一种基于信息粒度最优分配的钢铁工业高炉煤气长期区间预测方法与流程
本发明属于信息技术领域,涉及到粒度计算、动态时间弯曲、模糊系统建模等技术,是一种基于信息粒度最优化的钢铁工业高炉煤气长期区间预测方法。
背景技术:
冶金工业是一个高耗能高排放行业。除氧气、氮气等一次能源外,如何合理利用随钢铁生产过程所产生的副产煤气,亦即二次能源,是目前行业关注的重点。高炉煤气是钢铁生产过程的重要二次能源之一,它随高炉炼铁过程产生,广泛用于热风炉燃烧、焦炉炼焦和低压锅炉等环节。在日常生产中,高炉煤气发生量、热风炉高炉煤气用量等均为现场调度人员的关注重点,对上述产消用户未来趋势的判断,将直接影响到能源调度与优化排产的工作效率,以及企业的能耗成本等。(Guo,Z.C.,Fu,Z.X.(2010).Current situation of energy consumption and measures taken for energy saving in the iron and steel industry in China.Energy,35(11),4356-4360.)。
随着冶金企业信息化水平不断提高,数据驱动方法逐渐成为解决此类能源预测问题的有效途径。目前的应用模式主要基于迭代机制构建数据样本,进而采用诸如神经网络、支持向量机等模型进行数据样本训练和趋势预测(Sheng,C.,Zhao,J.,Wang,W.,Leung,H.(2013).Prediction intervals for a noisy nonlinear time series based on a bootstrapping reservoir computing network ensemble.IEEE Transactions on neural networks and learning systems,24(7),1036-1048.)(Z.Y.Han,Y.Liu,J.Zhao,W.Wang.(2012).Real time prediction for converter gas tank levels based on multi-output least square support vector regressor.Control Engineering Practice,20(12),1400-1409)。然而,这些方法的预测结果精度易收到迭代误差的影响,一般只能提供约30分钟的准确预测结果,对后续能源优化排产工作的指导意义较为有限。
在预测方法的研究上,粒度计算结合模糊系统建模的方式由于避免了迭代过程,已取得一定成果(Dong,R.,Pedrycz,W.(2008).A granular time series approach to long-term forecasting and trend forecasting.Physica A:Statistical Mechanics and its Applications,387(13),3253-3270.)。然而,这一模型在冶金工业应用上仍存在如下不足:首先,对数据的基本微粒划分仅依据简单的上升、下降等趋势,如此方式在面对波动剧烈的工业数据时难以适用,且忽视了数据变化与产品生产之间的关系;其次,现有研究成果一般是点预测,结果较为绝对,而以区间形式预估未来能源产消情况更符合人的认知习惯,且可直观给出结果的可靠性衡量,有助于提升其实用性。
技术实现要素:
本发明主要解决钢铁工业高炉煤气的长期区间预测问题。发明中所用数据为工业现场的真实数据,首先以能源产消的阶段性特征划分数据,形成基础数据微粒,进而借助时间弯曲距离将长度不等的数据微粒规范为等长,在模糊聚类后将聚类中心纵向延展为区间值,并以信息粒度最优分配为指导对其进行优化,最终获得长期区间预测结果。
为了达到上述目的,本发明的技术方案为:
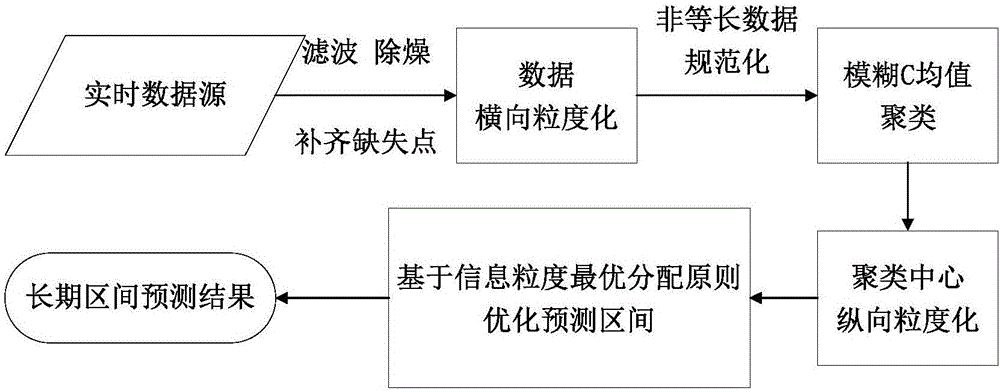
一种基于信息粒度最优分配的钢铁工业高炉煤气长期区间预测方法,该钢铁工业高炉煤气长期区间预测方法基于真实工业生产数据,在数据进行必要的预处理后,首先在横向即时间轴上,依据钢铁工业能源产消的阶段性特征,形成包括多个数据点的数据微粒;进而,考虑到后续模糊聚类分析需要,利用时间弯曲距离,将非等长数据微粒规范化为等长;在应用模糊聚类得到聚类中心后,将其在纵向上延展为区间值,借助模糊建模方法可获得初始区间预测结果;最终,求解基于信息粒度最优化分配理论的优化模型,获得长期区间预测结果。这种长期区间预测结果更具参考性,可更好地辅助指导现场能源调度工作,在钢铁工业其它能源介质系统中亦可推广应用。
本发明的具体步骤如下:
第一步,由钢铁工业现场能源系统的实时数据库中采集高炉煤气产消用户数据,并对这些原始数据做基本的除噪、滤波及填补等处理,为后续建模过程保证基础数据质量;
第二步,分析能源产消数据,例如高炉煤气回收、热风炉用高炉煤气等,对应生产阶段将多个数据点聚合为数据微粒,形成基本分析单元;
第三步,基于时间弯曲距离,在非等长数据微粒中选取基准序列,进而对其它数据微粒进行伸长或压缩,以达到统一数据长度的目的;
第四步,应用模糊C均值聚类算法,将所获得的聚类中心纵向延伸为区间数,利用模糊推理、解模糊化等模糊建模方法,获得初始区间预测结果;
第五步,以信息粒度最优分配为目标,针对预测区间建立优化模型,借助智能算法求得最终长期区间预测结果。
本发明方法在横轴、纵轴两个方向上实现了信息粒度的拓展。其中,横向上对应能源产消阶段将数据点聚合为数据微粒,为长期预测奠定基础;纵向上将聚类中心延伸为区间数,结合信息粒度最优分配进行优化;通过以上两部分工作最终获得长期区间预测结果。此外,时间弯曲距离的运用,解决了非等长数据微粒的等长规范化问题。准确的长期区间预测结果可为现场能源调度工作提供有力支持。
附图说明
图1为高炉煤气系统管网示意图。
图2为本发明应用流程图。
图3为热风炉高炉煤气用量数据横向粒度化举例示意图。
图4为热风炉高炉煤气用量数据聚类中心纵向粒度化举例示意图。
图5(a)为Delta方法对热风炉高炉煤气用量的长期区间预测结果图。
图5(b)为MVE方法对热风炉高炉煤气用量的长期区间预测结果图。
图5(c)为本发明方法对热风炉高炉煤气用量的长期区间预测结果图。
图6(a)为Delta方法对高炉煤气发生量的长期区间预测结果图。
图6(b)为MVE方法对高炉煤气发生量的长期区间预测结果图。
图6(c)为本发明方法对高炉煤气发生量的长期区间预测结果图。
图中:MVE是指均值方差估计(Mean Variance Estimation)。
具体实施方式
为了更好地理解本发明的技术方案与具体实施方式,下面以国内钢铁工业信息化水平较高的宝山钢铁厂高炉煤气系统为例做进一步说明。由图1所示的宝钢高炉煤气管网示意图可以看出,该系统中含有四座转炉作为发生单元,热风炉等则构成了消耗单元,低压锅炉、电厂等是该管网的可调节单元,两个煤气柜连接在管网末端存储多余煤气,为管网平衡起缓冲作用,此外还有煤气混合站、煤气加压站等作为输配系统。由于管网实际配置复杂,铺设线路较长,遍布厂区各个生产区域,同时高炉煤气管网又存在非线性、大时滞等特点,因此准确有效的机理建模显得尤为困难。鉴于此,本发明从数据驱动方法角度出发,解决相关能源预测问题。本发明的具体实施步骤如下:
步骤1:数据预处理
从钢铁工业现场实时关系数据库读取高炉煤气系统产消量数据。考虑到工业数据普遍存在有异常点、噪声、少量缺失点等问题,在建立模型之前对数据做基本的滤波、除噪和填补等处理。所述的流量数据主要包括高炉煤气发生量、热风炉高炉煤气用量、焦炉高炉煤气用量、冷/热轧高炉煤气用量等。
步骤2:横向的数据粒度化
冶金能源数据的波动一般对应产品生产阶段,含有一定实际意义,例如本发明所面向的高炉煤气管网中热风炉用高炉煤气量的休风送风状态切换,以及焦炉煤气管网自身用焦炉煤气量的切换等。应在建模中充分考虑此类生产过程特征,并依此对数据进行划分。
以下以预测对象之一的热风炉高炉煤气用量为例,说明其划分原则。图3是宝钢某热风炉高炉煤气用量3个小时的数据,由图可知,热风炉的一个工作阶段往往包含两部分,即正常燃烧阶段(幅值>200km3/h,持续时间约30分钟)和停止状态阶段(幅值<150km3/h,持续时间约15分钟)。由于该数据存在波形、时长不同的频繁波动,因此单纯的升降趋势形容显然不够适用。本发明在横向即时间轴上,按照一个完整生产阶段,将所对应的多个数据点记为一个数据粒子,如图3中虚线所示。
依据钢铁工业流量数据波动普遍对应产品生产阶段这一特性,对第一步得到的流量数据进行划分,即通过上述数据粒度化过程,可获得基础数据粒子t1,t2,……,tN,其中N为粒子个数,各粒子长度不同。这种方式首先在基本分析单元上保证了与实际生产的紧密联系,有助于提高预测精度;其次,此举对分析尺度的拓展,可为长期预测的实现奠定基础。
步骤3:非等长数据微粒规范化
首先通过各微粒间的时间弯曲距离动态计算,选择一个数据微粒作为基准序列;随后将其它序列与基准序列做比较,进行伸长或缩短,达到使各序列长度相同的目的。非等长数据微粒规范化的具体实施可通过以下两步完成:
3.1)基准序列选取:对于N个数据微粒t1,t2,……,tN,分别取其中一个与其它微粒计算时间弯曲距离和,并记录相应弯曲路径;在所得结果中,选取一个数据微粒作为基准序列ts,此序列满足即时间弯曲距离和取得最小值所对应序列;其中,DTW(ti,tj)为时间弯曲距离,arg Min表示取最小值时对应的ti;基准序列的长度记为n;
3.2)数据微粒规范化:根据上一步已获得的待规范序列与基准序列的弯曲路径结果,将待规范序列在弯曲部分进行自我复制或缩减(即以数据点平均值代替),实现伸长或压缩,使多段非等长的待规范序列等距化,所得的等长序列记做s1,s2,……,sN;
步骤4:纵向的聚类中心粒度化
对规范后的等长数据微粒s1,s2,……,sN,采用模糊C均值聚类方法,获得聚类中心和相应模糊隶属度,分别记做vij和uik,其中i=1,2,……,c,j=1,2,……,n,k=1,2,……,N。
考虑到最终预测结果形式的根本决定因素是聚类中心这一变量,本发明对其在纵向进行延展,形成区间数,即:
其中,εj称为信息粒度值。和分别是聚类中心区间的上下界。
相应模糊隶属度为:
其中,i=1,2,……,c,或或是聚类中心区间上下界和组成的列向量,m为模糊系数。基于这些区间化的聚类中心和模糊隶属度,可针对上下界分别进行模糊推理,即:
其中,nI为规则输入维数;t=1,2,……,N;和代表数据微粒的上下界;和均为数据微粒的聚类标识变量,例如当s(t-nI)-对第7个聚类的模糊隶属度最大时,则变量值取做7。对所有数据微粒进行模糊推理,即可获得由(N-nI)条规则组成的模糊规则库。提取各最大模糊隶属度对应聚类,在模糊规则库中寻找标识一致规则,记输出模糊隶属度最大值和对应位置为列向量和计算如下变量:
其中,i=1,2,……,c,再采用中心解模糊化方法可得到初始的长期预测区间:
其中,和是预测区间的上下界,V-、V+分别是聚类中心区间上下界所组成的矩阵。
步骤5:基于信息粒度最优分配的长期预测区间优化
对初始所得长期预测区间的优化之关键即是对信息粒度,即εj的优化。在公式(5)所得结果基础上,以信息粒度εj最优分配为目标,建立优化问题如下:
其中,sij(i=1,2,…,N,j=1,2,…,n)为测试样本点;card{}表示集合的势,即集合中元素的个数;等式约束的目的是将信息粒度的平均值限定为一给定值ε0;
对于上述优化问题的求解,本文选取粒子群优化算法作为求解算法。适应度函数则取测试样本下的区间覆盖率,即:
min n-card{sij∈[s-TV-,s+TV+]} (8)
其中,n为测试样本长度,亦即预测长度。优化求解过程需反复应用公式(1)(2)(3)(4)(5)。最终,求得最优化的信息粒度εj,及相应的长期区间预测结果
由以上过程可以看出,本发明方法分别在横向、纵向上实现了信息粒度化,并通过对信息粒度分配的最优值求取,获得最终长期区间预测结果。
图5、图6分别是针对某热风炉高炉煤气使用量、某高炉煤气发生量的长期区间预测结果,其中(a)为Delta方法,(b)为Mean Variance Estimation(MVE)方法,(c)则是本发明方法。带点线为真实值,灰色带状区域为预测区间。预测结果比较可参见表1,其中PICP(Prediction Interval Coverage Probability)为预测区间覆盖率,MPIW(Mean Prediction Interval Width)为预测区间平均宽度,CT为计算时间。
其中,ntest为测试样本点个数;当测试点含在预测区间中时ci值为1,否则为0;UBi和LBi分别是预测区间的上下限。图5、图6及表1的结果直观地表明了这种方法在预测精度、计算效率上优于一些工业应用的数据驱动方法。
表1三种方法预测结果比较
- 还没有人留言评论。精彩留言会获得点赞!