一种时空域统计匹配局部特征的运动目标检测方法与流程
本发明属于人工智能领域的运动目标检测技术,特别是一种时空域相似度判断、统计整体相似度和视频局部带权重特征结合的运动目标检方法。
背景技术:
为了更高效的从日益增长的海量的视频中提取目标信息、提高搜索效率等,运动目标检测模型研究一直是人工智能领域的重点发展技术。现有的监督类方法需要大量训练、算法复杂度高,而非监督类方法检测精度低、依赖于特征。本文根据运动目标检测精度高、时效快、参数少、易实现的要求,探索并设计实现了一种时空域统计匹配局部特征的运动目标检测方法。
三维lark特征由seo等人在2010年提出,具有旋转和尺度不变性,抓住图像潜在结构而不受噪声影响、稳定性好的优点,但是不能区分中心像素点和邻域像素点的重要性;而hog特征没有尺度、旋转不变性,lbp特征无法保留图像细节,sift特征容易被背景和噪声影响;cnn特征通过卷积核由浅入深地提取不同层次的特征,效果较好但是训练样本冗长复杂。
在检测方法方面,非监督类中seo的方法使用全背景整体模板,目标与模板整体匹配,导致待测视频适用场景有限;当运动目标动作路径与模板不同时,待测视频拍摄角度与模板拍摄角度差别较大时,当背景与模板不接近时,检测精度很低;监督类的方法需要对目标和背景分开训练,训练之后再进行验证调整,方法过程复杂、效率低。
技术实现要素:
本发明的目的是提供一种精确高效、简单方便的时空域统计匹配局部特征的运动目标检测方法。
实现本发明目的的技术解决方案为:一种时空域统计匹配局部特征的运动目标检测方法,包括以下步骤:
步骤1、提出3-dlwr算子:根据邻域像素点距离中心像素点的距离远近,设置基于圆域滤波器的时空权重滤波器f,结合现有的局部自适应回归核,得到时空局部带权重的回归核3-dlwr算子;
步骤2、构建复合模板集:将模板视频转成灰度图片序列,然后将图片序列去背景,选取运动半身和多尺度缩放处理,再用3-dlwr算子提取模板的局部特征,最后用主成分分析法和向量余弦匹配法对模板局部特征做冗余去除处理;
步骤3、待测视频预处理:将待测视频转换为灰度图片序列,并提取显著性区域,提取显著视频的3-dlwr特征,并用主成分分析法进行去冗余处理;
步骤4、时空域相似性评估:将待测视频显著区域内每一像素点对应的3-dlwr特征向量,与复合模板集的所有特征向量进行余弦匹配,记录最大匹配值对应的模板中向量的位置;
步骤5、时空域整体相似度统计:设立时空统计窗口,统计窗口内不同的位置数目,得到运动目标存在的概率矩阵;
步骤6、根据统计概率矩阵,用非极大值抑制的方法,逐帧提取出运动目标位置,并恢复成视频。
本发明与现有技术相比,其显著优点为:(1)提出了3-dlwr特征提取算子,通过滤波器区分了时空像素点的重要性,可以更加精细地描述视频数据结构;(2)采用复合模板集,用简单的几帧动作,带入后续检测处理流程,不需要复杂的样本训练过程,降低算法复杂度,同时提高了时间效率;(3)通过先判断局部相似度,再统计得到整体相似度的分解过程,检测多角度拍摄的视频、多场景视频以及目标动作路径多变的视频,有效降低了误检率。
附图说明
图1为本发明时空域统计匹配局部特征的运动目标检测方法的流程图。
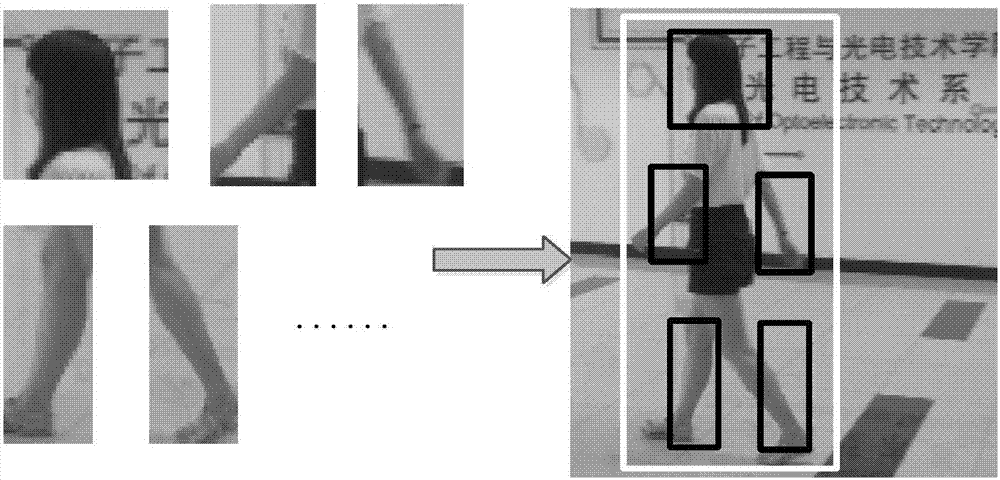
图2为多样局部结构构成整个运动目标说明图。
图3为整体相似性评估的时空统计过程图。
图4为检测结果和对应的统计概率矩阵图,其中(a)与(c)为不同帧的统计概率对比图,(b)与(d)为不同帧的检测结果图;(e)与(g)为不同帧的统计概率对比图,(f)与(h)为不同帧的检测结果图;(i)与(k)为不同帧的统计概率对比图,(j)与(l)为不同帧的检测结果图。
图5为运动目标的提取过程图,其中(a)为整体相似度图像s1;(b)为运动目标图像tmax;(c)为标记目标区域。
图6本发明方法检测标准库的结果图,其中(a)~(d)为标准库中sufer视频的不同帧检测结果图,(e)~(h)为标准库中jogging视频的不同帧检测结果图,(i)~(l)为标准库中dance视频的不同帧检测结果图。
图7本发明方法与seo算法检测结果对比图,其中左列(a)、(b)、(e)、(f)为本发明的检测结果,右列(c)、(d)、(g)、(h)为seo算法的检测结果。
图8本发明方法检测被遮挡目标的结果图,其中(a)~(d)为凉亭遮挡人体不同部位时目标的检测结果图。
图9为检测挥手动作使用的半身模板图,其中(a)~(f)为检测挥手动作使用的半身模板序列图。
图10为本发明检测识别挥手动作的结果图,其中(a)~(d)为检测挥手动作手处于不同位置时的结果图。
图11为检测下蹲动作使用半身模板图,其中(a)~(g)为检测下蹲动作使用半身模板序列图。
图12为本发明检测识别下蹲动作的结果图,其中(a)~(d)为检测识别下蹲动作蹲至不同位置时的结果图。
图13为三种方法检测标准库thumoschallenge2014中的部分自然拍摄的长视频检测精度柱状对比图。
具体实施方式
本发明创建了整个运动目标检测方法,先提出了3-dlwr算子,用于提取模板视频和待测视频特征,通过时空域局部相似度判断,再统计时空域整体相似度的过程,优化了目标存在的统计概率图,提高了运动目标检测的准确率。
本发明时空域统计匹配局部特征的运动目标检测方法,包括以下步骤:
步骤1、提出3-dlwr算子:根据邻域像素点距离中心像素点的距离远近,设置基于圆域滤波器的时空权重滤波器f,结合现有的局部自适应回归核(locallyadaptiveregressionkernel,lark),得到时空局部带权重的回归核3-dlwr(three-dimensionallocallyweightedregression)算子;
步骤1中所述时空权重滤波器f的大小为5×5×3,中间第二帧为圆域均值滤波器,第一帧和第三帧相同,具体为:
步骤1-1、3-dlwr特征基于的局部自适应回归算子,公式为:
式中,xl是时空中心点,xi是中心点时空邻域窗口内的像素点,h是全局平滑参数,cl∈r3×3是基于行、列和时间方向上的梯度向量的协方差矩阵;计算cl∈r3×3时需要另取一个时空邻域范围,设为5×5×3,邻域范围内的像素点被同等的选取,且cl∈r3×3计算公式为:
其中,m=5×5×3=75,梯度向量矩阵j公式为
步骤1-2、区分中心点周围像素点的重要性,将协方差矩阵与时空权重滤波器f结合,其公式为:
jnew=jl×f,∈5×5×3
步骤1-3、时空权重滤波器f∈5×5×3,中间第二帧为半径为5的圆域均值滤波器,如下式f(:,:,2)所示;第一帧和第三帧由基于圆域均值滤波器乘以权重因子0.6变形而成;由于cl∈r3×3在计算的过程中要使用奇异值分解,用于降低维度的主成分分析法pca中要使用特征值分解,数值为0则不必经历奇异值分解和特征值分解,由于0.2138乘以权重因子0.6后的数值接近于0,因此将其设置为0,将小数点后面第二位的数字忽略,得到权重矩阵的第一和第三帧,如下式f(:,:,1)所示,具体公式为:
步骤1-4、对步骤1中所述的3-dlwr,其中协方差矩阵公式为:
使用带权重的clnew代替原来的cl,得到整个视频中每个点的核值k,再进行归一化,将归一化之后窗口内的各像素点对应的元素值按序排成一列,得到该点的局部自适应回归核特征向量wi,即3-dlwr,公式为:
其中,i为任意一点,m为视频内总像素点的数目。
步骤2、构建复合模板集:将模板视频转成灰度图片序列,然后将图片序列去背景,选取运动半身和多尺度缩放处理,再用3-dlwr算子提取模板的局部特征,最后用主成分分析法和向量余弦匹配法对模板局部特征做冗余去除处理;
所述模板视频为感兴趣目标完成一个完整动作的图片序列,去背景后,由于只统计窗口内变化的像素点,而忽略不变的像素点,所以模板的每一帧只包含目标的运动部分即可,即半身模板;比如,行走动作的模板只要包含人腰部以下部分,检测挥手的人只要包含人肩部以上部分,如图9所示;将半身模板图片序列缩放,对得到的多尺度模板进行3-dlwr(3-d为时空域的缩写)特征提取,得到模板视频的特征集wq,公式为:
其中,q为模板queryvideo的缩写,mq为模板视频总像素点个数;
然后使用主成分分析法降低单个特征向量的维度,经过pca后,单个像素点的3-dlwr维度从1×75降低为1×4;由于后续统计过程需要统计滑动窗口内不相似的局部结构数目,为保证统计匹配的准确性,由于后续统计过程需要统计滑动窗口内不相似的局部结构数目,模板特征集中的局部结构必须是互不相似的,因此用向量余弦匹配去除向量间冗余,公式为:
其中,
当两个向量之间的相似度超过阈值的时候,表明这两个向量相似,则舍弃其中一个向量,得到复合模板集矩阵
步骤3、待测视频预处理:将待测视频转换为灰度图片序列,并提取显著性区域,提取显著视频的3-dlwr特征,并用主成分分析法进行去冗余处理;
所述将待测视频转换为灰度视频,之后进行显著性提取预处理,显著性区域内的像素点进行3-dlwr特征提取得到局部结构特征矩阵wt,之后对wt进行降低向量间维度处理,得到待测视频特征矩阵:
步骤4、时空域相似性评估:将待测视频显著区域内每一像素点对应的3-dlwr特征向量,与复合模板集的所有特征向量进行余弦匹配,记录最大匹配值对应的模板中向量的位置;
所述时空域相似度判断,具体为:
步骤4-1、将待测视频特征矩阵
其中,j为模板集中任意一个列向量;
步骤4-2、找出向量ρ中最大的匹配值
步骤4-3、对待测视频显著区域中所有像素点重复步骤4-1和步骤4-2的操作,并将位置编号按照视频像素点顺序排列,设视频大小为m×n×t,最后得到时空域位置矩阵p∈rm×n×t;
步骤4-4、设定相似度判断阈值α,当待测视频每个像素点对应的最大的匹配值
步骤5、时空域整体相似度统计:设立时空统计窗口,统计窗口内不同的位置数目,得到运动目标存在的概率矩阵;
所述时空统计窗口为16×16×5,窗口遍历时空域位置矩阵p之后得到时空统计概率矩阵s∈r(m-16)×(n-16)×(t-5);然后进行运动目标位置提取,具体为:
步骤5-1、首先判断每一帧图片中是否存在目标,将整体相似度矩阵s的第三维度依次读取,得到单帧相似度矩阵s1∈r(m-16)×(n-16),s1中的最大值代表最多的相似局部结构,即最强的运动信息,因此若s1中的最大值小于设定的目标阈值λ,则表示当前帧中不包含目标;
步骤5-2、确定当前帧中包含至少一个目标后,用非极大值抑制的方法提取目标。
步骤6、根据统计概率矩阵,用非极大值抑制的方法,逐帧提取出运动目标位置,并恢复成视频。所述非极大值抑制方法中搜寻范围参数σ的取值为0.92~0.97。
下面结合实施例对本发明的目标动作识别方法做进一步详细的描述:
实施例1
本实施例中时空域统计匹配局部特征的运动目标检测方法是利用3-dlwr特征和复合模板集进行时空域的统计匹配,其中3-dlwr特征包括对梯度向量矩阵通过时空域滤波器分配权重,视频预处理部分包括构建无背景多尺度模板和对待测视频提取时空域显著区域,对模板和待测视频提取3-dlwr特征,并进行降维和去冗余处理,得到复合模板集和待测视频特征集。相似性评估分局部相似性评估和统计整体相似度。最后判断单帧中包含目标以后提取目标动作。具体为:
第一步:梯度向量矩阵j的定义如下:
m1×n1×t1是计算协方差矩阵时的窗口。上式表明,窗口内像素点都是平等选取的,不利于区分像素点的时空重要性。为了区分像素点的重要性,将权重矩阵f和jl结合来实现权重分配。
jnew=jl×f,∈m1×n1×t1
三维窗口内离中心像素点越远的点权重分配越小,表明该像素点的梯度向量越不重要;反之离中心像素点越近的点权重分配越大,表明该像素点的梯度向量越重要。权重矩阵的权重类似于纺锤形,中间权重大,而两端权重小。例如,当三维窗口是5×5×3的时候,权重矩阵的大小也是5×5×3。最中间的二维矩阵,即第二帧,是一个5×5的圆域均值滤波器。圆域滤波器在二维空间内自带权重,圆心处权重大,边缘处权重小。权重矩阵的第一和第三帧离中心像素点较远,越往外权重越小,且距离相同,因此第一第三帧权重大小相同,初始设置为第二帧的0.6倍,得到的矩阵的边缘处的值接近于0。
由于协方差矩阵在计算的过程中要使用奇异值分解,以及用于降低维度的主成分分析法(pca)中要使用特征值分解,而数值为0则不必经历奇异值分解和特征值分解,本文将接近于0的数值设置为0,同时将小数点后面第二位的数字省略,使计算精简,最后得到权重矩阵的第一和第三帧,具体时空域权重滤波器公式为:
然后
其中,xl是中心点,xi是邻域像素点。h是全局平滑参数,clnew∈r3×3是协方差矩阵,
计算后得到每个像素点核值knew。
第二步:构建复合模板集。选取运动目标完成一个动作的几帧图片,并去除背景,针对运动信息只集中在目标一部分的,本发明选择半身模板,如图8和图10所示,分别为检测挥手目标和下蹲目标所使用的半身模板。之后将无背景模板缩放为0.5倍、1倍和1.5倍。计算三个模板图片序列的3-dlwk特征,3-dlwk继承了lark特征尺度不变和旋转不变性,适用于本发明的缩放模板。
本发明设置计算3-dlwk的时空域窗口为5×5×3,则每个像素点的3-dlwk向量大小为1×75,使用pca降低单个向量的维度后为1×4。向量余弦匹配法用于去除模板集向量间冗余,公式为:
其中,
第三步:构建待测视频特征集。为了提高算法速度,且更准确的识别目标,去除与感兴趣目标无关的背景,获取感兴趣区域,是待测视频预处理中重要部分,这个过程称为显著性提取。对显著性区域内的像素点进行3-dlwk特征提取,并进行pca降低单个向量维度,最后形成待测视频特征集。
第四步:局部特征相似性评估。利用余弦相似度将待测视频和模板进行匹配,待测视频特征集中每一个列向量
得到每一个点与复合模板集中所有列的匹配向量为:
在匹配向量ρ中,找出最大的ρj值,将其对应向量在复合模板集中的位置编号保留在待测视频中相应像素点的位置,待测视频特征集中每一个像素点都经过上述步骤,形成时空位置矩阵p∈rm×n×t。
其中,index为最大的ρj值对应的向量在复合模板集中的位置编号。
ρ值小的代表模板与待测视频当前像素点对应的局部结构相似度低,设立一个阈值θ,低于阈值的ρ值对应的向量位置编号赋为0,只保留相似度大于阈值θ的剩余位置编号。
第五步:评估与模板的整体相似性。记录最相似向量对的位置,以统计在一定的空间内,相似的局部结构的数目。局部结构如图2左边所示,同时也是右边黑框内的部分。模板特征去冗余步骤保证了复合模板集内向量代表的局部特征互不相似,当白色框内包含足够多的局部特征,才能检测窗口内整体为运动目标。
待测视频中目标信息包含在位置矩阵p中,但单个像素点相似只是局部疑似目标,不能说明整体就是目标。背景中可能有部分结构与目标结构相似导致误识别,如检测行人的时候,人迈步的腿与树枝的分叉、窗户角的方向都是相似的,可能识别为行人。为了避免这个问题,本文利用运动目标的整体结构。在相似度匹配后,统计相似结构的数目,统计值为统计窗口区域与模板的整体相似度。树杈、窗户角等虽然与行人的腿部相似,但周围没有人的摆臂、躯干等,因此统计整体相似度可以降低误识别率。
设立时空统计窗口smum遍历整个位置矩阵,窗口大小一般设为16×16×5。在矩阵p中,统计得到时空整体相似度矩阵s∈r(m-16)×(n-16)×(t-5),统计过程如图3所示。
图4中列出了运动目标位置统计概率图和最后目标位置提取结果的对比图。使用本发明方法检测visualtrackerbenchmarkdatasets标准库中运动目标,这个标准库主要用于目标跟踪检测,在2013年提出。库内包含来自最近文献的100个视频,本文选取了部分适用于单个或少数几个目标检测的视频。当同一视频中运动目标在不同的位置或姿态不同时,统计概率图也有明显不同,结合图4,(a)与(c)为标准库中同一视频不同帧的统计概率对比图,(b)与(d)为同一视频中不同帧的检测结果图;(e)与(g)为标准库中同一视频不同帧的统计概率对比图,(f)与(h)为同一视频中不同帧的检测结果图;(i)与(k)为标准库中同一视频不同帧的统计概率对比图,(j)与(l)为同一视频中不同帧的检测结果图。
第六步,在得到时空统计矩阵s后,逐帧独立提取运动目标。先考虑每一帧图片中是否存在目标,将整体相似度矩阵s的第三维度依次读取,得到单帧相似度矩阵s1∈r(m-16)×(n-16)。设定一个目标阈值λ用于判断单帧图片中是否存在至少一个目标。s1中的最大值代表了最多的相似的局部结构,即最强的运动信息,因此若s1中的最大值少于设定目标阈值λ,则表示当前帧中没有目标,经统计概率矩阵最大值分析和测试,当运动目标占幅不过大或过小的时候,λ设为20。
确定当前帧中包含至少一个目标后,用非极大值抑制的方法提取目标。寻找s1中的最大值,然后将最大值一定范围邻域内像素点的值置零,继续寻找剩下数值中的次极大值,重复上述过程,最后将数值为0的点提取出来。若单帧当中有多个目标,则逐个通过寻找最大值,将邻域像素点设置为0的方法,框出目标,得到运动目标单帧图像tmax。
非极大值抑制方法需要循环搜寻当前数值中的最大值,为了确定循环次数,设定一个搜寻范围参数α,只在α范围内搜寻最大值。在一幅图像中,目标在整幅图片中占的比例一般较小,大部分像素点是不需要搜寻最大值的。因此α一般范围设置为0.92-0.97。结合运动目标图像tmax,在原始图像中标记出运动目标,最后将多帧图像恢复成视频,如图5所示,(a)为统计概率图,(b)为tmax,(c)为单帧检测结果图。
图6列出了本发明检测visualtrackerbenchmarkdatasets标准库中sufer、jogging、dance三个视频的不同帧检测结果,其中(a)~(d)为标准库中sufer视频的不同帧检测结果图,(e)~(h)为标准库中jogging视频的不同帧检测结果图,(i)~(l)为标准库中dance视频的不同帧检测结果图。对整个标准库检测的结果来说,本方法检测精度较高,适用场景多。当视频中对比度明显的时候,如dance,检测精准度一般达到90%,检测的位置定位也很准确,这主要归因于对待测视频预处理的显著性提取,人眼视觉注意力机制将显著性提取锁定在对比度明显的区域。
图7列出了本发明与seo的3dlsk方法检测结果对比,左列(a)、(b)、(e)、(f)为本发明的检测结果,右列(c)、(d)、(g)、(h)为seo算法的检测结果。实验证明,本发明可以检测同一帧中多尺度目标,对背景复杂的场景也有很好的检测结果,而seo的方法识别结果较为混乱。
图8列出了本发明用只包含动作的半身的模板,检测被遮挡目标的实验结果,其中(a)~(d)为凉亭遮挡人体不同部位时目标的检测结果图。总体来说半身模板识别精度低于全身模板,且框出的目标对于目标的正确位置有偏移,且有几帧未能测出。未检测出帧在每秒25帧以上的视频中所占比例小,可以忽略。半身模板集适用于精度要求不高而时间效率要求高的测试。对于精度要求高的应用,例如,自动驾驶视觉系统,则不能使用半身复合模板集。
去背景半身复合模板集,使待测视频的适用场景和视频拍摄角度得到扩展,不仅效率更高,还能解决前景遮挡的问题。如图8所示,当凉亭遮挡部分人体的时候,本发明方法也能测出目标,且沙滩上的长椅类似与人腿,但也不会影响行人目标的检测。
本发明不仅可以识别行走动作,也可以识别其他动作。图9为检测识别挥手动作使用的半身模板,其中(a)~(f)为检测挥手动作使用的半身模板序列图。图10为检测识别挥手动作的结果,其中(a)~(d)为检测挥手动作手处于不同位置时的结果图。图11为检测下蹲动作使用的半身模板,其中(a)~(g)为检测下蹲动作使用半身模板序列图。图12为检测识别下蹲动作的结果,其中(a)~(d)为检测识别下蹲动作蹲至不同位置时的结果图。。
本发明与非监督类方法对比,有更高的检测精度;与监督类方法对比,使用简单高效的复合模板集,也能达到同样的检测精度。图13列出了在标准库thumoschallenge2014中的部分自然拍摄的长视频检测精度柱状对比图,对比的非监督方法包括:(1)s-cnn是通过三个分段实现深度神经网络法对目标进行时空定位;(2)wang等人建立一个基于idt的系统,运用循环神经网络提取目标特征。
由上可知,本发明的一种时空域统计匹配局部特征运动目标检测方法,在对多角度拍摄、多场景的长视频中多尺度运动目标检测中,具有良好的检测效果,并能有效识别同一帧中不同尺寸的目标,识别运动目标的不同动作。3-dlwk特征对光照、噪声具有良好的鲁棒性,在一定程度上改善了lark特征算子的性能,使提取的目标特征更精准,检测准确率更高。
- 还没有人留言评论。精彩留言会获得点赞!