歌词生成方法及装置与流程
本发明涉及音频处理
技术领域:
,尤其涉及一种歌词生成方法及装置。
背景技术:
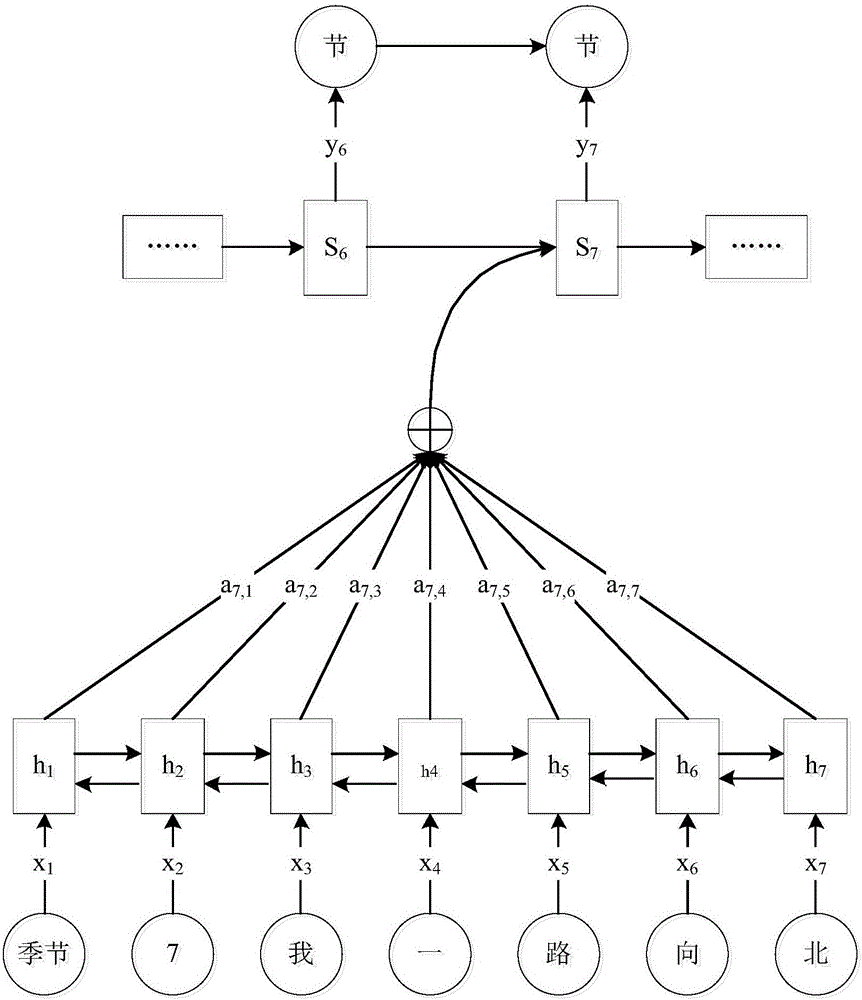
:众所周知,歌曲由歌词和乐曲组合而成。歌词作为诗歌的一种表现形式,是歌曲的本意所在。随着科技的不断发展,机器自动生成歌词的技术也逐渐成熟。目前,可以模仿现有歌曲的歌词结构生成新的歌词,保证生成的歌词与原歌词字数一致,使生成的歌词能够按照原来歌曲的乐曲进行演唱。因此,在给定乐曲的情况下,如何生成与乐曲匹配的歌词成为极具挑战的技术问题。现有基于循环神经网络(RecurrentNeuralNetwork,RNN)语言模型的歌词生成技术,需要先给定歌词的开始部分,将歌词的开始部分作为输入,利用RNN语言模型输出字典里所有字的概率,将概率最大的字作为下一个字。接着将新生成的字作为输入继续生成下一个字。重复上述步骤,直至生成最后一个字,歌词生成过程结束。然而,现有基于语言模型的歌词生成技术难以保证生成歌词与用户所需歌词主旨的相关性,生成的歌词之间的逻辑关联性低。技术实现要素:本发明的目的旨在至少在一定程度上解决上述的技术问题之一。为此,本发明的第一个目的在于提出一种歌词生成方法,该方法能够准确控制生成的每句歌词的长度,提高生成的歌词与主题词之间的相关性以及句子与句子之间的逻辑关联性。本发明的第二个目的在于提出一种歌词生成装置。本发明的第三个目的在于提出一种终端。本发明的第四个目的在于提出一种非临时性计算机可读存储介质。本发明的第五个目的在于提出一种计算机程序产品。为了实现上述目的,本发明第一方面实施例提出了一种歌词生成方法,包括:S1、获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度;S2、基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态;S3、基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词;S4、重复步骤S2和S3,以生成S句歌词。本发明第一方面实施例提出的歌词生成方法,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述目的,本发明第二方面实施例提出了一种歌词生成装置,包括:确定模块,用于获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度;转换模块,用于基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的组成的输入序列进行编码,以将输入序列转换为一组隐状态;生成模块,用于基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词。本发明第二方面实施例提出的歌词生成装置,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述目的,本发明第三方面实施例提出了一种终端,包括:处理器;用于存储处理器可执行指令的存储器。其中,处理器被配置为执行以下步骤:S1’、获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度;S2’、基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态;S3’、基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词;S4’、重复步骤S2’和S3’,以生成S句歌词。本发明第三方面实施例提出的终端,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述目的,本发明第四方面实施例提出了一种非临时性计算机可读存储介质,用于存储一个或多个程序,当存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行第一方面实施例提出的歌词生成方法。本发明第四方面实施例提出的非临时性计算机可读存储介质,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述目的,本发明第五方面实施例提出了一种计算机程序产品,当计算机程序产品中的指令被处理器执行时,执行第一方面实施例提出的歌词生成方法。本发明第五方面实施例提出的计算机程序产品,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。附图说明本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:图1是本发明一实施例提出的歌词生成方法的流程示意图;图2是基于LSTM模型进行编解码生成待生成句子的歌词的过程示意图;图3是基于LSTM模型将输入序列转换为隐状态的流程示意图;图4是基于包含内部状态向量的LSTM模型对隐状态进行解码生成待生成句子的歌词的流程示意图;图5是本发明另一实施例提出的歌词生成方法的流程示意图;图6是本发明又一实施例提出的歌词生成方法的流程示意图;图7是本发明一实施例提出的歌词生成装置的结构示意图;图8是本发明另一实施例提出的歌词生成装置的结构示意图;图9是本发明又一实施例提出的歌词生成装置的结构示意图;图10是本发明还一实施例提出的歌词生成装置的结构示意图;图11是本发明再一实施例提出的歌词生成装置的结构示意图。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。相反,本发明的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。随着科技的不断发展,机器自动生成歌词技术也逐渐成熟。然而,自动谱曲技术尚未成熟,仍需作曲家为歌词谱曲。如果没有作曲家谱写乐曲,生成的歌词则无法成为歌曲被演唱。这种情况下,可以通过为现有歌曲进行填词的方法来规避谱曲问题。也就是说,可以模仿现有歌曲的歌词结构生成新的歌词,保证生成的歌词与原歌词字数一致,使生成的歌词能够按照原来歌曲的乐曲进行演唱。因此,在给定乐曲和关键词的情况下,如何生成与乐曲匹配的歌词成为极具挑战的技术问题。现有基于RNN语言模型的歌词生成技术,需要先给定歌词的开始部分,将歌词的开始部分作为输入,利用RNN语言模型输出字典里所有字的概率,将概率最大的字作为下一个字。接着将新生成的字作为输入继续生成下一个字。重复上述步骤,直至生成最后一个字,歌词生成过程结束。然而,现有基于语言模型的歌词生成技术由于需要提供歌词的开始部分,难以保证歌词与关键词的相关性。由于语言模型能够记忆的历史信息有限,可能导致句子之间的逻辑关联性低。另外,由于采用现有技术生成歌词无法控制生成内容的长度,难以保证生成歌词的长度与指定乐曲长度的一致性。为了弥补现有歌词生词技术的不足,本发明提出一种歌词生成方法及装置,能够准确控制生成的每句歌词的长度,提高生成的歌词与主题词之间的相关性以及句子与句子之间的逻辑关联性。图1是本发明一实施例提出的歌词生成方法的流程示意图。如图1所示,本实施例的歌词生成方法包括:S1:获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度。本实施例中,为了生成新的歌词,首先要获取源歌词,并确定源歌词中所有句子的数量,记为S;同时获取源歌词中每个句子的长度。其中,源歌词指的是与待使用的乐曲组合成歌曲的歌词;句子的长度指的是该句子中所包含的字数。本实施例中,为了能够将待使用的乐曲和新生成的歌词组合成歌曲进行演唱,并保证新生成的歌词与待使用的乐曲匹配,需要先获取与待使用的乐曲组合成歌曲的源歌词,并确定源歌词中句子的数量以及每个句子的长度。S2:基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态。本实施例中,在确定了源歌词的句子数量和每个句子的长度之后,即可基于双向时间递归神经网络(Long-ShortTermMemory,LSTM)模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态。其中,LSTM模型是RNN模型的一种改进模型。在LSTM模型中,利用存储单元代替RNN模型中的常规神经元,每个存储单元与一个输入门、一个输出门和一个跨越时间步骤无干扰送入自身的内部状态相关联。相较于RNN模型,LSTM模型具有更强的记忆能力,能够记住更长的历史信息。需要说明的是,主题词是根据用户需求预先分配的与待生成句子相关的关键词,可以是单个字,也可以是多个字组词的词,对此不作限制。待生成句子的长度与源歌词中相应位置的句子的长度相同,即待生成句子中所包含的字数与源歌词中相应位置的句子所包含的字数相同。本实施例中,首先为待生成句子分配主题词,并根据源歌词的句子长度确定对应的待生成歌词的句子长度。接着,将待生成句子的主题词、待生成句子的长度,以及已生成的歌词按照顺序组成一个输入序列,利用双向LSTM模型对组成的输入序列进行编码,以将输入序列转换为一组隐状态。举例而言,假设将待生成句子的主题词、待生成句子的长度和已生成的歌词按序组合后,形成一个长度为T的输入序列,记为X=(x1,x2,…,xT)。将该序列输入至双向LSTM模型进行编码,即可获得一组隐状态,记为(h1,h2,…,hT)。需要说明的是,在生成第一句待生成句子的歌词时,由于此前没有已生成的歌词,因此,此时只将待生成句子的主题词和待生成句子的长度组成的输入序列输入至LSTM模型进行编码来将其转换为一组隐状态。S3:基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词。本实施例中,在获得待生成句子的主题词、长度和已生成的歌词组成的输入序列对应的隐状态后,基于包含内部状态向量的LSTM模型对获得的隐状态进行解码,即可生成待生成句子的歌词。其中,内部状态向量是解码端的LSTM模型自身携带的参数,用于生成与输入的隐状态最相关的字,并在解码的过程中不断更新,具体更新过程将在后续内容中给出。作为一种示例,参见图2,图2是基于LSTM模型进行编解码生成待生成句子的歌词的过程示意图。如图2所示,待生成句子的主题词为“季节”,待生成句子的长度为“7”,已生成的歌词为“我一路向北”,按序组成一个输入序列为“季节”“7”“我”“一”“路”“向”“北”,该输入序列的长度为7,记为X=(x1,x2,…,x7)。接着,基于双向LSTM模型对该长度为7的输入序列进行编码,获得一组隐状态,记为(h1,h2,…,h7)。随后,根据生成第i个字时各个隐状态对应的注意力得分,基于包含内部状态向量的LSTM模型对隐状态进行解码,生成第i个字。其中,i为正整数,i=1,2,…,7。图2中,a7,1,a7,2,…,a7,6,a7,7表示生成第7个字时各个隐状态对应的注意力得分,加权求和之后,结合内部状态向量S7,基于LSTM模型进行解码,获得待生成句子的第7个字y7,即“节”字。需要说明的是,隐状态对应的注意力得分是通过计算获得的,具体计算过程将在后续内容中给出。S4:重复步骤S2和S3,以生成S句歌词。本实施例中,在生成当前待生成句子的歌词之后,将其之后待生成的歌词作为新的待生成句子,并确定待生成句子的主题词和长度,将新生成的歌词作为已生成的歌词,重复前述步骤S2和S3,直至生成最后一句待生成句子的歌词,最终获得S句歌词。以歌曲《虫儿飞》为例。为了生成一首能够使用歌曲《虫儿飞》的乐曲的新歌词,需要保证新生成的歌词与歌曲《虫儿飞》的歌词具有相同的歌词结构。生成新歌词的具体过程描述如下:首先,需要获取歌曲《虫儿飞》的歌词作为源歌词。歌曲《虫儿飞》的歌词如下所示:黑黑的天空低垂亮亮的繁星相随虫儿飞虫儿飞你在思念谁天上的星星流泪地上的玫瑰枯萎冷风吹冷风吹只要有你陪通过获取《虫儿飞》的源歌词,可以确定该源歌词的句子数量为8句,每个句子的长度分别为7,7,6,5,7,7,6,5。假设第一句待生成句子的主题词为“天空”。根据源歌词第一个句子的长度,可以确定第一句待生成句子的长度为7。由于待生成句子为第一句,之前没有已生成的歌词,故仅将“天空”和“7”组成输入序列,经过双向LSTM模型进行编码和包含内部状态向量的LSTM模型进行解码之后,即可获得新歌词的第一句歌词“拥抱蔚蓝的天空”。假设第二句待生成句子的主题词为“繁星”。根据源歌词第二个句子的长度,可以确定第二句待生成句子的长度为7。将第二句待生成句子的主题词、长度、已生成的歌词即“拥抱蔚蓝的天空”组成输入序列,经过双向LSTM模型进行编码和包含内部状态向量的LSTM模型进行解码之后,即可获得新歌词的第二句歌词“有一颗繁星闪烁”。如此重复,即可获得与源歌词结构相同的新歌词的8句歌词,如下所示:拥抱蔚蓝的天空有一颗繁星闪烁萤火虫萤火虫世界多逍遥越过高山和海洋梦想靠在你肩膀任风浪任风浪迷失了方向需要说明的是,由于本实施例提出的歌词生成方法采用的是LSTM模型,之后的每一句歌词均是基于之前所有的歌词生成的。也就是说,在生成第五句歌词时,用到了已经生成的前四句歌词;在生成第六句歌词时,用到了已经生成的前五句歌词。这样,能够使句子之间的关联性更强。本发明实施例提出的歌词生成方法,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。图3是基于LSTM模型将输入序列转换为隐状态的流程示意图。如图3所示,前述步骤S2具体可以包括以下步骤:S21:基于正向LSTM模型对输入序列进行正向编码,以获取正向隐状态。S22:基于反向LSTM模型对输入序列进行反向编码,以获取反向隐状态。本实施例中,将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列输入至双向LSTM模型之后,基于正向LSTM模型对输入序列进行正向编码生成正向隐状态;基于反向LSTM模型对输入序列进行反向编码生成反向隐状态。需要说明的是,本实施例中获取正向隐状态和反向隐状态的步骤可以是先后进行的,也可以是同时进行,本发明对此不作限制。S23:拼接正向隐状态和反向隐状态,以生成隐状态。本实施例中,在分别获得正向隐状态和反向隐状态之后,拼接获得的正向隐状态和反向隐状态,生成输入序列对应的一组隐状态。本发明实施例提出的歌词生成方法,通过基于正向LSTM模型对输入序列进行正向编码获取正向隐状态,基于反向LSTM模型对输入序列进行反向编码获取反向隐状态,拼接正向隐状态和反向隐状态生成隐状态,能够同时获得上文和下文的信息,相较于单向LSTM模型和RNN模型能够获得更多的信息,进一步提高歌词生成的准确性。图4是基于包含内部状态向量的LSTM模型对隐状态进行解码生成待生成句子的歌词的流程示意图。如图4所示,前述步骤S3可以包括以下步骤:S31:获取隐状态对应的注意力得分。本实施例中,在获得输入序列对应的隐状态后,继续获取各个隐状态对应的注意力得分。具体地,可以根据公式(1)和公式(2)计算获得隐状态对应的注意力得分。其中,va、Wa和Ua是在模型训练过程中生成并更新的参数矩阵。k为正整数,且k=1,2,…,Tx,Tx表示输入序列X的长度。i、j均为正整数,其中,i=1,2,…,Tx,表示输入序列X的第i个元素;j=1,2,…,Tx,表示与输入序列X对应的隐状态的第j个元素。S32:根据隐状态和隐状态对应的注意力得分获得输入序列的历史信息向量。本实施例中,在获得隐状态对应的注意力得分之后,即可根据隐状态和隐状态对应的注意力得分获得输入序列的历史信息向量。具体地,可以根据公式(3)计算获得输入序列的历史信息向量。其中,i、j均为正整数,i=1,2,…,Tx,j=1,2,…,Tx。从公式(3)可以看出,在生成输入序列X中第i个元素对应的历史信息向量时,将此时各个隐状态对应的注意力得分分别与相应的隐状态相乘后相加,即可获得输入序列X中第i个元素对应的历史信息向量ci。S33:根据内部状态向量、历史信息向量和前一个字生成当前字。本实施例中,在计算获得输入序列的历史信息向量之后,即可根据内部状态向量、历史信息向量和前一个字生成当前字。具体地,可以根据公式(4)计算生成当前字。yi=argmaxp(y|si,ci,yi-1)(4)其中,si表示内部状态向量;ci表示计算所得的历史信息向量;yi-1表示前一个字,i为正整数,i=1,2,…,待生成句子的长度。S34:将生成的当前字组合成待生成句子的歌词。本实施例中,在生成符合待生成句子的长度的多个字之后,即可将生成的多个字组合成待生成句子的歌词。举例而言,假设待生成句子的长度为7,采用本实施例提出的歌词生成方法生成的7个字分别为“离”、“开”、“有”、“你”、“的”、“季”和“节”,则将这7个字组合可以获得待生成句子的歌词为“离开有你的季节”。可选地,参见图5,图5是本发明另一实施例提出的歌词生成方法的流程示意图。如图5所示,在根据内部状态向量、历史信息向量和前一个字生成当前字之后,还可以包括以下步骤:S35:更新内部状态向量。本实施例中,在根据内部状态向量、历史信息向量和前一个字生成当前字之后,可以对内部状态向量进行更新,以提高生成字的准确性。具体地,可以根据公式(5)更新解码端LSTM模型的内部状态向量。si=f(si-1,ci-1,yi)(5)其中,i为正整数,i=1,2,…,待生成句子的长度。需要说明的是,本实施例中的步骤S34和步骤S35可以同时进行,也可以分先后进行,本发明对此不作限制。本发明实施例提出的歌词生成方法,通过获取隐状态对应的注意力得分,并根据注意力得分和对应的隐状态获得输入序列的历史信息向量,进而根据内部状态向量、历史信息向量和前一个字生成当前字,将生成的多个字组合成待生成句子的歌词,能够提高字与字之间的关联性,进一步提高歌词生成的准确性。图6是本发明又一实施例提出的歌词生成方法的流程示意图。如图6所示,基于上述实施例,该歌词生成方法,还可以包括以下步骤:S5:训练双向LSTM模型和包含内部状态向量的LSTM模型。本发明实施例中,为了能够利用双向LSTM模型和包含内部状态向量的LSTM模型生成歌词,需要对上述两个模型进行训练。具体地,训练双向LSTM模型和包含内部状态向量的LSTM模型,包括:获取主题词样本和主题词样本对应的歌词样本;根据主题词样本和歌词样本训练双向LSTM模型和包含内部状态向量的LSTM模型。本实施例中,为了能够训练双向LSTM模型和包含内部状态向量的LSTM模型,需要获取大量的歌词以生成训练样本。具体地,从获取的歌词中的每句歌词中分别提取主题词,将提取的主题词、主题词对应的该句歌词的长度,以及前一句歌词共同作为主题词样本;将主题词对应的该句歌词作为歌词样本。主题词样本和对应的歌词样本组成样本对。需要说明的是,可以从预设歌词库中获取歌词,也可以从互联网数据库中获取歌词,或者以其他方式获得歌词,本发明对此不作限制。另外,需要说明的是,可以通过人工标注的方式从歌词中获得主题词样本与歌词样本的样本对,也可以采用相关技术自动获得主题词样本与歌词样本的样本对,本发明对此不作限制。下面以歌曲《一路向北》的前4句歌词为例来说明样本对的构造过程。首先,从每一句歌词中提取一个词作为主题词,如表1所示:表1主题词与歌词对应关系表主题词歌词长度主题词对应的歌词路5我一路向北季节7离开有你的季节累5你说你好累爱7已无法再爱上谁接着,构造主题词样本和歌词样本的样本对,如表2所示:表2样本对表主题词样本歌词样本路5我一路向北季节7我一路向北离开有你的季节累5我一路向北离开有你的季节你说你好累爱7我一路向北离开有你的季节你说你好累已无法再爱上谁从表2可以看出,主题词样本由主题词、主题词对应歌词的长度和前一句歌词组成,歌词样本由主题词对应的歌词组成。而由于在第一句歌词之前没有歌词,与第一句歌词对应的主题词样本仅由第一句歌词的主题词和第一句歌词的长度组成。在获得大量的主题词样本和主题词样本对应的歌词样本组成的样本对之后,即可根据获得的样本对训练双向LSTM模型和包含内部状态向量的LSTM模型。需要说明的是,本实施例中的步骤S5可以在步骤S2执行之前的任一时刻被执行,本发明对此不作限制。本发明实施例提出的歌词生成方法,通过获取主题词样本和对应的歌词样本来训练双向LSTM模型和包含内部状态向量的LSTM模型,能够利用双向LSTM模型和包含内部状态向量的LSTM模型自动生成歌词,进一步提高歌词生成的准确性。为了实现上述实施例,本发明还提出了一种歌词生成装置,图7是本发明一实施例提出的歌词生成装置的结构示意图。如图7所示,本实施例的歌词生成装置包括:确定模块710、转换模块720,以及生成模块730。其中,确定模块710,用于获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度。转换模块720,用于基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态。生成模块730,用于基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词。需要说明的是,为了生成整首歌的歌词,转换模块720和生成模块730需要重复工作,直至生成S句歌词。需要说明的是,前述实施例中对歌词生成方法实施例的解释说明也适用于本实施例的歌词生成装置,其实现原理类似,此处不再赘述。本发明实施例提出的歌词生成装置,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。图8是本发明另一实施例提出的歌词生成装置的结构示意图。如图8所示,该歌词生成装置的转换模块720,可以包括:正向编码单元721,用于基于正向LSTM模型对输入序列进行正向编码,以获取正向隐状态。反向编码单元722,用于基于反向LSTM模型对输入序列进行反向编码,以获取反向隐状态。拼接单元723,用于拼接正向隐状态和反向隐状态,以生成隐状态。需要说明的是,前述实施例中对歌词生成方法实施例的解释说明也适用于本实施例的歌词生成装置,其实现原理类似,此处不再赘述。本发明实施例提出的歌词生成装置,通过基于正向LSTM模型对输入序列进行正向编码获取正向隐状态,基于反向LSTM模型对输入序列进行反向编码获取反向隐状态,拼接正向隐状态和反向隐状态生成隐状态,能够同时获得上文和下文的信息,相较于单向LSTM模型和RNN模型能够获得更多的信息,进一步提高歌词生成的准确性。图9是本发明又一实施例提出的歌词生成装置的结构示意图。如图9所示,该歌词生成装置的生成模块730,可以包括:获取单元731,用于获取隐状态对应的注意力得分。获得单元732,用于根据隐状态和隐状态对应的注意力得分获得输入序列的历史信息向量。生成单元733,用于根据内部状态向量、历史信息向量和前一个字生成当前字。组合单元734,用于将生成的当前字组合成待生成句子的歌词。可选地,如图10所示,该歌词生成装置的生成模块730,还可以包括:更新单元735,用于在根据内部状态向量、历史信息向量和前一个字生成当前字之后,更新内部状态向量。需要说明的是,前述实施例中对歌词生成方法实施例的解释说明也适用于本实施例的歌词生成装置,其实现原理类似,此处不再赘述。本发明实施例提出的歌词生成装置,通过获取隐状态对应的注意力得分,并根据注意力得分和对应的隐状态获得输入序列的历史信息向量,进而根据内部状态向量、历史信息向量和前一个字生成当前字,将生成的多个字组合成待生成句子的歌词,能够提高字与字之间的关联性,进一步提高歌词生成的准确性。图11是本发明再一实施例提出的歌词生成装置的结构示意图。如图11所示,该歌词生成装置还可以包括:训练模块740,用于训练双向LSTM模型和包含内部状态向量的LSTM模型。具体地,训练模块740用于:获取主题词样本和主题词样本对应的歌词样本;根据主题词样本和歌词样本训练双向LSTM模型和包含内部状态向量的LSTM模型。需要说明的是,前述实施例中对歌词生成方法实施例的解释说明也适用于本实施例的歌词生成装置,其实现原理类似,此处不再赘述。本发明实施例提出的歌词生成装置,通过获取主题词样本和对应的歌词样本来训练双向LSTM模型和包含内部状态向量的LSTM模型,能够利用双向LSTM模型和包含内部状态向量的LSTM模型自动生成歌词,进一步提高歌词生成的准确性。为了实现上述实施例,本发明还提出了一种终端,包括:处理器,以及用于存储处理器可执行指令的存储器。其中,处理器被配置为执行以下步骤:S1’、获取源歌词,并确定源歌词中句子的数量S以及每个句子的长度;S2’、基于双向时间递归神经网络LSTM模型将待生成句子的主题词、待生成句子的长度和已生成的歌词组成的输入序列进行编码,以将输入序列转换为一组隐状态;S3’、基于包含内部状态向量的时间递归神经网络LSTM模型对隐状态进行解码,以生成待生成句子的歌词;S4’、重复步骤S2’和S3’,以生成S句歌词。需要说明的是,前述实施例中对歌词生成方法实施例的解释说明也适用于本实施例的终端,其实现原理类似,此处不再赘述。本发明实施例提出的终端,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述实施例,本发明还提出了一种非临时性计算机可读存储介质,用于存储一个或多个程序,当存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行本发明第一方面实施例提出的歌词生成方法。本发明实施例提出的非临时性计算机可读存储介质,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。为了实现上述实施例,本发明还提出了一种计算机程序产品,当计算机程序产品中的指令被处理器执行时,执行本发明第一方面实施例提出的歌词生成方法。本发明实施例提出的计算机程序产品,通过确定源歌词中句子的数量和每个句子的长度,基于双向时间递归神经网络模型将待生成句子的主题词、长度和已生成的歌词组成的输入序列进行编码转换为一组隐状态,并基于包含内部状态向量的时间递归神经网络模型对隐状态进行解码生成待生成句子的歌词,进而生成与源歌词句子数量相同的新的歌词。由此,能够准确控制生成的每句歌词的长度,通过为每句话分配主题词提高生成的歌词与主题词之间的相关性,并利用已生成的句子生成后续的句子,提高句子与句子之间的逻辑关联性。需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属
技术领域:
的技术人员所理解。应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。本
技术领域:
的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。上述提到的存储介质可以是只读存储器,磁盘或光盘等。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1