基于萤火虫算法和动态优先级的云工作流调度方法与流程
本发明属于云工作流调度技术领域,在调度时综合考虑了时间、费用和可靠性三个重要QoS因素。针对时间和可靠性双重约束下费用最小化的云工作流调度问题,提出了基于萤火虫算法和动态优先级的最优调度方案。
背景技术:
近年来,随着云计算技术的迅猛发展,越来越多的组织将传统的业务过程与应用迁移到云计算环境。云工作流调度指的是将相互之间具有依赖关系的工作流任务映射到虚拟机资源上执行的过程,它决定了工作流实例执行的成败和执行效率的高低。一般说来,云工作流调度问题是一个NP-hard问题,对于用户给定的工作流实例,调度过程存在着较大的改进和优化空间。
目前国内外学者在工作流优化调度方面做了许多有价值的研究工作。一是研究如何优化工作流完成时间。例如,针对单工作流应用,HEFT算法是一种针对异构资源的工作流调度经典算法。该算法根据任务的平均执行时间和通信时间计算出一个优先级,在任务分配时,选择具有最大优先级的任务并将其调度到完成时间最小的计算节点上。二是研究如何在截止时间约束下优化工作流费用。例如,ByuByun等人针对云计算环境提出了PBTS算法,该算法将工作流截止期划分为多个时间段,并利用BTS算法为每个时间段计算工作流需要的最少资源量,但该算法针对的是同构资源模型。
现有的工作流调度算法主要从时间和费用两方面进行研究,但这些算法都没有考虑可靠性,均假设任务执行过程和数据传输过程是没有中断、不会失败的,但在实际系统中,资源和网络的不可用都会对工作流的执行造成负面影响。
技术实现要素:
本发明针对现有技术的不足,提出了一种基于萤火虫算法和动态优先级的多QoS云工作流调度方法。该方法在云工作流调度时综合考虑了时间、费用和可靠性三个重要QoS因素。特别地,本发明结合云工作流调度问题的特点,重新定义了萤火虫算法中的位置、距离以及位置更新方式,同时对于每一种调度方案,采取动态优先级算法确定任务顺序,以减少工作流完成时间。
本发明方法的具体步骤是:
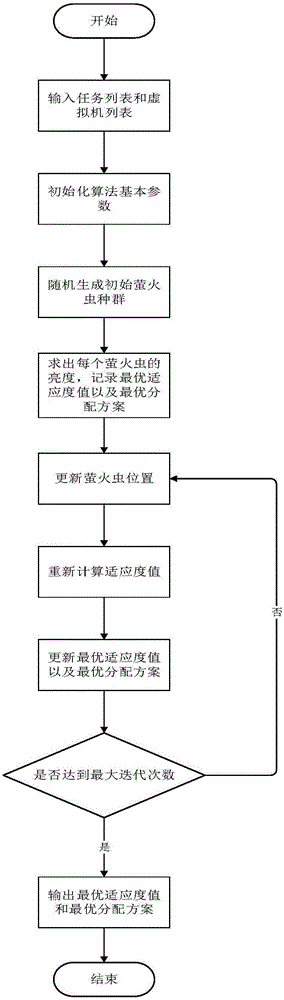
步骤(1).输入任务列表和虚拟机列表;其中任务列表包含了目标工作流中的所有待执行任务;虚拟机列表包含了云服务提供商提供的用来执行工作流任务的虚拟机资源;
步骤(2).初始化萤火虫算法的基本参数,设置萤火虫的数目v、光吸收系数γ、最大迭代数itMax、步长因子α;
步骤(3).随机生成初始萤火虫种群的位置,每个萤火虫的位置都代表了一种调度方案,即任务和虚拟机的映射关系;
假设萤火虫的个数为c,工作流中任务的个数为N,可用来进行调度的虚拟机个数为M,则第i个萤火虫的位置可用一个N维的向量xi=(xi,1,xi,2,...,xi,q,...,xi,N)表示,其中xi,q∈(1,2,...,M);一个萤火虫的位置向量代表一种可行的调度方案,该位置向量中的每一个元素都代表工作流中的一个任务由哪个虚拟机调度执行;
步骤(4).对每个萤火虫位置采用动态优先级调度算法来确定任务的执行顺序;之后求出每种调度方案的完成时间makespan、费用cost和可靠性reliablity,最终求得每种调度方案的适应度函数值作为萤火虫的亮度;设置最优适应度值bestFitness为初始萤火虫中最优适应度值、最优调度方案bestDop为相应的萤火虫位置;
对于某种调度方案S,其适应度函数f(S)定义如下:
其中,为了使费用单位化引入了min_cost变量,流程执行的费用必须小于这个值,MinRealiablity表示用户要求的最低可靠性,Deadline表示截止时间;
步骤(5).对每一个萤火虫i进行如下操作:若萤火虫i的周围有比其更亮的萤火虫,则该萤火虫向着比它亮的萤火虫移动,按照如下公式更新萤火虫移动之后的位置:
其中θ是0~1之间的随机数,βi,j表示比萤火虫i亮的萤火虫j对i的吸引度,由如下公式求得:
其中γ为光吸收系数,β0为最大吸引度,即在光源处的吸引度;rij表示两只萤火虫的距离,由如下公式求得:
其中l(·)是指示函数,当参数为真时,函数值为1,否则为0;
若周围没有比它更亮的萤火虫,此时该只萤火虫为最优萤火虫,如果对应的调度方案没有满足时间约束,则在最终完成时间最大的虚拟机上挑选出运行时间最短的任务,将它分配到最终完成时间最小的虚拟机上,优先满足时间约束;如满足了截止时间的情况下,则随机移动;
步骤(6).更新萤火虫位置后,重新计算适应度值,若适应度值大于bestFitness,则设置bestFitness为该适应度值,并更新最优调度方案bestDop;
步骤(7).重复步骤(5)、(6),直到迭代次数达到itMax;
步骤(8).输出此时的最优适应度值bestFitness以及最优调度方案bestDop。
本发明所提出的基于萤火虫算法和动态优先级的多QoS云工作流调度方法主要分为以下几个模块进行:工作流映射模块、虚拟机实例生成模块、工作流引擎模块、工作流调度模块。
工作流映射模块用于导入XML格式的流程定义文件(DAG)以及其他元数据文件,比如文件的大小。流程定义文件包括任务的描述、任务之间的依赖关系、执行任务所需的输入输出文件等。
虚拟机实例生成模块通过配置虚拟机的带宽、每秒处理的指令数(MIPS)、失败率、费用等参数生成处理工作流任务的虚拟机实例。
工作流引擎模块根据工作流任务之间的依赖关系来管理各个任务,以确保一个任务只有在其所有父任务都成功完成后才能得到释放。工作流引擎只会把空闲任务释放到调度器中。
工作流调度模块是整个调度过程中最核心的部分,该模块依据本发明提出的算法将任务分配到相应的工作节点上。
本发明提出的方法综合考虑了时间、费用和可靠性三个重要QoS因素。针对时间和可靠性双重约束下费用最小化的云工作流调度问题,提出了基于萤火虫算法和动态优先级的最优调度方案。特别地,本发明结合云工作流调度问题的特点对标准萤火虫算法进行了改进,重新定义了萤火虫算法中的位置、距离以及位置更新方式,提出了适用于云工作流调度问题的萤火虫算法。同时对于每一种调度方案,采取动态优先级算法确定任务顺序,以减少工作流完成时间。通过在WorkflowSim平台上进行模拟调度仿真实验,证明了该方法在收敛速度和最优值方面均优于传统云工作流调度算法。
附图说明
图1算法流程图;
具体实施方式
本发明提出的方法可以应用在如下场景:假设存在若干个相互之间具有依赖关系的工作流任务,以及用以执行这些工作流任务的若干虚拟机,如何将这些任务调度到相应的虚拟机上去执行使得工作流的执行效率达到最优。本发明提供的调度方法综合考虑了时间、费用和可靠性三个重要QoS因素,在满足时间和可靠性双重约束的前提下,使工作流的执行费用尽可能达到最小。
下面将对本发明所提供的基于萤火虫算法和动态优先级的最优调度方案做具体说明。
为叙述方便,定义相关符号如下:
ti:第i(i=1,2,...,N)个任务。
vmm:第m(m=1,2,...,M)个虚拟机。
表示虚拟机vmm的计算能力即每秒处理的指令数。
表示虚拟机vmm的失败率。
表示虚拟机的单位时间的租赁费用。
表示任务tj的完成时间。
数据从ti传输给tj的时间。
表示虚拟机执行完ti之前的任务空闲下来的时间。
表示任务ti的所有前驱任务都已经执行完毕并且将数据都传输到ti上的时间。
表示虚拟机与之间的带宽。
w(ti):任务ti的指令数。
虚拟机vmm上第一个被执行的任务。
虚拟机vmm上最后一个被执行的任务。
tf(vmm,vmn):表示虚拟机vmm与虚拟机vmn之间传输失败率。
Deadline:表示用户预先确定的工作流截止时间。
MinReliablity:表示用户要求的最低可靠性。
βi,j:表示萤火虫j对萤火虫i的吸引度。
β0:为最大吸引度,即在光源处的吸引度。
γ:为光吸收系数,一般取值0~1,其值越大,表明被空气介质吸收的荧光越多,被接收到的亮度越小吸引度越小。
rij:两只萤火虫之间的距离(即两种调度方案距离),距离越远,吸引度越小。
entityNum:表示每个任务的还有多少父任务未确定优先级。
idx:表示优先级(idx越小优先级越高)。
vmTaskList:表示每个虚拟机中的可执行任务列表。
步骤(1):输入任务列表和虚拟机列表。其中任务列表包含了目标工作流中的所有待执行任务,虚拟机列表包含了云服务提供商提供的用来执行工作流任务的虚拟机资源。
步骤(2):初始化萤火虫算法的基本参数,设置萤火虫的数目v、光吸收系数γ、最大迭代数itMax、步长因子α。
步骤(3):随机生成初始萤火虫种群的位置,每个萤火虫的位置都代表了一种调度方案,即任务和虚拟机的映射关系。
我们对传统萤火虫算法中的萤火虫位置进行重新编码,使得重新编码后的位置都代表了一种调度方案,即任务和虚拟机之间的映射关系。假设萤火虫的个数为c,工作流中任务的个数为N,可用来进行调度的虚拟机个数为M,则第i个萤火虫的位置可用一个N维的向量xi=(xi,1,xi,2,...,xi,q,...,xi,N)表示,其中xi,q∈(1,2,...,M);一个萤火虫的位置向量代表一种可行的调度方案,该位置向量中的每一个元素都代表工作流中的一个任务由哪个虚拟机调度执行。
步骤(4):对每个萤火虫位置采用动态优先级调度算法来确定任务的执行顺序。
动态优先级调度算法的具体执行过程如下:
1)将起始任务添加到对应的虚拟机可执行列表vmTaskList中,初始化entityNum为每个任务对应的父任务个数;
2)遍历每个虚拟机的可执行列表中,计算可执行任务的完成时间;
3)在所有可执行任务中,找到完成时间最早的任务ttask_sel;
4)为ttask_sel分配优先级,删除对应虚拟机中可执行任务列表中的该任务;
5)更新ttask_sel所有子任务在entityNum中的状态,如果变为可执行任务,则添加到对应虚拟机的可执行列表中;
6)重复步骤2)-5)直到每个虚拟机都没有可执行任务。
步骤(5):求出每种调度方案的完成时间makespan、费用cost和可靠性reliablity,最终求得每种调度方案的适应度函数值作为萤火虫的亮度。
1.完成时间
假设任务ti被分配到虚拟机上执行。由于受到工作流结构的约束,任务ti必须在其前驱任务执行完毕后将数据传输到任务ti所在的虚拟机上才可以执行。如果此时虚拟机上还有其他未完成的任务,则任务ti必须等待虚拟机其他任务执行完成才能开始执行,因此任务ti的开始时间可用如下公式计算:
任务ti的完成时间可用如下公式计算:
其中,任务ti在虚拟机上的执行时间通过如下公式计算:
从第一个任务开始到执行到最后一个任务的时间段称为整个工作流的完成时间,因而工作流的完成时间可用如下公式计算:
2.费用
对于单个虚拟机vmm的任务执行费用为:
整个工作流的费用等于所有虚拟机分费用之和,即:
3.可靠性
假设系统的调度方案可表示为S:T×R→{0,1},矩阵S代表了工作流中所有任务到所有虚拟机资源的一个有效映射,若其中的元素Si,m值为1,则表示任务ti被调度到虚拟机vmm上执行。由于虚拟机vmm在时间段t内的可靠性为则虚拟机vmm传输数据到虚拟机vmn在传输时间段t内的可靠性为在调度方案S中,虚拟机vmm上所有任务的执行时间为:
则虚拟机vmm的可靠性为:
同理可得数据在虚拟机vmm、vmn间的传输时间为:
则虚拟机vmm、vmn间传输可靠性为:
综上所述,可得整个工作流的可靠性即流程成功执行的可能性为:
4.适应度函数
为了能体现费用为目标、时间和可靠性为约束这一特点,现采用如下公式描述本方法研究的调度问题:
min cost
s.t.maskspan≤Deadline
reliability≥MinReliability
基于这种约束,对于某一种调度方案,定义其适应度函数如下公式所示:
步骤(6):在所有的调度方案中选出适应度值最优的,设置最优适应度值bestFitness的初始值为该萤火虫的适应度值、设置最优调度方案bestDop的初始值为该萤火虫的位置。
步骤(7):对每一个萤火虫i进行位置更新。在i的搜索范围内,找到所有比它亮的萤火虫放到集合中,其中ni表示集合中萤火虫个数,niti,j表示萤火虫编号。遍历集合Niti,萤火虫i被萤火虫niti,j吸引而向niti,j移动,1≤j≤ni。首先按照如下公式求出萤火虫niti,j对萤火虫i的吸引度:
其中l(·)是指示函数,当参数为真时,函数值为1,否则为0(即l(true)=1,l(false)=0)。
若萤火虫i的周围有比其更亮的萤火虫,则该萤火虫向着比它亮的萤火虫移动。假定比它亮的萤火虫为j,移动的时候是根据吸引度的大小来进行位置更新。按照如下公式对萤火虫的位置进行更新:
吸引度作为一个概率,用来决定xi是否从xj继承某个解维度。在判定前,我们随机得到0~1的取值θ,当吸引度大于θ时,则xi从xj处继承某个解维度的值,否则保留原始的值。如果周围没有比它更亮的萤火虫(Niti为空集),此时该只萤火虫为最优萤火虫,如果对应的调度方案没有满足时间约束,则在最终完成时间最大的虚拟机上挑选出运行时间最短的任务,将它分配到最终完成时间最小的虚拟机上,优先满足时间约束。如满足了截止时间的情况下,则随机移动。
步骤(8):更新萤火虫位置后,重新计算适应度值,若适应度值大于bestFitness,则设置bestFitness为该适应度值,并更新最优调度方案bestDop。
步骤(9):当前迭代次数it=it+1,如果it<itMax,则重复执行步骤(7)、步骤(8)。
步骤(10):当迭代次数达到itMax时,输出此时的最优适应度值bestFitness以及最优调度方案bestDop。
整个算法的执行过程如图1所示。
- 还没有人留言评论。精彩留言会获得点赞!