一种检测方法和装置与流程
本发明涉及通信领域,更具体的说,涉及一种检测方法和装置。
背景技术:
随着计算机技术的快速发展和互联网的应用范围的不断扩大,多媒体信息的传播成为了文化传播的重要形式,大量视频、音频、动画等多媒体文件的编码和播放成为了技术人员研究的热点。由于固态存储器与动画编辑器flash动画能够实现较好的动画效果,且其文件占用空间较小,经常使用互联网传播flash文件。
当flash文件通过互联网传播时,黑客常常将恶意代码嵌入到flash文件中,然后通过互联网传播该恶意代码,此种方法攻击性强,已经对我国的金融行业、能源行业、政府、电力行业等造成了一定的恶劣影响,所以检测flash文件中是否携带有恶意代码就变得至关重要。
现有技术中,采用特征码和人工规则的识别方法来检测flash文件中是否携带有恶意代码,特征码和人工规则的识别方法是指人工规定一些特定的恶意的字节,然后在flash文件中的特定位置,查看是否包含有人工规定的那些恶意的字节,如果包含有人工规定的那些恶意的字节,就证明包含有恶意代码,即该flash文件是恶意文件。
在计算机中存储代码时,存储的是其二进制的形式,即恶意的字节是恶意代码的二进制的形式。黑客常常在保证该恶意的字节对应的具有字符串形式的代码不变的前提下,通过修改恶意的字节的形式,如采用加一减一法修改恶意的字节的形式,来使形式改变后的恶意的字节不被检测到。此时,由于恶意的字节的形式已经被改变,采用特征码和人工规则的识别方法,来检测人工规定的那些恶意的字节时,就不会检测到形式改变后的恶意的字节,进而就不能判断flash文件是否是恶意文件。
因此,亟需一种能够在恶意的字节的形式改变后,仍能够判断flash文件是否是恶意文件的方法。
技术实现要素:
有鉴于此,本发明提供一种检测方法和装置,以解决采用特征码和人工规则的识别方法来检测flash文件中是否携带有恶意代码时,在恶意的字节的形式改变时,不能判断flash文件是否是恶意文件的问题。
为解决上述技术问题,本发明采用了如下技术方案:
一种检测方法,包括:
判断获取的目标文件是否是固态存储器与动画编辑器flash文件;
当判断出所述获取的目标文件是flash文件,将所述目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码;
将位于所述具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码;
判断所述待解析代码中是否包含有预设的恶意特征中的至少一个恶意特征;
当判断出所述待解析代码中包含有预设的恶意特征中的至少一个恶意特征,根据所述待解析代码中包含的每一个恶意特征中的待解析字符串,得到与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值;
根据与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断所述目标文件是否是恶意文件。
优选地,所述判断获取的目标文件是否是固态存储器与动画编辑器flash文件,包括:
采用文件格式识别方法识别所述目标文件的文件类型,判断所述文件类型是否是flash文件的文件类型。
优选地,所述将位于所述具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码,包括:
查找位于所述具有字符串形式的代码中的预设位置中的每个位置的代码;
将所述每个位置的代码提取出来,得到待解析代码。
优选地,
所述预设的恶意特征包括名称特征、恶意行为特征或数据拼接特征;
相应的,所述根据所述待解析代码中包含的每一个恶意特征中的待解析字符串,得到与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,包括:
当所述待解析代码中包含所述名称特征时,根据与所述待解析代码中包含的所述名称特征相匹配的字符串为正常字符串的概率,得到与所述名称特征对应的、能够表示所述名称特征的恶意程度的数值;
当所述待解析代码中包含所述恶意行为特征时,根据所述待解析代码中包含的所述恶意行为特征中的每个特征出现的次数,得到与所述恶意行为特征对应的、能够表示所述恶意行为特征的恶意程度的数值;
当所述待解析代码中包含所述数据拼接特征时,根据所述待解析代码中包含的所述数据拼接特征出现的次数,得到与所述数据拼接特征对应的、能够表示所述数据拼接特征的恶意程度的数值。
优选地,所述根据与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断所述目标文件是否是恶意文件,包括:
根据与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,计算得到所述目标文件为恶意文件的概率;
根据所述概率,判断所述目标文件是否是恶意文件。
一种检测装置,包括:
第一判断单元,用于判断获取的目标文件是否是固态存储器与动画编辑器flash文件;
转换单元,用于当所述第一判断单元判断出所述获取的目标文件是flash文件,将所述目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码;
提取单元,用于将位于所述具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码;
第二判断单元,用于判断所述待解析代码中是否包含有预设的恶意特征中的至少一个恶意特征;
特征提取单元,用于当所述第二判断单元判断出所述待解析代码中包含有预设的恶意特征中的至少一个恶意特征,根据所述待解析代码中包含的每一个恶意特征中的待解析字符串,得到与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值;
第三判断单元,用于根据与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断所述目标文件是否是恶意文件。
优选地,所述第一判断单元,包括:
第一判断子单元,用于采用文件格式识别方法识别所述目标文件的文件类型,判断所述文件类型是否是flash文件的文件类型。
优选地,所述提取单元包括:
查找单元,用于查找位于所述具有字符串形式的代码中的预设位置中的每个位置的代码;
提取子单元,用于将所述每个位置的代码提取出来,得到待解析代码。
优选地,
当所述预设的恶意特征包括名称特征、恶意行为特征或数据拼接特征时,
所述特征提取单元包括:
第一特征提取单元,用于当所述第二判断单元判断出所述待解析代码中包含所述名称特征时,根据与所述待解析代码中包含的所述名称特征相匹配的字符串为正常字符串的概率,得到与所述名称特征对应的、能够表示所述名称特征的恶意程度的数值;
第二特征提取单元,用于当所述第二判断单元判断出所述待解析代码中包含所述恶意行为特征时,根据所述待解析代码中包含的所述恶意行为特征中的每个特征出现的次数,得到与所述恶意行为特征对应的、能够表示所述恶意行为特征的恶意程度的数值;
第三特征提取单元,用于当所述第二判断单元判断出所述待解析代码中包含所述数据拼接特征时,根据所述待解析代码中包含的所述数据拼接特征出现的次数,得到与所述数据拼接特征对应的、能够表示所述数据拼接特征的恶意程度的数值。
优选地,所述第三判断单元包括:
计算单元,用于根据与所述每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,计算得到所述目标文件为恶意文件的概率;
第四判断单元,用于根据所述概率,判断所述目标文件是否是恶意文件。
相较于现有技术,本发明具有以下有益效果:
本发明提供了一种检测方法和装置,本发明中没有像现有技术中一样,直接查找是否具有恶意的字节,即没有直接对二进制形式的代码进行分析,而是将具有二进制形式的代码的格式转换成具有字符串形式的代码,进而对具有字符串形式的代码进行特征分析,由于现有技术中形式改变后的恶意的字节对应的具有字符串形式的代码是不变的,采用本发明中的方案就能够避免恶意的字节的形式改变后,采用特征码和人工规则的识别方法来检测flash文件中是否携带有恶意代码时,不能判断flash文件是否是恶意文件的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明提供的一种检测方法的方法流程图;
图2为本发明提供的另一种检测方法的方法流程图;
图3为本发明提供的一种检测装置的结构示意图;
图4为本发明提供的另一种检测装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
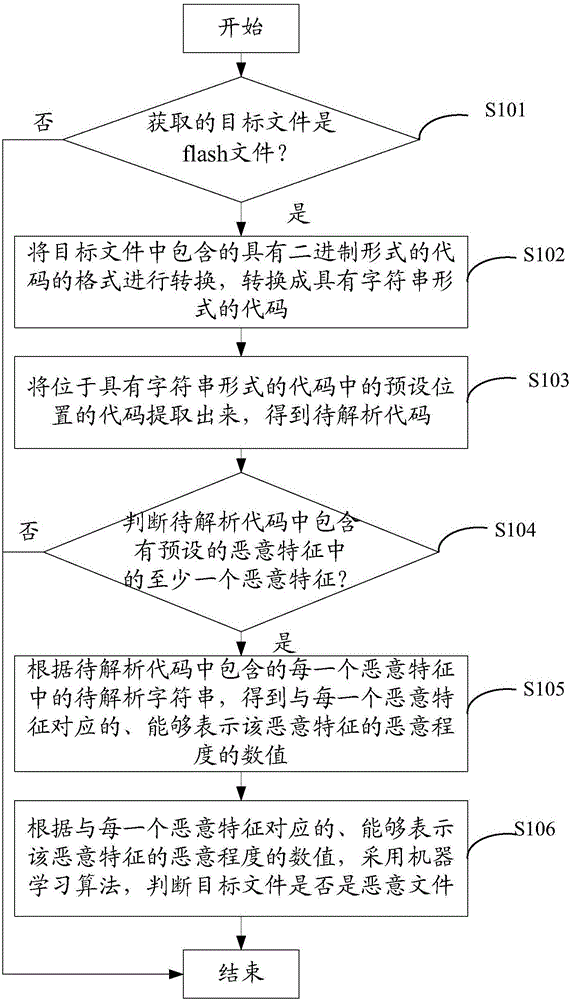
本发明实施例提供了一种检测方法,参照图1,包括:
S101、判断获取的目标文件是否是固态存储器与动画编辑器flash文件;
具体的,判断获取的目标文件是否是固态存储器与动画编辑器flash文件,包括:
采用文件格式识别方法识别目标文件的文件类型,判断文件类型是否是flash文件的文件类型。
需要说明的是,每一种文件都具有其特定的文件类型。flash文件包括两类,一类是已压缩文件,一类是未压缩文件,其中,已压缩文件的文件类型的开头三位为CWS,未压缩文件的文件类型的开头三位为FWS。
S102、将目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码;
需要说明的是,当判断出获取的目标文件是flash文件,将目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码。当判断出获取的目标文件不是flash文件时,流程结束。
具体的,根据flash文件对应的技术文档,将目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码。
S103、将位于具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码;
需要说明的是,恶意代码只会出现在具有字符串形式的代码中的预设位置,其中预设位置包括DoInitAction段、DoAction段和DoABC段。
具体的,将位于具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码,包括:
查找位于具有字符串形式的代码中的预设位置中的每个位置的代码;
将每个位置的代码提取出来,得到待解析代码。
即将位于DoInitAction段、DoAction段和DoABC段的代码都提取出来,得到待解析代码。
S104、判断待解析代码中是否包含有预设的恶意特征中的至少一个恶意特征;
其中,预设的恶意特征包括名称特征、恶意行为特征或数据拼接特征。
S105、根据待解析代码中包含的每一个恶意特征中的待解析字符串,得到与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值;
具体的,当判断出待解析代码中包含有预设的恶意特征中的至少一个恶意特征,根据待解析代码中包含的每一个恶意特征中的待解析字符串,得到与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值。需要说明的是,当判断出待解析代码中未包含有预设的恶意特征中的任何一个恶意特征,说明目标文件不是恶意文件,此时流程结束。
其中,当预设的恶意特征包括名称特征、恶意行为特征或数据拼接特征时,根据待解析代码中包含的每一个恶意特征中的待解析字符串,得到与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,包括:
当待解析代码中包含名称特征时,根据与待解析代码中包含的名称特征相匹配的字符串为正常字符串的概率,得到与名称特征对应的、能够表示名称特征的恶意程度的数值;
具体的,名称特征为类名,在待解析代码中查找与类名相匹配的字符串,根据马尔科夫链算法分析该字符串是否是正常的字符串,当分析出该字符串为正常字符串的概率大于预设值时,证明该字符串为正常字符串。根据这种方法来得到与类名相匹配的字符串中正常字符串所占的比例。
假设查找出两个与类名相匹配的字符串,此时分析这两个字符串是否是正常的字符串,假设这两个字符串中的一个为正常的字符串、另一个为不正常的字符串,则类名中正常字符串的占比为0.5。即名称特征对应的、能够表示名称特征的恶意程度的数值为0.5。需要说明的是,该数值为小数。
当待解析代码中包含恶意行为特征时,根据待解析代码中包含的恶意行为特征中的每个特征出现的次数,得到与恶意行为特征对应的、能够表示恶意行为特征的恶意程度的数值;
具体的,恶意行为特征包括获取内存信息和修改系统文件行为这两个小特征。
其中,获取内存信息和修改系统文件行为这两个小特征都对应有相应的字符串,如获取内存信息的字符串为getallocsize。
在待解析代码中,查找是否包含有上述每一个小特征对应的字符串,当查找出有其中的一个小特征对应的字符串时,将该字符串出现的次数乘以该字符串对应的分值,即得到该特征对应的一个分值。根据这种方法,能够得到每一个小特征对应的分值,将每个小特征对应的分值相加,即能得到恶意行为特征对应的、能够表示恶意行为特征的恶意程度的数值。其中,该数值为整数。
举例来说,当想要知道获取内存信息这个特征对应的数值,在待解析代码中查找getallocsize出现的次数,假设getallocsize出现一次对应的分值为五分,在查找的过程中,发现getallocsize出现了四次,那么获取内存信息这个特征对应的分值就是二十。
当待解析代码中包含数据拼接特征时,根据待解析代码中包含的数据拼接特征出现的次数,得到与数据拼接特征对应的、能够表示数据拼接特征的恶意程度的数值。
其中,数据拼接是指在某块具有二进制形式的代码段中有规律并且频繁的使用加add指令,对字符串进行拼接。
在待解析代码中,查找是否包含有数据拼接特征对应的字符串,当查找出有数据拼接特征对应的字符串时,将该字符串出现的次数乘以该字符串对应的分值,即得到该特征对应的一个分值。该分值即为与数据拼接特征对应的、能够表示数据拼接特征的恶意程度的数值。其中,该数值为整数。
需要说明的是,拼接后的字符串对应的分值的大小,与字符串的长短有关,若字符串的长度越长,则其对应的分值越高,若字符串的长度越短,则其对应的分值越小。
S106、根据与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断目标文件是否是恶意文件。
本实施例提供了一种检测方法,本实施例中没有像现有技术中一样,直接查找是否具有恶意的字节,即没有直接对二进制形式的代码进行分析,而是将具有二进制形式的代码的格式转换成具有字符串形式的代码,进而对具有字符串形式的代码进行特征分析,由于现有技术中形式改变后的恶意的字节对应的具有字符串形式的代码是不变的,采用本发明中的方案就能够避免恶意的字节的形式改变后,采用特征码和人工规则的识别方法来检测flash文件中是否携带有恶意代码时,不能判断flash文件是否是恶意文件的问题。
可选的,本发明的另一实施例中,参照图2,根据与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断目标文件是否是恶意文件,包括:
S206、根据与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,计算得到目标文件为恶意文件的概率;
需要说明的是,计算得到目标文件为恶意文件的概率采用的方法是机器学习算法中的支持向量机算法。
其中,支持向量机算法中赋予了每个恶意特征对应的分量,将每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值与该恶意特征对应的分量根据预设的规则进行计算,就能够得到目标文件为恶意文件的概率。
S207、根据概率,判断目标文件是否是恶意文件。
当计算出的概率大于50%时,就证明该目标文件为恶意文件。
当计算出的概率大于50%且小于70%时,目标文件的危险等级为低,当计算出的概率大于70%且小于90%,目标文件的危险等级为中,当计算出的概率大于90%时,目标文件的危险等级为高。
此外,当判断出目标文件为恶意文件时,在显示界面上显示全部的具有字符串形式的代码以及恶意代码。其中,名称特征中非正常的字符串、在待解析代码中出现的恶意行为特征中的每个小特征对应的字符串以及在待解析代码中出现的数据拼接特征对应的字符串为恶意代码。在显示恶意代码时,将包含有恶意代码的那行均标黄,或者以其他方式显示。
本实施例中,采用机器学习算法,计算得到目标文件为恶意文件的概率,进而根据该概率,判断目标文件是否是恶意文件。
可选的,本发明的另一实施例中提供了一种检测装置,参照图3,包括:
第一判断单元101,用于判断获取的目标文件是否是固态存储器与动画编辑器flash文件;
转换单元102,用于当第一判断单元101判断出获取的目标文件是flash文件,将目标文件中包含的具有二进制形式的代码的格式进行转换,转换成具有字符串形式的代码;
提取单元103,用于将位于具有字符串形式的代码中的预设位置的代码提取出来,得到待解析代码;
第二判断单元104,用于判断待解析代码中是否包含有预设的恶意特征中的至少一个恶意特征;
特征提取单元105,用于当第二判断单元104判断出待解析代码中包含有预设的恶意特征中的至少一个恶意特征,根据待解析代码中包含的每一个恶意特征中的待解析字符串,得到与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值;
第三判断单元106,用于根据与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,判断目标文件是否是恶意文件。
其中,第一判断单元101,包括:
第一判断子单元,用于采用文件格式识别方法识别目标文件的文件类型,判断文件类型是否是flash文件的文件类型。
提取单元包括:
查找单元,用于查找位于具有字符串形式的代码中的预设位置中的每个位置的代码;
提取子单元,用于将每个位置的代码提取出来,得到待解析代码。
此外,当预设的恶意特征包括名称特征、恶意行为特征或数据拼接特征时,
特征提取单元105包括:
第一特征提取单元,用于当第二判断单元判断出待解析代码中包含名称特征时,根据与待解析代码中包含的名称特征相匹配的字符串为正常字符串的概率,得到与名称特征对应的、能够表示名称特征的恶意程度的数值;
第二特征提取单元,用于当第二判断单元判断出待解析代码中包含恶意行为特征时,根据待解析代码中包含的恶意行为特征中的每个特征出现的次数,得到与恶意行为特征对应的、能够表示恶意行为特征的恶意程度的数值;
第三特征提取单元,用于当第二判断单元判断出待解析代码中包含数据拼接特征时,根据待解析代码中包含的数据拼接特征出现的次数,得到与数据拼接特征对应的、能够表示数据拼接特征的恶意程度的数值。
本实施例提供了一种检测装置,本实施例中没有像现有技术中一样,直接查找是否具有恶意的字节,即没有直接对二进制形式的代码进行分析,而是将具有二进制形式的代码的格式转换成具有字符串形式的代码,进而对具有字符串形式的代码进行特征分析,由于现有技术中形式改变后的恶意的字节对应的具有字符串形式的代码是不变的,采用本发明中的方案就能够避免恶意的字节的形式改变后,采用特征码和人工规则的识别方法来检测flash文件中是否携带有恶意代码时,不能判断flash文件是否是恶意文件的问题。
需要说明的是,本实施例中的各个单元的工作过程请参照图1对应的实施例中的内容,在此不再赘述。
可选的,本发明的另一实施例中,参照图4,第三判断单元106包括:
计算单元1061,用于根据与每一个恶意特征对应的、能够表示该恶意特征的恶意程度的数值,采用机器学习算法,计算得到目标文件为恶意文件的概率;
第四判断单元1062,用于根据概率,判断目标文件是否是恶意文件。
本实施例中,采用机器学习算法,计算得到目标文件为恶意文件的概率,进而根据该概率,判断目标文件是否是恶意文件。
需要说明的是,本实施例中的各个单元的工作过程请参照图2对应的实施例中的内容,在此不再赘述。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!