一种基于浏览器的高性能用户追踪方法与流程
本发明属于信息收集技术领域,尤其涉及一种基于浏览器的高性能用户追踪方法。
背景技术:
随着用户隐私安全意识越来越高,以及Cookie暴漏的安全问题也随之增长,用户通过安装插件或者禁用Cookie等方法来保护个人隐私。Canvas指纹技术是虽然能有效的追踪一个用户,由于Canvas渲染技术是基于用户的硬件设备,所以该技术有一个很高的碰撞率。对于一些恶意攻击者,通过VPS或者其他加密代理的方式来隐藏自己的信息,使得追踪和识别变得更加困难。传统的分析日志的方式只能对攻击事件进行分析,并不能有效的追踪恶意攻击者,用户的追踪和识别依旧非常艰难。EFF提出的Browser Fingerprint指纹识别技术能够有效且唯一地识别用户的浏览器特征信息,但是在追踪用户方便并不高效。
技术实现要素:
本发明要解决的技术问题是,提供一种基于浏览器的高性能用户追踪方法。
为解决上述问题,本发明采用如下的技术方案:
一种基于浏览器的高性能用户追踪方法包括以下步骤:
步骤1、获取用户浏览器特征信息,生成相应的Fingerprint指纹值,并将所述用户浏览器特征信息以及相应的Fingerprint指纹值发送到相应的后台服务器;
步骤S2、根据所述用户浏览器特征信息以及相应的Fingerprint指纹值,依据策略性指纹识别方法对得到的相应数据进行关联处理;
步骤S3、将关联后的用户客户端信息存储到Redis数据库,使用过滤识别方式对新的指纹数据进行处理,判定两个指纹信息是否相关联。
作为优选,用户浏览器特征的信息包括浏览器本身的特征信息以及浏览器所在终端的信息;浏览器本身的特征信息包括:浏览器UA、语言Language、使用字体Font、安装插件Plugins、Cookie和Canvas信息、浏览器所属的平台Platform、HTML5的本地存储机制Local_stroage和Session_stroage、是否允许追踪Do Not Track等;浏览器所在终端的信息包括:公网和内网IP;色彩深度Color_depth;时区Time_zone;屏幕分辨率Resolution等。
作为优选,步骤S2中通过fingerprint值、cookie和canvas、内网IP和外网IP三组唯一标识用户的方式来对指纹信息进行关联性的比对判断。
作为优选,步骤S3中,当出现新的指纹信息,先将其与redis数据库中已被识别的指纹进行比对,若存在则可直接存入相应的数据库,若不存在则重新与所有指纹进行策略性识别关联比对。
作为优选,如果不能通过fingerprint值、cookie和canvas、内网IP和外网IP三组唯一标识用户的方式来对指纹信息进行关联性的比对判断,则需要对剩余的特征信息进行进一步的判别分析,具体为:对于特征信息值长度较短的直接进行字符串比对;使用Difflib库对特征信息值长度较长的进行字符串相似比较,通过Difflib库的ratio()函数求得特征信息值的相似度值,若该相似度值在特征对应的阈值范围内,则认为特征信息相同;结合计算比较的结果与对应权重值相乘,可得出两条指纹最终的指纹相似度值;将所述指纹相似度值与浏览器指纹的相似度阈值进行比对,在阈值范围内的指纹相似度值则表明其所代表的两条指纹来自于同一浏览器。
作为优选,利用德尔菲方法给每个浏览器特征信息设定权重,得出最终的权重值。
本发明为了实现有效追踪用户,收集用户浏览器特征的信息,并在大批量的用户浏览器特征信息中高效地识别出因浏览器特征信息改变生成的不同的Fingerprint值,同时采用策略性的识别方法,依托于一个搭建在公网服务器上的一个站点,主要负责收集用户的浏览器特征信息,对不同阶段的有改变的指纹进行有效的关联和识别,以实现高性能用户追踪。
本发明用户追踪方法,通过网站收集中用户的浏览器特征信息,并发送至网站后台;使用策略性识别算法对收集到的数据进行关联分析,本发明的策略性识别算法使用德尔菲方法给每个浏览器特征设定权重;在特征信息的比对中,对特征信息值较短的字符串进行直接比对,通过Difflib对较长的特征信息值字符串进行相似性比对,针对同一浏览器在比较的特征信息值上可能有的范围内的变化进行定性测试,以此求得每一项对应的阈值,通过Difflib库的ratio()函数求得特征信息值的相似度值,若该相似度值在特征对应的阈值范围内,则认为特征信息相同;结合计算比较的结果与对应权重值相乘,可得出两条指纹最终的指纹相似度值;最后针对所有的浏览器特征信息项,界定两个以下(包含两个)的特征信息值不一致为同一浏览器指纹,并对所有的浏览器信息值进行定性的升级或伪造测试,对所有测得的指纹相似度值求平均值,设定为整个浏览器指纹的相似度阈值;将上一步求得的指纹相似度值与得到的相似度阈值进行比对,在阈值范围内的指纹相似度值则表明其所代表的两条指纹来自于同一浏览器;当收集到新的指纹时,通过在已识别出的指纹中进行过滤识别,若没有匹配,则继续使用策略性识别算法与所有的指纹进行相似关联分析。本发明能够实现高效地判定两个指纹信息是否相关联。
附图说明
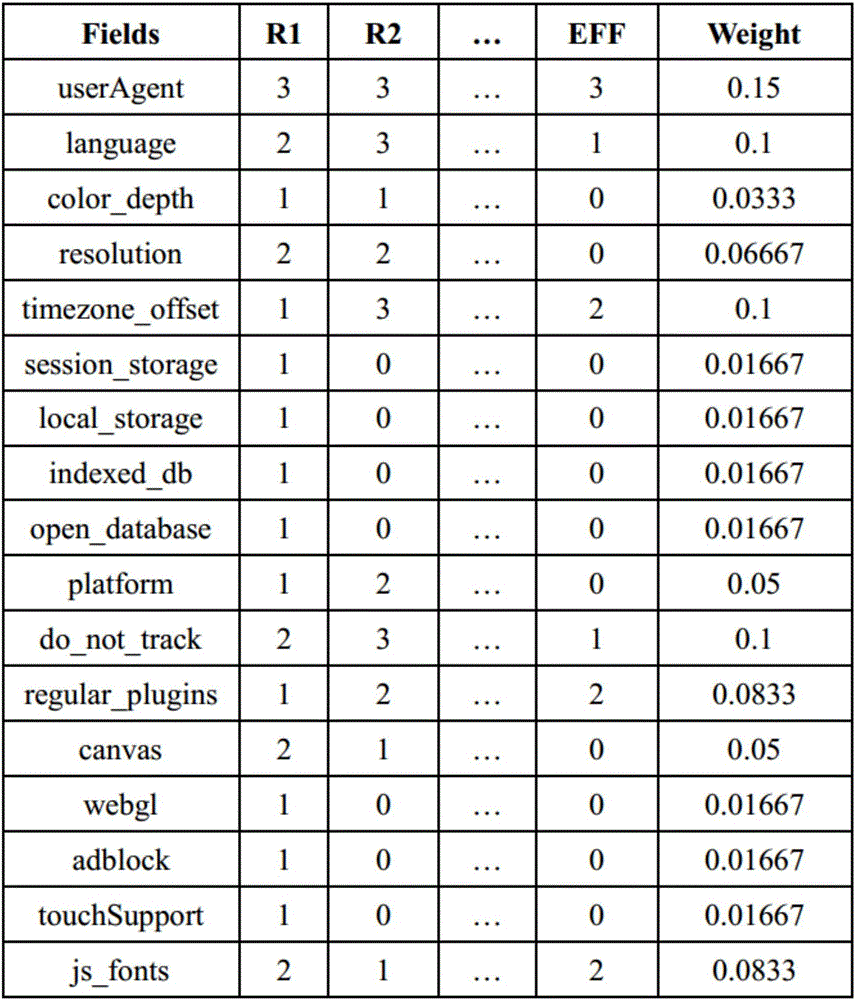
图1是本发明实施方式中基于德尔菲方法计算权重的结果示意图;
图2是本发明实施方式中的一些浏览器特征项信息的展示示意图;
图3是本发明实施方式中策略性识别算法中的核心比对算法;
图4是本发明实施方式中用户追踪的框架示意图。
具体实施方式
以下将结合附图所示的具体实施方式对本发明作进一步详细说明。
本发明实施例提供一种基于浏览器的高性能用户追踪方法,包括以下步骤:
步骤1、获取用户浏览器特征信息,生成相应的Fingerprint指纹值,并将所述用户浏览器特征信息以及相应的Fingerprint指纹值发送到相应的后台服务器;
步骤S2、根据所述用户浏览器特征信息以及相应的Fingerprint指纹值,依据策略性指纹识别方法对得到的相应数据进行关联处理;
步骤S3、将关联后的用户客户端信息存储到Redis数据库,使用过滤识别方式对新的指纹数据进行处理,判定两个指纹信息是否相关联。
步骤1具体为:
采用JavaScript语言技术获取用户浏览器的特征信息。用户浏览器特征的信息包括浏览器本身的特征信息以及浏览器所在终端的信息;浏览器本身的特征信息包括:浏览器UA、语言Language、使用字体Font、安装插件Plugins、Cookie和Canvas信息、浏览器所属的平台Platform、HTML5的本地存储机制Local_stroage和Session_stroage、是否允许追踪Do Not Track等;浏览器所在终端的信息包括:公网和内网IP;色彩深度Color_depth;时区Time_zone;屏幕分辨率Resolution等。关于浏览器特征信息的收集功能都被写在Fingerprint.js脚本中。
通过在VPS上搭建测试网站,将信息收集功能脚本加载到网站上。当用户浏览该网站的时候,JavaScript脚本对浏览器特征信息进行收集,使用murmurhash算法对特征信息进行哈希生成一个指纹值,即浏览器指纹。网站前端将所有信息回传到后台服务器,并存入数据库。
步骤2具体为:
在后台服务器对接收到的所有用户浏览器指纹信息进行关联分析,整个关联处理包括:
利用德尔菲法设定权重
因浏览器的不同特征对指纹处理造成的影响不一,因此需要给每一个参与后续相似比较的浏览器特征设定权重,对这些项的重要程度进行定量分配,本发明利用德尔菲方法给每个浏览器特征信息设定权重,具体为:根据Web安全专家对浏览器的特征进行打分,并在第一轮打分完成后对每个进行反馈和探讨,然后再进行下一轮的打分,通过几轮打分后,将几轮打分得到的平均值与EFF对采集到的用户数据的统计信息结合进行求平均值计算,得到最终的值即为权重值。
策略性识别算法
对两条指纹信息进行关联分析,首先对由特征信息生成的fingerprint值进行比对,fingeprint值具有唯一性,如果两个值相等,则认定两条指纹属于同一个用户。如果fingerprint值不相等,利用Cookie和Canvas,内网IP和外网IP两个组合对指纹进行判定,因为两个组合的值均具有唯一性,由此可以判断两条指纹是否来自同一个客户端。如果以上均不能判别成功,则需要对剩余的特征信息进行进一步的判别分析。
对每两条比对的指纹信息新建一个列表,对于浏览器特征中信息值长度较短项(例如图2中的Platform项),使用直接字符串比较的方法进行比对,若相等,则列表中的相应位置放数值1,若不等,则为0。对长度较长的特征信息值(例如图2中的User Agent项),Regular Plugins和Fonts等,则利用Difflib库来进行比对,针对同一浏览器在比较的特征信息值上可能有的范围内的变化进行定性测试,以此求得每一项对应的阈值,如果两个特征信息比较的值,即Difflib库的ratio()函数值小于该特征信息的相应的阈值则认为不相等,列表中相应位置放0,反之为1;最后得到的列表形式为[1,0,1,1,…]。结合计算比较的结果与对应权重值相乘,可得出两条指纹最终的指纹相似度值;最后针对所有的浏览器特征信息项,界定两个以下(包含两个)的特征信息值不一致为同一浏览器指纹,并对所有的浏览器信息值进行定性的升级或伪造测试,对所有测得的指纹相似度值求平均值,设定为整个浏览器指纹的相似度阈值;将上一步求得的指纹相似度值与得到的相似度阈值进行比对,在阈值范围内的指纹相似度值则表明其所代表的两条指纹来自于同一浏览器。
步骤S3具体为:
将所有已经关联的指纹信息存储到redis数据库中,并按fingerprint值,cookie值以及IP等几个分类进行存储。当出现新的指纹信息,先将其与redis中已被识别的指纹进行比对,若存在则可直接存入相应的数据库,若不存在则重新与所有指纹进行比对。
如图1所示,在本发明的实施方式中,收集的用户浏览器特征表中Fields所示。通过使用murmurhash方法对浏览器特征项进行哈希运算,生成唯一的fingerprint值。
利用德尔菲方法,由特定的专家按照既定的程序对所有浏览器的特征进行打分,在第一轮打分完成后,对每一个专家进行交流反馈。然后进行第二轮的特征打分,如此往复几轮,使专家小组的意见趋于集中。结合电子前哨基金会(EFF)的关于用户更改浏览器特征的数据分析,求得专家评分与EFF数据评定的平均值,得出最后特征的权重值。
图2展示了浏览器指纹中的几个特征项的信息,可以利用这些信息对不同的指纹信息进行关联分析。
首先对两条指纹信息的fingerprint值进行比较,因为fingerprint值是唯一的,如果两者相等,则认为两条指纹是同一个客户端。否则继续对cookie进行比较,cookie也具有唯一性,可以作为用户的唯一标识来进行判断,如果两个cookie值相等则认为指纹来自同一个客户端。在用户禁用cookie的前提下,使用canvas作为唯一标识进行比较,canvas指纹虽然有高碰撞率,但结合cookie的状态依旧可以作为唯一标识来进行比对。
如果以上两项唯一标识的比较依旧不同,则结合内外网IP进行比对,即publicIP和intranetIP。用户可能通过配置VPN或者加密代理浏览网站,所以publicIP不能作为用户的唯一识别标识。WebRTC漏洞可暴漏用户的内网IP,其功能相当于ipconfig/all命令。用户的网络环境大不相同,所以内外网IP的组合具有唯一性。
图3展示了在以上判定均失败的情况下,利用剩余的特征(即图1中的特征项)对两条指纹进行相似关联分析的伪代码。
在比较之前新建一个列表存储比较后的结果,对于特征的信息字符串长度比较短的项,使用直接字符串比较的方法。如果两个字符串相等,则将值1放到列表中相应的位置,否则该位置我0。对于特征的信息字符串较长的项,对其使用difflib模块进行比较,每项特征会有自己的阈值,如果两条指纹的项difflib求得的值小于相应的阈值,则相应位置为0,否则为1。
如图4所示,本发明的实验环境为搭建在公网的网站,用户在浏览网站的时候,其浏览器特征信息被收集并发送到网站后台存入到MySQL数据库,通过策略性识别算法关联分析的指纹信息按特征存入到Redis数据库,当新的指纹信息被传到后台时,新信息会先和存放在Redis中的指纹进行比较,即过滤识别。如果不存在相等的项,则与MySQL数据库中所有的指纹信息进行关联判断。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!