一种高招大本数据采集系统及方法与流程
本发明涉及一种数据采集方法,更具体的,涉及一种高招大本数据采集系统及方法。
背景技术:
在普通高校的招生过程中,考生填报志愿不仅关系着能否被高校录取,更为重要的是:填志愿时选择专业、学校内在地规定了学生未来的学业及职业发展路线及发展状态。通常所说的考生志愿,指考生所选报的院校和专业,是考生的志向、愿望、爱好、个性和能力等因素的综合反映。而其中往年录取数据是考生在填报学校时的最重要的依据,这关系着考生是否能够考生该所学校。
通常情况下,各省都会派发对应的《高考填报指南》,其中就包含着该省往年的所有学校的录取数据。但这类书籍页数多,数据量大,考生在翻阅该书籍时难以快速准确捕获自己所需要的信息,因此将该类书籍数据电子化有其必要性。
目前主流的将书籍数据电子化的方式是人工录入,但这种方式耗费时间较长,且因有非常重的人工干预的成分,难以保证数据的准确性和完整性。从2016年开始,高招大本的书籍出版都很晚,将数据电子化需要在非常短的时间内完成,否则失去意义。所以全、准、快是录入高招大本数据的基本原则,显然人工录入的方式并不能达成这三项标准。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一。
为此,本发明的目的在于,提供一种快捷、流程化的数据采集方法处理高招大本数据,避免数据的缺失,保证其准确性,帮助考生便捷地查看往年录取数据。
为实现上述目的,本发明提供了一种一种高招大本数据采集方法,包括如下步骤:
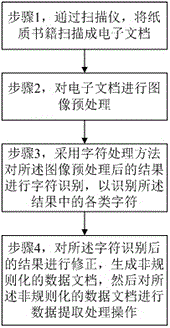
步骤1,通过扫描仪,将纸质书籍扫描成电子文档;
步骤2,对电子文档进行图像预处理;
步骤3,采用字符处理方法对所述图像预处理后的结果进行字符识别,以识别所述结果中的各类字符;
步骤4,对所述字符识别后的结果进行修正,生成非规则化的数据文档,然后对所述非规则化的数据文档进行数据提取处理操作。
本发明还提供了一种高招大本数据采集系统,该系更具体的,所述步骤2中对电子文档进行图像预处理包括:
步骤1.1,图像二值化处理,采用阈值分割技术,设定灰度阈值,若图像像素点灰度值大于或等于所述阈值,则被判定为属于某一特定区域,用 255 表示其灰度值,否则,像素点将被排除在特定区域之外而被判定为背景或其他无用区域,用0表示其灰度值;
步骤1.2,图像增强处理,通过基于空间域的增强和基于频率域的增强处理方法,以减少所获取图像的小的空间改变;
步骤1.3,噪声处理,使用滤波器对所述图像增强处理后的结果进行滤波,去除噪声。
更具体的,所述步骤3中的字符识别包括:
步骤3.1,汉字字符识别:采用水平方向上、竖直方向上、45度角方向、反45度角方向4个特定方向上的矢量准确地描述出一个汉字的基本字形特征;
步骤3.2,英文字符识别:采用基于字符结构的方法对字符进行识别,根据字符在水平方向、竖直方向、笔画的特点,对字符进行逐级的分类,形成一颗判定树,每个字符就是一个叶子,依据字符自身的结构特征进行逼近识别;
步骤3.3,阿拉伯数字识别:先计算欧拉数,再提取凹陷区的特征,最后根据特征组合识别字符。
更具体的,所述步骤4中的对识别后的结果进行修正包括:
利用上下文信息、语法及逻辑,对识别的结果进行修正,生成非规则化的数据文档。
更具体的,所述步骤4中对所述非规则化的数据文档进行数据提取处理操作包括:
步骤4.1,把非规则化的数据文档按照文件名的规则顺序处理,把表格的行转换为普通文本格式的行;
步骤4.2,查看转换出来的文本格式,确定分割条件,分割的条件包括:文理科段落的区分、各个院校段落的区分、院校下各个专业段落的区分条件;
步骤4.3,分别提取所述步骤4.2中的各个所述的段落,合并断行和上下文回溯;
步骤4.4,通过所述步骤4.3得到一个相对规格化的段落的数据文本后,再针对步骤4.2中的各类具体情况提取需要的信息;
步骤4.5,对步骤4.4得到的信息结果做合并,把某些可能混合在其它段落中的信息作缺省的上下文推断填充,至此完成数据提取处理操作。
本发明还提供了一种高招大本数据采集系统,该系统包括书籍扫描模块、图像预处理模块、字符识别模块、修正模块,其中,
书籍扫描模块,用于通过扫描仪,将纸质书籍扫描成电子文档;
图像预处理模块,用于对电子文档进行图像预处理;
字符识别模块,采用字符处理方法对所述图像预处理后的结果进行字符识别,以识别所述结果中的各类字符;
修正模块,用于所述对字符识别后的结果进行修正,生成非规则化的数据文档,然后所述对非规则化的数据文档进行数据提取处理操作。
更具体的,所述图像预处理模块包括:图像二值化模块,采用阈值分割技术,设定灰度阈值,若图像像素点灰度值大于或等于所述阈值,则被判定为属于某一特定区域,用 255 表示其灰度值,否则,像素点将被排除在特定区域之外而被判定为背景或其他无用区域,用0表示其灰度值;
图像增强模块,通过基于空间域的增强和基于频率域的增强处理方法,以减少所获取图像的小的空间改变;
噪声处理模块,使用滤波器对图像进行滤波,去除噪声。
更具体的,所述字符识别模块包括:
汉字字符识别模块:采用水平方向上、竖直方向上、45度角方向、反45度角方向4个特定方向上的矢量准确地描述出一个汉字的基本字形特征;
英文字符识别模块:采用基于字符结构的方法对字符进行识别,根据字符在水平方向、竖直方向、笔画的特点,对字符进行逐级的分类,形成一颗判定树,每个字符就是一个叶子,依据字符自身的结构特征进行逼近识别;
阿拉伯数字识别模块:先计算欧拉数,再提取凹陷区的特征,最后根据特征组合识别字符。
更具体的,所述修正模块包括非规则化数据文档生成模块和数据提取处理模块,其中,
非规则化数据文档生成模块,利用上下文信息、语法及逻辑,对字符识别的结果进行修正,生成非规则化的数据文档;
数据提取处理模块,用于对所述非规则化的数据文档进行文理、院校、专业等的提取和合并处理操作。
更具体的,所述数据提取处理模块具体还包括顺序处理模块、分割模块、合并断行和上下文回溯模块、信息提取模块、合并模块,其中,
顺序处理模块,把非规则化的数据文档按照文件名的规则顺序处理,把表格的行转换为普通文本格式的行;
分割模块,查看转换出来的文本格式,确定分割条件,分割的条件包括:文理科段落的区分、各个院校段落的区分、院校下各个专业段落的区分条件;
合并断行和上下文回溯模块,分别提取分割模块中分割后的所述的段落,进行合并断行和上下文回溯操作;
信息提取模块,通过所述合并断行和上下文回溯模块操作得到一个相对规格化的段落的数据文本后,再针对所述分割模块中的各类具体情况提取需要的信息;
合并模块,对信息提取模块中得到的信息结果做合并,把某些可能混合在其它段落中的信息作缺省的上下文推断填充,完成数据提取处理操作。
本发明的高招大本数据采集方法采用OCR (Optical Character Recognition,光学字符识别)文字识别和非规则文本提取的形式,将书籍数据快速电子化,提高了效率,降低了成本,且避免了人为的错误。
本发明与现有的人工录入数据相比,本发明具有如下有益技术效果:(1)通过自动化代替手工,相比于人工录入,本发明大大降低了人工操作的成本,避免了重复的劳动力;(2)提高效率;通过自动化处理的方式,有效地减少了时间成本,且保证了数据的准确性和完整性;(3)数据ETL化;通过将高招大本的数据进行抽取、转换、加载的处理,变成预先定义好的数据仓库模型,最大化地利用已存在的数据资源,节省了大量时间和资金。
本发明的附加方面和优点将在下面的描述部分中给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了根据本发明一种高招大本数据采集方法的流程图;
图2示出了对非规则化的数据文档进行数据提取处理操作方法流程图;
图3示出了本发明一实施例的一种高招大本数据采集方法流程图;
图4示出了根据本发明一种高招大本数据采集系统的整体系统框图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
为实现上述的发明目的,本发明主要通过如下几点实现:
一、将文件录入,通过扫描仪扫描为电子文档,如将高招大本书籍扫描成PDF文档。
二、对电子文档通过图像二值化处理、图像增强处理及噪声处理等进行图像预处理。
三、采用字符处理方法对所述图像预处理后的结果进行字符识别,以识别所述结果中的各类字符。
四、对所述字符识别后的结果进行修正,生成非规则化的数据文档,然后对所述非规则化的数据文档进行数据提取处理操作。
为了更好的说明本发明的方案,下面将结合说明书附图进行说明。
图1示出了根据本发明一种高招大本数据采集方法的流程图。
如图1所示,根据本发明的一种高招大本数据采集方法,包括:
步骤1,通过扫描仪,将纸质书籍扫描成电子文档;
步骤2,对电子文档进行图像预处理;
步骤3,采用字符处理方法对所述图像预处理后的结果进行字符识别,以识别所述结果中的各类字符;
步骤4,对所述字符识别后的结果进行修正,生成非规则化的数据文档,然后对所述非规则化的数据文档进行数据提取处理操作。
具体的,步骤1中的文件录入操作,如将高招大本书籍扫描成PDF文档。
更具体的,所述步骤2中对电子文档进行图像预处理包括:
步骤1.1,图像二值化处理,采用阈值分割技术,设定灰度阈值,若图像像素点灰度值大于或等于所述阈值,则被判定为属于某一特定区域,用 255 表示其灰度值,否则,像素点将被排除在特定区域之外而被判定为背景或其他无用区域,用0表示其灰度值。
图像二值化擅长处理物体与背景具有较强对比度的图像分割,计算简单,能够用封闭、连通的边界区分出不交叠的区域。打印或手写的文档一般背景与字符的差别较大,适合于进行二值化处理,可以直接设定阈值进行二值化。
步骤1.2,图像增强处理,通过基于空间域的增强和基于频率域的增强处理方法,以减少所获取图像的小的空间改变;
空间域的增强通过减少图像采集系统产生的伪迹来改善图像的完整性。虽然图像可能是原始图像的扭曲变形,感兴趣区域通常因为它的高对比度特点而保持完好。通过灰度图像展现的噪声可以被视为像素值相对于原始值的小的随机变化,这个步骤一般能够减少获取图像的小的空间改变。
步骤1.3,噪声处理,如使用高斯平滑滤波器对所述图像增强处理后的结果进行滤波,去除噪声。
更具体的,所述步骤3中的字符识别包括:
步骤3.1,汉字字符识别:采用水平方向上、竖直方向上、45度角方向、反45度角方向4个特定方向上的矢量准确地描述出一个汉字的基本字形特征。
在汉字的基本笔画里,采用水平方向上、竖直方向上、45度角方向、反45度角方向4个特定方向上的矢量,他们能很好地对应于标准的横线和竖线,也能比较好的反映出撇和捺的特征。另一方面,由于除了点以外的其他基本笔画也可以看成是由这四个基本笔画所组合而成的,所以这四个方向上的矢量就可以相当准确地描述出一个汉字的基本字形特征。
步骤3.2,英文字符识别:采用基于字符结构的方法对字符进行识别,根据字符在水平方向、竖直方向、笔画的特点,对字符进行逐级的分类,形成一颗判定树,每个字符就是一个叶子,依据字符自身的结构特征进行逼近识别。
字符结构在水平方向上有三种类型:左右对称,左大右小,左小右大;竖直方向上也有三种类型:上下对称,上大下小,上小下大。笔画也有两大类:直笔画和弧笔画,直笔画又可分为横笔画、竖笔画、左斜笔画;弧笔画是一条曲线段,可分为两类:开弧笔画和闭弧笔画。所谓开弧笔画,指该弧笔画没有形成封闭环,如字母“C”。根据字符的这些特点,可以对字母进行逐级的分类,形成一颗判定树,每个字符就是一个叶子。这种方法不需要对分割得到的字符进行大小归一化,也不需要建立样本库,完全依据字符自身的结构特征进行逼近识别。
步骤3.3,阿拉伯数字识别:先计算欧拉数,再提取凹陷区的特征,最后根据特征组合识别字符。
欧拉数是一种应用广泛的对物体进行识别的特征,定义为连同成分数减去洞数,E=C-H,其中E、C和H分别为欧拉数、连同成分数和洞数。
更具体的,所述步骤4中的对识别后的结果进行修正包括:
利用上下文信息、语法及逻辑,对识别的结果进行修正,生成非规则化的数据文档。
识别结束后,由于不同文档的清晰度不同,其识别后的结果可能会有较大差别,利用上下文信息、语法及逻辑,对识别的结果进行修正,往往能改善和提高系统的整体性能。修正处理结束后,非规则化的数据文档即可生成。
更具体的,图2示出了所述步骤4中对所述非规则化的数据文档进行数据提取处理操作方法流程图。
如图2所示,步骤包括:
步骤4.1,把非规则化的数据文档按照文件名的规则(省份、页码)顺序处理,把表格的行转换为普通文本格式的行;
步骤4.2,查看转换出来的文本格式,确定分割条件,分割的条件包括:文理科段落的区分、各个院校段落的区分、院校下各个专业段落的区分条件;
步骤4.3,分别提取所述步骤4.2中的各个所述的段落,合并断行和上下文回溯。比如文理段落可能是在原来纸质书籍上的居中部分,在进行OCR识别时该部分数据可能会插到院校或者专业段落,这个需要回溯或区分。
步骤4.4,通过所述步骤4.3得到一个相对规格化的段落的数据文本后,再针对步骤4.2中的各类具体情况提取需要的信息;
步骤4.5,对步骤4.4得到的信息结果做合并,把某些可能混合在其它段落中的信息作缺省的上下文推断填充,如学费/学制等信息有可能一部分在院校段落,一部分在专业段落,因此需要做缺省的上下文推断填充,至此完成处理工作至此完成数据提取处理操作。
图3示出了本发明一实施例的一种高招大本数据采集方法流程图。
如图3所示,首先,将高招大本书籍扫描成PDF文档;对PDF文档进行二值化、图像增强、噪声处理图像预处理;进行字符识别,其中分为汉字字符识别、英文字符识别、阿拉伯数字识别处理;利用上下文信息、语法及逻辑,对字符识别的结果进行修正,生成非规则化的数据文档,然后对所述非规则化的数据文档进行数据提取处理操作。
图4示出了本发明一种高招大本数据采集系统的整体系统框图。
如图4所示,该系统包括:书籍扫描模块、图像预处理模块、字符识别模块、修正模块,其中,
书籍扫描模块,用于通过扫描仪,将纸质书籍扫描成电子文档;
图像预处理模块,用于对电子文档进行图像预处理;
字符识别模块,采用字符处理方法对所述图像预处理后的结果进行字符识别,以识别所述结果中的各类字符;
修正模块,用于所述对字符识别后的结果进行修正,生成非规则化的数据文档,然后所述对非规则化的数据文档进行数据提取处理操作。
更具体的,所述图像预处理模块包括:图像二值化模块,采用阈值分割技术,设定灰度阈值,若图像像素点灰度值大于或等于所述阈值,则被判定为属于某一特定区域,用 255 表示其灰度值,否则,像素点将被排除在特定区域之外而被判定为背景或其他无用区域,用0表示其灰度值;
图像增强模块,通过基于空间域的增强和基于频率域的增强处理方法,以减少所获取图像的小的空间改变;
噪声处理模块,使用滤波器对图像进行滤波,去除噪声。
更具体的,所述字符识别模块包括:
汉字字符识别模块:采用水平方向上、竖直方向上、45度角方向、反45度角方向4个特定方向上的矢量准确地描述出一个汉字的基本字形特征;
英文字符识别模块:采用基于字符结构的方法对字符进行识别,根据字符在水平方向、竖直方向、笔画的特点,对字符进行逐级的分类,形成一颗判定树,每个字符就是一个叶子,依据字符自身的结构特征进行逼近识别;
阿拉伯数字识别模块:先计算欧拉数,再提取凹陷区的特征,最后根据特征组合识别字符。
更具体的,所述修正模块包括非规则化数据文档生成模块和数据提取处理模块,其中,
非规则化数据文档生成模块,利用上下文信息、语法及逻辑,对字符识别的结果进行修正,生成非规则化的数据文档;
数据提取处理模块,用于对所述非规则化的数据文档进行文理、院校、专业等的提取和合并处理操作。
更具体的,所述数据提取处理模块具体还包括顺序处理模块、分割模块、合并断行和上下文回溯模块、信息提取模块、合并模块,其中,
顺序处理模块,把非规则化的数据文档按照文件名的规则顺序处理,把表格的行转换为普通文本格式的行;
分割模块,查看转换出来的文本格式,确定分割条件,分割的条件包括:文理科段落的区分、各个院校段落的区分、院校下各个专业段落的区分条件;
合并断行和上下文回溯模块,分别提取分割模块中分割后的所述的段落,进行合并断行和上下文回溯操作;
信息提取模块,通过所述合并断行和上下文回溯模块操作得到一个相对规格化的段落的数据文本后,再针对所述分割模块中的各类具体情况提取需要的信息;
合并模块,对信息提取模块中得到的信息结果做合并,把某些可能混合在其它段落中的信息作缺省的上下文推断填充,完成数据提取处理操作。
本发明的高招大本数据采集方法采用OCR (Optical Character Recognition,光学字符识别)文字识别和非规则文本提取的形式,将书籍数据快速电子化,提高了效率,降低了成本,且避免了人为的错误。
以一本500页的高招大本的数据为例,按照一个人一个小时录入一页的速度计算,需要500小时的工作量。而采用本发明的技术方案,主要时间将花在OCR识别过程上,大概只需不到40小时的时间,即可完成数据的入库工作。因此本发明对于资源的节约有着明显的作用。
本专利可应用各种复杂的数据采集录入操作,在任何需要将书籍录入为电子化应用场景下都可以使用。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!