一种基于社交网络短文本流的用户聚类和短文本聚类方法与流程
本发明涉及计算机技术领域,更具体地,涉及一种基于社交网络短文本流对用户聚类和短文本聚类的方法及系统。
背景技术:
随着移动互联网的普及和社交网络的迅速发展,社交网络上已经沉积了亿万的用户数据,如何分析这些用户发表的短文本进行用户聚类和短文本聚类成为一个十分重要的课题。然而现有的方法并没有针对社交网络中的短文本数据流潜在语义信息进行用户动态聚类的有效方法,所以本发明提出有效的动态聚类方法解决社交网络中对短文本数据流进行潜在语义分析进行用户聚类和短文本聚类的问题。
本发明在原理和设计上以及应用场景上和下述几个短文本处理专利有显著不同。
公开号CN104850617A提供了短文本处理方法及装置,方法是获取第一短文本集合,并对所述第一短文本集合进行预处理;基于预处理后的第一短文本集合,执行如下处理步骤:使用所述预处理后的第一短文本集合训练主题模型LDA,得到所述第一短文本集合中各短文本的主题概率分布;对所述主题概率分布进行聚类,确定所述第一短文本集合中各短文本的主题类别。(但该发明涉及的LDA不适用于社交网络中短文本数据流,原因有三,1.未考虑时间因素。2.未考虑社交因素3.未考虑用户表达习惯。因此无法真正捕捉社交网络中用户的主题特征。)
公开号CN101477563提供了一种短文本聚类的方法、系统及其数据处理装置,具体地说,步骤1,将该短文本集中的所有短文本作为一个类别;步骤2,从当前的所有类别中选择一个类别,从中寻找核心词汇;步骤3,如果找到核心词汇,根据是否包含该核心词汇将所选择的类别分成两个类别,执行步骤2;步骤4,如果没找到核心词汇,记录并删除该所选择的类别,从剩余的类别中选择一个类别,执行步骤2,直至没有剩余类别为止,所记录的类别作为聚类的结果。
公开号CN105468713A提供了一种在线分析网络流中短文本信息聚类的方法,该发明公开了一种多模型融合的短文本分类方法,包括学习方法和分类方法两部分;学习方法的步骤包括:对短文本训练数据进行分词、过滤,得到单词集合;计算每个单词的IDF值;计算所有单词的TFIDF值,构建文本向量VSM;基于向量空间模型进行文本学习,构建出本体树模型、关键字重叠模型、朴素贝叶斯模型和支持向量机模型。分类方法的步骤包括:对待分类短文本进行分词、过滤;基于向量空间模型生成文本向量;分别应用本体树模型、关键字重叠模型、朴素贝叶斯模型和支持向量机模型进行分类,得到单一模型分类结果;对单一模型分类结果进行融合,得到最终分类结果。
公开号CN104915386A提供了一种基于深度语义特征学习的短文本聚类方法,选取训练文本,通过特征降维方法在局部信息保存约束下对所述训练文本的原始特征进行降维,并对低维实值向量进行二值化;从所述训练文本中获取词特征,根据所述词特征通过查表分别获取所述词特征对应的词向量,以此作为卷积神经网络的输入特征学习深度语义表示特征;所述卷积神经网络的输出节点通过多个逻辑斯特回归拟合降维得到二值码;通过所述卷积神经网络输出的二值特征与所述原始特征降维后二值化特征的拟合残差进行误差反向传播训练所述卷积神经网络模型;利用所述更新后的卷积神经网络模型对所述训练文本进行深度语义特征映射,然后利用K均值聚类算法得到所述短文本的聚类结果。
技术实现要素:
本发明目的在于解决当前基于语义的用户聚类和短文本聚类方法中未考虑社交因素,“词义漂移”和短文本稀疏性问题。在传统的主题生成模型中加入用户文字表达习惯以及朋友关系紧密度分布对用户本身主题分布的影响来对社交网络中的短文本流进行主题建模。可选地本文使用英文作为语料进行训练。
为了达到上述目的,本发明采用以下技术方案:
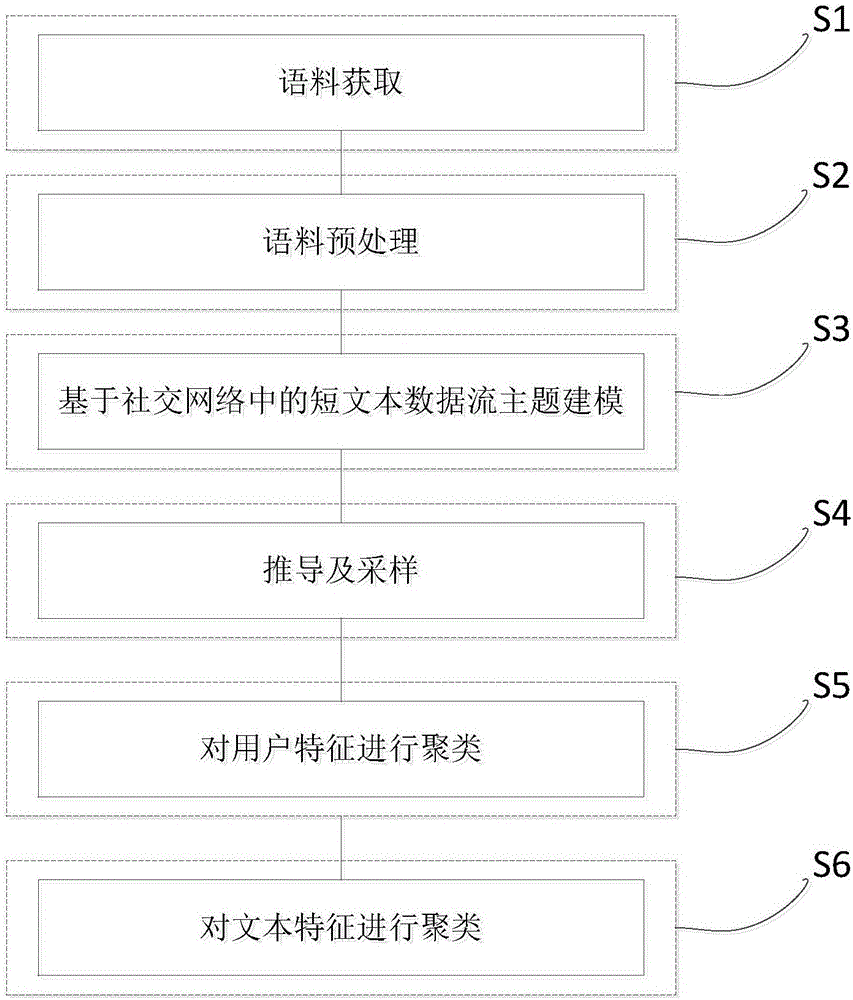
基于社交网络短文本流主题建模的用户聚类和文本聚类方法,如图1所示,包括下述步骤:
S1、语料获取。通过实现爬虫或社交网络平台公司开放的API获取该社交网络平台的语料库抑或通过自建社交网络系统收集用户语料;
S2、语料预处理。包含分词,去停用词,提取词干和提取实体;
S3、基于社交网络中的短文本数据流主题建模。针对语料中文本作者之间存在的社交关系,文本内“词义漂移”问题和短文本稀疏性问题,对语料中的文本进行主题建模,以抽取每个文本的主题;
S4、推导及采样。根据已建立的概率图模型,推导该模型的主题联合概率分布,并以此作为吉布斯抽样的联合概率分布,最后抽样收敛时,统计用户和文本的主题分布;
S5、对用户进行聚类。将得到的用户主题作为语料中用户的特征,并执行K-Means聚类,得到用户聚类结果;
S6、对短文本进行聚类。将得到的短文本主题作为短文本的特征,对执行K-Means聚类,得到短文本聚类结果。
作为优选的,步骤S1中,采用Twitter公司公开的Streaming API获取英文语料。采用新浪API获取中文语料。可选地,本发明以英文语料为例作为处理对象。
作为优选地,步骤S2中,对于中文语料,本发明采用“最长分词法对短文本进行分词”ICTCLAS分词法对语料进行分词处理。对于英文语料,本发明采用Lemur的停用词库去除停用词。并且采用NLTK的Stemming方法中Porter方法进行提取词干。
作为可选地,步骤S3中,本发明采用自主设计的主题模型。在文本主题建模和用户主题建模中,同时考虑社交网络中的“词义漂移”,“短文本稀疏性”和“朋友圈”的特点,重新设计主题模型以适应该应用环境下的主题建模。并且,本发明将用户主题建模和文本主题建模融为一个模型,高效方便,一举两得。
●对于先验αt,u,βt,e,z,本发明将其设置成狄利克雷分布。
●对于主题分布θt,u,φt,e,z,本发明将其设置成和狄利克雷分布共轭的多项式分布。
并且本发明在成功建完模型后,采用Gibbs Sampling方法对主题模型进行推导出主题的联合概率分布,进而继续采用该采样公式对对该主题生成过程进行采样以获得最终主题分布。采样公式为:
作为优选地,步骤S4和步骤S4中,本发明采用K-Means对获得的主题。步骤S4不同于S3,对于新来的用户,其主题分布进和当前时间段内发表的短文本和用户互动有关。
附图说明
图1本发明的系统流程图;
图2本发明中主题建模的概率图模型;
图3本发明的对已存在的用户进行聚类的流程;
图4本发明对新来用户的聚类流程;
图5本发明对已存在用户发表的短文本的聚类流程;
图6本发明对新用户发表的短文本的聚类流程。
具体实施方式
下面结合附图和一个具体实施方式来进一步阐述本发明的内容。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了于发明有关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
本发明针对社交网络中用户发表的短文本数据流的“词义漂移”和短文本稀疏性问题,提出新的文本主题建模方法,以得到每个时间段的文本主题和用户主题。
获取语料:获取一个长时间段T的短文本。然后选择一个小的时间数值t将大的时间分成T/t个时间区间(t可以取一年,一季度,一个月,一周或一天)。由于在社交网络中,文本与文本的作者之间存在社交关联,如果分析一个文本的主题仅考虑本身就会丢失这种社交关联,,从而得不到符合实际情况的文本特征。又由于前后两个时间段t内的文本主题具有主题关联,于是我们提出了动态社交概率图模型用于对用户发表短文本的过程进行主题建模。(可选地,可以自建社交系统获取用户信息,或实现网络爬虫系统以爬取已有的社交网站中用户信息和发表的数据)服务器通过网络获取用户信息,包含但不限于用户id,用户短文本,用户各个朋友id,短文本发表的时间戳。语料按照语言不同,我们将其分为中文语料和英文两种。对于英文语料,通过Twitter的Streaming API获取twitter数据,包含了时间戳,用户id,用户id的所有朋友,用户发表的推特内容。对于中文语料,通过爬虫抓取微博的用户数据,或可选地自建社交系统采集系统用户数据。
可选地,作为例子,本发明的英文语料选择Twitter公司的Streaming API来获取社交用户发布的文本数据,该数据带有时间戳,用户id和tweet内容。亦可基于现有的语料,但要求语料中每个数据包含文本,用户id和时间戳。以及用户id之间的朋友关系。
收集T时长的用户数据。存储用户发表的短文本数据,格式为用户id,文本内容,时间戳。并存储在服务器SVR上。然后按照时间戳,从在最早时间到整个时段内,按时长将T区间分割成段T/t个小区间。然后把所有短文本按照上述区间整理成个短文本集合。设置短文本数据格式,用一个三元组<userid,text,timestamp>表示,其中userid是用户的id,text是短文本内容,timestamp是该短文本发表时的时间戳。并且,还需要获取用户的在该时刻的朋友列表。假设用户user有n个朋友,我们将其表示[f1,f2,…,fn]格式。
语料预处理:为了提高短文本处理的高效性,需要对短文本进行预处理。对于英文:去除停用词,并对每个词抽取词干。可选地,抽取词干的方法我们选择NLTK的Porter方法。对于中文:去除停用词,如“的”,“地”等,然后再对文本进行分词,可选地,可以采用“最长分词法对短文本进行分词”可选地如ICTCLAS分词法,然后可以获得如下格式的数据,[用户id,用户朋友id,短文本词集合,时间戳]
基于社交网络中短文本流的主题建模:步骤S3中,同时考虑社交网络中短文本作者的社交关系、“词义漂移”和短文本稀疏性对主题建模的影响,从而建立一个适合社交网络短文本特性的主题模型以提取用户和文本主题;包括下述步骤:
S301、针对社交网络中短文本作者的社交关系,我们引入朋友关系紧密度分布,用于衡量朋友之间主题相互影响程度。
S302、针对社交网络中短文本语义的“词义漂移”问题,我们将主题-词分布视作用户表达习惯并将其分成3类,分别是用户自己的表达习惯,用户朋友的表达习惯以及其余整个社交网络中的普遍的表达习惯。
S303、针对社交网络中短文本的稀疏性问题,我们在对主题模型进行采样的时候对文本中的所有词的主题统一成短文本的主题,这符合用户在发表短文本时候的行为,因为短文本字数限制,所有文字只为短文本的主题服务,即其应该和短文本的主题一致。
对该短文本发表过程构建基于时间和朋友关系链的主题生成模型DSM。本发明首次提出的动态社交主题生成模型如附图2:
该模型展示了三个时间段t-1,t,t+1内的短文本主题和用户主题生成过程,由于短文本的稀疏性,区别于传统的LDA模型,我们将每个短文本只赋予一个主题z(传统的LDA认为一个文本中的每个词不是相同的主题)。该短文本中的所有词w均被指派到z主题上。每个词w的生成依赖于表达习惯e的选择和对应的主题-词分布每一篇短文本均是由某个用户发表的,该短文本的主题反应了用户的潜在语义和表达意图。在社交网络中,每个用户都用于一定数量的朋友,在朋友的影响下,他可能发表一些不同自己以往风格和意图的文本,这也是本发明考虑社交因素的原因。我们将用户q和朋友集合{f1,…,fn}的亲疏远近用多项式分布来表示。上述模型图中,灰色的圆圈表示观察量,白色的圆圈表示隐含变量(抽象出来的)。矩形框代表该里面变量的抽样迭代次数,被箭头指向的变量代表生成该变量需要依赖箭头后面的变量。
主题生成:本发明在建立好上述概率图生成模型后,采用吉布斯采样对短文本集中每个短文本,短文本中的每个词,以及每个用户进行主题采样。最后统计收敛后的用户的主题分布。(可选地采用吉布斯采样)直至收敛到概率图所表达的概率分布,并统计每个用户和短文本的主题分布
特征聚类:在获得用户和短文本的主题特征后,我们可以分别对用户和这些短文本进行聚类。聚类的结果是符合人类语义理解的聚类结果。对于聚类方法,可选地,可以采用K-Means聚类算法进行聚类。这样就获得t时段的用户聚类和短文本聚类和短文本聚类。K-Means方法在数中预先选定k个簇类中心,然后对于其它每个数据(此处为主题概率分布是一个n维向量),我们可以用cosine计算其它数据和簇类中心的余弦距离,将每个数据指派到余弦距离最近的簇类中。并重新计算每个簇的中心以得到新的k个中心。重复上述步骤直至k个中心不再改变。
特别地,对于只在t时段开始出现的新用户或新文本,我们采用t时段的主题-词分布。对于只在t时段新来的用户或文本,我们分析该用户在t时段主题分布和该用户在t时段发布的短文本的主题分布,然后将其指派到t时段中已经计算好的距离他最近的簇类中去。
对于用户聚类按照用户存在的先后,分为以下2种。
对已存在系统中的用户(如附图3):
步骤S5101:收集1到t时段内各个用户发表的短文本数据流;
步骤S5102:对1到t时段已存在的用户发表的短文本进行动态社交主题分析并作为对应用户特征;
步骤S5103:根据各个时间段中每个用户的主题特征用K-Means聚类;
对新到来的用户(在t时段刚到的用户,如附图4):
步骤S5201:收集t时间段内新来用户发表的短文本数据;
步骤S5202:对该时间段的短文本数据进行主题分析求得新用户的主题特征;
步骤S5203:根据用户的主题特征和已计算出的类簇对比,将其该用户赋予到欧氏距离最近的类簇中去。
同样地,对于短文本聚类按照用户的不同,分为以下2种。
对已存在用户发表的短文本(如附图5):
步骤S6101:收集1到t时段内各个用户发表的短文本数据流;
步骤S6102:对1到t时段已存在的用户发表的短文本进行动态社交主题分析并作为对应短文本特征;
步骤S6103:根据各个时间段中每篇短文本的主题特征用K-Means聚类;
对新到来的用户发表的短文本(如附图6):
步骤S6201:收集t时间段内新来用户发表的短文本数据;
步骤S6202:对该时间段的短文本数据进行主题分析求得新短文本的主题特征;
步骤S6203:根据用户的主题特征和已计算出的类簇对比,将其该短文本赋予到欧氏距离最近的类簇中去。
上述具体实施方案及实例仅为本专利的优选实施方案及实例,不能理解为对本专利的实施方式的限定。对于所属区域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法
- 利用媒体提示来识别和关联用户设备的系统、方法和介质的制作方法
- 基于用户的媒体内容分节系统和方法
- 对公司社交网络的用户接收的消息进行分类的方法