基于知识迁移的多模态循环神经网络的图像文本描述方法与流程
本发明涉及机器视觉与模式识别领域,更具体地,涉及一种基于知识迁移的多模态循环神经网络的图像文本描述方法。
背景技术:
近年来,循环神经网络的自然语言处理以及基于卷积神经网络的图像分类处理的快速发展,使得应用深度神经网络进行的图像理解技术广泛被人们采用。自动生成图像文本描述作为联系着两大人工智能领域的技术(计算机视觉以及自然语言处理),吸引了越来越多的人关注以及研究。
对于普通的图像文本描述生成,目前已取得了较好的效果。如2015年,Junhua Mao等人提出了一种基于多模态循环神经网络(m-RNN)的图像描述模型,这个网络模型可以将图像信息与语言模型的信息结合在一个多模态单元,使生成的句子语义能更符合图像表达的信息,而且采用LSTM模型能改善句子的语法结构,增强句子的可读性。
但由于该方法只能应用于现有的图像与文本描述成对匹配的数据集,对于一些图像中的一些没有在文本描述数据字中出现的新的对象,该方法无法识别出来,导致了生成的句子描述的信息可能与图像呈现的信息不相关。而且由于图像与文本描述成对匹配的数据集有限,无法覆盖大部分图像中的对象,并且此类数据集制作时,图像信息要求与文本信息相匹配,需要人工的制作,因此制作此类数据集成本较高。
技术实现要素:
本发明提供一种基于知识迁移的多模态循环神经网络的图像文本描述方法,该方法可满足大部分成对匹配训练集外的新对象的识别。
为了达到上述技术效果,本发明的技术方案如下:
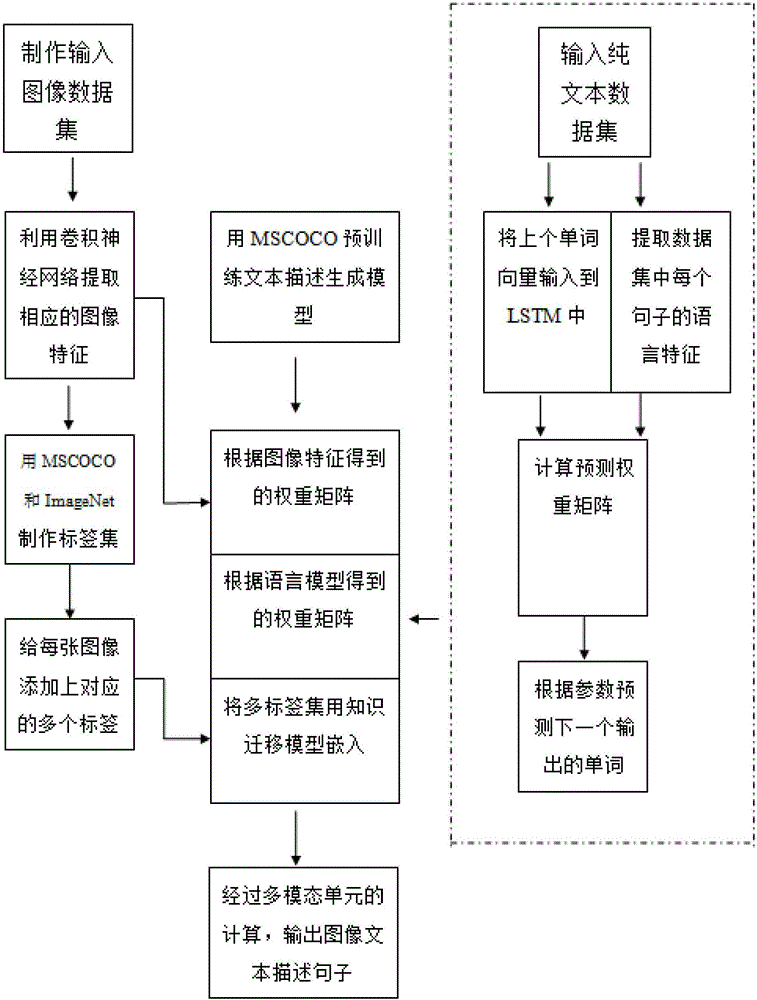
一种基于知识迁移的多模态循环神经网络的图像文本描述方法,包括以下步骤:
S1:在服务器中训练图像语义分类器;
S2:在服务器中训练语言模型;
S3:在服务器中预训练文本描述生成模型并生成描述句子。
进一步地,所述步骤S1的具体过程如下:
S11:采集多种图像数据集:下载现成的数据集,包括ImageNet和MSCOCO,由于MSCOCO是一种图像与文本描述成对匹配的数据集,取其图像部分;
S12:使用的卷积神经网络,对采集的数据集中的每一张图片提取相应的图像特征fI;
S13:制作标签集,选取1000个最常见的单词即覆盖了90%图像与文本描述成对匹配的训练集中使用到的单词,以及加上ImageNet图像分类中没有出现在成对匹配训练集中的对象的词,将两者组成需要用到的标签词库;
S14:利用上个步骤制作好的标签词库,对每张图片采用多示例学习的方法为其添加上多个视觉概念标签:
多示例学习中将各种多示例的集合定义为“包”,正包指的是包中至少有一个正示例,否则定义为负包,在这里把每张图片定义成一个包;
对于MSCOCO数据集中每一张图片,根据其数据集中五个参考文本描述去给每个图像设定相对应的标签,如果一个图像中对应的五个参考文本描述中的任意一个提到了一个标签,则认为对应的图片是一个正包,否则认为该图片是负包;对于ImageNet数据集中的每一张图片,以其本来的标签作为单独的标签。
进一步地,所述步骤S2的具体过程如下:
S21:语言模型采用三种纯文本数据集去训练即MSCOCO中的所有文本描述、Flicker1M,Flicker30K,Pascal1K中的图像文本描述、英国国家语料库和维基百科中的文本数据;
S22:将文本数据集中的单词转变成向量的形式;
S23:将文本的上一个单词作为输入,输入到一个长短期记忆模型中,让LSTM单元学习语言中的递归结构;
S24:同时将单词向量以及LSTM的输出组合起来,输出模型需要的语言特征fL。
进一步地,所述步骤S3的具体过程如下:
S31:用调整的卷积神经网络提取MSCOCO中的图像特征;
S32:将独立训练好的语言模型特征fL和S31的图像特征整合嵌入到一个含有多模态单元的循环神经网络之中;
S33:把MSCOCO数据迭代输入,预训练的文本描述生成模型;
S34:将图像语义分类器中得到的图像特征fI嵌入到多模态单元当中;
S35:将成对匹配训练集中的一些对象的概率预测权重矩阵转移到概念相似的非成对匹配训练集中的对象中即当语义分类器判定非成对匹配数据集中的一个对象与成对匹配训练集中的某个对象相似时,令它们的预测权重矩阵相同;
S36:同时要令两种相似对象预测的情况要独立,此时增加一个判定条件,对于根据图像特征的生成的权重矩阵要结合语义分类器来决定,类似bus和car,若语义分类器预测该图像为bus,则根据图像特征预测生成car的权重矩阵,使其为预测的概率为0,反之亦然;
S37:将验证集中的图片输入到图像文本描述生成模型当中,通过训练好的模型参数得到一系列单词向量以及它们对应的概率;
S38:选取概率最高的单词作为句子的首个单词;
S39:将第一个单词输入到语言模型中,经过语言模型中的LSTM计算得出的特征结合fL,再次生成一系列的单词向量以及对应的概率;
S310:选取概率最高的作为句子的第二个单词;
S311:循环重复S39和S310的工作,直至模型输出一个句子结束标志。
进一步地,所述步骤S13中制作的标签集是结合图像与文本描述成对匹配训练集的词和ImageNet图像分类中没有出现在成对匹配训练集中的对象的词。
进一步地,所述步骤S21中语言模型是通过纯文本数据集去训练的,语言模型的单词向量输出可由下列式子表示:
Pv=Ws·fL+OLSTM+b
其中Pv为单词向量的预测概率,fL为句子特征向量,OLSTM为LSTM输出向量,b为偏移量。
进一步地,所述步骤S35和S36中首先使两个相似的对象的预测权重矩阵相同,再添加一个根据图像特征的生成的权重矩阵要联合语义分类器的判定条件决定最终的预测权重矩阵。
与现有技术相比,本发明技术方案的有益效果是:
本发明方法通过多模态单元中的知识转移模型,很好地利用了现成图像分类器对大多数对象的识别能力以及现成语料库中的语法结构和语义关联性,能更准确地描述出图像中的目标对象以及使生成的句子描述语法结构更丰富,语义贴切,可读性更强。
附图说明
图1为本发明方法的总体流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种基于知识迁移的多模态循环神经网络的图像文本描述方法,包括以下步骤:
S1:在服务器中训练图像语义分类器;
S2:在服务器中训练语言模型;
S3:在服务器中预训练文本描述生成模型并生成描述句子。
步骤S1的具体过程如下:
S11:采集多种图像数据集:下载现成的数据集,包括ImageNet和MSCOCO,由于MSCOCO是一种图像与文本描述成对匹配的数据集,取其图像部分;
S12:使用卷积神经网络,对采集的数据集中的每一张图片提取相应的图像特征fI;
S13:制作标签集,选取1000个最常见的单词即覆盖了90%图像与文本描述成对匹配的训练集中使用到的单词,以及加上ImageNet图像分类中没有出现在成对匹配训练集中的对象的词,将两者组成需要用到的标签词库;
S14:利用上个步骤制作好的标签词库,对每张图片采用多示例学习的方法为其添加上多个视觉概念标签:
多示例学习中将各种多示例的集合定义为“包”,正包指的是包中至少有一个正示例,否则定义为负包,在这里把每张图片定义成一个包;
对于MSCOCO数据集中每一张图片,根据其数据集中五个参考文本描述去给每个图像设定相对应的标签,如果一个图像中对应的五个参考文本描述中的任意一个提到了一个标签,则认为对应的图片是一个正包,否则认为该图片是负包;对于ImageNet数据集中的每一张图片,以其本来的标签作为单独的标签。
步骤S2的具体过程如下:
S21:语言模型采用三种纯文本数据集去训练即MSCOCO中的所有文本描述、Flicker1M,Flicker30K,Pascal1K中的图像文本描述、英国国家语料库和维基百科中的文本数据;
S22:将文本数据集中的单词转变成向量的形式;
S23:将文本的上一个单词作为输入,输入到一个长短期记忆模型中,让LSTM单元学习语言中的递归结构;
S24:同时将单词向量以及LSTM的输出组合起来,输出模型需要的语言特征fL。
步骤S3的具体过程如下:
S31:用调整的卷积神经网络提取MSCOCO中的图像特征;
S32:将独立训练好的语言模型特征fL和S31的图像特征整合嵌入到一个含有多模态单元的循环神经网络之中;
S33:把MSCOCO数据迭代输入,预训练的文本描述生成模型;
S34:将图像语义分类器中得到的图像特征fI嵌入到多模态单元当中;
S35:将成对匹配训练集中的一些对象的概率预测权重矩阵转移到概念相似的非成对匹配训练集中的对象中即当语义分类器判定非成对匹配数据集中的一个对象与成对匹配训练集中的某个对象相似时,令它们的预测权重矩阵相同;
S36:同时要令两种相似对象预测的情况要独立,此时增加一个判定条件,对于根据图像特征的生成的权重矩阵要结合语义分类器来决定,类似bus和car,若语义分类器预测该图像为bus,则根据图像特征预测生成car的权重矩阵,使其为预测的概率为0,反之亦然;
S37:将验证集中的图片输入到图像文本描述生成模型当中,通过训练好的模型参数得到一系列单词向量以及它们对应的概率;
S38:选取概率最高的单词作为句子的首个单词;
S39:将第一个单词输入到语言模型中,经过语言模型中的LSTM计算得出的特征结合fL,再次生成一系列的单词向量以及对应的概率;
S310:选取概率最高的作为句子的第二个单词;
S311:循环重复S39和S310的工作,直至模型输出一个句子结束标志。
步骤S13中制作的标签集是结合图像与文本描述成对匹配训练集的词和ImageNet图像分类中没有出现在成对匹配训练集中的对象的词。
步骤S21中语言模型是通过纯文本数据集去训练的,语言模型的单词向量输出可由下列式子表示:
Pv=Ws·fL+OLSTM+b
其中Pv为单词向量的预测概率,fL为句子特征向量,OLSTM为LSTM输出向量,b为偏移量。
步骤S35和S36中首先使两个相似的对象的预测权重矩阵相同,再添加一个根据图像特征的生成的权重矩阵要联合语义分类器的判定条件决定最终的预测权重矩阵。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!