一种通过文本主题挖掘推测用户大五人格的方法及系统与流程
本发明涉及人格预测领域,更具体地,涉及一种通过文本主题挖掘推测用户大五人格的方法和系统。
背景技术:
目前,随着互联网的发展和社交媒体的普及,人们的生活方式及社交方式产生了极大的变革,人们在社交网站上浏览网页、发照片、写日志、更新状态,留下了越来越多的行为信息。而用户的行为信息可以反映他的喜好、性格,成为了各企业、电商为用户提供个性化服务的重要依据。其中,用户在社交媒体留下的文本信息就是一项重要的数据信息。如今,社交媒体用户文本信息的分析与研究在各个领域都得到了广泛关注,我们可以借助用户在社交媒体平台上发表的状态、日志等文本信息,挖掘用户的情绪、心理、及偏好等。此类技术的优势在于,以往利用调查问卷的形式采集用户信息不仅耗费成本,而且不具备足够的可信度;而用户在社交网络上自发撰写的文本信息既易于搜集,数据量巨大,也真实反映了用户的心情、状态及性格。因此网络社交媒体的文本信息为分析用户行为性格提供了极大的便利,无论在研究方面还是应用方面都有非常重要的意义。但该技术思路也面临着种种挑战,网络社交媒体是一个自由、开放的环境,用户也更趋向于更方便、简洁的表达方式,因此社交媒体文本口语化、非正规特色鲜明,且以短文本居多。这些因素为传统的文本分析带来了极大的挑战。
目前已有一些研究通过社交媒体的文本信息分析用户人格,这些研究大多借助传统词频分析法,LIWC,矩阵分解,主题模型等技术手段,从词项、隐向量等角度对文本进行分析建模。但现有研究大多存在以下局限:(1)主题模型是建立在词语固定的封闭词表基础上,不适用于环境开放、拥有多样语言形式的社交媒体平台;(2)即便少数模型是基于开放性词表的,在用n维向量对文本特征进行描述时,忽略了各个特征之间的语义关系;(3)现有研究利用的少量的经验样本数据进行实验,缺乏一定的可靠性。除以上,现有研究给出的大多是定性分析结果,即只对文本信息与用户行为的关联性存在与否做出回答,局限于“是”与“否”的问题,而没有给出“是多少”的结论。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的一种通过文本主题挖掘推测用户大五人格的方法和系统。
根据本发明的一个方面,提供一种通过文本主题挖掘推测用户大五人格的方法,包括:
S1,采集文本数据及大五人格评分,进行预处理;
S2,基于人格-主题模型,根据预处理后的文本获得人格-主题分布矩阵;
S3,根据人格-主题分布矩阵分析人格与主题关系获得不同主题关联的大五人格得分。
进一步,S1进一步包括:
S1.1,将不同用户的文本按不同的人格分类,获得与不同人格对应的汇总文本;
S1.2,对每个汇总文本进行过滤噪声、分词处理及去停止词。
进一步,S2进一步包括:
S2.1,建立人格-主题模型,并设置人格-主题模型中的参数;
S2.2,利用吉布斯算法,按人格-主题模型推导预处理后的文本,获得人格-主题分布矩阵。
进一步,S3进一步包括:
S3.1,对人格-主题分布矩阵进行纵向归一化处理,获得主题-人格分布矩阵;
S3.2,计算主题区分度;
S3.3,根据每个主题的人格概率分布及区分度,计算每个主题的大五人格得分。
进一步,S2.1进一步包括:
S2.1.1,根据先验参数,对每一种人格,采样主题分布;对每一个主题,采样主题词分布,并采样背景词概率分布和背景词-主题词判断的概率分布;
S2.1.2,对每一种人格,依据对应的主题分布,采样每条文本中主题;
S2.1.3,对每一条文本,依次对每个单词进行采样;
S2.1.4,基于上述文本生成过程,建立人格-主题模型;
S2.1.5,设置先验参数及主题数目。
进一步,S2.2进一步包括:
S2.2.1,随机初始化每条文本的主题编号,随机初始化每个单词属于背景词或主题词;
S2.2.2,利用吉布斯算法对主题和背景词-主题词判断进行循环采样,经过预定次数的迭代,概率分布趋近于稳定,获得人格-主题分布矩阵。
进一步,S3.2进一步包括,所述区分度的计算公式如下:
其中,对每一个主题的不同人格概率值进行排序,XH表示排序后较大的一半的人格概率值,XL表示排序后较小的一半的人格概率值,W表示概率值的上界。
进一步,S2.1.3进一步包括:对每一个的单词,采样该单词是背景词还是主题词,如果是背景词,依据背景词概率分布,采样背景词;如果是主题词,依据该条文本的主题,选取对应的主题词分布采样主题词。
根据本发明的另一面,还提供一种通过文本主题挖掘推测用户大五人格的系统,其特征在于,包括文本采集模块、模型处理模块和人格分析模块,
所述文本采集模块,用于采集文本数据及大五人格评分,进行预处理;
所述模型处理模块,用于基于人格-主题模型,根据预处理后的文本获得人格-主题分布矩阵;
所述人格分析模块,用于根据人格-主题分布矩阵分析人格与主题关系获得不同主题关联的大五人格得分。
本申请提出的一种通过文本主题挖掘推测用户大五人格的方法和系统,建立了一个全新的基于开放词表的主题模型,在心理学中大五人格理论的支撑下,结合用户大五人格标签,使训练样本通过模型作用得到用户主题分布与人格类型的关系,针对主题模型输出的数据结果,寻找有效的数据处理方案和评定方法,对主题与人格的关系进行量化分析,从而实现用户人格预测。
附图说明
图1为现有技术LDA主题模型示意图;
图2为现有技术PT-LDA模型示意图;
图3为本发明一种通过文本主题挖掘推测用户大五人格的方法流程图;
图4为根据本发明人格-主题模型概率模型示意图;
图5为根据本发明第一实施例人格主题分析流程图;
图6为根据本发明第二实施例建立人格-主题模型流程图;
图7为本发明一种通过文本主题挖掘推测用户大五人格的系统示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本发明所述大五人格及文本挖掘的相关术语解释如下:
大五人格:心理学上用五种特质来涵盖人格描述所有方面的理论。包括A(agreeableness,宜人性)、C(conscientiousness,尽责性)、E(extraversion,外向性)、O(openness,开放性)、N(neuroticism,神经质)五个描述人格的维度
主题模型:对文字中隐含主题的一种建模方法,其中主题由词表中词语的条件概率分布表示。
文本挖掘:从大量文本数据中抽取事先未知的、可理解的、最终可用的知识的过程,同时运用这些知识更好地组织信息以便将来参考。
社交网络:由人和人与人之间的关系构成的一种网络。
生成模型:指在给定某些隐含参数的条件下,能够随机生成观测数据的模型,它给观测值和标注数据序列指定了一个联合概率分布。
LIWC:一种基于语词计量的文本分析工具。
词袋模型:这种模型将文本看作是无序的单词集合,根据文本中单词的统计信息完成对文本的分类。
在对本发明实施例进行具体描述前,先对本发明的相关背景技术介绍如下:
1、大五人格理论
大五人格理论,也被称为人格的海洋,是研究者通过词汇学的方法,发现大约有5种因素可以涵盖人格描述的所有方面。这五种因素包括:A(agreeableness,宜人性)、C(conscientiousness,尽责性)、E(extraversion,外向性)、O(openness,开放性)、N(neuroticism,神经质)。
这五类人格因素可以解释为:
A(agreeableness,宜人性):热心对无情,信赖对怀疑,乐于助人对不合作。包括信任、利他、直率、谦虚、移情等品质。
C(conscientiousness,尽责性):有序对无序,谨慎细心对粗心大意,自律对意志薄弱。包括胜任、公正、条理、尽职、成就、自律、谨慎、克制等特点。
E(extraversion,外向性):好交际对不好交际,爱娱乐对严肃,感情丰富对含蓄;表现出热情、社交、果断、活跃、冒险、乐观等特点。
O(openness,开放性):富于想象对务实,寻求变化对遵守惯例,自主对顺从。具有想象、审美、情感丰富、求异、创造、智慧等特征。
N(neuroticism,神经质):烦恼对平静,不安全感对安全感,自怜对自我满意,包括焦虑、敌对、压抑、自我意识、冲动、脆弱等特质。
大五人格测试的个人的得分反馈为百分位数得分。例如,尽责性C评分较高则显示其有较强的责任心,而外向性E评分高则显示测试者需要保持孤独和安静。虽然这些特质群可能存在例外的个性情况,但平均来看,开放性O得分高的话,其求知欲强,有开放的情感,有艺术兴趣,愿意尝试新事物。而有些人可能会有一个全面开放的高得分,他有兴趣学习和探索新的文化,但没有对艺术或者诗歌产生兴趣。
在大五人格理论下产生了不同版本的大五人格测试方案,本专利采用的是由O.John设计提出的44项目大五人格问卷,由此得到用户的大五人格分数作为其人格标签。
2、LDA主题模型
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,三层的含义在于,在该模型中,假设一篇文档包含词、主题和文章三层结构。所谓生成模型,即在一篇文章中,我们将语句看作已知的词语序列,我们认为每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。因此,在已知词语序列的条件下,推测模型中的隐含变量,即造成该结果的主题分布和词语分布。LDA模型文本生成的过程可以详细描述如下:
(1)对一篇文档以随机概率选取一个主题分布;
(2)对文档中的每一个词,依据选定的主题分布随机抽取一个主题;
(3)对每一个词,依据该词的主题,从主题对应的单词分布中抽取一个单词;
(4)重复上述过程直至遍历文档中的每一个单词。
在LDA模型中,单词作为可观测的已知变量,主题作为待推测的隐含变量,一篇文档由若干隐含主题构成,而主题由特定单词的分布来表示。将上述文本生成过程赋予数学表示,其生成图模型如图1所示。
图中各个变量的表示说明如下表1:
概率图可以分解为两个物理过程,一是依据主题的概率分布采样主题的过程,另一个是依据某一个主题的单词分布采样单词的过程。用图中符号描述如下:
(1)α→θm→zm,n,这个过程表示在生成第m篇文档时,先依据先验参数采样得到一个主题分布θm,然后根据主题分布采样生成文档中第n个词的主题,编号zm,n。
(2)这个过程表示生成语料中第m篇文档的第n个词,在K个主题中,挑选主题zm,n代表的单词分布进行采样,然后生成wm,n。
LDA模型假设了文档是在上述过程中生成而来,利用此生成模型对文本进行训练,其输入是已知的词项序列,输出是各文档的主题分布和主题下的单词分布,这其中借助可观测变量推测隐含变量的算法就是Gibbs Sampling算法(吉布斯采样算法)。
3、Gibbs Sampling算法
Gibbs Sampling是一种特殊的MCMC算法,最早由Geman S和Geman D讨论图像恢复时提出,现在广泛应用于统计推断。目前,MCMC已经成为一种处理复杂统计问题的特别流行的工具,主要是利用某中概率分布的已知采样结果,来求取普通方法无法得到的后验分布密度。如上节LDA介绍中所说,Gibbs Sampling算法借助可观测变量推测隐含变量,在主题模型中,可观测变量即指特定词项分布下随机取词的采样结果,待推测变量指的是造成该采样结果的主题分布和词项分布。该算法在马尔可夫平稳分布的理论基础上建立起来,假设马尔可夫链的平稳分布就是所需的后验分布,在多次迭代后找到符合现有采样结果的概率分布。Gibbs Sampling算法的基本思想是,对高维总体或复杂总体取样时,通过平稳分布π的条件分布,来构造一个马尔科夫链{θ{j}},使它以π为平稳分布。当n充分大时,θ(j)的概率分布接近于π,他就可以近似作为分布π的总体样本。Gibbs Sampling算法在给定采样结果为n维向量时,采样过程如下:
1.随机初始化n维采样结果{xi:i=1,…,n}
2.对t=0,1,2…循环采样
(3)…
(5)…
吉布斯采样算法大多是坐标轴轮换采样的,而坐标轴轮换是一个确定性的过程,也就是在给定时刻t,在一根固定的坐标轴上转移的概率是1。Gibbs Sampling算法在足够多的迭代循环后,其采样结果逐渐趋于平稳分布,得到的平稳分布就是我们所要求的后验概率分布。
4、PT-LDA模型
PT-LDA模型如图2所示,首先做出了一下假设:
(1)假设一共有T个用于描述所有用户文档内容的主题。每一个主题都是V个单词的多项分布
(2)用户的人格特性服从于高斯混合分布
(3)每一个用户对一个特定的主题分布θu。
其中主体分布θu有一个狄利克雷先验参数α,单词分布有一个先验参数β,这两个参数在PT-LDA模型中可以看做在对用户文档采样主题和单词前,各个主题数目的预先观察值和从每个主题采样而来的各个单词数目的观察值。
总的来说,PT-LDA模型的文本生成的流程如下:
对每一个用户,采样一个主题分布θu~Dirichlet(α);
对每一个主题,采样一个单词分布
对每一个单词wu,n:
采样zu,n~Dirichlet(θu);
采样
在主题zu,n下大五人格的每一个维度,采样
PT-LDA模型是在假设主题分布决定人格特性的基础上建立起来的,即用户的大五人格评分是由主题决定的高斯分布采样而来。这种假设与我们的常规思维不符,更易接受的假设条件应是用户人格决定主题分布。
PT-LDA模型在探究人格与主题分布的关系时,将用户大五人格的五个维度分开进行讨论,仅仅保证了主题和某一人格维度关系的可靠性,并不具备在分析或预测话题分布时,对某一用户人格特性的综合考虑,从而得到较为片面的预测结果。
本发明借助LDA主题模型的思想,在人格决定主题分布的假设基础上,建立了一个新的生成模型,即人格-主题模型。该模型将一篇文本看作从属于不同主题的单词序列的概率组合,用于探索文档的主题分布特性。不同于传统LDA模型,本模型特别针对于短文本,并引入了背景词的概念,即在一篇文本中,存在与主题相关的单词,也存在与主题无关的背景单词。
如图3所示,为本发明一种通过文本主题挖掘推测用户大五人格的方法流程图,包括:
S1,采集文本数据及大五人格评分,进行预处理;
S2,基于人格-主题模型,根据预处理后的文本获得人格-主题分布矩阵;
S3,根据人格-主题分布矩阵分析人格与主题关系获得不同主题关联的大五人格得分。
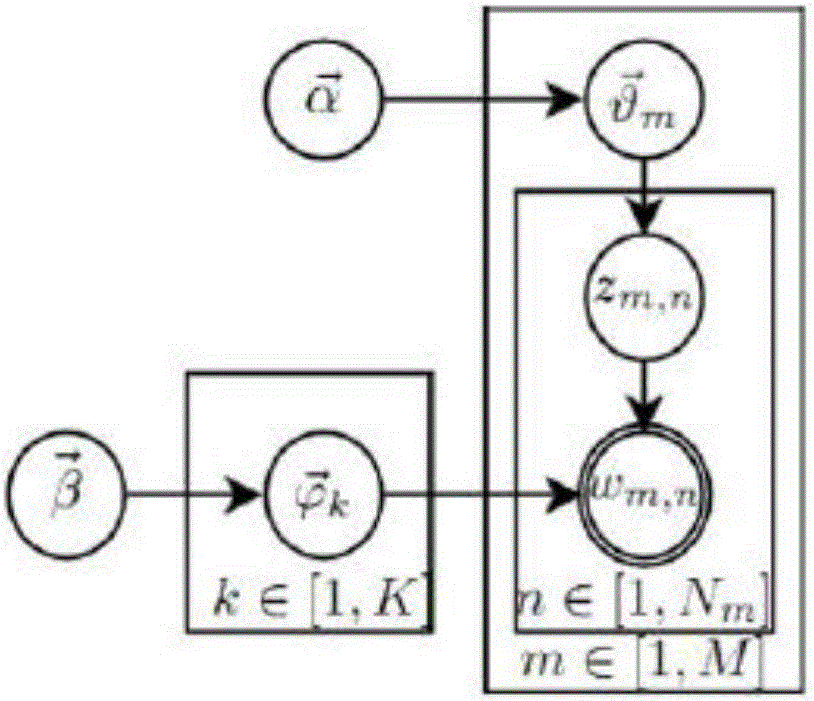
如图4所示,为本发明人格-主题模型概率模型示意图,图中各个圆圈中的符号代表模型中各个参数,右下角字母代表迭代次数;圆圈Wk,s,n代表可观测变量,方框代表需要进行迭代的过程。图中各个符号代表的含义如表2。
表2 模型参数符号含义
通常的经验值是β=βbg=0.01,γ=20。
如图5所示,根据本发明第一实施例人格主题分析流程图,包括如下步骤:
步骤1:采集文本数据及大五人格评分;
步骤2:将不同用户的文本按不同的人格分类;
步骤3:对每个汇总文本进行过滤噪声、分词处理及去停止词;
步骤4:设置人格-主题模型中的参数并按人格-主题模型推导预处理后的文本,获得人格-主题分布矩阵;
步骤5:对人格-主题分布矩阵进行纵向归一化处理,获得主题-人格分布矩阵;
步骤6:计算主题区分度;
步骤7:根据每个主题的人格概率分布及区分度,计算每个主题的大五人格得分。
传统LDA模型对文本主题进行分析时,是只适用于长文本的,本发明中的模型改善了传统主题模型面向短文本的缺陷,尤其适用于当今社交媒体广泛存在的文本形式——口语化严重、非正规语法、及短文本。
其中,
步骤1中,文本数据包括网络环境下社交媒体文本,如微博短文本等;大五人格包括A、C、E、O和N五个维度。本实施例原始数据为144名新浪微博用户从2009年9月至2014年10月的微博文本数据,共计49万条微博。对这144名用户进行大五人格测试,得到每个用户的人格标签,即大五人格中A、C、E、O、N五个维度的得分。
步骤2中,本实施例中,为了达到最佳效果将用户划分为12种不同的人格簇,将同一人格簇的用户文本汇总到一个文档,共12个汇总文本。
步骤3中,对每个汇总文本进行过滤噪声、分词处理及去停止词,生成新的分词文档,方便后续利用人格-主题模型对文本进行处理。
以上步骤2和步骤3为预处理过程。
步骤4中,设置人格-主题模型中的参数包括设置模型中先验参数和主题数目,如下:
主题数T=10,β=βbg=0.01,γ=20
将预处理过的文本经过人格-主题模型,输出人格-主题分布矩阵,如表3。
表3 人格-主题分布矩阵
步骤5中,对结果做纵向归一化处理,即对人格-主题分布矩阵中每一列数值做除以该列总和,目的是消除人格-主题分布中热门话题(即在每一种人格类型中该话题都占有较高比例,比如日记主题)对人格区分度的影响。
步骤6中,引入了区分度D的概念用以判断某个主题的人格倾向是否明显。该区分度的计算借鉴了考试成绩区分度的计算方法,其公式如下:
对每一个主题的不同人格概率值进行排序,XH表示排序后较大的一半的人格概率值,XL表示排序后较小的一半的人格概率值,W表示最大的概率值,本实施例中W=1。
步骤7中,计算出每个主题的人格区分度,如表4,
表4 人格区分度
最后,每一个主题的人格概率分布和区分度D,计算每一个主题的大五人格得分,结果如表5,
所述步骤4中,人格-主题模型的建立如图6所示。根据本发明第二实施例,建立人格-主题模型流程如下:
步骤4.1:根据先验参数,对每一种人格,采样主题分布;对每一个主题,采样主题词分布,并采样背景词概率分布和背景词-主题词判断的概率分布;
步骤4.2:对每一种人格,依据对应的主题分布,采样每条文本中主题;
步骤4.3:对每一条文本,依次对每个单词进行采样;
步骤4.4:基于以上文本生成过程,建立人格-主题模型;
其中,步骤4.3进一步包括:对每一个的单词,采样该单词是背景词还是主题词,如果是背景词,依据背景词概率分布,采样背景词;如果是主题词,依据该条文本的主题,选取对应的主题词分布采样主题词。第二实施例的实施前提为:
假设有U个用户,将这U个用户划分为K种不同的人格,则按人格分类,将U个用户的文本分类成K个汇总文本,每个汇总文本中包含一个或多个用户的文本。同时假设这U个用户的所有文本由T个主题进行描述,每个文本由词与主题以某种概率分布随机组合起来。
具体实施为:
(1)依据先验参数βbg、γ,采样背景词分布背景词和主题词判断的概率分布ρ~Dir(γ);
(2)有T个主题,对每一个主题t=1,…,T,采样主题词分布
(3)有K种人格,对每一种人格k=1,…,K,循环执行如下过程:
A 采样主题分布θk~Dir(α);
B 有Nk个文本,对每一条文本s=1,…,Nk,循环执行如下过程:
B1 采样主题zk,s~Multi(θk);
B2 有Nk,s个单词,对每一个单词n=1,…,Nk,s,循环执行如下过程:
B2.1 采样背景词和主题词的判断xk,s,n~Multi(ρ);
B2.2 如果该词被判断为背景词,即xk,s,n=0,从背景词概率分布中采样背景词如果该词被判断为主题词,即xk,s,n=1,从该主题下的单词分布中采样主题词
上述采样过程表示模型中一篇文本的生成过程,依据该流程的采样结果,用吉布斯采样算法求解概率分布,具体算法表示如下:
1随机初始化每一条微博的主题编号zk,s,s=1,2,…,Nk;
2随机初始化每一个词是背景词还是主题词xk,s,n,s=1,2,…,Nk,n=1,2,…,Nk,s;
3对t=0,1,2…循环采样
(ii)…
(2)…
(ii)…
(4)…
(ii)…
以上过程针对模型中的两个隐变量——主题zk,s和主题词/背景词的判断xk,s,n进行循环采样,zk,s和xk,s,n的初始化(第一次采样)是依据随机概率进行采样的;而后每一次循环时,zk,s和xk,s,n采样所依据的概率分布则是由吉布斯算法得来的,之后每次对主题进行采样时所依据的概率为:
即采样得到主题为zi的概率。
每次对词的主题词/背景词的判断进行采样时所依据的概率为:
分别对应采样为背景词和采样为主题词的概率。
每次循环依照此概率分布对zk,s和xk,s,n进行采样,经过足够次数的迭代后,zk,s的概率分布就无限接近于模型中的参数θk,即k类人格的主题分布。
如图7所示,根据本发明的另一面,还提供一种通过文本主题挖掘推测用户大五人格的系统,其特征在于,包括文本采集模块、模型处理模块和人格分析模块,
所述文本采集模块,用于采集文本数据及大五人格评分,进行预处理;
所述模型处理模块,用于基于人格-主题模型,根据预处理后的文本获得人格-主题分布矩阵;
所述人格分析模块,用于根据人格-主题分布矩阵分析人格与主题关系获得不同主题关联的大五人格得分。
社交媒体内容分析为用户人格分析预测开辟了崭新的思路。利用社交网络文本既可以获得大量的数据集信息,保障信息的真实性,又降低了成本,提高了用户人格分析的准确度。本申请从主题角度对文本进行分析,建立了一个针对网络社交媒体短文本的主题模型,从生成模型的角度,探究主题与人格的关联性。将用户文本信息与其对应的大五人格评分结合起来,提出了一个合理的假设条件——用户人格决定主题分布,并在此假设的基础上,建立了一个新的生成模型——人格-主题模型,推测模型中代表主题分布的参数,直接建立起主题与人格的关系矩阵,得出主题分布与用户综合的人格特性之间关系的解释性,并在合理评判方案下得到此种关联的量化认知,实现人格预测。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
-
 0150268... 来自[中国] 2020年09月24日 22:23没有代码,失望
0150268... 来自[中国] 2020年09月24日 22:23没有代码,失望