一种推广关键词的触发方法及装置与流程
本发明涉及搜索技术领域,尤其涉及一种推广关键词的触发方法及装置。
背景技术:
搜索引擎是网民获取信息的主要途径,而搜索引擎的收入主要来自于搜索推广,因此搜索引擎公司需要构建复杂的搜索推广投放系统。而搜索推广投放系统展现推广的主要流程为:1)根据用户的搜索词找到与之相关的推广关键词;2)找到购买了这些推广关键词的广告并进行点击率预估;3)根据一定的机制选择推广展现给用户。其中,如何根据用户的搜索词触发出合适的拍卖词,在很大程度上决定了展现的广告是否符合用户的搜索意图。因此,推广关键词的触发技术是搜索推广投放系统中的核心技术之一。
而目前推广关键词的触发技术大多基于搜索关键词的字面变换,例如基于同义词的变换,这种方式,并不能真正从语义上确定与query相匹配的推广关键词,导致触发推广关键词的准确率和召回率较低。因此亟需提供一种推广关键词的触发方法,实现真正从语义上确定与query相匹配的推广关键词,提升推广关键词触发的准确率和召回率。
技术实现要素:
有鉴于此,本发明提供了一种推广关键词的触发方法和装置,实现真正从语义上确定与query相匹配的推广关键词,提升推广关键词触发的准确率和召回率。
本发明为解决技术问题而采用的技术方案是提供一种推广关键词的触发方法,所述方法包括:获取用户输入的query;将所述获取的query对应的输入序列输入到翻译模型,得到输出序列;利用所述输出序列确定所述query触发的推广关键词;其中,所述翻译模型是采用如下方式预先训练得到的:从用户点击行为日志中获取query及其对应的被点击标题作为训练数据;利用训练数据中的query得到输入序列,利用query对应的被点击标题得到目标序列,训练神经网络模型,得到翻译模型。
根据本发明一优选实施例,将所述获取的query对应的输入序列输入到翻译模型包括:对所述获取的query进行分词处理,将分词处理后得到的词语序列作为输入序列输入到翻译模型;所述利用训练数据中的query得到输入序列包括:将训练数据中的query进行分词处理,将分词处理后得到的词语序列作为输入序列。
根据本发明一优选实施例,,所述翻译模型利用beam-search技术以及预设的推广关键词库,对所述获取的query对应的输入序列进行翻译,得到输出序列。
根据本发明一优选实施例,所述翻译模型对所述获取的query对应的输入序列翻译得到的各输出序列满足以下条件:输出序列的数量在beam-size以内,且各输出序列的概率大于或等于预设的概率阈值Q,且在所述推广关键词库中存在与所述输出序列一致的推广关键词或者存在以所述输出序列为前缀的推广关键词。
根据本发明一优选实施例,所述翻译模型在对所述输入序列进行翻译的过程中,在各层均进行如下处理:在推广关键词库中查询各层翻译得到的候选词语;若推广关键词库中不存在以之前各层已确定的词语与该候选词语构成的序列为前缀的词语,则将该候选词语剪枝掉;将剩余的候选词语依据概率值进行排序,将排在beam-size个之后的词语剪枝掉;对排在beam-size个以内的词语中,概率值小于所述Q的词语剪枝掉。
根据本发明一优选实施例,所述神经网络模型为:循环神经网络模型RNN。
根据本发明一优选实施例,利用所述输出序列确定所述query触发的推广关键词包括:判断推广关键词库中是否存在与所述输出序列一致的推广关键词,如果是,则将与所述输出序列一致的推广关键词作为所述query触发的推广关键词。
根据本发明一优选实施例,所述方法还包括:在所述query对应的搜索结果页中包括所述query触发的推广关键词对应的推广结果。
本发明为解决技术问题提供一种推广关键词的触发装置,所述装置包括:获取单元,用于获取用户输入的query;翻译单元,用于将所述获取的query对应的输入序列输入到翻译模型,得到输出序列;确定单元,用于利用所述输出序列确定所述query触发的推广关键词;训练单元,用于采用如下方式预先训练得到所述翻译模型:从用户点击行为日志中获取query及其对应的被点击标题作为训练数据;利用训练数据中的query得到输入序列,利用query对应的被点击标题得到目标序列,训练神经网络模型,得到翻译模型。
根据本发明一优选实施例,所述翻译单元将所述获取的query对应的输入序列输入到翻译模型时,具体执行:对所述获取的query进行分词处理,将分词处理后得到的词语序列作为输入序列输入到翻译模型;所述训练单元在利用训练数据中的query得到输入序列时,具体执行:翻译单元将训练数据中的query进行分词处理,将分词处理后得到的词语序列作为输入序列。
根据本发明一优选实施例,所述翻译单元的翻译模型利用beam-search技术以及预设的推广关键词库,对所述获取的query对应的输入序列进行翻译,得到输出序列。
根据本发明一优选实施例,所述翻译单元中的翻译模型对所述获取的query对应的输入序列翻译得到的各输出序列满足以下条件:输出序列的数量在beam-size以内,且各输出序列的概率大于或等于预设的概率阈值Q,且在所述推广关键词库中存在与所述输出序列一致的推广关键词或者存在以所述输出序列为前缀的推广关键词。
根据本发明一优选实施例,所述翻译单元中的翻译模型在对所述输入序列进行翻译的过程中,在各层均进行如下处理:在推广关键词库中查询各层翻译得到的候选词语;若推广关键词库中不存在以之前各层已确定的词语与该候选词语构成的序列为前缀的词语,则将该候选词语剪枝掉;将剩余的候选词语依据概率值进行排序,将排在beam-size个之后的词语剪枝掉;对排在beam-size个以内的词语中,概率值小于所述Q的词语剪枝掉。
根据本发明一优选实施例,所述翻译单元中翻译模型使用的神经网络模型为:循环神经网络模型RNN。
根据本发明一优选实施例,所述确定单元在利用输出序列确定所述query触发的推广关键词包括:判断推广关键词库中是否存在与所述输出序列一致的推广关键词,如果是,则将与所述输出序列一致的推广关键词作为所述query触发的推广关键词。
根据本发明一优选实施例,所述装置还包括:触发单元,用于在所述query对应的搜索结果页中包括所述query触发的推广关键词对应的推广结果。
由以上技术方案可以看出,本发明选取用户点击行为日志中的query及其对应的被点击标题作为训练数据,训练神经网络模型以得到翻译模型,在获取用户输入的query后,通过预先训练得到的翻译模型获得该query触发的推广关键词。这种方式能够获取到在语义上与query匹配的推广关键词,相比较字面变换的方式,准确率和召回率都得到了较大的提升。
【附图说明】
图1为本发明一实施例提供的方法流程图。
图2为本发明实施例提供的RNN网络结构图。
图3为本发明实施例提供的装置结构图。
图4为本发明实施例提供的设备结构图。
【具体实施方式】
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
在本发明实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。
应当理解,本文中使用的术语“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”或“响应于检测”。类似地,取决于语境,短语“如果确定”或“如果检测(陈述的条件或事件)”可以被解释成为“当确定时”或“响应于确定”或“当检测(陈述的条件或事件)时”或“响应于检测(陈述的条件或事件)”。
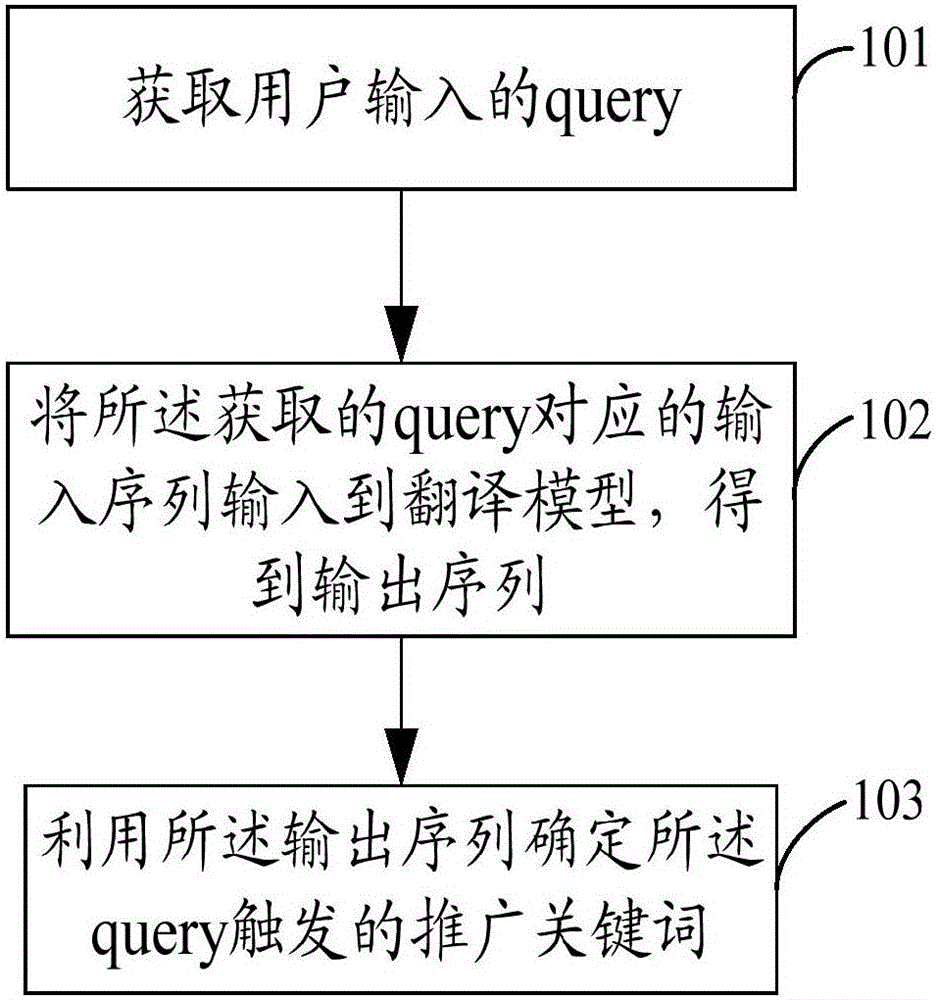
图1为本发明一实施例提供的方法流程图,如图1所示,该方法可以主要包括以下步骤:
在101中,获取用户输入的query。
在本步骤中,用户输入的query可以为任意形式,可以为单个词,也可以为一句话。
在102中,将所述获取的query对应的输入序列输入到翻译模型,得到输出序列。
在本步骤中,对所述获取的query进行分词处理,将分词处理后得到的词语序列作为输入序列输入到翻译模型中。其中的翻译模型为预先训练得到的,通过所获取的训练数据对神经网络模型进行训练,从而得到翻译模型。
在对神经网络模型进行训练时,所使用的训练数据为:从用户点击行为日志中获取的query及其对应的被点击标题所构成的二元组。其中被点击标题优选被点击推广结果的标题。
其中,用户点击行为日志来自于搜索引擎的日志系统。搜索引擎的日志系统会记录用户的点击行为,该点击行为反映了用户的搜索意图和搜索结果与推广之间的相关性。在搜索引擎的日志系统中,会有成熟的算法对用户的有效性和用户点击行为的有效性进行标识,因此本步骤在训练翻译模型时所使用的训练数据为有效用户产生的有效点击数据,也可以将该训练数据称之为用户的优质点击行为数据。利用该训练数据进行训练所得到的翻译模型对输入query进行翻译时会更加准确有效。
在使用训练数据训练神经网络模型得到翻译模型时,将训练数据中的query进行分词处理,将分词处理后得到的词语序列作为输入序列,训练数据中query对应的被点击标题作为目标序列进行训练。
在本步骤中,所使用的神经网络模型优选循环神经网络模型(RNN,Recurrent Neural Network),这是因为循环神经网络模型网络结构中的隐节点之间连接形成环状,而其内部状态则由输入序列决定,因此循环神经网络模型的网络结构非常适合用来处理较长的文本序列,在以下说明中用RNN来表示循环神经网络模型。
RNN网络结构如图2所示,该结构从下到上主要分为5个部分,完成由输入序列到目标序列的训练过程,而该训练过程实际上就是从query到该query所对应被点击标题的翻译过程。
其中,RNN网络结构的第一层为输入端的词向量层,该层将query的每个词表示为词向量,例如训练数据中的query为“如何培养孩子的良好习惯”,将分词后得到的词汇“如何”、“培养”、“孩子”、“的”、“良好”、“习惯”表示为词向量的形式,方框内的数字即表示该词的词向量,通过计算词向量之间的余弦相似度来衡量词语之间的语义相似度;RNN网络结构的第二层为双向RNN层,该层从正反两个方向读取输入的词向量序列,通过迭代的方式将读到的序列信息编码成内部状态,因为训练数据中的query包含有丰富的语义信息,经过第一层将query表示为词向量后,不同的词向量中包含不同的语义信息,双向RNN层将词向量序列中的语义信息进行编码,并将输入序列的语义信息编码在RNN的内部状态中;RNN网络结构的第三层为对齐层,该层用不同的权重值对双向RNN的内部状态进行加权;RNN网络结构的第四层为RNN层,该层通过迭代的方式,依据对齐层的输出、上一次迭代的内部状态及已翻译出的词序列,计算出该次迭代中各词的概率;RNN网络结构的第五层为输出端的词向量层,该层表示了由输入序列翻译得到的目标序列中每个词的词向量。
举例来说,训练数据中的query为“如何培养孩子的良好习惯”,而该query对应被点击的标题为“儿童好习惯培养”。利用RNN网络结构对该训练数据进行训练,训练的目标是尽可能通过该RNN网络结构,在query为“如何培养孩子的良好习惯”时,输出的目标序列为“儿童好习惯培养”。也就是说以RNN网络结构进行训练的目的为:使得训练数据中的query经过翻译后尽可能得到该query对应被点击的标题。
由上面对RNN训练网络结构的描述中可以看出,RNN网络结构在翻译模型中主要用来对序列数据进行编码和解码,双向RNN层对输入序列进行编码,将输入序列的语义信息编码在RNN的内部状态中;而RNN层则将含有语义信息的内部状态解码成目标序列,以此完成由输入序列到目标序列的翻译过程。
因此在本步骤中,将所述获取的query对应的输入序列输入到翻译模型后,得到的输出序列即包含有该query的语义信息。
在103中,利用所述输出序列确定所述query触发的推广关键词。
在本步骤中,在利用训练数据进行翻译模型的训练时,将所获取的训练数据中所有的query及标题进行分词处理,并将所有训练数据分词后得到的词汇组成候选翻译字符集合。
通过步骤102,得到所述输入query的语义信息之后,翻译模型根据所述输入query的语义信息,对候选翻译字符集合中的每个字符赋予相应的概率值。也就是说,当所输入的query不同时,翻译模型对候选翻译字符集合中的每个字符所赋予的概率值是不同的。根据所述候选翻译字符集合中每个字符的概率值,结合beam-search技术以及推广关键词库,对所述输入序列进行翻译,得到输出序列。
推广关键词的触发可以看作是从query到推广关键词的翻译过程,因此可以应用上述翻译模型完成query到推广关键词的触发。但是在这种翻译过程中还存在一个问题,即使用翻译模型翻译的过程是自由的,其输出序列是一个开放空间,因此并不能保证由所输入的query经过翻译模型后就会触发广告主所购买的推广关键词,而且标准机器翻译只要求返回一个最优解,因此会导致降低推广关键词触发的召回率。
针对上述问题,本发明在利用翻译模型对输入的query进行翻译时,采用了改进的beam-search技术,即在对输入query进行翻译前,预先设定beam-size和概率阈值Q。其中,概率阈值Q决定了候选序列选择的最低概率值,该值通过多次实验观察得出;beam-size则决定了每一层翻译时选择的候选序列数量以及最终候选序列集合的大小,该值需要通过权衡翻译性能以及翻译结果相关性来决定。而且本发明在利用翻译模型对输入的query进行翻译时,还需要结合推广关键词库进行,该推广关键词库包含了广告主所购买的所有推广关键词。
因此,在通过翻译模型翻译得到的各输出序列满足以下条件:输出序列的数量在beam-size以内,且各输出序列的概率大于或等于预设的概率阈值Q,且在所述推广关键词库中存在与所述输出序列一致的推广关键词或者存在以所述输出序列为前缀的推广关键词。
在翻译模型对所输入的query进行翻译的过程中,根据输入query的语义信息,翻译模型赋予候选翻译字符集合中每个字符概率值,根据所述候选字符集合中每个字符的概率值,在推广关键词库中得到beam-size个候选字符,因此就保证了不在推广关键词库中的词语不会出现在翻译模型得到的结果中。
并且在使用训练数据进行翻译模型的训练时,在query及其对应的被点击标题后自动添加一个特殊标记字符,该特殊标记字符用以表示翻译结束,那么通过对训练数据进行训练,翻译模型就可以学习到在什么时候输出的那些词会构成一个完整的句子时结束翻译过程。
因此,当某个候选字符以该特殊标记字符结尾时,表明本次翻译过程结束。在翻译结束时,选取beam-size个大于概率阈值Q的候选字符作为最终候选字符,该最终候选字符即为对所述输入query翻译后得到的推广关键词。
举例来说,假设翻译模型采用的候选翻译字符集合为{a,b,c,d,EOF},即在翻译过程中目标序列中的各候选字符从该集合中选取。其中EOF代表翻译结束的特殊标记字符,设定beam-size=2,概率阈值Q=0.3,最终候选序列集合表示为R。
在翻译输入query的首字符时,翻译模型根据该query的语义信息在候选翻译字符集合中给出每个字符作为首字符的概率值,如p(a)代表字符a作为翻译结果首字符的概率值,p(b)代表字符b作为翻译结果首字符的概率值,以此类推。将该字符的概率值从大到小进行排序,假如p(a)最大,则在推广关键词库中首先检索是否有以a为前缀的推广关键词,若有,则将a作为候选首字符,若没有,则剪枝掉a;设p(b)仅次于p(a),则在推广关键词库中检索是否有b,若有,则将b作为候选首字符,若没有,则剪枝掉b。按照该选取规则,最终选取beam-size个候选首字符,其余字符都剪枝掉,且必须保证该beam-size各候选首字符的概率值均大于或等于预设的概率阈值Q,对于概率值小于Q的候选首字符也被剪枝掉。因为设定的beam-size=2,所以选取两个字符作为候选首字符,假设本次选择的候选首字符是a和b。
对于翻译的第二个字符,翻译模型会计算出以a或b开头的所有序列{aa,ab,ac,ad,aEOF,ba,bb,bc,bd,bEOF}的概率,同首字符的选取规则一样,将这些序列依据概率值的大小降序排序,并在推广关键词库中检索是否有以得到的序列为前缀的推广关键词,若有则选取,若无则剪枝掉。最终选取beam-size个概率值大于或等于Q的候选序列进行继续翻译。
重复以上翻译过程,当某个候选序列以EOF结尾时,则认为该输入序列的翻译过程结束,若所得到的候选序列的概率值大于概率阈值Q,则将该序列放入最终候选序列集合R中。当集合R的大小等于beam-size时,翻译结束。
再举例来说,用户输入的query为“如何选择北京鲜花速递”,将该query进行分词处理后得到“如何”、“选择”、“北京”、“鲜花”、“速递”,将分词处理后得到的词汇输入到翻译模型,通过翻译模型得知该输入query的语义后,翻译模型开始进行翻译。
翻译模型首先确定输出的第一个词是什么,根据query的语义对候选翻译字符集合中的每个字符赋予概率值,该概率值代表候选翻译字符中每个字符作为首字符的概率。假如,“如何”、“哪里”、“北京”这三个词的概率值较高,但在推广关键词库中没有检索到以“如何”、“哪里”开头的推广关键词,而检索到以“北京”开头的推广关键词,则放弃前两个词,选取“北京”作为首字符。然后翻译模型确定输出的第二个词是什么,也就是跟在词语“北京”后输出哪个词合适,翻译模型同样对候选翻译字符集合中每个字符赋予概率值,该概率值代表跟在“北京”之后输出这个词汇的可能性,假设第二个字符为“鲜花”和“花卉”的概率值较高,并且在推广关键词库中检索到有以“北京鲜花”或者“北京花卉”开头的推广关键词,则将“鲜花”、“花卉”选择为第二个词,以此类推。假设翻译模型选择了“北京”、“鲜花”、“快递”这三个词汇后,在选择第四个词汇时,翻译模型发现第四个字符为“EOF”的概率最大,则结束本次翻译过程。这时模型会在推广关键词库中检索是否有“北京鲜花快递”这个推广关键词,如果有,并且该推广关键词的概率大于设定的概率阈值Q时,将该词作为候选推广关键词输出。
在利用所述输出序列确定由所述query触发的推广关键词后,便可以利用该推广关键词得到与该推广关键词所对应的推广,在用户输入query后所对应的搜索结果页中便包括由所述query触发的推广关键词对应的推广结果。
利用本发明提供的技术方案,选取用户点击行为日志中的query及其对应的被点击标题作为训练数据,训练神经网络模型以得到翻译模型,在获取用户输入的query后,通过预先训练得到的翻译模型获得该query触发的推广关键词。这种方式能够获取到在语义上与query匹配的推广关键词,相比较字面变换的方式,触发推广关键词的准确率和召回率都得到了较大的提升。
下面对本发明实施例提供的装置结构图进行详述。如图3中所示,所述装置主要包括:获取单元31、翻译单元32、确定单元33、训练单元34以及触发单元35。
获取单元31,用于获取用户输入的query。
在本步骤中,用户输入的query可以为任意形式,可以为单个词,也可以为一句话。
翻译单元32,用于将所述获取的query对应的输入序列输入到翻译模型,得到输出序列。
翻译单元32需要将所述获取的query进行分词处理,将分词处理后得到的词语序列作为输入序列,然后将该输入序列输入到翻译模型进行翻译。
翻译单元32中所使用的翻译模型由训练单元34预先训练得到的,训练单元34通过所获取的训练数据对神经网络模型进行训练,从而得到翻译模型。
训练单元34对神经网络模型进行训练所使用的训练数据为:从用户点击行为日志中获取的query及其对应的被点击标题所构成的二元组。其中被点击标题优选被点击推广结果的标题。
其中,用户点击行为日志来自于搜索引擎的日志系统。搜索引擎的日志系统会记录用户的点击行为,该点击行为反映了用户的搜索意图和搜索结果与推广之间的相关性。在搜索引擎的日志系统中,会有成熟的算法对用户的有效性和用户点击行为的有效性进行标识,因此本步骤在训练翻译模型时所使用的训练数据为有效用户产生的有效点击数据,也可以将该训练数据称之为用户的优质点击行为数据。利用该训练数据进行训练所得到的翻译模型对输入query进行翻译时会更加准确有效。
训练单元34在使用训练数据训练神经网络模型得到翻译模型时,需要将训练数据中的query进行分词处理,将分词处理后得到的词语序列作为输入序列,训练数据中query对应的被点击标题作为目标序列进行训练。
在本步骤中,所使用的神经网络模型优选循环神经网络模型(RNN,Recurrent Neural Network),这是因为循环神经网络模型网络结构中的隐节点之间连接形成环状,而其内部状态则由输入序列决定,因此循环神经网络模型的网络结构非常适合用来处理较长的文本序列。
RNN网络结构如图2所示,该结构从下到上主要分为5个部分,完成由输入序列到目标序列的训练过程,而该训练过程实际上就是从query到该query所对应被点击标题的翻译过程。
其中,RNN网络结构的第一层为输入端的词向量层,该层将query的每个词表示为词向量,例如训练数据中的query为“如何培养孩子的良好习惯”,将分词后得到的词汇“如何”、“培养”、“孩子”、“的”、“良好”、“习惯”表示为词向量的形式,方框内的数字即表示该词的词向量,通过计算词向量之间的余弦相似度来衡量词语之间的语义相似度;RNN网络结构的第二层为双向RNN层,该层从正反两个方向读取输入的词向量序列,通过迭代的方式将读到的序列信息编码成内部状态,因为训练数据中的query包含有丰富的语义信息,经过第一层将query表示为词向量后,不同的词向量中包含不同的语义信息,双向RNN层将词向量序列中的语义信息进行编码,并将输入序列的语义信息编码在RNN的内部状态中;RNN网络结构的第三层为对齐层,该层用不同的权重值对双向RNN的内部状态进行加权;RNN网络结构的第四层为RNN层,该层通过迭代的方式,依据对齐层的输出、上一次迭代的内部状态及已翻译出的词序列,计算出该次迭代中各词的概率;RNN网络结构的第五层为输出端的词向量层,该层表示了由输入序列翻译得到的目标序列中每个词的词向量。
举例来说,训练数据中的query为“如何培养孩子的良好习惯”,而该query对应被点击的标题为“儿童好习惯培养”。利用RNN网络结构对该训练数据进行训练,训练的目标是尽可能通过该RNN网络结构,在query为“如何培养孩子的良好习惯”时,输出的目标序列为“儿童好习惯培养”。也就是说以RNN网络结构进行训练的目的为:使得训练数据中的query经过翻译后尽可能得到该query对应被点击的标题。
由上面对RNN训练网络结构的描述中可以看出,RNN网络结构在翻译模型中主要用来对序列数据进行编码和解码,双向RNN层对输入序列进行编码,将输入序列的语义信息编码在RNN的内部状态中;而RNN层则将含有语义信息的内部状态解码成目标序列,以此完成由输入序列到目标序列的翻译过程。
因此在本步骤中,翻译单元32将所述获取的query对应的输入序列输入到翻译模型中,得到的输出序列包含有该query的语义信息。
确定单元33,用于利用所述输出序列确定所述query触发的推广关键词。
在利用训练数据进行翻译模型的训练时,将所获取的训练数据中所有的query及标题进行分词处理,并将所有训练数据分词后得到的词汇组成候选翻译字符集合。
通过翻译单元32得到所述输入query的语义信息之后,翻译单元32中的翻译模型根据所述输入query的语义信息,对候选翻译字符集合中的每个字符赋予相应的概率值。也就是说,当所输入的query不同时,翻译模型对候选翻译字符集合中的每个字符所赋予的概率值是不同的。根据所述候选翻译字符集合中每个字符的概率值,结合beam-search技术以及推广关键词库,对所述输入序列进行翻译,得到输出序列。
推广关键词的触发可以看作是从query到推广关键词的翻译过程,因此可以应用上述翻译模型完成query到推广关键词的触发。但是在这种翻译过程中还存在一个问题,即使用翻译模型翻译的过程是自由的,其输出序列是一个开放空间,因此并不能保证由所输入的query经过翻译模型后就会触发广告主所购买的推广关键词,而且标准机器翻译只要求返回一个最优解,因此会导致降低推广关键词触发的召回率。
针对上述问题,本发明在利用翻译模型对输入的query进行翻译时,采用了改进的beam-search技术,即在对输入query进行翻译前,预先设定beam-size和概率阈值Q。其中,概率阈值Q决定了候选序列选择的最低概率值,该值通过多次实验观察得出;beam-size则决定了每一层翻译时选择的候选序列数量以及最终候选序列集合的大小,该值需要通过权衡翻译性能以及翻译结果相关性来决定。而且本发明在利用翻译模型对输入的query进行翻译时,还需要结合推广关键词库进行,该推广关键词库包含了广告主所购买的所有推广关键词。
因此,在通过翻译模型翻译得到的各输出序列满足以下条件:输出序列的数量在beam-size以内,且各输出序列的概率大于或等于预设的概率阈值Q,且在所述推广关键词库中存在与所述输出序列一致的推广关键词或者存在以所述输出序列为前缀的推广关键词。
在翻译模型对所输入的query进行翻译的过程中,根据输入query的语义信息,翻译模型赋予候选翻译字符集合中每个字符概率值,根据所述候选字符集合中每个字符的概率值,在推广关键词库中得到beam-size个候选字符,因此就保证了不在推广关键词库中的词语不会出现在翻译模型得到的结果中。
并且在使用训练数据进行翻译模型的训练时,在query及其对应的被点击标题后自动添加一个特殊标记字符,该特殊标记字符用以表示翻译结束,那么通过对训练数据进行训练,翻译模型就可以学习到在什么时候输出的那些词会构成一个完整的句子时结束翻译过程。
因此,当某个候选字符以该特殊标记字符结尾时,表明本次翻译过程结束。在翻译结束时,选取beam-size个大于概率阈值Q的候选字符作为最终候选字符,该最终候选字符即为对所述输入query翻译后得到的推广关键词。
举例来说,假设翻译模型采用的候选翻译字符集合为{a,b,c,d,EOF},即在翻译过程中目标序列中的各候选字符从该集合中选取。其中EOF代表翻译结束的特殊标记字符,设定beam-size=2,概率阈值Q=0.3,最终候选序列集合表示为R。
在翻译输入query的首字符时,翻译模型根据该query的语义信息在候选翻译字符集合中给出每个字符作为首字符的概率值,如p(a)代表字符a作为翻译结果首字符的概率值,p(b)代表字符b作为翻译结果首字符的概率值,以此类推。将该字符的概率值从大到小进行排序,假如p(a)最大,则在推广关键词库中首先检索是否有以a为前缀的推广关键词,若有,则将a作为候选首字符,若没有,则剪枝掉a;设p(b)仅次于p(a),则在推广关键词库中检索是否有b,若有,则将b作为候选首字符,若没有,则剪枝掉b。按照该选取规则,最终选取beam-size个候选首字符,其余字符都剪枝掉,且必须保证该beam-size各候选首字符的概率值均大于或等于预设的概率阈值Q,对于概率值小于Q的候选首字符也被剪枝掉。因为设定的beam-size=2,所以选取两个字符作为候选首字符,假设本次选择的候选首字符是a和b。
对于翻译的第二个字符,翻译模型会计算出以a或b开头的所有序列{aa,ab,ac,ad,aEOF,ba,bb,bc,bd,bEOF}的概率,同首字符的选取规则一样,将这些序列依据概率值的大小降序排序,并在推广关键词库中检索是否有以得到的序列为前缀的推广关键词,若有则选取,若无则剪枝掉。最终选取beam-size个概率值大于或等于Q的候选序列进行继续翻译。
重复以上翻译过程,当某个候选序列以EOF结尾时,则认为该输入序列的翻译过程结束,若所得到的候选序列的概率值大于概率阈值Q,则将该序列放入最终候选序列集合R中。当集合R的大小等于beam-size时,翻译结束。
再举例来说,用户输入的query为“如何选择北京鲜花速递”,将该query进行分词处理后得到“如何”、“选择”、“北京”、“鲜花”、“速递”,将分词处理后得到的词汇输入到翻译模型,通过翻译模型得知该输入query的语义后,翻译模型开始进行翻译。
翻译模型首先确定输出的第一个词是什么,根据输入query的语义对候选翻译字符集合中的每个字符赋予概率值,该概率值代表候选翻译字符中每个字符作为首字符的概率。假如,“如何”、“哪里”、“北京”这三个词的概率值较高,但在推广关键词库中没有检索到以“如何”、“哪里”开头的推广关键词,而检索到以“北京”开头的推广关键词,则放弃前两个词,选取“北京”作为首字符。然后翻译模型确定输出的第二个词是什么,也就是跟在词语“北京”后输出哪个词合适,翻译模型同样对候选翻译字符集合中每个字符赋予概率值,该概率值代表跟在“北京”之后输出这个词汇的可能性,假设第二个字符为“鲜花”和“花卉”的概率值较高,并且在推广关键词库中检索到有以“北京鲜花”或者“北京花卉”开头的推广关键词,则将“鲜花”、“花卉”选择为第二个词,以此类推。假设翻译模型选择了“北京”、“鲜花”、“快递”这三个词汇后,在选择第四个词汇时,翻译模型发现第四个字符为“EOF”的概率最大,则结束本次翻译过程。这时模型会在推广关键词库中检索是否有“北京鲜花快递”这个推广关键词,如果有,并且该推广关键词的概率大于设定的概率阈值Q时,将该词作为候选推广关键词输出。
在确定单元33利用所述输出序列确定由所述query触发的推广关键词后,便可以利用该推广关键词得到与该推广关键词所对应的推广,触发单元35进而在用户输入query后所对应的搜索结果页中包括由所述query触发的推广关键词对应的推广结果。
本发明实施例提供的上述方法和装置可以以设置并运行于设备中的计算机程序体现。该设备可以包括一个或多个处理器,还包括存储器和一个或多个程序,如图4中所示。其中该一个或多个程序存储于存储器中,被上述一个或多个处理器执行以实现本发明上述实施例中所示的方法流程和/或装置操作。例如,被上述一个或多个处理器执行的方法流程,可以包括:
获取用户输入的query;
将所述获取的query对应的输入序列输入到翻译模型,得到输出序列;
利用所述输出序列确定所述query触发的推广关键词;
其中,所述翻译模型是采用如下方式预先训练得到的:
从用户点击行为日志中获取query及其对应的被点击标题作为训练数据;
利用训练数据中的query得到输入序列,利用query对应的被点击标题得到目标序列,训练神经网络模型,得到翻译模型。
利用本发明提供的技术方案,选取用户点击行为日志中的query及其对应的被点击标题作为训练数据,训练神经网络模型以得到翻译模型,在获取用户输入的query后,通过预先训练得到的翻译模型获得该query触发的推广关键词。这种方式能够获取到在语义上与query匹配的推广关键词,相比较字面变换的方式,触发推广关键词的准确率和召回率都得到了较大的提升。
而推广关键词的触发技术是搜索推广投放系统中的核心技术之一,将本发明中所公开的推广关键词的触发方法应用到搜索推广投放系统中,便能够通过用户输入的query触发推广关键词库中的与输入query语义相匹配的推广关键词,然后搜索推广投放系统将与该推广关键词所对应的推广进行展现,从而使得所展现的推广更加符合用户的搜索意图。
在本发明所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!