一种数据处理方法、装置及设备与流程
本发明涉及计算机技术领域,具体涉及一种数据处理方法、装置及设备。
背景技术:
随着网络中内容的爆炸式增长,如何基于用户的兴趣向用户推荐感兴趣的内容是一个亟待解决的问题。为了解决该问题,可以根据用户的反馈、点击阅读等用户行为,结合内容本身的标签属性,统计用户行为在各个标签上的分布,作为内容推荐的依据。然而在实践中发现,热门内容的大量展示和点击往往导致用户行为集中在一些热门标签上,无法突出用户的个性化兴趣,从而导致内容推荐的效率较低。
技术实现要素:
本发明实施例提供一种数据处理方法、装置及设备,能够突出用户的个性化兴趣,提高内容推荐的效率。
本发明实施例第一方面提供一种数据处理方法,包括:
根据用户在场景下的历史行为数据以及所述历史行为数据中每条信息的各标签的权重获取所述用户在每个标签上的累计权重;
计算所述用户在所述每个标签上的累计权重与所述用户在所有标签上的总累计权重之间的比值,作为所述用户在所述每个标签的累计权重分布;
根据所述用户在所述每个标签上的累计权重分布以及所述场景下所有用户在所述每个标签上对应的总累计权重分布,确定所述用户在所述每个标签上的兴趣权重;
利用所述每个标签以及所述每个标签上所述用户的兴趣权重生成所述场景下所述用户的兴趣分布向量。
可选的,针对场景集合中的每个场景,利用所述用户在所述场景下所述每个标签上的兴趣权重、所述用户在所述场景下在所有标签上的总累计权重以及所述用户在所述场景集合中所有场景下的总累计权重,确定所述用户在所述场景下在所述每个标签上的兴趣权重比例;
针对每个标签,计算所述用户在所述所有场景下在所述标签上的所述兴趣权重比例之和,作为所述用户在所述所有场景下在所述标签上的总兴趣权重;
利用所述每个标签以及所述用户在所述每个标签对应的所述总兴趣权重,生成所述用户在所述所有场景下的最终的兴趣分布向量。
可选的,根据用户在场景下历史行为数据中每条信息的特征,将所述每条信息量化为标签向量,所述标签向量包括所述每条信息具有的标签以及所述每个标签的权重。
可选的,所述根据用户在场景下的历史行为数据以及所述历史行为数据中每条行为信息的各标签的权重获取所述用户在每个标签上的累计权重,包括:针对用户在场景下的历史行为数据中的每条信息,计算所述每条信息的每个标签的权重与所述每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为所述每条信息的整体权重;计算所述用户的历史行为对应的所有信息的整体权重之和,作为所述用户在所述每个标签上的累计权重。
可选的,以预设周期获取用户在各场景下的历史行为数据。
相应的,本发明实施例第二方面还提供一种数据处理装置,,包括:
第一获取模块,用于根据用户在场景下的历史行为数据以及所述历史行为数据中每条信息的各标签的权重获取所述用户在每个标签上的累计权重;
计算模块,用于计算所述用户在所述每个标签上的累计权重与所述用户在所有标签上的总累计权重之间的比值,作为所述用户在所述每个标签的累计权重分布;
确定模块,用于根据所述用户在所述每个标签上的累计权重分布以及所述场景下所有用户在所述每个标签上对应的总累计权重分布,确定所述用户在所述每个标签上的兴趣权重;
生成模块,用于利用所述每个标签以及所述每个标签上所述用户的兴趣权重生成所述场景下所述用户的兴趣分布向量。
可选的,所述确定模块还用于:
针对场景集合中的每个场景,利用所述用户在所述场景下所述每个标签上的兴趣权重、所述用户在所述场景下在所有标签上的总累计权重以及所述用户在所述场景集合中所有场景下的总累计权重,确定所述用户在所述场景下在所述每个标签上的兴趣权重比例;
所述计算模块,还用于针对每个标签,计算所述用户在所述所有场景下在所述标签上的所述兴趣权重比例之和,作为所述用户在所述所有场景下在所述标签上的总兴趣权重;
所述生成模块,还用于利用所述每个标签以及所述用户在所述每个标签对应的所述总兴趣权重,生成所述用户在所述所有场景下的最终的兴趣分布向量。
可选的,量化模块,用于根据用户在场景下历史行为数据中每条信息的特征,将所述每条信息量化为标签向量,所述标签向量包括所述每条信息具有的标签以及所述每个标签的权重。
可选的,所述第一获取模块,具体用于:
针对用户在场景下的历史行为数据中的每条信息,计算所述每条信息的每个标签的权重与所述每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为所述每条信息的整体权重;
计算所述用户的历史行为对应的所有信息的整体权重之和,作为所述用户在所述每个标签上的累计权重。
可选的,第二获取模块,用于以预设周期获取用户在各场景下的历史行为数据。
本发明实施例第三方面还提供了一种数据处理设备,包括:处理器、存储器、通信接口和通信总线;
所述处理器、所述存储器和所述通信接口通过所述总线连接并完成相互间的通信;所述存储器存储可执行程序代码;所述处理器通过读取所述存储器中存储的可执行程序代码来运行与所述可执行程序代码对应的程序,以用于执行一种数据处理方法;其中,所述方法包括:
根据用户在场景下的历史行为数据以及所述历史行为数据中每条信息的各标签的权重获取所述用户在每个标签上的累计权重;
计算所述用户在所述每个标签上的累计权重与所述用户在所有标签上的总累计权重之间的比值,作为所述用户在所述每个标签的累计权重分布;
根据所述用户在所述每个标签上的累计权重分布以及所述场景下所有用户在所述每个标签上对应的总累计权重分布,确定所述用户在所述每个标签上的兴趣权重;
利用所述每个标签以及所述每个标签上所述用户的兴趣权重生成所述场景下所述用户的兴趣分布向量。
本发明实施例中,数据处理系统根据用户在场景下的历史行为数据以及该历史行为数据中每条信息的各标签的权重获取该用户在每个标签上的累计权重,可以确定该用户在每个标签上的兴趣权重,从而可以生成在该场景下该用户的兴趣分布向量,以突出用户的个性化兴趣,提高内容推荐的效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种数据处理方法的流程示意图;
图2是本发明实施例提供的一种数据处理方法的流程示意图;
图3是本发明实施例提供的一种数据处理方法的流程示意图;
图4是本发明实施例提供的一种数据处理装置的结构示意图;
图5是本发明实施例提供的一种数据处理装置的结构示意图;
图6是本发明实施例提供的一种数据处理设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在当前信息全球化的趋势下,一个全球化的产品要同时面对不同的用户群体,因此,需要一套统一的建模机制或者服务来对用户的历史行为数据进行处理获取用户的兴趣模型。然而,在实践中发现,不同场景下,例如,来自不同国家、地区、语种的用户,属于不同的用户群体,由于其文化背景、经济水平等社会因素的影响,其对所需新闻的需求有较大的差异,其接收的信息集合以及用户兴趣的分布也会有较大的差异。例如,一些发达国家可能更关注于金融、时尚,一些发展中国家可能更关注于紧急发展、社会、生活类的新闻,相应地,不同地区的群体也会偏好不同的体育项目;再例如,不同国家、地区、语种的用户看到的新闻集合也大有不同,对应的用户行为产生的标签分布也会有较大的差异;再例如,有些地区的用户属于多语种用户,其在不同语种下的兴趣标签集合需要进行整合,才能得到完整和统一的用户兴趣集合,为后续的新闻推荐或者产品推送提供完整、准确、全面的用户兴趣模型。又例如,用户在PC、手机等移动终端上多种应用上的操作均能反映用户的喜好,通过收集、汇总用户在不同应用上的行为,可以为用户兴趣建模提供更多的数据支持,有助于提升用户兴趣建模的完整和准确度。然而,不同应用产品上的人群,其看到内容以及对应得到反馈的标签整体分布也相应地会有明显的差异。例如,在浏览器、体育、游戏应用上投放的新闻或其他内容,得到反馈的内容的特征分布具有明显的差异,这两种应用上用户得出的不同标签的整体流行度。
综上所述,在对用户的历史行为数据进行处理的过程中,需要使用整体的内容及标签流行度作为偏差来辅助用户个性化兴趣建模。因此,本发明实施例中的数据处理方法可以考虑不同场景(包括但不限于国家、地区、语言、产品)下用户群体和新闻整体的区别。针对不同场景下的用户的历史行为数据,计算所有场景下的总累计权重分布作为计算相应用户的兴趣模型的偏差。即,本发明实施例可以将各个场景下推导出的用户兴趣进行整合,建立统一的用户兴趣特征模型,为后续的推荐任务、产品、新闻等信息提供完整统一的用户兴趣模型。本发明实施例中,通过考虑用户在不同场景下的参与度作为当前用户兴趣的置信度,通过线性加权融合用户在不同场景下的兴趣,得到当前用户的最终兴趣模型。
进一步的,本发明实施例可以对用户的兴趣模型采用周期性更新计算流程,每隔一个固定时间片对用户当前兴趣模型进行更新。由于新闻内容和对应的标签集合,以及用户兴趣随着时间会发生变化,该实施方式可以更加突出用户的近期行为,并及时反映用户短期兴趣的变化。对用户阅读过的新闻、信息或者使用的应用,根据其阅读或使用时间距离当前时间的时长,使用时间衰减法,设置用户的历史行为数据中每次阅读或使用行为对用户当前兴趣分布的重要程度。
以下对本发明实施例提供的数据处理方法、系统和设备进行详细介绍。
请参阅图1,图1为本发明实施例提供的一种数据处理方法的流程示意图,该数据处理方法可以由数据处理系统来执行,该数据处理系统可以设置在终端或者服务器中,本发明实施例不做限定。如图1所示,该数据处理方法可以包括以下步骤:
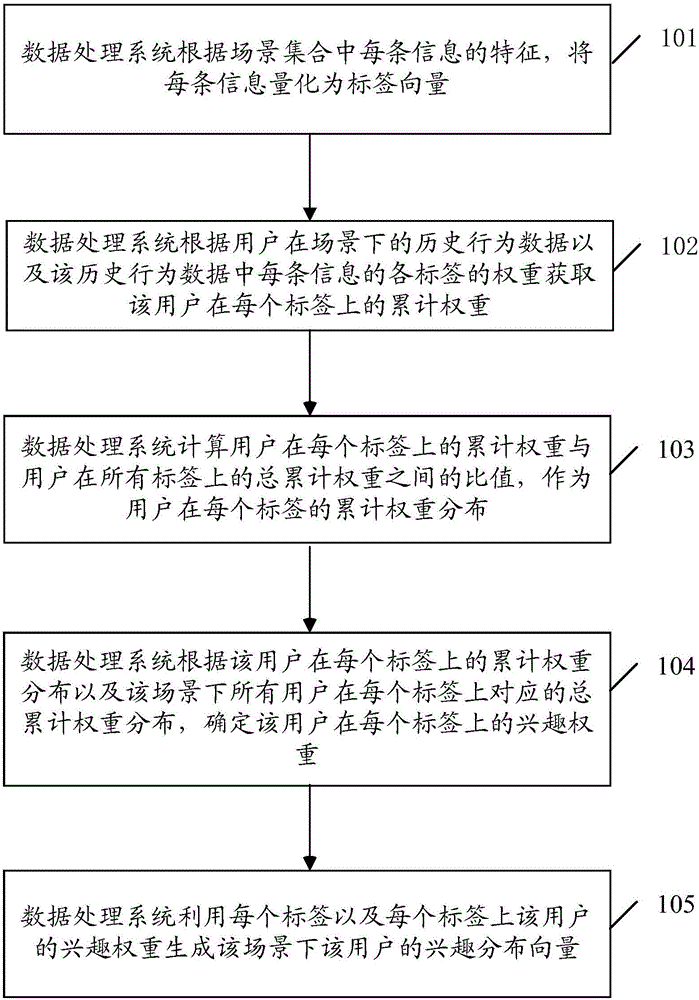
101、数据处理系统根据场景集合中每条信息的特征,将每条信息量化为标签向量。
本发明实施例中,标签向量包括每条信息具有的标签以及每个标签在该条信息中的权重。用户的兴趣通常使用标签化的特征集合来刻画描述,如用户对“娱乐”、“篮球”等标签偏好程度,即兴趣度。用tk表示一个标签,用户μ历史上阅读过的新闻集合记作C(μ)。对每个新闻Ci,其特征的标签表示为<(t1,wi1),(t2,wi2),…,(tn,win)>,其中wik表示标签tk在Ci中的重要程度。例如,针对新闻推荐,对用户阅读过的新闻上的标签进行本发明实施例所述的数据处理,就可以得到用户的历史行为数据在各个标签上的兴趣向量分布。
本发明实施例中,将用户所使用的各个应用,如游戏应用、购物应用、新闻类应用、浏览器应用等产品,以及国家、地区、语言等统称为不同的场景,相应地,该场景不限于上述内容;本发明实施例中,将用户阅读过的新闻、使用的应用等统称为信息,相应地,该信息可以包括但不限于上述内容。本发明实施例根据每条信息的特征可以将每条信息归纳出包括多个标签,例如,该信息为用户阅读过的新闻集合,则可以设置信息的标签为娱乐、社会、明星、犯罪、影视、政治、国际、科技、健康等,即每条信息可以对应多个标签。本发明实施例中,将标签在该条信息中的重要程度设置为标签的权重。
举例来说,用S表示包括各种场景的场景集合,s表示S中的一个特定场景,用户μ在场景s中的历史行为数据所对应的信息集合记作C(μ),每条信息记作Ci,每条信息包括的标签可以为n个,分别为t1,t2,…,tk,…,tn,wik表示标签tk在该条信息Ci中的重要程度,即标签tk的权重。因此,每条信息Ci所量化的标签向量为<(t1,wi1),(t2,wi2),…,(tk,wik),…,(tn,win)>。
102、数据处理系统根据用户在场景下的历史行为数据以及该历史行为数据中每条信息的各标签的权重获取该用户在每个标签上的累计权重。
本发明实施例中,数据处理系统可以根据用户在场景下的历史行为数据以及该历史行为数据中每条信息的标签向量获取用户在每个标签上的累计权重。
可选地,数据处理系统可以执行以下步骤来确定用户在标签上的累计权重:
针对用户在场景下的历史行为数据中的每条信息,计算所述每条信息的每个标签的权重与所述每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为所述每条信息的整体权重;计算所述用户的历史行为对应的所有信息的整体权重之和,作为所述用户在所述每个标签上的累计权重。
该实施方式可以根据用户对每条信息的阅读或使用时间距离当前时间的时长,使用时间衰减法来设置标签的权重,将标签的权重乘以衰减因子后的权重也可以称为标签在该条信息的整体权重,从而,使得数据处理系统获得的用户兴趣模型可以反映用户的历史行为数据中每次阅读或使用行为对用户当前兴趣模型的重要程度。
举例来说,计算信息Ci的标签tk的权重wik与该条信息Ci对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为该条信息的整体权重,具体为:计算用户μ的历史行为对应的所有信息(即信息集合C(μ))的整体权重之和,作为用户μ在标签tk上的累计权重具体为:
其中,衰减因子中,α为预设时间衰减参数(通常,0<α≤1),Ti为信息对应的历史行为产生时刻距离当前时刻的时长,也就是用户对每条信息的阅读或使用时间距离当前时间的时长。
103、数据处理系统计算该用户在每个标签上的累计权重与该用户在所有标签上的总累计权重之间的比值,作为该用户在每个标签的累计权重分布。
本发明实施例中,数据处理系统通过步骤103可以统计出用户在某个场景的标签分布,即用户的历史行为数据在每个标签的比例情况。
具体的,用户μ在标签tk上的累计权重为相应地,用户μ在场景s的所有标签t1,t2,…,tk,…,tn上的总累计权重为:相应地,用户μ在标签tk上的累计权重分布即为两者的比值:
104、数据处理系统根据该用户在每个标签上的累计权重分布以及该场景下所有用户在每个标签上对应的总累计权重分布,确定该用户在每个标签上的兴趣权重。
本发明实施例中,单个用户在单个标签上的累计权重分布如步骤103所示,例如,用户μ在标签tk上的累计权重分布为相应地,场景下所有用户在每个标签上对应的总累计权重分布即为:所有用户在该标签上对应的累计权重与所有用户在所有标签上对应的总累计权重之和之间的比值。
例如,场景s下所有用户在标签tk上对应的累计权重为:
场景s下所有用户在所有标签上对应的总累计权重为:
相应的,场景s下所有用户在标签tk上对应的总累计权重分布即为:
反映了场景s下用户群体在各标签上的总累计权重分布,从而,可以利用该总累计权重分布向量来衡量场景s下各标签的热门程度,即总累计权重分布越大的标签,越热门,其所对应的信息、新闻、应用等中该标签的权重越大,该信息、新闻、应用被用户群体受欢迎的程度越高。
相应地,步骤104中,用户在每个标签上的兴趣权重就可以根据上述的用户在每个标签上的累计权重分布以及所有用户在每个标签上的总累计权重分布来确定该用户在该标签上分布的差异,利用该差异即可表示用户在该标签上的兴趣度。具体的,用户μ在标签tk的累计权重分布与所有用户即用户群体在此标签tk上的总累计权重分布的差异为:
其中,平滑系数∈的大小,可根据过去的预测数与实际数比较而定。差额大,则平滑系数应取大一些;反之,则取小一些。平滑系数愈大,则近期倾向性变动影响愈大;反之,则近期的倾向性变动影响愈小,愈平滑。
该差异反映了用户在标签tk上的兴趣度与用户群体在该标签tk上的兴趣度的差异,因此可以利用该差异作为用户的兴趣权重,从而可以更加清楚的反映用户的在该标签上的个性化兴趣,相应的,多个标签的兴趣权重即可构成该用户在该场景的个性化的兴趣分布向量。
可选的,当用户在标签上的累计权重分布小于用户群体在标签上的总累计权重分布时,该差异为小于0的数值,也就是说该标签并不是用户感兴趣的标签,因此,为了更加直观的反映用户的兴趣分布向量,可去除小于0的兴趣权重,即用户μ在标签tk上的兴趣权重为:
用户在标签上的累计权重分布小于用户群体在标签上的总累计权重分布时,该差异为小于0的数值,从某种程度上说,该类标签是用户不感兴趣的标签,因此,可以利用小于0的兴趣权重对应的标签来去除掉向用户推送的内容中对应的部分内容,降低内容推送的错误率,即用户μ在标签tk上的不感兴趣权重为:
105、数据处理系统利用每个标签以及每个标签上用户的兴趣权重生成该场景下该用户的兴趣分布向量。
例如,场景s下用户μ的兴趣分布向量为:
可见,本发明实施例可以利用信息的标签向量与用户的兴趣分布向量之间的匹配度来确定是否将该信息推送给该用户,与传统的单纯利用用户的累计权重分布作为用户兴趣分布向量进行内容推荐的方法相比,该实施方式所构建的用户的兴趣分布向量可以更加突出用户兴趣中的“个性化”兴趣,即步骤104所示利用单个用户的累计权重分布与所有用户的累计权重分布之间的差异来确定用户在某个标签上的兴趣权重,可以提取用户的独特兴趣。例如,用户点击阅读热门事件的新闻,比如“奥运会”,与用户点击阅读冷门事件的新闻相比,其反映出用户对该类新闻对应的标签的兴趣程度是不同的,故本发明实施例所述的数据处理方法可以构建更加贴合用户真实兴趣的兴趣分布向量,从而,可以在某个场景下向用户推送更加感兴趣的内容,提高内容推送的准确率。
请参阅图2,图2为本发明实施例提供的一种数据处理方法的流程示意图,该数据处理方法可以由数据处理系统来执行,该数据处理系统可以设置在终端或者服务器中,本发明实施例不做限定。图2所示的数据处理方法与图1所示的数据处理方法相比,图2所示的数据处理方法可以整合多场景下用户的兴趣分布向量,获得用户在不同场景下整体的兴趣分布向量。具体的,具体的,图2所示的该数据处理方法还可以包括以下步骤:
106、数据处理系统针对场景集合中的每个场景,利用该用户在该场景下每个标签上的兴趣权重、该用户在该场景下在所有标签上的总累计权重以及该用户在所有场景下的总累计权重,确定该用户在该场景下在每个标签上的兴趣权重比例。
本发明实施例中,数据处理系统可以通过步骤105得到该用户μ在场景下该每个标签上的兴趣权重数据处理系统可以通过步骤103得到用户μ在场景s的所有标签t1,t2,…,tk,…,tn上的总累计权重相应的,数据处理系统可以根据得到用户μ在所有场景下的总累计权重Nμ,即其中,s∈S;相应的,该用户μ在场景s下在标签tk上的兴趣权重比例为:
举例来说,用户μ在场景s下在标签t1上的兴趣权重比例可以是在标签t2上的兴趣权重比例可以是
107、数据处理系统针对每个标签,计算该用户在所有场景下在该标签上的兴趣权重比例之和,作为该用户在所有场景下在该标签上的总兴趣权重。
本发明实施例中,该用户在该场景下在每个标签上的兴趣权重比例可以通过步骤106来获得,相应的,用户在所有场景下在每个标签上的总兴趣权重即为:该用户在所有场景下每个标签上的兴趣权重比例之和来作为该用户在在该标签上的总兴趣权重wμk,也就是针对所有场景的最终的兴趣权重。
例如,用户μ在场景s下在标签tk上的兴趣权重比例为那么就可以得到该用户在所有场景下在该标签tk上的总兴趣权重wμk:
108、数据处理系统利用每个标签以及用户在每个标签对应的总兴趣权重,生成该用户在所有场景下的最终的兴趣分布向量。
例如,用户μ在所有场景下的最终的兴趣分布向量可以为:
Preference(μ)=<wμ1,wμ2,…,wμn>
其中,系统可以将其用稀疏向量表示,用其更新用户当前兴趣模型。例如,wμ1为用户μ针对标签t1的总兴趣权重,即为用户μ对标签t1的兴趣度;wμ2为用户μ针对标签t2的总兴趣权重,即为用户μ对标签t2的兴趣度。
可见,图3所示的实施例中,数据处理系统不仅可以通过步骤101-105得到单个场景中用户的兴趣权重以及单场景下用户的兴趣分布向量,还可以由步骤106-108整合场景集合中各个场景下的兴趣权重,对各个场景下的兴趣分布向量中的兴趣权重进行线性加权,得到用户在所有场景下对各个标签的总兴趣权重,以得到所有场景中用户的最终的兴趣分布向量,可见,本发明实施例可以针对不同场景更加全面地计算出用户完整的兴趣分布,弥补了用户在跨场景时用户兴趣特征的缺失,也为后续的内容推荐提供完整、准确、全面的用户兴趣模型。
请参阅图3,图3为本发明实施例提供的一种数据处理方法的流程示意图,该数据处理方法可以由数据处理系统来执行,该数据处理系统可以设置在终端或者服务器中,本发明实施例不做限定。图3所示的数据处理方法与图2所示的数据处理方法相比,图3所示的数据处理方法可以通过周期性的获得用户在所有场景下的历史行为数据,并通过图2所示的各步骤确定用户在所有场景下的兴趣分布向量。具体的,图3所示的该数据处理方法可以包括图2所示的所有步骤,并且步骤102可以包括:步骤102a、步骤102b以及步骤102c,具体地:
102a、数据处理系统以预设周期获取用户在各场景下的历史行为数据。
本发明实施例中,数据处理系统可以预设在场景下对用户的兴趣分布向量的更新周期,以更新用户的兴趣模型。因此,数据处理系统可以以预设周期获取用户在各场景下的历史行为数据。其中,该预设周期可以是预设的更新周期。
需要说明的是,此处数据处理系统以预设周期获取的用户在各场景下的历史行为数据,可以是数据处理系统在每次更新了用户的兴趣模型后,清空之前的历史行为数据后记录新的关于该用户的历史行为数据,还可以是在场景下关于用户所有的历史行为数据,未进行相关清空操作,本发明实施例对其不做限制。
需要说明的是,数据处理系统可以根据用户针对场景集合中每个场景下的历史行为数据以及该历史行为数据中每条信息的各标签的权重获取该用户在每个标签上的累计权重。上述历史行为数据可以记录在用户在一个或多个场景下所执行的消息阅读操作的日志信息中。其中,该消息阅读操作的日志信息可以包括用户所阅读的消息内容、阅读时间、消息备注等,本发明实施例对此不做限制。通俗的来说,该日志信息可以是用户的历史阅读记录、历史阅读足迹或历史阅读足迹等。当然,用户可以通过点击、滑动等触控操作,在当前页面或者跳转页面来阅读相应消息。
本发明实施例中,在执行完步骤102a后,可以执行步骤102b。
102b、数据处理系统针对用户在场景下的历史行为数据中的每条信息,计算每条信息的每个标签的权重与每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为每条信息的整体权重。
102c、数据处理系统计算所述用户的历史行为对应的所有信息的整体权重之和,作为所述用户在所述每个标签上的累计权重。
本发明实施例中,对步骤102b以及步骤102c的具体描述可以参考实施例1中对步骤102的相关描述部分,此处将不再进行进一步的阐释。
可见,本发明实施例中,数据处理系统可以通过周期性的获取用户在各场景下的历史行为数据,以更新用户在该场景下的兴趣分布向量,若结合实施例2来看的话,数据处理系统还可以更新用户在多场景下的最终的兴趣分布向量,以便更新数据处理系统中关于该用户的兴趣模型,从而方便后续内容推荐相关的工作。
请参阅图4,图4为本发明实施例提供的一种数据处理装置的结构示意图,该数据处理装置可以应用于数据处理系统中,该数据处理系统可以设置在终端或者服务器中,本发明实施例不做限定。如图4所示,该数据处理装置可以包括:
第一获取模块401,用于根据用户在场景下的历史行为数据以及该历史行为数据中每条信息的各标签的权重获取该用户在每个标签上的累计权重。
本发明实施例中,第一获取模块401可以针对用户在场景下的历史行为数据中的每条信息,计算每条信息的每个标签的权重与每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为每条信息的整体权重;计算该用户的历史行为对应的所有信息的整体权重之和,作为该用户在每个标签上的累计权重。
计算模块402,用于计算该用户在每个标签上的累计权重与该用户在所有标签上的总累计权重之间的比值,作为该用户在每个标签的累计权重分布。
确定模块403,用于根据该用户在每个标签上的累计权重分布以及该场景下所有用户在每个标签上对应的总累计权重分布,确定该用户在每个标签上的兴趣权重。
生成模块404,用于利用每个标签以及每个标签上该用户的兴趣权重生成该场景下该用户的兴趣分布向量。
可见,图4所示的实施例中,数据处理系统可以利用信息的标签向量与用户的兴趣分布向量之间的匹配度来确定是否将该信息推送给该用户,与传统的单纯利用用户的累计权重分布作为用户兴趣分布向量进行内容推荐的方法相比,该实施方式所构建的用户的兴趣分布向量可以更加突出用户兴趣中的“个性化”兴趣,其中,数据处理系统利用单个用户的累计权重分布与所有用户的累计权重分布之间的差异来确定用户在某个标签上的兴趣权重,可以提取用户的独特兴趣。例如,用户点击阅读热门事件的新闻,比如“奥运会”,与用户点击阅读冷门事件的新闻相比,其反映出用户对该类新闻对应的标签的兴趣程度是不同的,故本发明实施例所述的数据处理方法可以构建更加贴合用户真实兴趣的兴趣分布向量,从而,可以在某个场景下向用户推送更加感兴趣的内容,提高内容推送的准确率。
请一并参阅图5,图5为本发明实施例提供的一种数据处理装置的结构示意图,该数据处理装置可以应用于数据处理系统中,该数据处理系统可以设置在终端或者服务器中,本发明实施例不做限定。图5是在图4的基础上优化得到的。其中,该数据处理装置包括第一获取模块401、计算模块402、确定模块403、生成模块404,还包括量化模块405、第二获取模块406,其中,该装置包括:
可选的,确定模块403,还用于针对场景集合中的每个场景,利用该用户在该场景下每个标签上的兴趣权重、该用户在该场景下在所有标签上的总累计权重以及该用户在该场景集合中所有场景下的总累计权重,确定该用户在该场景下在每个标签上的兴趣权重比例。
可选的,计算模块402,还用于针对每个标签,计算该用户在所有场景下在该标签上的兴趣权重比例之和,作为该用户在所有场景下在该标签上的总兴趣权重。
可选的,生成模块404,还用于利用每个标签以及该用户在每个标签对应的总兴趣权重,生成该用户在所有场景下的最终的兴趣分布向量。
本发明实施例中,确定模块403可以针对场景集合中的每个场景,确定该用户在该场景下在每个标签上的兴趣权重比例,并且可以由计算模块402得到该用户在所有场景下在该标签上的总兴趣权重,然后交由生成模块404生成该用户在所有场景下的最终的兴趣分布向量,以更加全面地计算出用户完整的兴趣分布,弥补了用户在跨场景时用户兴趣特征的缺失,也为后续的内容推荐提供完整、准确、全面的用户兴趣模型。
可选的,量化模块405,用于根据用户在场景下历史行为数据中每条信息的特征,将该每条信息量化为标签向量,该标签向量包括每条信息具有的标签以及每个标签的权重。
可选的,第二获取模块406,用于以预设周期获取用户在各场景下的历史行为数据。
可见,图5所示的实施例中,数据处理系统可以数据处理系统不仅可以得到单个场景中用户的兴趣权重以及单场景下用户的兴趣分布向量,还可以整合场景集合中各个场景下的兴趣权重,对各个场景下的兴趣分布向量中的兴趣权重进行线性加权,得到用户在所有场景下对各个标签的总兴趣权重,以得到所有场景中用户的最终的兴趣分布向量,可见,本发明实施例可以针对不同场景更加全面地计算出用户完整的兴趣分布,弥补了用户在跨场景时用户兴趣特征的缺失,也为后续的内容推荐提供完整、准确、全面的用户兴趣模型。并且,数据处理系统还可以通过周期性的获取用户在各场景下的历史行为数据,以更新用户在该场景下的兴趣分布向量,并且还可以更新用户在多场景下的最终的兴趣分布向量,以便更新数据处理系统中关于该用户的兴趣模型,从而方便后续内容推荐相关的工作。
请参阅图6,图6是本发明实施例提供的一种数据处理设备的结构示意图,如图所示,该数据处理设备可以包括:至少一个处理器601,例如CPU(Central Processing Unit,中央处理器),至少一个通信接口603,存储器604,至少一个通信总线602。其中,通信总线602用于实现这些组件之间的连接通信。其中,通信接口603可以包括显示屏(Display)、键盘(Keyboard),可选通信接口603还可以包括标准的有线接口、无线接口。存储器604可以是高速RAM存储器(Ramdom Access Memory,易挥发性随机存取存储器),也可以是非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器。存储器604可选的还可以是至少一个位于远离前述处理器601的存储装置。其中处理器601可以结合图4和5所描述的装置,存储器604中存储一组程序代码,且处理器601调用存储器604中存储的程序代码,以用于执行一种数据处理方法,即用于执行以下操作:
根据用户在场景下的历史行为数据以及所述历史行为数据中每条信息的各标签的权重获取所述用户在每个标签上的累计权重;
计算所述用户在所述每个标签上的累计权重与所述用户在所有标签上的总累计权重之间的比值,作为所述用户在所述每个标签的累计权重分布;
根据所述用户在所述每个标签上的累计权重分布以及所述场景下所有用户在所述每个标签上对应的总累计权重分布,确定所述用户在所述每个标签上的兴趣权重;
利用所述每个标签以及所述每个标签上所述用户的兴趣权重生成所述场景下所述用户的兴趣分布向量。
本发明实施例中,处理器601调用存储器604中的程序代码,还用于执行以下操作:
针对场景集合中的每个场景,利用所述用户在所述场景下所述每个标签上的兴趣权重、所述用户在所述场景下在所有标签上的总累计权重以及所述用户在所述场景集合中所有场景下的总累计权重,确定所述用户在所述场景下在所述每个标签上的兴趣权重比例;
针对每个标签,计算所述用户在所述所有场景下在所述标签上的所述兴趣权重比例之和,作为所述用户在所述所有场景下在所述标签上的总兴趣权重;
利用所述每个标签以及所述用户在所述每个标签对应的所述总兴趣权重,生成所述用户在所述所有场景下的最终的兴趣分布向量。
本发明实施例中,处理器601调用存储器604中的程序代码,根据用户在场景下的历史行为数据以及所述历史行为数据中每条信息的各标签的权重获取所述用户在每个标签上的累计权重之前,还用于执行以下操作:
根据用户在场景下历史行为数据中每条信息的特征,将所述每条信息量化为标签向量,所述标签向量包括所述每条信息具有的标签以及所述每个标签的权重。
本发明实施例中,处理器601调用存储器604中的程序代码,根据用户在场景下的历史行为数据以及所述历史行为数据中每条行为信息的各标签的权重获取所述用户在每个标签上的累计权重,可以执行以下操作:
针对用户在场景下的历史行为数据中的每条信息,计算所述每条信息的每个标签的权重与所述每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为所述每条信息的整体权重;
计算所述用户的历史行为对应的所有信息的整体权重之和,作为所述用户在所述每个标签上的累计权重。
本发明实施例中,处理器601调用存储器604中的程序代码,针对用户在场景下的历史行为数据中的每条信息,计算所述每条信息的每个标签的权重与所述每条信息对应的历史行为产生时刻距离当前时刻的衰减因子之间的乘积,作为所述每条信息的整体权重之前,还用于执行以下操作:
以预设周期获取用户在各场景下的历史行为数据。
其中,通信总线602可以是外设部件互连标准(peripheral component interconnect,简称PCI)总线或扩展工业标准结构(extended industry standard architecture,简称EISA)总线等。所述通信总线602可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
其中,存储器604可以包括易失性存储器(英文:volatile memory),例如随机存取存储器(英文:random-access memory,缩写:RAM);存储器也可以包括非易失性存储器(英文:non-volatile memory),例如快闪存储器(英文:flash memory),硬盘(英文:hard disk drive,缩写:HDD)或固态硬盘(英文:solid-state drive,缩写:SSD);存储器604还可以包括上述种类的存储器的组合。
其中,处理器601可以是中央处理器(英文:central processing unit,缩写:CPU),网络处理器(英文:network processor,缩写:NP)或者CPU和NP的组合。
其中,处理器601还可以进一步包括硬件芯片。上述硬件芯片可以是专用集成电路(英文:application-specific integrated circuit,缩写:ASIC),可编程逻辑器件(英文:programmable logic device,缩写:PLD)或其组合。上述PLD可以是复杂可编程逻辑器件(英文:complex programmable logic device,缩写:CPLD),现场可编程逻辑门阵列(英文:field-programmable gate array,缩写:FPGA),通用阵列逻辑(英文:generic array logic,缩写:GAL)或其任意组合。
可选地,所述存储器604还用于存储程序指令。所述处理器601可以调用所述程序指令,实现如本申请图1,2和3实施例中所示的数据处理方法。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!