Token表示文本的每个单词的词向量,n为文本中单词个数,m为文本词向量的具体维度为256,Wk,j为第i个单词在文档j中的tfidf值。
步骤S4的具体过程如下:
1)从n个单词中数随机动态选取k个词向量作为初始聚类中心;
2)分别计算未选中的词向量与这k个聚类中心的距离,根据最小距离对这些词向量进行划分得到新的聚类;
3)计算第2)中得到的聚类的每一个词向量的均值作为聚类中心;
4)迭代计算标准测度函数,如当迭代次数达到一定阈值,或者标准测度函数收敛K值不再变化时,算法终止,否则跳转至步骤2)。
将待处理的文本利用得到的词向量模型处理得到若干个单词的词向量的过程是:对预处理后的文本作为word2vec模型的输入,词向量维度设为256,上下窗口为5,利用连续空间词向量技术CBOW方法进行训练得到文本的单词的词向量。
本实施例中以某银行的用户客户问答日志记录作为例子,来说明本发明的方法的过程:
(1)收集数据集
通过将用户输入问题进行聚类分析,从而协助构建智能客服FAQ常用问答库。实际应用中可使用任何文本。
(2)文本预处理
相对于传统的词袋模型,尤其针对用户查询语句的短文本,高维性和稀疏性缺点突出,而且不能刻画词与词直接的相似性,可采用基于知识库的方法对部分词语进行消歧,如中文的《知网》,英文的WordNet等。然后,进行常规的高频词、停用词、标点符号、表情符号、简繁体转换的去除处理。
(3)训练词向量
为了让机器“读懂”文字,本发明采用了向量空间模型,将每个文档表示为256维的实数向量序列。向量的特征项为文档中的词语,词向量的值由word2vec训练而来。Word2vec是Google公司开源的一个用于将词语进行向量化表示的工具,通过大语料训练得到的词向量有一定的表示词汇语法和语义关系的能力。本发明采用谷歌Mikolov等人提出的连续空间词向量技术(Continous Bag of Words,简称CBOW),通过单词的上下文预测该词的词向量,滑动窗口设为5。
(4)文本向量化
将单词映射成一个向量后,使用TF-IDF(Term Frequency-Inverse Document Frequence,词频-逆文档频率)算法来计算每个词在该文本的tfidf值作为权重,将每个短文本LTP切词后的文本加权求和映射为256维的向量:
其中,doc表示文本向量,Token表示文本的每个单词的词向量,n为文本中单词个数,m为文本词向量的具体维度为256,Wk,j为第i个单词在文档j中的tfidf值。
(5)选择聚类算法进行聚类
K-Means算法实现简单,效果良好,但最大的问题在于类目数K的确定。可根据实际应用情况选定K值,或按照基于密度的聚类动态得到聚类簇数。本发明中,针对日志流的海量数据,使用Spark的机器学习库MLlib进行计算进行加速。K值的确定,一个是人工定义,在具体问题日志聚类中定义了公式(2)根据文本数的规则进行动态调整。很多具体的规则确定需要按实际,可用不同K值多次迭代,研究在不同聚类情况下的数据特点,再最终确定。问答系统中,针对噪音异常点较的情况,也采用了Dbscan基于密度的算法进行聚类。
本发明的关键步骤在于第三步和第四步,下面分别简述一下第三步词向量训练的具体步骤。
第(3)步词向量训练步骤:
(3.1)采用的是gensim的开源优化word2vec的python版本接口,利用互联网维基百科和财经新闻结合用户日志记录数据进行词向量的训练。每个单词256维,大大降低了计算的复杂性,同时有效解决了如“麦克风”与“话题”,“百度”与”腾讯”之间的语义的近似性。将原始语料(维基百科、财经新闻、业务客服问答日志约25G)进行清洗规范化后(10G),利用中科院的LTP分词工具进行分词。引入业务专有词典和《知网》同义词词典后进行替换翻译,减少数据稀疏性。
(3.2)将处理后的语料作为word2vec模型的输入,词向量维度设为256,上下窗口为5,选取CBOW方法进行训练。
(3.3)得到词模型太大(近5个G,26万个词),为提高效率,按照频率递减,剔除高频常用词和低频词,得到有效的15万个单词的向量。
(3.4)将需要聚类的文本同样预处理和切词后,计算出每个单词的tfidf值,作为后续word2vec的权重,将文本加权求和,得到每个文本固定256维度的向量。
第四步K-Means聚类算法步骤:
(4.1)通过第三步将文本向量化后,使用公式2,从n个短文本中数随机动态选取k个文本向量作为初始聚类中心。
(4.2)根据每个聚类对象的均值,分别计算其它每个文本向量与这K个聚类中心的距离,根据最小距离对这些文本进行划分。
(4.3)重新计算每个聚类的均值作为聚类中心。
(4.4)计算标准测度函数,如当迭代次数达到一定阈值,或者函数收敛K值不再变化时,算法终止,否则重新步骤(4.2)。
算法的时间复杂度上界为O(n*k*t),其中n为文本数,k为聚类簇数,t为迭代次数。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!