信息采集方法与流程
本发明涉及互联网技术领域,特别涉及一种信息采集方法。
背景技术:
随着互联网技术的发展,互联网中信息量越来越大,随之而来的是信息获取工作难度不断增加。
现有技术中获取信息的方法有,利用火车头采集器、八爪鱼采集器等。这些方法可以提供简单的网页抓取,所采用的技术包括GET、POST等网页请求方式,适用于包括列表、详情页的简单网站。但是对于需要运态传递参数的网站则适用效果不理想。
技术实现要素:
有鉴于此,本发明实施例的目的是提供一种采用信息对象模型的方式对网站信息进行抓取和分析的信息采集方法。
为了实现上述目的,本发明实施例提供了一种信息采集方法,包括:
建立待采集信息网站的采集信息入口;
建立用于采集网站信息的信息对象模型;
通过所述采集信息入口,并根据所述信息对象模型,对所述待采集信息网站的信息进行提取,并保存。
作为优选,设置采集信息入口,包括:
构建所述待采集信息网站的信息列表,所述信息列表包含待采集信息网站的链接;
设置对所述待采集信息网站的采集信息规则。
作为优选,通过所述采集信息入口,并根据所述信息对象模型,对所述待采集信息网站的信息进行提取,包括:
获取所述信息列表中的链接;
获取所述链接指向的网站的网站详情页;
判断是否需要保存所述网站详情页中的信息;
若是,则分析所述网站详情页中的信息,并根据所述信息对象模型保存所述网站详情页的信息;
其中,所述信息对象模型包含以下组成网站信息的必要元素:网站名称、网站首页地址、网站LOGO和网站简介。
作为优选,获取所述信息列表中的链接,包括:
检测所述信息列表是否存在分页;
若存在,则循环读取所述信息列表的每一页,以获取所有信息列表中的链接;
若不存在,则直接获取所述信息列表中的链接。
作为优选,根据所述信息对象模型保存所述网站详情页的信息,包括:
根据所述信息对象模型获取所述网站详情页的信息;
将所获取的详情页中的信息根据预设转换规则转换为预设表述;
存储转换后的信息;
分析所提取的详情页中的信息进行,根据分析结果调整所述信息对象模型。
作为优选,通过所述采集信息入口,根据所述信息对象模型,对所述待采集信息网站的信息进行提取之后,所述方法还包括:
检测所采集的信息的完整性。
作为优选,检测所采集的网站信息的完整性,包括:
检测所采集的网站信息是否包括所有组成网站信息的必要元素;
若存在,则确认所采集的网站信息完整。
作为优选,通过所述采集网站信息的入口,根据所述信息对象模型,对所述待采集信息网站的信息进行提取,并保存之前,所述方法还包括:
判断是否已经完成对所述待采集信息网站的信息提取;
若是,则若述待采集信息网站存在信息变更,则重新获取所述待采集信息网站的网站详情页的信息。
作为优选,所述方法还包括;
监控对所述待采集信息网站信息提取的过程;
监控所保存的所述告诉采集信息网站的信息。
作为优选,所述方法还包括;
统计所提取的网站信息,以预测所述待采集信息网站的信息发布量。
与现有技术相比,本发明实施例具有以下有益效果:本发明实施例的技术方案通过建立采集信息入口和信息对象模型,来提取待采集信息网站的信息,不但可以提取简单网站中的信息,对于需要动态传递参数的动态网站也可以适用。
附图说明
图1为本发明的信息采集方法的实施例一的流程图;
图2为本发明的信息采集方法的实施例二的流程图;
图3为本发明的信息采集方法的实施例三的流程图;
图4为本发明的信息采集方法的实施例四的流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图1为本发明的信息采集方法的实施例一的流程图,如图1所示,本实施例的信息采集方法,具体可以包括如下步骤:
S101,建立待采集信息网站的采集信息入口。
具体地,本实施例在具体实施时需要设置能够获取网站信息的入口,即采集信息入口。采集信息入口主要配置为提供网站链接,并且设置采集信息的规则,以便于将不需要采集的信息过滤掉,仅采集需要采集的信息。例如,需要采集某租房网的房屋信息,则可以根据所设置的采集信息的规则,将新闻过滤掉,仅采集房屋信息。
在设置采集信息入口时,还包括设置采集频率。该采集频率可以是一个供任务调度使用的表达式,具体形式可根据任务调度类型而定,如Quartz。
S102,建立用于采集网站信息的信息对象模型。
具体地,在采集信息时,需要根据信息对象模型所包含的元素进行采集。其中,信息对象模型可以包含以下组成网站信息的必要元素:网站名称、网站首页地址、网站LOGO和网站简介。则仍以某租房网为例,需要采集该租房网的网站名称、网站首页地址、网站LOGO和网站简介。当然在实际应用过程中,可以根据实际需要设置信息对象模型所包含的元素。
S103,通过采集信息入口,并根据信息对象模型,对待采集信息网站的信息进行提取,并保存。
具体地,根据采集信息入口提供的网站链接、以及经过过滤保留的需要采集集息的网站,再根据信息对象模型,可以对待采集信息网站的信息进行提取,并保存所提取的信息。
本发明实施例的技术方案通过建立采集信息入口和信息对象模型,来提取待采集信息网站的信息,不但可以提取简单网站中的信息,对于需要动态传递参数的动态网站也可以适用。
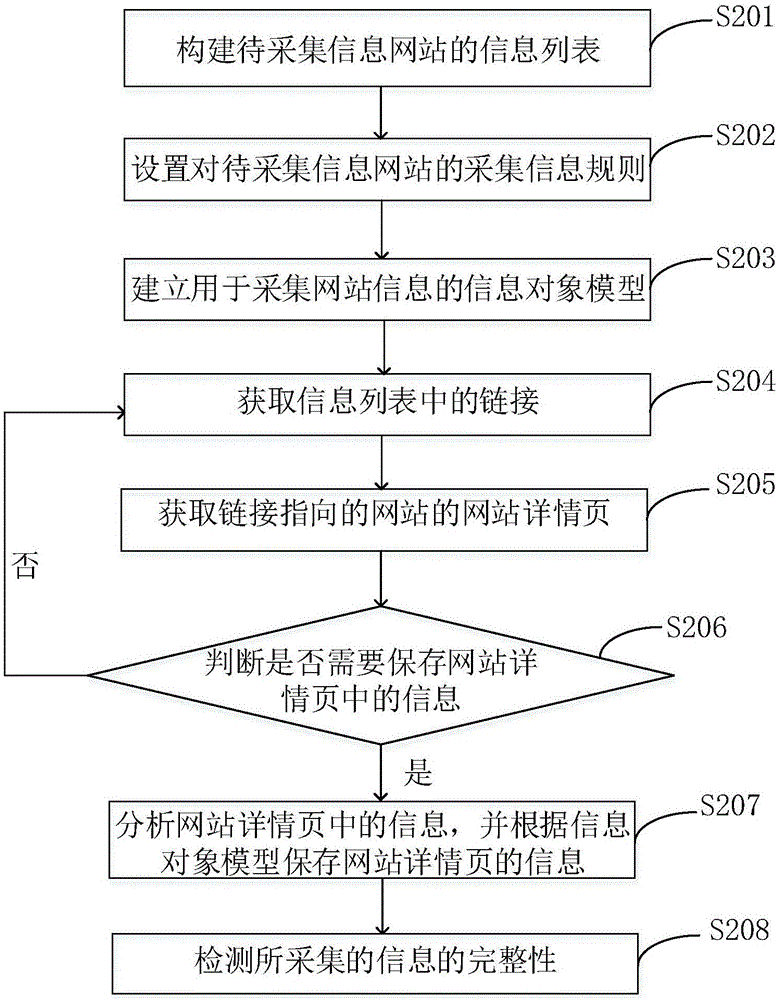
图2为本发明的信息采集方法的实施例二的流程图,本实施例的信息采集方法在如图1所示实施例的基础上,进一步更加详细地介绍本发明的技术方案。如图2所示,本实施例的信息采集方法,具体可以包括如下步骤:
S201,构建待采集信息网站的信息列表,信息列表包含待采集信息网站的链接。
具体地,由于互联网上的信息量巨大,而用户所需要的仅是某一类的信息。因此,可以将用户所需要的某类别的网站构建成待采集信息网站的信息列表,该信息列表应当包含待采集信息网站的链接。
S202,设置对待采集信息网站的采集信息规则。
具体地,采集信息规则,例如,可以设置关键字,获取网站中与关键字相关的信息,例如,将某租房网的关键字设置为房屋地址、房屋所属小区名称、价格等,则在采集该租房网的信息时,可以采集到出租房或者承租房的相关系信息。
S203,建立用于采集网站信息的信息对象模型。
具体地,在采集信息时,需要根据信息对象模型所包含的元素进行采集。其中,信息对象模型可以包含以下组成网站信息的必要元素:网站名称、网站首页地址、网站LOGO和网站简介。则仍以某租房网为例,需要采集该租房网的网站名称、网站首页地址、网站LOGO和网站简介。当然在实际应用过程中,可以根据实际需要设置信息对象模型所包含的元素。
S204,获取信息列表中的链接。
具体地,步骤S204包括:A,检测信息列表是否存在分页;B,若存在,则循环读取信息列表的每一页,以获取所有信息列表中的链接;C,若不存在,则直接获取信息列表中的链接。
S205,获取链接指向的网站的网站详情页。
具体地,由于网站的首页等页面,仅包括一些框架信息,而在实际应用中,客户往往想获得更详细的信息,因此,本实施例根据预先设定的采集信息的规则,仅获取链接指向的网站的网站详情页。
S206,判断是否需要保存网站详情页中的信息;若是,则执行步骤S207;否则,返回执行步骤S204。
具体地,由于网站中往往包含了大量的信息,因此,在采集信息时,要判断哪些是需要保存的信息,而对于无用的信息则放弃掉。例如,对于某租房网,用户仅想知道租房相关的,如房屋地址、价格等信息,而不想知道新闻和广告类的信息,则在提取到新闻或广告类信息时,不保存该类信息。
S207,分析网站详情页中的信息,并根据信息对象模型保存网站详情页的信息。
具体地,分析详情页时,要将该页面的地址、源站点信息编号、信息标题、发布时间进行保存,以便再次采集到该网站时判断信息是否已经提取过,以及该网站的信息是否进行了更新。
具体地,由于网站一般是html网页组成,可以通过正则表达式、Html document(Html Agility Pack)组件等方法对html对象进行分析提取。如果采集内容是特定类型的数据对象,可以通过Json Object、XML Document等对象进行操作,来提取信息。
在具体实施时,进行与提取网站信息相关的任务调度服务时,根据任务表达式启动任务,即根据采集信息入口,来传递一些参数,如分页参数,View State参数等。
S208,检测所采集的信息的完整性。
具体地,由于在采集网站信息时,是根据网站信息的必要元素进行采集,但是这些元素可能存在漏掉的情况,因此,可以根据所采集的信息中是否包含了信息对象模型中的所有必要元素,来判断所采集的信息是否完整。具体地,步骤S208包括:D,检测所采集的网站信息是否包括所有组成网站信息的必要元素;E,若存在,则确认所采集的网站信息完整。
检测信息完整性可以帮助用户进行可用性的判断。
本发明实施例的技术方案通过建立采集信息入口和信息对象模型,来提取待采集信息网站的信息,不但可以提取简单网站中的信息,对于需要动态传递参数的动态网站也可以适用。
图3为本发明的信息采集方法的实施例二的流程图,本实施例的信息采集方法在如图2所示的实施例的基础上,进一步更加详细地介绍本发明的技术方案。如图3所示,本实施例的信息采集方法,具体可以包括如下步骤:
S301,构建待采集信息网站的信息列表,信息列表包含待采集信息网站的链接。
具体地,由于互联网上的信息量巨大,而用户所需要的仅是某一类的信息。因此,可以将用户所需要的某类别的网站构建成待采集信息网站的信息列表,该信息列表应当包含待采集信息网站的链接。
S302,设置对待采集信息网站的采集信息规则。
具体地,采集信息规则,例如,可以设置关键字,获取网站中与关键字相关的信息,例如,将某租房网的关键字设置为房屋地址、房屋所属小区名称、价格等,则在采集该租房网的信息时,可以采集到出租房或者承租房的相关系信息。
S303,建立用于采集网站信息的信息对象模型。
具体地,在采集信息时,需要根据信息对象模型所包含的元素进行采集。其中,信息对象模型可以包含以下组成网站信息的必要元素:网站名称、网站首页地址、网站LOGO和网站简介。则仍以某租房网为例,需要采集该租房网的网站名称、网站首页地址、网站LOGO和网站简介。当然在实际应用过程中,可以根据实际需要设置信息对象模型所包含的元素。
S304,获取信息列表中的链接。
具体地,步骤S304包括:A,检测信息列表是否存在分页;B,若存在,则循环读取信息列表的每一页,以获取所有信息列表中的链接;C,若不存在,则直接获取信息列表中的链接。
S305,获取链接指向的网站的网站详情页。
具体地,由于网站的首页等页面,仅包括一些框架信息,而在实际应用中,客户往往想获得更详细的信息,因此,本实施例根据预先设定的采集信息的规则,仅获取链接指向的网站的网站详情页。
S306,判断是否需要保存网站详情页中的信息;若是,则执行步骤S307;否则,执行步骤S304。
具体地,由于网站中往往包含了大量的信息,因此,在采集信息时,要判断哪些是需要保存的信息,而对于无用的信息则放弃掉。例如,对于某租房网,用户仅想知道租房相关的,如房屋地址、价格等信息,而不想知道新闻和广告类的信息,则在提取到新闻或广告类信息时,不保存该类信息。
S307,分析网站详情页中的信息。
具体地,分析详情页时,要将该页面的地址、源站点信息编号、信息标题、发布时间进行保存,以便再次采集到该网站时判断信息是否已经提取过,以及该网站的信息是否进行了更新。S308,根据信息对象模型获取所述网站详情页的信息。
具体地,由于网站一般是html网页组成,可以通过正则表达式、Html document(Html Agility Pack)组件等方法对html对象进行分析提取。如果采集内容是特定类型的数据对象,可以通过Json Object、XML Document等对象进行操作,来提取信息。
在具体实施时,进行与提取网站信息相关的任务调度服务时,根据任务表达式启动任务,即根据采集信息入口,来传递一些参数,如分页参数,View State参数等。S309,将所获取的详情页中的信息根据预设转换规则转换为预设表述。
具体地,因地域、行业不同,针对同一事物,往往存在不同的表述形式,因此本实施例还提供字典项对应表,将由不同网站提取的信息进行转换,在将所有的表述统一为本实施例预设的表述形式,这样便于后期查询、统计和分析。
该字典项对应表可以支持一定的逻辑运算,例如,必须、相等、包含即可、同时和满足两个及以上条件等逻辑运算。
S310,存储转换后的信息。
具体地,将信息进行转换后,再存储至相应的数据库中。
S311,分析所提取的详情页中的信息进行,根据分析结果调整信息对象模型。
具体地,在提取待采集信息网站的信息过程中,由于信息量较大,用户所关注的信息较多,因此可以对采集的信息进行分析,根据用户所关注的信息对信息对象模型进行调整,这样在下次采集信息过程中将更好地满足客户的需求。
S312,检测所采集的网站信息的完整性。
具体地,由于在采集网站信息时,是根据网站信息的必要元素进行采集,但是这些元素可能存在漏掉的情况,因此,可以根据所采集的信息中是否包含了信息对象模型中的所有必要元素,来判断所采集的信息是否完整。具体地,步骤S311包括:D,检测所采集的网站信息是否包括所有组成网站信息的必要元素;E,若存在,则确认所采集的网站信息完整。
检测信息完整性可以帮助用户进行可用性的判断。
本发明实施例的技术方案通过建立采集信息入口和信息对象模型,来提取待采集信息网站的信息,不但可以提取简单网站中的信息,对于需要动态传递参数的动态网站也可以适用。
图4为本发明的信息采集方法的实施例四的流程图,本实施例的信息采集方法在如图1至图3所示的实施例的基础上,进一步更加详细地介绍本发明的技术方案。如图4所示,本实施例的信息采集方法,具体可以包括如下步骤:
S401,建立待采集信息网站的采集信息入口。
具体地,本实施例在具体实施时需要设置能够获取网站信息的入口,即采集信息入口。采集信息入口主要配置为提供网站链接,并且设置采集信息的规则,以便于将不需要采集的信息过滤掉,仅采集需要采集的信息。例如,需要采集某租房网的房屋信息,则可以根据所设置的采集信息的规则,将新闻过滤掉,仅采集房屋信息。
在设置采集信息入口时,还包括设置采集频率。该采集频率可以是一个供任务调度使用的表达式,具体形式可根据任务调度类型而定,如Quartz。
S402,建立用于采集网站信息的信息对象模型。
具体地,在采集信息时,需要根据信息对象模型所包含的元素进行采集。其中,信息对象模型可以包含以下组成网站信息的必要元素:网站名称、网站首页地址、网站LOGO和网站简介。则仍以某租房网为例,需要采集该租房网的网站名称、网站首页地址、网站LOGO和网站简介。当然在实际应用过程中,可以根据实际需要设置信息对象模型所包含的元素。
S403,判断是否已经完成对待采集信息网站的信息提取;若是,则执行步骤S404;否则,执行步骤S405。
具体地,为避免对于已经采集过信息的网站,重复采集信息会降低执行效率,因此,本实施例判断对该待采集信息网音频毒品是否进行过信息采集。
S404,若待采集信息网站存在信息变更,则重新获取待采集信息网站的网站详情页的信息。
具体地,若已经采集过该待采集信息网站,则需要进行一步判断,该待采集信息网站的信息是否已经更新,若是,则要重新采集,以使用户能够获得最新的信息。
S405,通过采集信息入口,并根据信息对象模型,对待采集信息网站信息提取,并保存。
具体地,如果还没有采集过该待采集信息网站,则根据采集信息入口提供的网站链接、以及经过过滤保留的需要采集集息的网站,再根据信息对象模型,可以对待采集信息网站的信息进行提取,并保存所提取的信息。
S406,监控对待采集信息网站的息提取的过程。
S407,监控所保存的待采集信息网站的信息。
具体地,本实施例对上述整个采信息采集的过程以及结果进行监控,以确定采集过程是否存在异常,可以通过监控数据库中的数据,或者通过获取的信息判断该待采集信息网站是否可用。
S408,统计所提取的网站信息,以预测待采集信息网站的信息发布量。
具体地,可以查看对所有待采集信息网站的信息采集情况,将这些信息进行统计,可以辅助预测某网站的信息发布量走势,从而辅助判断网站的信息采集是否存在异常。
本发明实施例的技术方案通过建立采集信息入口和信息对象模型,来提取待采集信息网站的信息,不但可以提取简单网站中的信息,对于需要动态传递参数的动态网站也可以适用。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!