智能LED交互装置的制作方法
本实用新型涉及一种智能LED交互装置。
背景技术:
随着电子技术的不断发展,广告、新闻、资讯、咨询等信息越来越多的使用LED显示屏完成,这些显示屏广泛分布在楼宇、电梯、过道、地铁、公交站等位置。随着用户体验和感受要求的不断提高,能够进行智能交互的LED显示技术得以出现和发展。
申请公布号为CN104080010A(申请号为201410295113.9)的中国发明专利申请《交互式信息推送系统及方法》,其中公开的交互系统识别前景图像中朝向显示屏的人脸,当人脸朝向显示屏的时间超过一定的时间后则播放显示屏当前播放的第一图文数据对应的第二图文数据,进而发送到显示屏进行播放。该系统中人机的交互内容仅限于显示屏中存储的内容,且是被动的播放给用户,交互的局限性大。并且使用过程中,用户处于动态状态,该系统无法实时获取用户的动态状态,即无法获知交互用户是否已经更换,进而不能的准确的满足不同用户的需求。
申请公开号为CN102221881A(申请号为201110131915.2)的中国发明专利申请《基于仿生代理与实现追踪兴趣区域分析的人机交互方法》,其中公开的交互方法,能够计算用户眼球在屏幕上的焦点位置,进而得到用户眼球在屏幕上的焦点位置,进而分析用户关注的兴趣区域,从而实现自然、和谐的人机交互。但是该交互方法也同样忽略了用户的动态状态检测,容易出现兴趣内容误传的情况。
技术实现要素:
本实用新型所要解决的技术问题是针对上述现有技术提供一种能够实时检测用户的动态状态,以确认当前的交互用户身份,以确保交互信息准确性的智能LED交互装置。
本实用新型解决上述技术问题所采用的技术方案为:一种智能LED交互装置,其特征在于包括:
中央处理器,用于进行数据处理和发送控制命令;
存储器,与所述中央处理器相连接,用于存储数据;所述存储器具有用于存储预存文字、图片、视频、语音的预存内容存储单元和用于存储问题、答案的本地知识库;
LED显示屏,与所述中央处理器相连接,用于显示文字、图片、视频;
视频采集模块,用于采集LED显示屏前方的视频画面;
人脸检测模块,与所述视频采集模块相连接,用于检测和获取视频采集模块传送的视频画面中的人脸的坐标和特征数据;
音频采集模块,用于采集用户的语音信息;
检测控制器,分别与所述人脸检测模块、音频采集模块相连接,用于计算比较人脸的尺寸与设定的人脸尺寸阈值的大小,以及检测是否存在用户语音信息;
注视识别模块,分别与所述检测控制器和中央处理器相连接,用于计算分析用户注视LED显示屏各个注视区域的角度和时间,进而获取LED显示屏上用户的兴趣区域;
声纹识别模块,分别与所述音频采集模块和检测控制器相连接,用于识别音频采集模块传送的用户语音信息中的声纹特征;
语音识别模块,分别与所述音频采集模块和检测控制器相连接,用于识别分析音频采集模块传送的用户语音信息并将用户语音信息转换为语音文本;
语义分析模块,分别与所述语音识别模块和中央处理器相连接,用于分析语音识别模块传送的语音文本以提取语音文本中的核心词和关键词,进而将核心词和关键词传送至中央处理器中;
答案提取模块,分别与所述中央处理器和存储器中的本地知识库相连接,根据所述中央处理器传送的核心词和关键词,在本地知识库中搜索并提取答案,进而将答案传送至中央处理器;
音频播放模块,分别与中央处理器、存储器相连接以根据所述中央处理器的控制命令播放音频数据。
为了保证交互质量,还包括网络搜索模块,所述网络搜索模块与所述中央处理器相连接,所述网络搜索模块当答案提取模块在本地知识库中未提取到答案时,根据所述中央处理器的控制命令通过网络搜索答案。
方便地,还包括语音合成模块,所述语音合成模块分别与所述中央处理器和音频播放模块相连接以将中央处理器传送的答案合成为语音音频并通过所述音频播放模块进行播放。
与现有技术相比,本实用新型的优点在于:本实用新型中的智能LED交互装置,在使用过程中能够实时检测用户的动态状态和身份特征,以确认当前的用户身份,从而实现交互过程中用户与需求信息的匹配性,确保将匹配的内容准确的传送至用户,使得交互过程更加智能化,避免了交互资源的浪费,提高了交互的准确性、有效性。
附图说明
图1为本实用新型实施例中智能LED交互装置的结构框图。
图2为本实用新型实施例中智能LED交互的流程图。
具体实施方式
以下结合附图实施例对本实用新型作进一步详细描述。
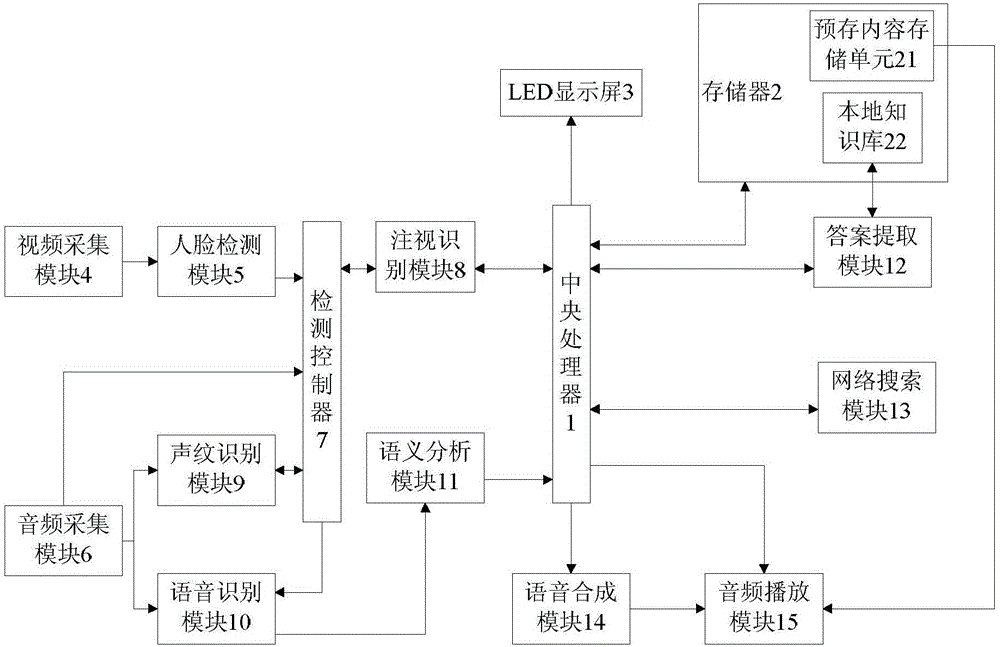
如图1所示,本实施例中的智能LED交互装置包括:中央处理器1、存储器2、LED显示屏3、视频采集模块4、人脸检测模块5、音频采集模块6、检测控制器7、注视识别模块8、声纹识别模块9、语音识别模块10、语义分析模块11、答案提取模块12、网络搜索模块13、语音合成模块14以及音频播放模块15。
其中中央处理器1,用于进行数据处理和发送控制命令。
存储器2与中央处理器1相连接,用于存储数据。本实施例中的存储器2专门设置有用于存储预存文字、图片、视频、语音的预存内容存储单元21,以及用于存储问题、答案的本地知识库22。
LED显示屏3与中央处理器1相连接,根据中央处理器1的控制,显示存储器2中的文字、图片、视频等内容。
视频采集模块4安装在LED显示屏3上,用于采集LED显示屏3前方的视频画面。本实施例中的视频采集模块4可以选用摄像头,实施采集LED显示屏3前方的视频画面。
人脸检测模块5与视频采集模块4相连接,该人脸检测模块5可以使用现有技术中的人脸检测装置或者集成芯片,该人脸检测模块5可以用于检测和获取视频采集模块4传送的视频画面中的人脸的坐标和特征数据。
音频采集模块6用于采集用户的语音信息,该音频采集模块6可以安装在LED显示屏3上,也可以安装在LED显示屏3附近,本实施例中的音频采集模块6可以采用话筒。
检测控制器7分别与人脸检测模块5、音频采集模块6相连接进行工作,该检测控制器7可以选用单片机。该检测控制器7用于计算比较人脸的尺寸与设定的人脸尺寸阈值的大小,从而判断是否启动该智能LED交互装置的交互操作。该检测控制器7还可以检测是否存在用户语音信息,用户语音信息的判断可以根据需要设定音频的声强阈值,从而判断采集到用户语音信息与否。
注视识别模块8分别与检测控制器7和中央处理器1相连接,该注视识别模块8可以采用现有技术中注视识别装置成品或者现有的注视识别集成芯片。该注视识别模块8用于计算分析用户注视LED显示屏3各个注视区域的角度和时间,进而获取LED显示屏3上用户的兴趣区域。
声纹识别模块9分别与音频采集模块6和检测控制器7相连接,该声纹识别模块9可以采用现有的声纹识别装置或者集成芯片,该声纹识别模块9用于识别音频采集模块6传送的用户语音信息中的声纹特征,从而在分析多个用于语音信息后能够判断是否为同一个用户的声纹特征,方便确认用户的身份,进而将分析结果传送至检测控制器7中。
语音识别模块10分别与音频采集模块6和检测控制器7相连接,该语音识别模块10可以采用现有的语音识别装置或者集成芯片。语音识别模块10用于识别分析音频采集模块6传送的用户语音信息并将用户语音信息转换为语音文本。
语义分析模块11分别与语音识别模块10和中央处理器1相连接,该语义分析模块11可以采用现有的语音分析装置或者集成芯片。语义分析模块11可以用于分析语音识别模块10传送的语音文本以提取语音文本中的核心词和关键词,进而将核心词和关键词传送至中央处理器1中,根据核心词和关键词传送至中央处理器1的次数,可以设置相应核心词和关键词的权重,以方便在使用中利用其权重进行控制。
答案提取模块12分别与中央处理器1和存储器2中的本地知识库22相连接。该答案提取模块12可以采用现有的信息搜索装置或者集成芯片,该答案提取模块12使用的搜索算法可以使用现有技术中的各种搜索算法。如答案提取模块12根据所述中央处理器1传送的核心词和关键词,在本地知识库22中通过模糊搜索查询提取相应的答案,进而将提取的答案传送至中央处理器1。中央处理器1也可以根据接收的答案的频率来设置本地知识库22中相应答案的权重,从而方便利用答案权重进行答案的选择控制。
网络搜索模块13与中央处理器1相连接,通过该网络搜索模块13可以实现和外部广域网、互联网的网络连接,进而当答案提取模块12在本地知识库22中未提取到答案时,根据中央处理器1的控制命令,该网络搜索模块13通过网络搜索答案,并将搜索到的答案传送至中央处理器1中,进而中央处理器1一方面可以控制将该答案进行显示,另一方面可以将该答案存储至本地知识库22中以备使用。本实施例中的网络搜索模块13可以采用现有的网络搜索装置或者集成芯片。
语音合成模块14与中央处理器1相连接,用于将中央处理器1传送的答案合成为语音音频。该语音合成模块14可以使用现有成熟的语音合成装置或者集成芯片。
音频播放模块15分别与语音合成模块14、中央处理器1、存储器2相连接,用于播放语音合成模块14中合成的语音音频以及存储器2中的音频数据。该音频播放模块15可以使用通用的扩音器。音频播放器软件可以设置在中央处理器1。
本实施例中的智能LED交互方法,包括如下步骤:
步骤1、初始化,中央处理器1调取存储器2的预存内容存储单元21中的文字、图片、视频内容,控制LED显示屏3显示设定的首页内容,LED显示屏3上分为多个显示区域,则设定的首页内容分别在不同的显示区域显示不同的内容;
步骤2、利用视频采集模块4采集获取LED显示屏3前方的视频画面;
步骤3、根据视频采集模块4采集的视频画面,利用人脸检测模块5实时对视频画面图像进行人脸检测,判断是否有人脸存在;当视屏画面图像中检测到人脸,则进入步骤4;
步骤4、利用人脸检测模块5遍历视频画面图像中所有的人脸坐标和特征,进而将所有的人脸坐标和特征数据传送至检测控制器7中,检测控制器7计算获取最大人脸的坐标和特征数据;
步骤5、检测控制器7计算并判断最大人脸尺寸是否超过设定的人脸尺寸阈值,如果最大人脸尺寸超过设定的人脸尺寸阈值,则将最大人脸的特征数据存储在检测控制器7中,并进入步骤6;如果最大人脸尺寸未超过设定的人脸尺寸阈值,则返回步骤2;
步骤6、检测控制器7判断最大人脸在视频画面图像中的出现的累积时间是否超过设定的识别时间阈值,如果超过设定的识别时间阈值,则进入步骤7,如果未超过设定的识别时间阈值,则删除其内存储的最大人脸的特征数据,并返回步骤2;
步骤7、检测控制器7检测其内的交互状态标识,如果检测控制器7中当前的交互状态标识示为工作状态,则删除检测控制器7内存储的最大人脸的特征数据,并返回步骤2,如果检测控制器7中当前交互状态标识示为空闲状态,则启动交互;
步骤8、检测控制器7检测音频采集模块6采集的用户语音信息,进而检测控制器7判断是否存在用户语音信息;
检测控制器7获取语音信息时,检测语音信息对应的音频声强是否超出检测控制器7中设定的音频声强阈值,如果语音信息的音频声强未超过设定的音频声强阈值则视为未接收到语音信息,如果语音信息的音频声强超出检测控制器7中设定的音频声强阈值,则视为接收到语音信息;同时检测控制器7在其设定的语音信息检测时间阈值内检测语音信息,如果在设定的语音信息检测时间阈值内检测到语音信息,则视为检测到用户的语音信息,如果在设定的语音信息检测时间阈值内未检测到语音信息,则视为未检测到用户的语音信息;
如果检测控制器7未检测到用户的语音信息则进入步骤9,如果检测控制器7检测到用户的语音信息,则进入步骤14;
步骤9、检测控制器7将其内的交互状态标识调整为视觉交互工作状态,将步骤4中最大人脸对应的用户作为当次交互用户,注视识别模块8获取检测控制器7中的最大人脸特征数据,并分析最大人脸特征数据对应的当次交互用户相对于LED显示屏3的注视角度,进而分析当次交互用户在屏幕上所有的注视区域,同时分别对当次交互用户注视的各个注视区域的累计时间进行计时;
步骤10、注视识别模块8将用户注视各个注视区域的累积时间分别与其设定的注视时间阈值进行比较;
如果用户注视各个注视区域的累积时间均小于设定的注视时间阈值,则注视识别模块8分别向检测控制器7和中央处理器1反馈当次视觉交互工作结束的信息,检测控制器7则将其内的交互状态标识调整为空闲状态,并删除其内存储的最大人脸的特征数据,而中央处理器1则控制LED显示屏3仍然显示首页内容,并返回步骤2;
如果用户注视各个注视区域的累积时间中有大于设定的注视时间阈值,则进行步骤11;
步骤11、注视识别模块8将LED显示屏3上用户注视累积时间最长的注视区域识别为用户的兴趣区域,注视识别模块8将识别结果传送至中央处理器1,中央处理器1控制LED显示屏3将当前兴趣区域显示内容对应的更详细的内容显示播放给用户,如果LED显示屏3播放的是视频内容,则中央处理器1同时控制音频播放模块15播放相应的音频数据;
步骤12、在LED显示屏3播放兴趣区域的详细内容过程中,利用视频采集模块4实时获取LED显示屏3前方的视频画面并传送至人脸检测模块5;人脸检测模块5将视频画面图像中所有的人脸坐标和特征传送至检测控制器7,检测控制器7将获取的新的人脸特征数据与其内存储的最大人脸的特征数据进行对比,从而判断视频画面图像中当次交互用户对应的人脸特征数据是否还存在;
如果检测控制器7判断当次交互用户对应的人脸特征数据存在,则注视识别模块8检测默认当次交互用户注视LED显示屏3观看LED显示屏3的播放内容,从而将注视结果传送至中央处理器1,则中央处理器1控制LED显示屏3持续播放步骤10中的内容;
如果检测控制器7判断当次交互用户对应的人脸特征数据丢失,则检测控制器7对该人脸特征数据的丢失时间进行计时;
步骤13、如果步骤12中的人脸特征数据的丢失时间超过检测控制器7内设定的丢失时间阈值,检测控制器7则删除其内存储的当次交互用户对应的最大人脸特征数据,并将其内的交互状态标识调整为空闲状态,并返回步骤2;
同时检测控制器7向注视识别模块8发送当次交互用户丢失的结果,注视识别模块8则相应默认当次交互用户未注视LED显示屏3观看LED显示屏3的播放内容,从而将注视结果传送至中央处理器1,中央处理器1控制LED显示屏3停止当前内容的播放,并控制LED显示屏3显示设定的主页内容;
如果步骤12中的人脸特征数据的丢失时间未超出设定的丢失时间阈值,则LED显示屏3继续播放当前内容直至播放结束;
LED显示屏3播放结束后,中央中央处理器1则获取LED显示屏3传送的当次视觉交互工作结束的信息,该当次视觉交互工作结束的信息经过注视识别模块8传送至检测控制器7,则检测控制器7删除当次交互用户对应的人脸特征数据,同时将其内的交互状态标识调整为空闲状态,并返回步骤2;
步骤14、检测控制器7将其内的交互状态标识调整为语音交互工作状态,检测控制器7控制声纹识别模块9和语音识别模块10接收音频采集模块6传送的音频声强超出检测控制器7中设定的音频声强阈值的语音信息,声纹识别模块9提取语音信息中的声纹特征并传送至检测控制器7,检测控制器7存储当次交互用户的声纹特征数据;
步骤15、对获取的语音信息进行识别和语义分析,具体包括如下步骤:
步骤15.1、语音识别模块10识别语音信息,并将语音信息转换为语音文本,进而将该语音文本传送至语义分析模块11中;
步骤15.2、语义分析模块11对获取的语音文本进行分词,进而提取语音文本中的核心词和关键词,进而将提取的核心词和关键词传送至中央处理器1中;
步骤15.3、中央处理器1根据接收到核心词和关键词的次数调整相应核心词和关键词的权重,同时中央处理器1将对接收到的核心词和关键词传送至答案提取模块12,答案提取模块12根据接收到的核心词和关键词使用相应的搜索算法自本地知识库22中搜索并提取答案,根据不同的搜索要求,答案提取模块12对本地知识库22的搜索算法可以根据要求采用现有的各种搜索算法;根据不同核心词和关键词的权重可以扩展使用核心词和关键词的优先级,进而优化搜索过程,缩短搜索时间;
步骤15.4、答案提取模块12将相应的答案搜索结果传送至中央处理器1,如果答案提取模块12在本地知识库22中搜索到答案,则将答案传送至中央处理器1,中央处理器1对本地数据库中该答案的权重进行调整,进而进入步骤15.9,否则将答案提取失败的结果传送至中央处理器1,进入步骤15.5;对答案权重的调整可以实现答案优先级的应用,如此在出现多个能够使用的答案时,可以根据答案的优先级选择更加精准的答案;
步骤15.5、中央处理器1向网络搜索模块13传送前述的核心词和关键词并向网络搜索模块13发送启动工作的控制命令,网络搜索模块13搜索广域网或互联网以获取前述的核心词和关键词对应的答案;
步骤15.6、网络搜索模块13如果搜索到答案,则将答案传送至中央处理器1,进而进入步骤15.8和步骤15.9,否则网络搜索模块13向中央处理器1返回获取答案失败的结果,进而进入步骤15.7;
步骤15.7、中央处理器1控制LED显示屏3显示和/或控制音频播放模块15语音提示答案获取失败,同时中央处理器1记录答案获取失败的问题,以备人工添加答案;
步骤15.8、中央处理器1将网络搜索模块13搜索到的答案及对应的核心词和关键词保存到本地知识库22;
步骤15.9、中央处理器1控制LED显示屏3显示答案,和/或中央处理器1将答案传送至语音合成模块14,语音合成模块14将答案合成为语音音频,进而通过音频播放模块15播放给当次交互用户。
步骤16、在步骤15进行的同时,利用视频采集模块4实时获取LED显示屏3前方的视频画面,并利用人脸检测模块5对实时对视频画面图像进行人脸检测,判断是否有人脸存在,如果无人脸存在,则检测控制器7对人脸丢失时间进行累积计时,如果人脸丢失的累积时间超过检测控制器7内设置的语音交互用户丢失时间阈值,则立即结束步骤15,同时检测控制器7删除其内存储的当次交互用户的声纹特征,并将其内的交互状态标识调整为空闲状态;注视识别模块8则相应默认无交互用户未注视LED显示屏3,从而将注视结果传送至中央处理器1,中央处理器1控制LED显示屏3显示设定的主页内容,同时返回步骤2;
在步骤15进行的同时,如果检测控制器7接受到音频采集模块6传送的语音信息则不予响应;
步骤17、当次语音交互完成后,检测控制器7重新等待获取音频采集模块6传送的语音信息,如果在检测控制器7设定的等待时间阈值范围内获取到语音信息,则进入步骤18;如果在检测控制器7设定的等待时间阈值范围内未获取到语音信息,则删除当次交互用户的声纹特征,LED显示屏3显示设定的主页内容,将交互状态标识调整为空闲状态,并返回步骤2;
步骤18、声纹识别模块9获取音频采集模块6传送的新的语音信息,进而声纹识别模块9提取新的语音信息的声纹特征并传送至检测控制器7,检测控制器7将新的新的语音信息对应的声纹特征与存储的声纹特征进行对比,进而判断获取的语音信息对应的声纹特征是否为当次交互用户的声纹特征,如果是,则进入步骤15;如果不是,则进入步骤17。
- 还没有人留言评论。精彩留言会获得点赞!