基于标记分布的解决类别缺失问题的人类年龄自动估计方法与流程
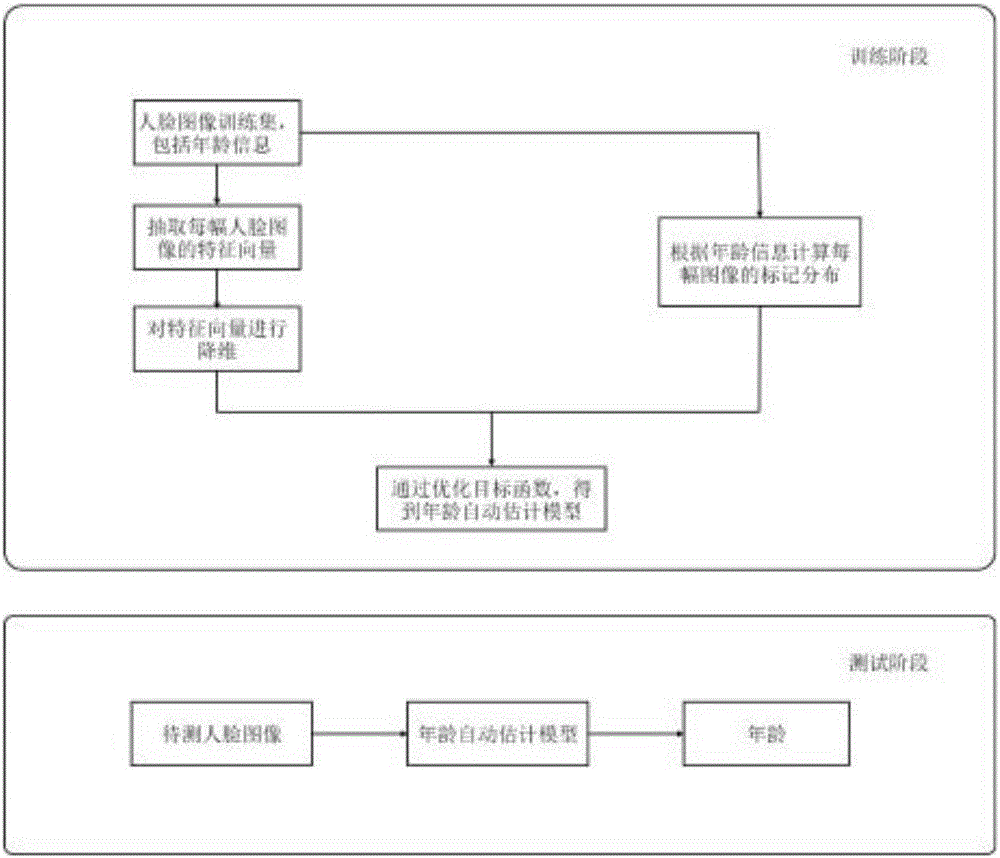
本发明属于模式识别和机器学习技术,具体涉及一种基于标记分布的解决类别缺失问题的人类年龄自动估计方法。
背景技术:
:基于人脸图像的自动年龄估计的应用日趋广泛,主要包括以下几个方面:(1)基于年龄的人机交互系统:与普通的人机交互系统不同的是,通过加入年龄信息,针对不同年龄段的用户采取不同的交互界面或交互方式,保证不同年龄的用户可以更方便的使用人机交互系统;(2)基于年龄的刑事侦查:根据监控设备拍下的犯罪嫌疑人的人脸图像来判断嫌疑人的大概年龄,从而缩小排查范围;(3)基于年龄的访问控制系统:在自动售货机上安装该系统,可以阻止未成年人购买烟酒等产品,并且也可以防止未成年人进入不适宜的场合。由以上可见,人脸图像的自动年龄估计在实际生活中有着巨大的作用,扮演者重要的角色。人脸年龄估计的主要困难之一是现存的人脸数据库在许多年龄上缺少充足的训练数据(人脸图像),比如在老年人以及婴儿这些年龄段,人脸数据库中的人脸图像比少年和青壮年这些年龄段要少很多,并且目前的年龄估计算法又不能充分利用这些数据。在极端情况下,有些年龄的人脸图像非常的难收集,造成在这种情况下该年龄没有人脸图像,形成一种典型的类别缺失问题。以往对于类别缺失问题,往往采用一些辅助信息,比如属性或者语义信息。但是在人脸年龄信息中,并没有合适的辅助信息,只能利用已有的人脸年龄图像来进行建模。而一些现有人脸年龄估计方法并不能很好的直接应用在类别缺失问题上,使用还是有缺陷。技术实现要素:发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于标记分布的解决类别缺失问题的人类年龄自动估计方法。技术方案:本发明的一种基于标记分布的解决类别缺失问题的人类年龄自动估计方法,依次包括以下步骤:(1)获取用于训练的人脸年龄图像数据集,该数据集中缺少某些年龄的样本(这些年龄是随机产生的,比如一个数据集中没有1岁到15岁的年龄,或者别的数据集中没有60岁到75岁的年龄),对该类别缺失数据集中的人脸图像抽取人脸图像特征向量(例如可以采用基于生物启发的方法,例如可以得到4376维特征向量);(2)对已经抽取出的人脸年龄图像特征向量进行降维,使特征向量的维度降低,作为最终的人脸图像特征向量,例如可以采用MFA算法进行降维,选择最终200维特征向量;(3)收集每幅图像对应的类别信息(即年龄信息),根据每幅图像的类别信息以及类别之间的关系(人类年龄之间有很大的相关性,比如同一个人25岁的人脸图像与26岁的人脸图像非常的相似),给予每幅图像一个标记分布,该标记分布用向量表示,将该标记分布向量作为训练中所需的图像的类别信息;(4)使用人脸图像特征向量及其标记分布作为训练集,求解最大熵模型生成的标记分布与真实年龄生成的标记分布的Jeffrey散度,使Jeffrey散度最小,并加入平滑正则项作为目标函数,对该目标函数进行优化,训练得到可以用于人类年龄自动估计的参数模型,该参数模型可以生成标记分布向量,即预测的年龄分布;(5)将待测人脸图像经过步骤(1)提取出图像的特征向量,并经过步骤(2)进行降维,接着使用步骤(4)中训练出来的参数模型计算得到一个年龄,所述年龄分布表示各个年龄对该图像的描述度,将年龄分布与对应的年龄相乘后相加,之后再将所得的结果取整作为待测人脸图像的年龄输出。进一步的,所述步骤(4)的具体过程为:使用最大熵模型作为人类年龄估计的参数模型;然后在目标函数中加入平滑正则项使预测出的标记分布更加平滑,同时通过平滑正则项来加强对缺失类别的学习;使用l-bfgs方法对目标函数进行优化,通过优化目标函数得到最优的参数。进一步的,所述步骤(5)中,进行人脸年龄估计时,先计算出年龄分布,然后将年龄分布与对应的年龄相乘后相加,最后再将所得的结果取整作为待测人脸图像的年龄输出计算。有益效果:本发明使用标记分布方法,利用类别之间的相关性来进行学习,能够快速、有效地训练出用于人脸年龄自动估计的模型,利用该方法可以对新类别的人脸图像进行头部姿态估计,并且不需要额外的辅助信息。附图说明图1为本发明的流程图;图2为本发明中标记分布的示例图;图3为实施例中Moprh数据集中某个样本的标记分布示例图。具体实施方式下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。如图1所示,本发明的一种基于标记分布的解决类别缺失问题的人类年龄自动估计方法,依次包括以下步骤:(1)获取用于训练的人脸年龄图像数据集,该数据集中缺少某些年龄的样本,然后对该类别缺失数据集中的人脸图像抽取人脸图像特征向量;(2)对步骤(1)中已经抽取出的特征向量进行降维,作为最终的人脸图像特征向量;(3)收集每幅图像对应的类别信息,根据每幅图像的类别信息以及类别之间的关系,给予每幅图像一个标记分布Y,如图2所示;在该步骤中,由于标记分布要满足分布中每个元素大于0以及总体和为1,因此采用高斯离散分布公式来生成标记分布;用y表示每个样本图像的年龄,标记分布采取均值为y,标准差为3的高斯分布,Y生成公式为Z为归一化因子,即它保证标记分布的和为1,Yi表示标记分布向量中的第i个元素。ai表示标记分布向量中的第i个元素对应的年龄,且i的取值范围为人脸年龄图像数据集中年龄的个数。(4)使用图像特征向量及其类别分布作为训练集,将最大熵模型与真实标记分布的Jeffrey散度以及平滑正则项结合起来作为目标函数,使用l-bfgs算法优化该目标函数,得到可以用于头部姿态估计的参数模型;该步骤中,目标函数可以表示为Jeffrey()表示Jeffrey散度,用来衡量两个分布的相似程度,计算公式如下Pi与Qi表示分布P与Q中的第i个元素,公式(2)中Yki表示第k个图像对应的标记分布向量中的第i个元素,Eki表示最大熵模型对第k个图像估计出的标记分布向量中的第i个元素值,最大熵模型的公式为其中,K表示人脸年龄图像数据集的某一个图像,如果数据集中有5万张图像,么K的取值就是1-50000;θid表示步骤(4)中待优化的模型参数矩阵θ的第i行第d列所对应的元素,Qkd表示第k个图像特征向量中的第d个元素,D表示步骤(2)中降维后的特征向量的维度;θm和θn表示第m个年龄对应的参数向量和第n个年龄对应的参数向量,并且第m个年龄与第n个年龄之间相差1,即|m-n|≤1,λ1为平衡Jeffrey散度与平滑正则项之间的权重;表示二范式的平方。(5)将待测人类年龄图像经过步骤(1)提取出图像的特征向量,经过步骤(2)进行降维,接着使用步骤(4)中训练出来的参数模型,根据公式(4)计算得到一个年龄分布向量A,表示各个年龄对该图像的描述度,将年龄分布与对应的年龄相乘后相加,之后再将所得的结果取整作为待测人脸图像的年龄输出。具体公式为age=∑iai*Ai(5)Ai为标记分布向量A中的第i个元素,ai为第i个元素对应的年龄。实施例1:为了证明本发明的实施效果,接下来以Morph人脸数据集为例说明。该数据集包含55132张人脸图像,涉及到的人脸年龄总共60个,头部姿态在两个自由度上变化。随机取数据集中的11026(20%)作为测试集,在剩下的44106(80%)幅图像中,选取特定的类别,将这些类别的样本剔除,剩下的图像作为训练集。因为是随机划分的数据,测试集中某些样本的类别在训练集中并没有出现,因此是类别缺失问题。本方法将使用基于标记分布的人类年龄自动估计方法进行训练。具体实现步骤如下:步骤S1,获取用于训练的类别缺失的人脸年龄的图像集,然后抽取人脸图像特征向量并降维;步骤S2,对已经抽取出的特征向量进行降维,作为最终的人脸图像特征向量;步骤S3,收集每幅图像对应的类别信息,根据每幅图像的类别信息以及类别之间的关系,给予每幅图像一个标记分布。图3示例了在Morph数据集中的某个年龄的标记分布;步骤S4,使用图像特征向量及其标记分布作为训练集,将最大熵模型与真实标记分布的Jeffrey散度以及平滑正则项作为目标函数,使用l-bfgs算法优化该目标函数,得到可以用于头部姿态估计的参数模型;步骤S5,将测试集中的图像经过步骤S1提取出图像的特征向量,经过步骤S2进行降维,接着使用步骤S4中训练出来的参数模型计算得到一个表示各个年龄对该图像描述度的分布,将年龄分布与对应的年龄相乘后相加,之后再将所得的结果取整作为待测人脸图像的年龄输出。如表1所示,此处对人脸年龄自动估计的平均绝对误差进行统计,统计结果表明本发明中的方法优于其他对比方法。平均绝对误差指的是测试集中预测年龄与真实年龄的插值的绝对值的平均,该评价指标越小,说明算法准确性越好。如下表所示。实验采用五倍交叉验证,在60个年龄中随机挑选12个年龄,在训练集中剔除这些年龄的样本。表1本发明与现有技术的平均绝对误差对比算法平均绝对误差标记分布学习4.0441±0.0412AAS4.4866±0.0502WAS9.2023±0.0802Cart5.6996±0.0490OHRank5.6454±0.0235KPLS4.3971±0.0276KSVR8.5372±0.0447当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1