基于决策树方法的蒸汽管网调度规则系统与流程
本发明属于蒸汽管网调度规则技术领域,特别是提供一种基于决策树方法的蒸汽管网调度规则系统,实现了蒸汽管网调度规则的程序化,科学化。
背景技术:
在大型联合钢铁企业里,蒸汽系统是具有大时滞、大惯性、变参数、非线性、多变量耦合等特点的复杂对象,面对这样的复杂运行状况,管理人员基本还是依靠多年来的生产所运行积累下的经验指挥系统运行,难以避免发生放空、降质使用等情况,造成极大的浪费。这样必然导致调度的盲目性和管网运行的低效。同时由于生产量、季节性变化等原因蒸汽用量会随之发生变化,对蒸汽系统的优化调度与管理是相关企业节能增效减少环境污染的有效措施。建立基于决策树的调度规则库,结合企业调度规则库,合理优化蒸汽管网调度,可大大降低人工调度的盲目性和滞后性,从而提高蒸汽系统调度水平。
决策树算法是一种以决策树这种数据结构为基础的分类算法。决策树是一个类似于流程图的树结构,其中每个内部结点表示一个属性上的测试,每个分枝代表一个测试输出,而每个树叶结点代表一个类或类分布。在给未知的样本分类时,由树根开始对该样本中对象的属性按照顺序逐个测试其值,并且沿着符合条件的分枝向下走,直至到达某个叶结点,这个叶结点代表的类则为该对象所属的类。基于决策树方法,建立钢铁企业蒸汽管网调度规则决策树系统。根据决策树原理的系统熵及决策属性等方法,结合现有企业调度规则库、专家知识库以及事实库,以典型的决策树ID3算法建立钢铁企业蒸汽管网调度规则决策树系统,使得管网调度策略更加合理安全,有效降低管网波动范围
本发明将建立一种科学的蒸汽管网调度规则系统,可科学合理的建立蒸汽管网调度规则系统,减少管网波动,保障管网高效安全运行。
技术实现要素:
本发明的目的在于提供一种基于决策树方法的蒸汽管网调度规则系统,实现了蒸汽管网调度规则的程序科学化,使得管网运行更加科学合理。系统采用自顶向下递归的分治方式来构建,从训练样本集以及与其相关的属性开始构造。随着决策树的不断深层次构造,训练样本集将递归地被划分为几个较小的子集。树根与各节点之间的路径对应着一条关联规则,因此整个决策树也就对应着一组完整的关联规则。
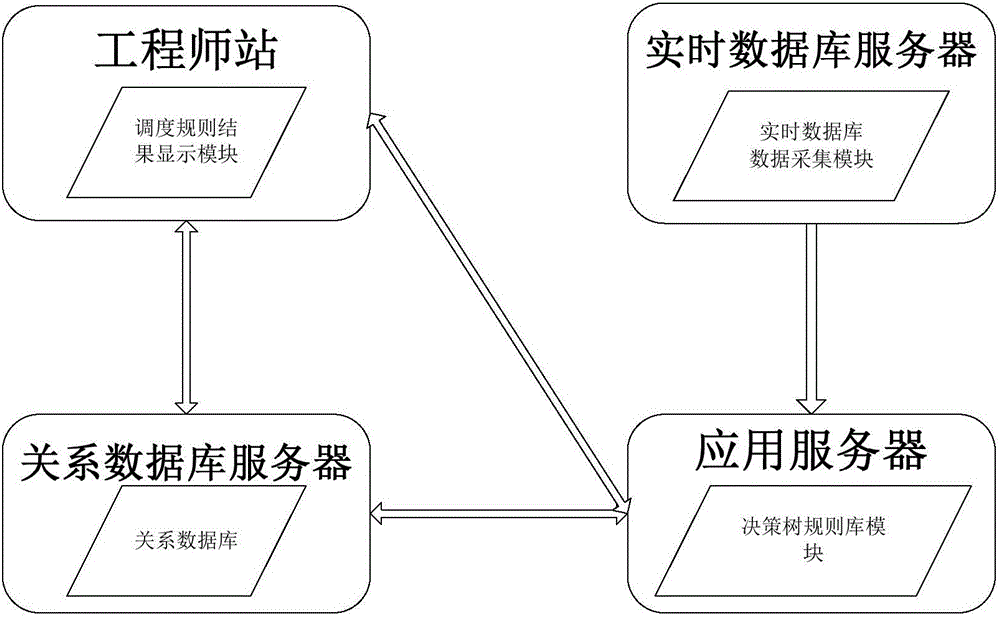
本发明硬件系统包括关系数据库服务器,实时数据库服务器,应用服务器,工程师站。关系数据库服务器与工程师站和应用服务器相连,应用服务器除与关系数据库服务器相连外,还与实时数据库和工程师站相连,保持三者之间数据交换。应用模块包括关系数据库,数据采集模块,调度规则结果显示模块,决策树规则库生成模块。其中调度规则结果显示模块部署在工程师站,决策树规则库模块部署在应用服务器,关系数据库部署在关系数据库服务器,数据采集模块部署在实时数据库。
关系数据库是显示模块与决策树规则库模块之间的数据通讯媒介。决策树规则库模块将生成的决策规则写入关系数据库,显示模块再从关系数据库中读出并予以显示。
关系数据库:存储用于调度记录、决策树规则库、显示的数据。
数据采集模块:由实时数据库和现场采集仪表以及传输网络组成;现场采集仪表将信息实时传入实时数据库中;
调度规则结果显示模块:数据接口部分,为决策树算法提供数据输入功能,包括读取数据文件;
决策树规则库模块:包括1、树根是从代表训练样本集的单个节点开始的;2、训练样本集属于同一个类的节点为树叶,并对该类进行标记;3、否则以信息增益度量为分裂准则,选择可以实现最好地样本分类的属性作为该节点的分裂属性;4、为分裂属性的每个已知值创建一个分枝,并以此为依据划分样本集;5、使用上述同样的过程,递归地形成每个划分的样本决策树。一旦某个属性出现在某个节点上,则其后代就不必再考虑了;6、当满足下列条件之一时,递归划分步骤停止:a)给定节点的所有样本集同属一个类;b)没有剩余属性可以用来对样本进行进一步的划分;c)分枝中无样本。
1、数据集划分前的熵:
对于有s个数据样本集合S,其中分类属性C有m个不同的离散取值c1,c2,…,cm(即数据样本S最终要被分成m个类别)。分类属性值为c1,c2,…,cm的样本数分别s1,s2,…,sm。那么划分之前,样本集S的总熵(期望信息)为:
其中,pi是S集中任意一个样本属于类别Ci的概率,并用si/s估计。注意,对数函数以2为底,因为信息用二进制编码。容易看出,数据集S的总熵在划分前是属于不同类别的样本的信息量的加权平均。
2、数据集划分后的熵:
设属性A有n个不同的离散属性值{a1,a2,…,an},可使用属性A将数据集S划分为n个子集{s1,s2,…,sn},对应每个子集Sj中所有样本的属性A都是aj。
设子集Sj中的全部样本数为sj,其中分类属性值为c1,c2,…,cm的样本数为s1j,s2j,…,smj,则子集Sj的熵为:
其中pij=sij/sj,是Sj中样本分别属于类别Ci的概率。
使用属性A把数据集S划分成n个子集后,S的总熵为n个子集的熵的加权平均:
其中为Sj子集的权重,表示sj子集在数据集S中的比重。
信息增益:
信息增益表示系统由于分类获得的信息量,由系统熵的减少量度,定义数据集S按属性A划分后的信息增益为S划分前后的熵差:
Gain(A)=I(s1,s2,…,sm)-E(A)
算法计算每个属性的信息增益,然后选择具有最高信息增益的属性作为给定数据集S的决策属性,创建一个结点,并以该属性标记,对属性的每个值创建分枝,并据此划分样本。
3、ID3算法
ID3算法是基于信息增益的典型决策树算法,通过自顶向下递归的分治方式构造决策树来进行学习。其具体方法是对所有的候选属性进行测试,选择信息增益最大的属性作为最佳分裂属性,并以此分裂属性作为决策树的根结点,通过该属性的不同取值构造分支,然后对各分支的子集不断重复上述方法,并依次构造决策树结点的其它分支,一直到所有的子集合只包括同类别的训练样本集为止。最终所得到的ID3决策树模型就可以对新的数据样本集进行分类和预测。属性皆为离散型,或数值属性事先经过预处理转化成离散型。
假设用T代表当前样本集,当前候选属性集用T_attributelist表示,候选属性集中所有属性皆为离散型,或数值属性事先经过预处理转化成离散型。则ID3算法ID3formtree(T,T_attributelist)的流程具体描述如下:
步骤一:创建根节点N;
步骤二:如果T都属于同一类C,则返回N为叶节点,标记为类C;
步骤三:如果T_attributelist为空,则返回N为叶节点,标记N为T中出现最多在类;
步骤四:对每一个T_attributelist中的属性,计算信息增益gain;
步骤五:N的测试属性test_attribute=T_attributelist具有最高gain值的属性;
步骤六:对每一个test_attributelist的取值,由节点N一个新的叶子节点,且如果新叶子节点对应的样本子集T为空,则不分裂此叶子节点,将其标记为T中出现最多在类;否则在该叶子节点上执行ID3formtree(T,T_attributelist),继续对它分裂;
本发明的优点在于:基于决策树方法建立蒸汽管网调度规则系统,实现管网调度的规则化,科学化,保证管网运行安全高效,提高运行效率,为企业节能减排。
附图说明
图1是本发明系统各模块之间关系图。
图2是决策树规则求解流程图。
图3是并行求解方程组过程图。
具体实施方式
本发明硬件系统包括关系数据库服务器,实时数据库服务器,应用服务器,工程师站。关系数据库服务器与工程师站和应用服务器相连,应用服务器除与关系数据库服务器相连外,还与实时数据库和工程师站相连,保持三者之间数据交换。应用模块包括关系数据库,数据采集模块,调度规则结果显示模块,决策树规则库生成模块。其中调度规则结果显示模块部署在工程师站,决策树规则库模块部署在应用服务器,关系数据库部署在关系数据库服务器,数据采集模块部署在实时数据库。
关系数据库是显示模块与决策树规则库模块之间的数据通讯媒介。决策树规则库模块将生成的决策规则写入关系数据库,显示模块再从关系数据库中读出并予以显示。
图1是发明系统各模块之间关系图。本发明系统包括关系数据库,数据采集模块,调度规则结果显示模块,决策树规则库生成模块。其中调度规则结果显示模块部署在工程师站,决策树规则库生成模块部署在应用服务器,关系数据库部署在关系数据库服务器,数据采集模块部署在实时数据库。关系数据库是调度规则结果显示模块与决策树规则库生成模块之间的数据通讯媒介。决策树规则库生成模块将生成的规则库写入关系数据库,显示模块再从关系数据库中读出并予以显示。
图2是决策树规则求解流程图。首先创建根节点N,判断如果T都属于同一类C,则返回N为叶节点,标记为类C;然后判断如果T_attributelist为空,则返回N为叶节点,标记N为T中出现最多在类;其次对每一个T_attributelist中的属性,计算信息增益gain;N的测试属性test_attribute=T_attributelist具有最高gain值的属性;最后对每一个test_attributelist的取值,由节点N一个新的叶子节点,且如果新叶子节点对应的样本子集T为空,则不分裂此叶子节点,将其标记为T中出现最多在类;否则在该叶子节点上执行ID3formtree(T,T_attributelist),继续对它分裂。
- 还没有人留言评论。精彩留言会获得点赞!