面向知识服务的科研数据处理和预测性分析平台的制作方法
本发明涉及数据处理操作的系统或方法,涉及专门适用于教育部门的系统或方法,尤指一种面向知识服务的科研数据处理和预测性分析平台。
背景技术:
随着信息技术的发展和科研传播的全球化,机构科研成果成为国际各高校及科研院所等单位衡量其基础研究实力的评价标准,众多高校将职称评定、绩效考核、院系奖金等与科研产出和影响力直接挂钩,以此提高科研积极性。另外机构量化的科研数据为学校及相关部门再进行院系重组、发展调整和规划等重大决策时,提供了客观的事实依据。
近年来国内各大高校都把三大文摘数据库(SCI-E、CPCI-S、EI)的论文收录作为学科水平和学术地位的重要指标,另外一些文摘数据库如:SCOPUS作为后起之秀也正在不断扩大其影响力。由于各系统数据收录标准、覆盖范围、数据格式各有不同,而数据本身也会存在错录、误录等诸多不规范情况。往往难以满足机构对数据进行跨平台、跨系统、随机、多选择的调用,不利于机构对科研数据的有效管理和利用。其缺点主要有:
1、数据库规范不一,检全率、检准率低,全面获取机构成果成本高。如机构写法不规范、不统一、更名、同名机构、据拼写错误或字段设置问题等导致的漏检、误检。
2、由于不同平台之间数据的非规范性以及部分隐形数据没有有效的清洗提炼,用户难以直接通过不同平台获取其所需要的直接数据。如难以统计不同院系的发文及贡献率,本校第一机构、通讯机构的成果统计。
3、数据没有有效的进行数据存储、转换,数据再利用率非常低。
技术实现要素:
针对现有技术的缺点,本发明的目的在于提供一种面向知识服务的科研数据处理和预测性分析平台。提供科研数据的一站式管理、查询和预测性分析平台,对科研数据进行便捷管理,提高机构数据利用率和价值,助力机构科研发展。
本发明解决其技术问题所采用的技术方案是:提供一种面向知识服务的科研数据处理和预测性分析平台,其特征在于包括:
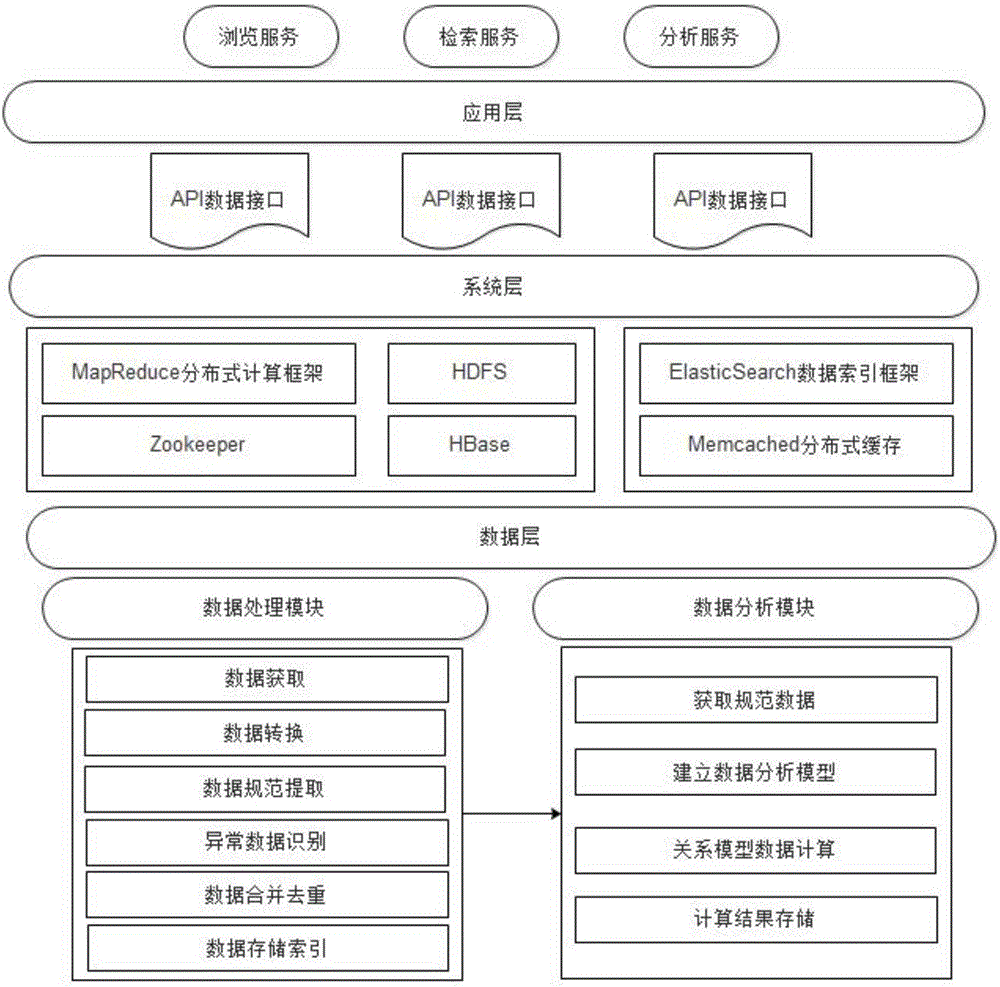
数据处理模块:以国际主流的文摘数据库特定格式接收数据,将不同来源数据库的对应字段、著录规则、存储要求进行统一,将不同来源数据库转化为本平台所需要的数据,对数据进行规范提取,进行异常数据的识别和筛选,将异常数据提取出来以便人工识别,对错误数据重新识别提取;将处理后的数据进行去重处理,并进行MD5加密,规范后数据可通过ES索引实现对数据分析、查询操作;
数据分析模块:用于获取规范后的数据、建立数据分析模型、从关系模型中抽取数据并以可视化视图展示出来;
平台应用模块:用于将数据处理模块以及数据分析模块的结果提供给WEB应用程序,以便用户查询、浏览、统计科研数据。
进一步地:
所述数据处理模块包括:
S1.1数据转换模块:数据转换在于将不同来源数据库的对应字段、著录规则、存储要求进行统一,以便不同来源数据库可以转化为应用平台所需要的数据;
S1.2数据规范提取模块:用于对不同来源数据按照转换数据格式和要求对特定字段数据进行提取;
S1.3异常数据识别模块:对数据异常情况进行判断,通过机器学习可以完善数据清洗规则的数据则利用机器完成数据清洗,机器无法识别匹配,则提交数据处理界面用于将异常数据提取出来以便人工识别,对于处理错误数据重新识别提取。
数据分析模块包括:
S2.1数据分析模型模块:用于建立数据分析模型,根据规范后的数据,提取数据分析结果、存储数据之间的内在关系;
S2.2可视化分析界面:用于数据分析结果以可视化的界面供用户浏览。
本发明的有益效果是:
1整合多源数据,并最终以规范统一的格式,根据用户不同需求,在WEB端提供浏览、检索、查询、统计工作,解决高校对于机构科研数据统计、查询的困扰。
2数据清洗策略和规则可以不断完善和复用,通过初步的数据清洗策略和规则判断即可完成绝大部分机构科研数据的机构清洗工作,极大简化用户数据处理流程;
3对机构科研数据进行进阶分析挖掘,以可视化视图形式直观揭示机构科研情况。
附图说明
下面结合附图对本发明作进一步的描述。
图1是本发明的系统结构图。
图2是本发明的数据处理模块系统图。
图3是本发明的数据分析模块系统图。
具体实施方式
参见附图,本发明一种面向知识服务的科研数据处理和预测性分析平台实施例,包括有:
数据处理模块:参见图2,
数据处理模块包括:数据获取、数据转换、数据规范提取、异常数据识别、数据合并去重、数据存储、索引;为了确保收录数据的准确性,在本发明的实施例中,数据源主要以国际主流的文摘数据库特定格式;数据转换将不同来源数据库的对应字段、著录规则、存储要求进行统一,以便不同来源数据库可以转化为本发明平台所需要的数据;由于部分应用平台所需数据关系隐含于某些字段中,本发明还对数据进行规范提取,如从作者地址字段中提取:国家、省份、城市、邮编、学校、若干二级院系等字段;由于数据本身不规范、或者提取信息中不匹配从而导致了数据无法提取或识别,本发明实施例带有异常数据的识别和筛选,能够将异常数据按照某些规则提取出来以便人工识别,对于处理错误数据能够重新识别提取;处理后的数据按照特定规则进行去重处理,并进行MD5加密;规范后数据通过ES索引实现对数据分析、查询操作;
数据分析模块:数据分析是数据价值挖掘的灵魂,数据可视化在于借助图形化手段,将科研数据的隐含信息直观形象的表达出来,数据分析模块流程参见图3;
数据分析模块包括:通过“数据处理模块”获取规范后的数据、建立数据分析模型、从关系模型中抽取数据并以可视化视图展示出来;其中,数据来源主要为“数据处理模块”规范后的数据;建立数据分析模型是分析的重点,涵盖分析规则设定、分析阈值设定、分析维度确定;将分析数据对象及关系模型定期存储,根据体现数据关系的可视化图表展示数据关系;
平台应用模块:该功能模块主要将数据处理模块以及数据分析模块的结果提供给WEB应用程序,以便用户查询、浏览、统计科研数据;包括在web端浏览科研数据、筛选科研数据、检索科研数据。
在本发明的实施例中:
所述数据处理模块包括:
S1.1数据转换模块:数据转换在于将不同来源数据库的对应字段、著录规则、存储要求进行统一,以便不同来源数据库可以转化为应用平台所需要的数据,如SCI-E作者机构通用格式为学校+二级院系+城市邮编,而EI作者机构通用格式为二级院系+学校+城市邮编,数据转换模块需要将学校与二级院系关系准确转换;
S1.2数据规范提取模块:对不同来源数据按照转换数据格式和要求对特定字段数据进行提取,由于不同数据著录格式不同,有的隐藏字段及数据关系需要从数据关系中提炼获取,如从作者地址字段中提取:国家、省份、城市、邮编、学校、若干二级院系等字段;
S1.3异常数据识别模块:由于数据本身不规范或规则不一,直接获取的一手数据的可利用率比较低,只有对数据进行深层次的挖掘和处理后,用于查询、统计、分析的数据才真实有效;异常数据分为两个情况:机器通过学习可以处理的异常情况(如数据的拼写错误、统一机构的不同命名方式、不同机构写法一致,统一机构不同时间名称变更、非实意的数据干扰等)。预见词库,可以利用分离数据的词频统计技术初步识别大部分数据;采用语法分析和模糊匹配技术对数据相似性判断可以识别系统比较常见的拼写错误等问题;通过利用多字段组合判断的方式分析关联数据,可以用于识别不同机构写法一致的问题;利用非实意词可以分离出干扰数据项;通过将数据清洗策略和规则不断的完善和机器学习,可以进一步提高数据清洗效率。对于机器完全无法识别的问题:如不合法值、数据缺失,则增加异常数据的识别和筛选,以便人工识别。
数据分析模块包括:
S2.1数据分析模型:建立数据分析模型是分析的重点,如何根据规范后的数据,提取数据分析结果、存储数据之间的内在关系,提炼分析的维度是建立数据分析模型的关键;
S2.2可视化分析界面:用于数据分析结果以可视化的界面供用户浏览。
- 还没有人留言评论。精彩留言会获得点赞!