基于图的最大紧密度划分的复合短语无监督识别方法与流程
本发明属于信息技术领域,具体涉及一种基于图的最大紧密度划分的复合短语无监督识别方法。
背景技术:
随着多科学研究的逐步深入,现今学术界和研究者发表大量的研究成果呈海量爆炸性增长。如何自动化收集、整合、分析这些工作成为了学术界和工业界关注的问题。论文、书籍、技术报告、专利的题目、科技项目名称等这一类短语在这里统称为复合短语。如何高效的从各类网络语料中抽取需要的科技复合名词实体,是自动化进行学术信息抽取、知识产权保护、科技资源数据库在线建设与维护等诸多应用的基础。
传统意义上的命名实体是自然语言处理的基本任务抽取的对象,主要包括人名、地名、组织机构名、数字、计量单位等专有名词。这些命名实体具有长度相对稳定、结构规范、命名规则统一的有利特点,这使得传统的命名实体识别系统的F1-measure往往能达到90%以上,几乎接近人类正常识别水平。而科技类名词短语不同于人名和地名。科技类名词往往内部结构复杂,内部包含嵌套的科技名词实体。而且科技类名词短语纷繁复杂,词·语的出现与否本身具有极大的稀疏性,内部实体之间相互组合的冗余度低。这类词法结构导致识别该类命名实体的难度较大。这使得通过词语本身隐式马尔科夫输入的方法不可行。由于复合短语相对于普通的命名实体(人名、地名、机构名)词语本身词法组成更加复杂,传统的纯手工角色标注容易导致标注错误,而且传统方法依赖于手工标注数据,费时费力。
技术实现要素:
本发明的目的在于提供无监督的复合短语自动识别方法,为解决科技类短语手工标注数据费时费力的困难以及数据稀疏,冗余度低的特点以及传统的有监督方法效果较差,本文提出了一种无监督的基于图的最大紧密度划分的复合短语的高效识别方法。
本发明采用的技术方案如下:
一种基于图的最大紧密度划分的复合短语无监督识别方法,包括以下步骤:
1)采用词性标注工具对输入语料进行词性标注和分词;
2)将分词后的输入序列映射到有序的图结构中,将语义紧密度高的词语划分到一个分段内,并使得整个图的紧密度之和最大;
3)通过验证各分段是否包含特征词,实现候选复合短语的最终识别。
进一步地,步骤2)通过动态规划方法求解不同分段组合之间的紧密度,从而将整个输入文本的紧密度之和最大化。
进一步地,步骤2)中分词之间的紧密度包含:特殊符号紧密度、维基百科紧密度、以及词性紧密度。
进一步地,步骤3)通过求解最小集合覆盖问题来产生特征词集合。
本发明的关键点包括两个方面:
1)针对设置对科技类复合名词短语自身的特点,通过将输入序列映射到有序的图模型,通过寻找最大化紧密度的切分,从而将候选科技复合短语切分出来。
2)根据复合短语特征词中富含特征词这一重要特性,采用了前一阶段的分段是否包含特征词来实现候选科技复合短语的最终识别。本发明采用了最小集合覆盖的思想,来产生特征词集合。
本发明的有益效果如下:
本发明提供了一种无监督的基于图的最大紧密度划分的复合短语自动识别方法,能够自动识别科技类复合短语,省时省力,相比于传统的有监督方法,不需要大量标注语料,便于在线部署应用,是一种高效的科技类复合短语识别方法。
附图说明
图1是命名实体识别处理流程图。
图2是单词图分割例子示意图。
图3是二元运算计算示意图。
图4是681-NSPTA数据集上参数u对算法性能影响曲线图,其横坐标为参数u的值,纵坐标为算法性能值,其中Recall Rate表示查全率,Precision表示查准率,F1measure表示F1测度。
图5是NSPTA数据集上参数u对算法性能影响曲线图,其横坐标为参数u的值,纵坐标为算法性能值。
图6是681-NSPTA数据集上参数v对算法性能影响曲线图,其横坐标为参数v的值,纵坐标为算法性能值。
图7是NSPTA数据集上参数v对算法性能影响曲线图,其横坐标为参数v的值,纵坐标为算法性能值。
图8是681-NSPTA上滑动窗口大小对算法性能影响曲线图,其横坐标为滑动窗口大小,纵坐标为算法性能值。
图9是NSPTA上滑动窗口大小对算法性能影响曲线图,其横坐标为滑动窗口大小,纵坐标为算法性能值。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步说明。
1.科技复合短语特征
基于对复合短语的观察,发现有以下几个特性:
(1)多成分组成:复合短语往往由多个词语组成成分,例如:“两系法杂交水稻研究与应用”中,对其进行分词后,包含“两系法”、“杂交”、“水稻”、“研究”、“应用”这几个词语组成成分。
(2)维基百科成分:由于复合短语本身的领域特性,其内部成分往往是由维基百科条目组成。仍以科技复合短语“两系法杂交水稻研究与应用”为例,其中的“杂交”、“水稻”、“研究”、“应用”均为维基百科条目,由此可见,连续的维基百科条目可以作为从输入序列切分科技复合短语的一个重要依据。
(3)特殊组成词性:在科技复合短语中极少出现几类词性、例如系动词、人称代词、感叹词、语气词,输入序列的中若出现此类词性,则依据无关性原则,来切分上下文输入词语序列。
根据以上几个原则,我们提出基于图的紧密度最大化划分的原则:将一个输入序列映射到一个有序的图模型中。将前后具有紧密联系的词语划分到一个分段中,以将无关的成分与候选复合短语相分离。
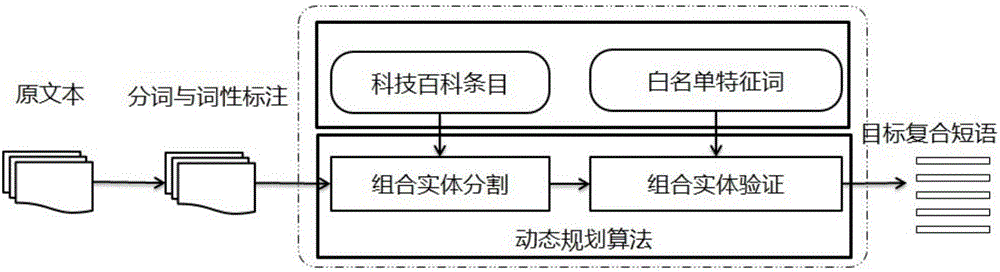
2.科技复合短语识别流程
如图1所示,本方法模型主要分为三部分:第一部分首先采用词性标注工具对输入语料进行词性标注和分词。第二部分通过计算分词结果之间组合的紧密度,通过动态规划求解不同分段组合结果之间的紧密度,将整个输入文本的紧密度之和最大化。第三部分通过验证分段是否包含特征词,从而筛选出需要的复合短语。
我们在这里假定通过基本标点符号截取的输入分词序列前后由边相连,构成一个有序的图结构。在输入的一段文本中,各个词之间在语义上是关联的,所有的分词与关联构成一个图。从该分词的序列中提取并组合合适的内容,如同对图进行了切分。将切分后语义紧密度高的分配到一个分段内,使得整个图的紧密度之和最大(如图2所示)。
这里定义整个输入序列图模型的紧密度为:
s.t.1≤|si|≤uwhere t=s1s2···sm
其中,si代表每一个分段,|si|表示划分分段si中包含分词的个数,t表示分词组成的分段,C(t)表示分段整体紧密度,C(si)表示单个分词对应的紧密度,m表示分段的数目,u表示分段的最大长度。
为了求解所有分段方案的中最优方案,本发明提出基于动态规划的分段划分算法SCSeg(SCi-tech compound entities SEGment solutions),对输入序列求解全局的紧密度划分方法。如下式,对于每一个分段,都有一个对应的分段的紧密度。我们遍历每一个分割方案,将目标函数定义为各个分段紧密度之和,通过动态规划求解目标函数最大值,从而对原输入分词序列求解最优划分分段方案,进而得到文本中科技类复合短语与其他成分的最优的划分方案。
其中,s1=w1…wj,s2=wj+1…wn
上式中,C(s)表示分词组成的分段整体紧密度,s1,s2表示对该分段进一步分割得到的两个子分段,wj表示输入语句中中第j个分词,u代表分段的最大长度,n表示语句中一共包含的分词的数量。
整个输入序列对应图的分段整体紧密度计算公式为:
其中,C(w1,w2)代表分词w1与w2之间的紧密度,s表示一个分段,|s|表示分段中分词的个数。
基于此,本发明提出紧密度最大化的求解算法如下:
返回中C(st)值最大的划分方案作为最优划分
该算法为动态规划算法,共有两个参数:u:分段的最大长度,v:递推求解的候选集合大小。上述算法用自然语言描述如下:
1)假设当前句子包含的分词数为n,算法从1到n-1之间逐个递归遍历切分得到的子分段之和,其中参数u是为了限制每个子分段中包含分词的最大数量;
2)算法从1到n-1之间存储之前划分的子分段的前υ个最优划分,当算法进行下一次递归时,会在已经存储的最优划分方案中递归查找,以求解当前子分段的前υ个最优划分;
3)递归进行这一过程,直到在句子分词的末尾,从而得到整个句子的前υ个最优划分。
3.分词之间的紧密度计算
通过对科技复合短语的分析,本发明将分词之间的紧密度划分为特殊符号紧密度、维基百科紧密度以及词性的紧密度。
我们定义分词之间的紧密度的计算公式为
C(w1,w2)=(Csm(w1,w2)+Cwt(w1,w2))×Cp2v(w1,w2)
其中Csm代表特殊符号紧密度,Cwt代表维基百科紧密度,Cp2v代表词性的紧密度。
特殊符号紧密度:科技复合短语、例如论文与专利题目等往往由特殊符号包围,基于此现象,位于特殊符号内的分词节点应当具有更高的紧密度。我们定义特殊符号紧密度为其中Ds(w1,w2)代表词w1与词w2之间间隔的分词个数,为表征w1与w2之间是否位于同一对特殊符号内的布尔函数。
维基百科紧密度:由上述科技复合短语的维基百科特性可知,连续的维基百科条目为科技复合短语的可能性较大。这里定义维基百科紧密度为。
其中I(w)为表征词w是否为维基百科条目的布尔函数,s’表示位于词w1与词w2之间的分词组成的分段,|s|表示分段s中分词的个数。
词性紧密度:由科技复合短语中特殊组合词性特性可知,部分词性极少出现在科技复合短语中。基于此观察,本发明引入word2vec模型,将词性标注(POS)后的科技复合短语的输入序列作为训练word2vector的模型(以下简称pos2vec),这里定义词性紧密度为。
这里在分子加1是为了保证Cp2v(w1,w2)恒为正。其中,Sc表示词w1和w2对应词性在隐式空间内的余弦相似度,p(ω1),p(ω2)表示词w1和w2对应的词性,表示词w1和w2对应词性在隐式空间的向量。
4.科技复合短语的验证
在切分后的候选科技复合短语实体中,需要对候选的集合进行判断。注意到科技类科技复合短语中包含一类特殊的高频词语、例如上述短语中的“技术”、“研究”和“应用”。我们将这一类词语称为科技复合短语的特征词。特征词集合规模过大会导致过匹配非复合短语。而特征词集合规模过小又会导致遗漏。为了解决上述问题,我们基于最小集合覆盖问题,进行特征词集合的生成。所谓最小集合覆盖,是指给定全集U,以及一个包含n个集合且这n个集合的并集为全集的集合S。集合覆盖问题是要找到S中最小的子集,使得他们的并集等于全集U,并且子集的规模最小。给定科技名词短语集合,记训练集为P={p1,p2,...,pn},其中pi为第i条文本标题。通过对P进行分词处理后可以获取一个词典数据W={w1,w2,...,wm},其中wi为词典中第i个单词。关系类型的特征词提取可以转化为在词典中寻找一个满足最小覆盖的子集S,使得S满足:
1.集合S能够覆盖集合P,即P的每条语料pi中至少有一个单词在S中出现;
2.S中元素个数最小。由于求解最小集合覆盖问题是一个NP-hard问题。这里采用贪心算法求解特征词的覆盖问题。
将求解训练集P的最小覆盖单词集S问题记为WLAN(Words with the LeAst Number)。我们通过以下方法求解特征词的最小覆盖集合。通过训练集P和词典W可以构造一个m×n维的二值矩阵M,若词典中第i个单词wi在pj中出现过则Mij=1,否则Mij=0。首先如图3,定义二元运算符计算结果为去掉矩阵中M第i行以及所有第j列中非0元素Mij≠0,j∈[i,n],组成的新矩阵。如图3所示,P={p1,p2,p3}为三条同类型的标题语料,分词后得到含有4个单词的词典W={w1,w2,w3,w4},构造矩阵M。如果选择单词w2,则的计算结果为删除M的第2行和第1列中非0元素所在的列,得到矩阵M′。利用运算符以使用动态规划的方法来求得问题的最优解。本发明中采用贪心算法计算问题的近似最优解,计算过程如下:
构造布尔矩阵M,对训练语料中所有科技复合短语看作矩阵M的列向量,对于训练语料中所有科技复合短语中所有的分词构成矩阵M的列向量的行向量。若一个单词在某条科技复合短语中出现,则把其对应结果置为1。
矩阵M作为初始输入值,令单词集
选择M中1数量最多的一行,假设为第i行,计算S=S∪wi;
令并将其作为下一步输入;
重复上述两个步骤直到M为空矩阵为止,此时单词集S即所求的最小覆盖集,即得到了科技复合短语的特征词集合。
然后利用该特征词集合,通过验证分段是否包含特征词,从而筛选出需要的复合短语。
5.本发明的效果
本发明利用包含从2005年到2014年的获得国家科技进步奖(National Science and Technology Progress Award between)的科技项目作为输入,爬取并选取1869条语料数据作为实验数据(以下简称为NSTPA),其中每一条语料包含一个或者多条复合短语。在其中本发明选取了681条数据(以下简称为681-NSTPA),前后共投入四名志愿者,花了两个月的时间,做了隐式马尔科夫模型的角色标注。训练集与测试集采用十折交叉验证的方法,另外,本发明从搜狗新闻语料中选取766条数据(以下简称为SOUGOU),其中不包含任何科技复合短语。我们定义单条查全率为、查准率如下:
这里,eij与分别代表正确的科技复合短语与提取出的科技复合短语,代表eij与的公共字串长度。如果eij与均为空,则我们定义Re(ti)=Pr(ti)=1;若eij非空而为空,Re(ti)=0,Pr(ti)=1;若非空而eij为空,Re(ti)=1,Pr(ti)=0。总体查全率和查准率定义为:
表1.实验方法及数据集对比
由表1可以看出,在681-NSTPA对比数据集上,本发明的基于图的最大紧密度划分的复合短语的识别方法(SCSegVal)好于基于隐式马尔科夫的方法(HMM),在完整的数据集NSTPA以及SOUGOU上,取得了80.2%的查全率、80.8%的查准率、80.5%的F1测度以及100%的查全率、55.22%的查准率、71.15%的F1测度。
下面说明切分文本动态求解参数设定:
切分文本的算法有两个参数,分段最大长度u、候选集合大小v。另外我们控制前后图中相连的点的个数在一个滑动窗口内。如图4至图9所示,发现以下规律:
根据图4、图5可以看出,查全率、查准率、F1测度随着u增大而增大。随着u增大,查全率、查准率、F1测度增长速度减慢,随后停滞不前,这表明当u大于科技复合短语时,算法的性能不在增长。
根据图6、图7可以看出,当v增长时,算法总体性能轻微增长,其中准确率在一个阶段内轻微下降,随后增长。造成这一现象的原因是,由于候选集合的增大,算法轻微陷入局部最优,随后由于候选集合的继续增大,算法摆脱局部最优。
根据图8、图9可以看出,当随着滑动窗口的增加,算法性能急剧增加,但是窗口到达一定规模后,算法性能增长趋于停滞。这表明为了减小内存与时间消耗,适当缩减滑动窗口大小,不会明显降低算法的性能。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!