一种基于环境感知与用户反馈的垂直领域知识库构建方法与流程
本发明涉及计算机领域,特别是一种基于环境感知与用户反馈的垂直领域知识库构建方法。
背景技术:
目前知识库的构建方法主要采用的是通过网络爬虫,对某一网站以及其子网站进行关键内容爬取,存储到数据库中。
主要实现流程是:
(1)确定该知识库所需信息所在的URL。
(2)对该URL进行网络爬虫爬取,爬虫下载网络资源。
(3)从资源中获取该知识库所需的数据。
(4)将所获得的数据存入数据库。
(5)生成该垂直领域知识库。
环境感知技术主要的应用领域是在智能车辆的辅助驾驶领域或智能机器人等方向。目前,环境感知的传感方法主要由以下几种:
(1)雷达探测技术
雷达是一种主动式传感装置,它的优势在于能够直接给出环境深度信息,受光照的影响程度较低,能够昼夜工作。常用的雷达包括:激光雷达、超声波雷达、毫米波雷达等类型。基于雷达的环境理解方法主要有云聚类、帧匹配、特征提取和可通行区域分析等。
(2)机器视觉技术
机器视觉系统通过感知外部环境对光照的反射来获取环境信息,和雷达系统相比,机器视觉系统具有信息量大、成本低廉等优点。
(3)导航定位技术
当今,全球定位系统(GPS:Global Position System)可以为车辆实时提供准确的位置、速度、方向和加速度信息。GPS系统如配合电子地图和匹配算法一起使用,更可以获得当前道路情况、交通规划等信息。高精度差分GPS系统的定位精度可达到厘米级,并被应用于车辆定位和道路跟踪领域。
使用网络爬虫爬取数据的方法来进行构建知识库,如果所爬取的URL中所包含的子网站很多,会使得该知识库的生成周期很长,同时也会影响所爬取的信息的准确性与有效性,造成所创建的知识库很冗余。
环境感知的几种主要传感方法,都会有相应的缺点:
雷达的缺点在于视野小、价格昂贵,在某些天气如雨雪等环境中系统便无法工作。
机器视觉系统受环境影响较大,在能见度低或光照差等环境中效果不理想。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种基于环境感知与用户反馈的垂直领域知识库构建方法。
为解决上述技术问题,本发明所采用的技术方案是:一种基于环境感知与用户反馈的垂直领域知识库构建方法,包括以下步骤:
1)获取用户当前所在的位置坐标信息;
2)对所述位置坐标500米以内进行环境感知,确定该地区所属垂直领域知识库;
3)在现有的知识库中查找是否存在该垂直领域的知识库;
4)若该知识库存在,则暂定用户所在坐标所使用的知识库为步骤2)确定的垂直领域知识库;若该知识库不存在,则创建一个新的垂直领域知识库作为暂定的知识库,并进入步骤5);
5)判断暂定的知识库所包含的信息是否符合用户反馈,若符合,将该暂定的知识库在用户所在坐标的权值提升;否则,判断步骤1)所获取的用户所在坐标位置是否另外存在新的知识库,若步骤1)所获取的用户当前所在的坐标位置需要创建新的知识库,则跳转到步骤4),创建新的垂直领域知识库;若该坐标位置不存在其他知识库,则将暂定的知识库所含内容进行更新。
步骤2)中,确定垂直领域知识库的主要过程为:根据步骤1)所确定的位置坐标信息,通过地图API对所在位置周围环境进行感知,获取当前位置附近的建筑、地标名称,并进行统计汇总,将所获取的建筑、地标名称进行分词,得到地区所属垂直领域知识库。
步骤3)的具体实现过程为:搜索储存所有知识库的总数据库,遍历查找总数据库中是否存在步骤2)所述的垂直领域知识库,查找依据是所确定的垂直领域知识库名拼音,去总数据库中的knowledgeBaseList表中与kb_name进行匹配,如果有多个结果,则再次对表中的kb_location进行匹配,如果位置匹配经纬度相差值小于或等于0.005,判断为当前所在地属于的垂直领域知识库。
步骤4)中,创建新的垂直领域知识库的过程为:更新knowledgeBaseList表,在knowledgeBaseList表中添加一条新的记录,kb_id字段进行自增,kb_name字段的取值是步骤2)获取的垂直领域知识库名的中文拼音,kb_location字段的取值是将步骤1)中所获得的当前位置坐标经纬度信息转化成”经度数值,纬度数值”格式的字符串,kb_weight字段设置为初始值50;在数据库中新建一个表,用来存放该垂直领域知识库的信息资源,表的名称是字符串”kb”与knowledgeBaseList表中的该垂直领域数据项kb_id的值拼接在一起;在新建的表中插入数据,所有数据的来源是通过网络爬虫对该垂直领域知识库名的官网上进行爬取的,通过修改百度网址后面的参数进行搜索,分析搜索结果的网页的html文件,从中得到该垂直领域知识库名的官网的url,再将这个url作为网络爬虫进行信息爬取的起点,对该url以及内部的子url进行爬取,并同时将爬取的信息逐条插入到垂直领域知识库所对应的新建的数据表中。
与现有技术相比,本发明所具有的有益效果为:本发明采用了环境感知与用户反馈来创建垂直领域知识库,使得所创建某一垂直领域知识库所包含内容更加丰富,同时采用的构建方法成本低廉,节省了创建垂直领域知识库的开销,提高了垂直领域知识库的精确性。
附图说明
图1为本发明方法流程图。
具体实施方式
本发明所提出的垂直领域知识库的构建方法是将大量的垂直领域知识库都会存放在一个总数据库中。
首先,这个大型数据库需要一个表来对所有垂直领域知识库名进行存储,使用knowledgeBaseList命名该表,knowledgeBaseList表所设计的结构如表1:
表1 knowledgeBaseList表结构
在这个垂直领域知识库的总数据中的其他表均为存放每单个的知识库的数据,使用该垂直领域知识库在knowledgeBaseList表中对应的kb_id与kb拼接来作为每一个表的表名,如”kb1”,予以区分不同的垂直领域知识库,这样可以很有效的避免因为使用拼音的英文来为知识库命名而造成的同名的错误。存放每一个垂直领域知识库的表结构如表2:
表2 单个垂直领域知识库表结构
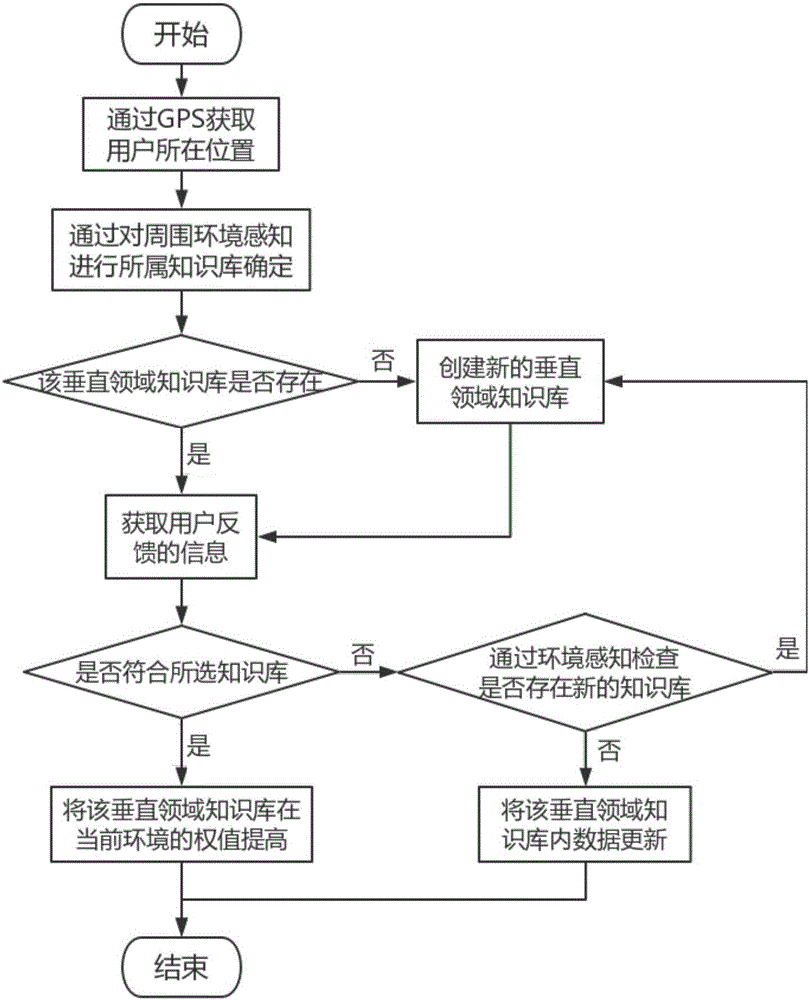
本发明所提出的一种基于环境感知与用户反馈的垂直领域知识库构建方法的主要流程如图1。
具体的实现步骤如下:
(1)通过GPS获取用户当前所在的位置坐标信息
通过Android系统自带的GPS系统,使用onLocationChanged()方法的参数中由系统给予的Location位置对象进行坐标获取,可以有效的避免了由于GPS定位不成功而造成的空指针异常,进而获取到用户所在位置的经度纬度、国家、省份、城市等信息,行精确地定位。
(2)对该坐标附近进行环境感知,确定该地区所属垂直领域知识库名
根据步骤(1)所确定的位置信息,通过第三方所提供的地图API对所在位置周围环境进行感知,获取当前位置附近的建筑、地标等名称,并进行统计汇总。如:k大学图书馆、k大学第一办公楼、k大学学生公寓……讲这些所获取的周围环境名称进行分词,便可以得到以下结果:k大学(3次)、图书馆、第一办公楼、学生公寓等。对这个分词结果进行分析便可以得出该地区是属于k大学,便可以确定用户当前坐标所属的知识库是k大学的垂直领域知识库。
(3)在现有的知识库中查找是否存在该垂直领域的知识库
通过搜索储存现所有知识库的总数据库,遍历查找总数据库中是否存在前一步骤所确定的当前坐标位置的垂直领域知识库。查找依据是所确定的库名拼音的英文,去数据库中的knowledgeBaseList表中与kb_name进行匹配,如果有多个结果,则再次对表中的kb_location进行匹配,如果位置匹配经纬度相差值小于等于0.005,判断是否为当前所在地属于的垂直领域知识库。
(4)若该知识库存在,则暂定用户所在坐标所使用的知识库
若在总数据库中找到了一致的垂直领域知识库,则暂定当前坐标位置所使用的垂直领域知识库便是通过步骤(2)所确定的知识库,进而用户可以在该地区从所确定的垂直领域知识库中获取自身需要的相关信息。
(5)若该知识库不存在,创建一个新的垂直领域知识库
若在总数据库中没有找到一致的垂直领域知识库,则在总数据库中创建一个新的垂直领域知识库。创建新的知识库的步骤如下:
首先更新knowledgeBaseList表。在表knowledgeBaseList中添加一条新的记录,kb_id字段进行自增,kb_name字段的取值是步骤(2)获取的知识库名的中文拼音,kb_location字段的取值是将步骤1)中所获得的当前位置坐标经纬度信息转化成”经度数值,纬度数值”格式的字符串,kb_weight字段设置为初始值50。
在数据库中新建一个表,专门用来存放该垂直领域的信息资源。表的名称是字符串”kb”与knowledgeBaseList表中的该垂直领域数据项kb_id的值拼接在一起(如”kb105”),并在新建表的时候赋予四个字段:
1.knowledge_id,int(16),not null,primary key,auto_increment
2.knowledge_content,varchar(50),not null
3.knowledge_type,varchar(10),not null
4.knowledge_remark,varchar(50),not null
还需要向这个刚刚进行初始化的数据库表中插入数据,所有数据的来源是通过网络爬虫对该垂直领域名称的官网上进行爬取的。可以通过修改百度网址后面的参数进行搜索,分析搜索结果的网页的html文件,从中可以得到该名称垂直领域的官网的url。再将这个url作为网络爬虫进行信息爬取的起点,对该url以及内部的子url进行爬取,并同时将爬取的信息逐条插入到新建的垂直领域知识库所对应的的数据表中。
(6)在暂定的知识库所包含信息中查询是否符合用户反馈
当用户通过语音等其他方式在当前所在位置进行信息检索的时候,对用户的问题进行分词,并将分词的所得结果中的语气词排除掉,剩下的关键信息便会在暂定的垂直领域知识库中的信息判断是否可以找到用户所需要的信息。
(7)若暂定的知识库符合用户反馈,将该知识库在用户所在坐标的权值提升
如果步骤(5)中用户反馈进行信息检索等操作都可以在当前所确定的垂直领域知识库中得到相应的信息,那么即可以确定该垂直领域知识库就是符合当前坐标位置的一个知识库。所以便将总数据库中knowledgeBaseList表中该垂直领域知识库对应的记录的kb_weight字段的值上升0.1,从而达到将该垂直领域知识库在该坐标位置权值的提升的效果。如果在同一个地点存在多个类似的垂直领域知识库,便可以通过对它们各自权值的判断来进行选取,减少了错误率。
(8)若暂定的知识库不符合用户反馈,通过环境感知的方法判断该坐标位置是否另外存在新的知识库
若暂定使用的垂直领域知识库不能满足用户的反馈,那么就要重新判断是否选择了错的知识库,或者在该位置有其他没有被记录的知识库。因为步骤(2)是根据分词结果中最大出现频率的词作为该垂直领域知识库的名字,进行知识库再确定的时候会选择出现频率次之的分词结果到表knowledgeBaseList中进行检索,如果仍不存在,便会在表knowledgeBaseList中对当前所在坐标进行检索,根据坐标位置判断周围是否有其他知识库。如果这两种检索的结果都是为空,则判断需要在该坐标位置创建新的垂直领域知识库。
(9)若该坐标位置需要创建新的知识库,则跳转到步骤(5),创建新的垂直领域知识库
(10)若该坐标位置不存在其他知识库,将暂定的知识库所含内容进行更新
如果步骤(9)的判断结果是该坐标附近不存在其他垂直领域知识库,便需要对当前所使用的知识库进行更新。将用户所反馈的信息作为该知识库表中的knowledge_content字段的内容向该表中新插入一条数据,并在knowledge_remark字段内容设置成feedback,予以区分知识库通过网络爬取而获得的资源和通过用户反馈进行更新的资源。
- 还没有人留言评论。精彩留言会获得点赞!