一种问答方法、系统和机器人与流程
本发明涉及机器人交互技术领域,尤其涉及一种问答方法、系统和机器人。
背景技术:
随着社会和科技的发展,机器人越来越多的应用到与人类的工作、生活沟通中,人类可以向机器人提出问题,机器人经过一系列的过程后向人类回复结果,类似于人与人沟通的过程。为了让机器人在与人沟通的过程中更加拟人化,更加模拟真实的与人沟通的场景,人们探索了很多种方法,然而在现有的问答系统中,存在回答的答案准确率不高的情况。
因此,如何提供一种回答的答案正确率更高的问答方法,成为亟需解决的技术问题。
技术实现要素:
本发明的目的是提供一种回答的答案正确率更高的问答方法的问答方法、系统和机器人。
本发明的目的是通过以下技术方案来实现的:
一种问答方法,包括:
获取提问信息;
将提问信息输入到知识图谱中查询答案;
若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;
若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。
优选的,所述方法进一步包括:
若在知识图谱中查询到答案,则终止查询。
优选的,所述方法进一步包括:
若在社区数据中查询到答案,则终止查询。
优选的,所述将提问信息输入到知识图谱中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在知识图谱中分别查找中间结果;
将中间结果输入到数据库中获取情感偏向,根据情感偏向得到答案。
优选的,所述将提问信息输入到社区数据中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在社区数据中分别查找中间结果;
将中间结果与预设的特征信息进行比较,根据比较结果得到答案。
优选的,所述将提问信息输入到互联网数据中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在互联网数据中分别查找中间结果;
将中间结果按照语言规则组合后得到答案。
本发明公开一种问答系统,包括:
获取模块,用于获取提问信息;
知识图谱模块,用于将提问信息输入到知识图谱中查询答案;
社区数据模块,用于若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;
互联网数据模块,用于若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。
优选的,所述系统包括第一终止模块,用于若在知识图谱中查询到答案,则终止查询。
优选的,所述系统包括第二终止模块,若在社区数据中查询到答案,则终止查询。
优选的,所述知识图谱模块具体用于:
将提问信息进行切分;
将切分后的结果在知识图谱中分别查找中间结果;
将中间结果输入到数据库中获取情感偏向,根据情感偏向得到答案。
优选的,所述社区数据模块具体用于:
将提问信息进行切分;
将切分后的结果在社区数据中分别查找中间结果;
将中间结果与预设的特征信息进行比较,根据比较结果得到答案。
优选的,所述互联网数据模块具体用于:
将提问信息进行切分;
将切分后的结果在互联网数据中分别查找中间结果;
将中间结果按照语言规则组合后得到答案。。
本发明公开一种机器人,包括如上述任一所述的一种问答系统。
相比现有技术,本发明具有以下优点:本发明公开的一种问答方法包括:获取提问信息;将提问信息输入到知识图谱中查询答案;若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。这样就可以将提问信息首先输入到知识图谱中查询答案,如果查询到,就是反馈给用户,如果没有查询到,那么就会继续到社区数据中查询,如果查询到,就反馈给用户,如果没有查询到,那就会继续到互联网数据中查询,如果查询到及反馈给用户。这样就可以结合基于知识图谱的问答的准确率高的特点,基于社区数据的问答的覆盖率较高的特点,基于互联网数据的问答的覆盖率更高的特点,来提高问答的覆盖率和准确率,扩大问答方法的适用范围和通用性。
附图说明
图1是本发明实施例一的一种机器人交互内容的生成方法的流程图;
图2是本发明实施例二的一种机器人交互内容的生成系统的示意图。
具体实施方式
虽然流程图将各项操作描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。各项操作的顺序可以被重新安排。当其操作完成时处理可以被终止,但是还可以具有未包括在附图中的附加步骤。处理可以对应于方法、函数、规程、子例程、子程序等等。
计算机设备包括用户设备与网络设备。其中,用户设备或客户端包括但不限于电脑、智能手机、PDA等;网络设备包括但不限于单个网络服务器、多个网络服务器组成的服务器组或基于云计算的由大量计算机或网络服务器构成的云。计算机设备可单独运行来实现本发明,也可接入网络并通过与网络中的其他计算机设备的交互操作来实现本发明。计算机设备所处的网络包括但不限于互联网、广域网、城域网、局域网、VPN网络等。
在这里可能使用了术语“第一”、“第二”等等来描述各个单元,但是这些单元不应当受这些术语限制,使用这些术语仅仅是为了将一个单元与另一个单元进行区分。这里所使用的术语“和/或”包括其中一个或更多所列出的相关联项目的任意和所有组合。当一个单元被称为“连接”或“耦合”到另一单元时,其可以直接连接或耦合到所述另一单元,或者可以存在中间单元。
这里所使用的术语仅仅是为了描述具体实施例而不意图限制示例性实施例。除非上下文明确地另有所指,否则这里所使用的单数形式“一个”、“一项”还意图包括复数。还应当理解的是,这里所使用的术语“包括”和/或“包含”规定所陈述的特征、整数、步骤、操作、单元和/或组件的存在,而不排除存在或添加一个或更多其他特征、整数、步骤、操作、单元、组件和/或其组合。
下面结合附图和较佳的实施例对本发明作进一步说明。
实施例一
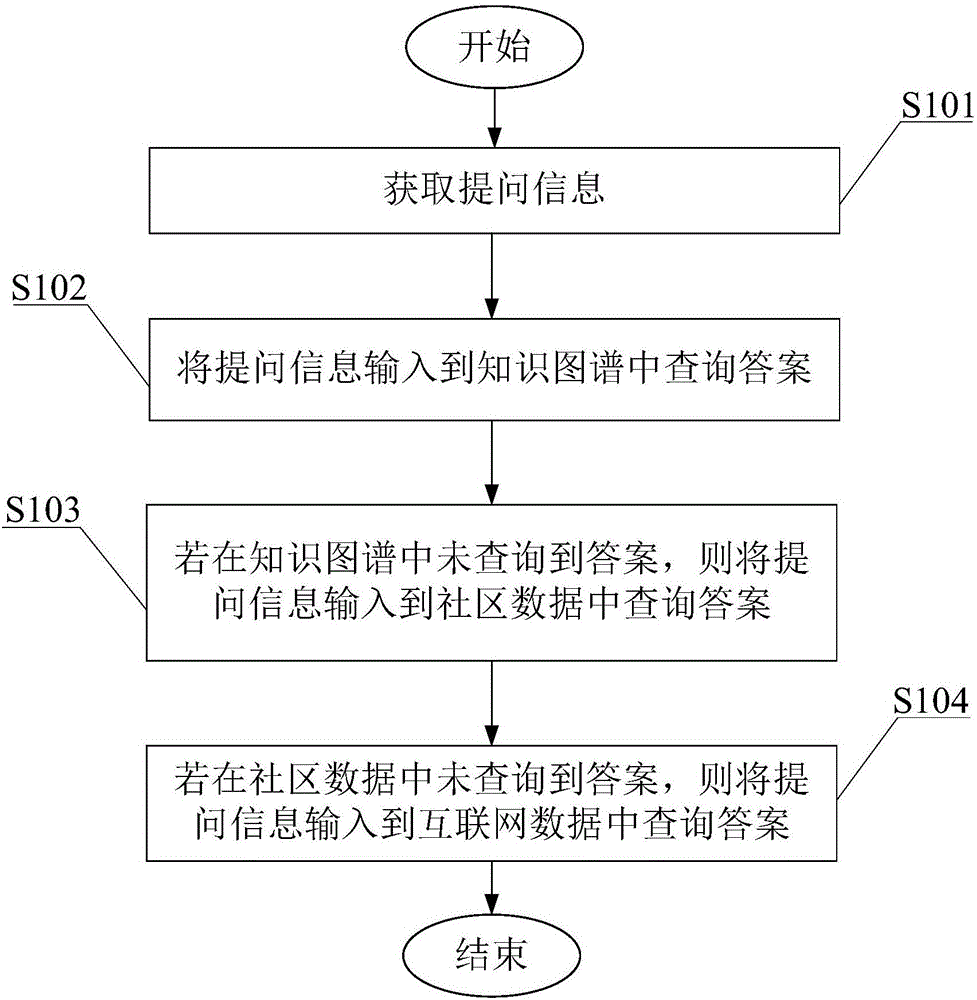
如图1所示,本实施例中公开一种问答方法,包括:
S101、获取提问信息;
S102、将提问信息输入到知识图谱中查询答案;
S103、若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;
S104、若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。
本发明公开的一种问答方法包括:获取提问信息;将提问信息输入到知识图谱中查询答案;若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。这样就可以将提问信息首先输入到知识图谱中查询答案,如果查询到,就是反馈给用户,如果没有查询到,那么就会继续到社区数据中查询,如果查询到,就反馈给用户,如果没有查询到,那就会继续到互联网数据中查询,如果查询到及反馈给用户。这样就可以结合基于知识图谱的问答的准确率高的特点,基于社区数据的问答的覆盖率较高的特点,基于互联网数据的问答的覆盖率更高的特点,来提高问答的覆盖率和准确率,扩大问答方法的适用范围和通用性。
本实施例中,基于互联网数据的问答(WEB-QA,web question answering),基于社区数据的问答(C-QA,community question answering),基于知识图谱的问答(KB-QA,knowledge based question answering)这三种问答的方法和系统中,KB-QA的特点在于准确率最高,但覆盖率最低,C-QA的特点在于准确率次高,但覆盖率较高,WEB-QA的特点在于准确率最低,但覆盖率最高。本实施例通过将三者有效的结合,可以增加问答的准确率和覆盖率。
根据其中一个示例,所述方法进一步包括:若在知识图谱中查询到答案,则终止查询。这样就可以在查找到答案之后就终止查询以节省资源和时间,方便用户及时获取到答案。
根据其中一个示例,所述方法进一步包括:若在社区数据中查询到答案,则终止查询。这样就可以在查找到答案之后就终止查询以节省资源和时间,方便用户及时获取到答案。
根据其中另一个示例,所述将提问信息输入到知识图谱中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在知识图谱中分别查找中间结果;
将中间结果输入到数据库中获取情感偏向,根据情感偏向得到答案。
这样就可以快速、方便的在知识图谱中查找到答案。
根据其中另一个示例,所述将提问信息输入到社区数据中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在社区数据中分别查找中间结果;
将中间结果与预设的特征信息进行比较,根据比较结果得到答案。
这样就可以快速、方便的在社区数据中查找到答案,社区数据例如“百度知道”,“知乎”等社区。
根据其中另一个示例,所述将提问信息输入到互联网数据中查询答案的步骤具体包括:
将提问信息进行切分;
将切分后的结果在互联网数据中分别查找中间结果;
将中间结果按照语言规则组合后得到答案。
这样就可以快速、方便的在知识图谱中查找到答案。
例如,用户提出的一个“我穿这件衣服好看吗”的问题。
那么Step1:在KB-QA中查询,“我”的爱好、心情,衣服的样式、颜色等,然后根据获取的人的偏好和衣服的特征,来判断是好看还是难看,从而得到答案。
Step2:如果在KB-QA中查询不到,就在C-QA中查询。例如,知乎上是否有“我”的偏好信息,和是否有衣服的资料,目的就是得到“我”的特征,“衣服”的特征,然后判断是好看还是难看,从而得到答案。
Step3:就本问题而言,显然web-QA是不合适的。因为web-QA没有“我”的资料,所以在web-QA就不会查询答案。
实施例二
如图2所示,本实施例公开一种问答系统,包括:
获取模块201,用于获取提问信息;
知识图谱模块202,用于将提问信息输入到知识图谱中查询答案;
社区数据模块203,用于若在知识图谱中未查询到答案,则将提问信息输入到社区数据中查询答案;
互联网数据模块204,用于若在社区数据中未查询到答案,则将提问信息输入到互联网数据中查询答案。
这样就可以将提问信息首先输入到知识图谱中查询答案,如果查询到,就是反馈给用户,如果没有查询到,那么就会继续到社区数据中查询,如果查询到,就反馈给用户,如果没有查询到,那就会继续到互联网数据中查询,如果查询到及反馈给用户。这样就可以结合基于知识图谱的问答的准确率高的特点,基于社区数据的问答的覆盖率较高的特点,基于互联网数据的问答的覆盖率更高的特点,来提高问答的覆盖率和准确率,扩大问答方法的适用范围和通用性。
本实施例中,基于互联网数据的问答(WEB-QA,web question answering),基于社区数据的问答(C-QA,community question answering),基于知识图谱的问答(KB-QA,knowledge based question answering)这三种问答的方法和系统中,KB-QA的特点在于准确率最高,但覆盖率最低,C-QA的特点在于准确率次高,但覆盖率较高,WEB-QA的特点在于准确率最低,但覆盖率最高。本实施例通过将三者有效的结合,可以增加问答的准确率和覆盖率。
根据其中一个示例,所述系统包括第一终止模块,用于若在知识图谱中查询到答案,则终止查询。这样就可以在查找到答案之后就终止查询以节省资源和时间,方便用户及时获取到答案。
根据其中另一个示例,所述系统包括第二终止模块,若在社区数据中查询到答案,则终止查询。这样就可以在查找到答案之后就终止查询以节省资源和时间,方便用户及时获取到答案。
根据其中另一个示例,所述知识图谱模块具体用于:
将提问信息进行切分;
将切分后的结果在知识图谱中分别查找中间结果;
将中间结果输入到数据库中获取情感偏向,根据情感偏向得到答案。
这样就可以快速、方便的在知识图谱中查找到答案。
根据其中另一个示例,所述社区数据模块具体用于:
将提问信息进行切分;
将切分后的结果在社区数据中分别查找中间结果;
将中间结果与预设的特征信息进行比较,根据比较结果得到答案。
这样就可以快速、方便的在社区数据中查找到答案,社区数据例如“百度知道”,“知乎”等社区。
根据其中另一个示例,所述互联网数据模块具体用于:
将提问信息进行切分;
将切分后的结果在互联网数据中分别查找中间结果;
将中间结果按照语言规则组合后得到答案。
这样就可以快速、方便的在知识图谱中查找到答案。
例如,用户提出的一个“我穿这件衣服好看吗”的问题。
那么Step1:在KB-QA中查询,“我”的爱好、心情,衣服的样式、颜色等,然后根据获取的人的偏好和衣服的特征,来判断是好看还是难看,从而得到答案。
Step2:如果在KB-QA中查询不到,就在C-QA中查询。例如,知乎上是否有“我”的偏好信息,和是否有衣服的资料,目的就是得到“我”的特征,“衣服”的特征,然后判断是好看还是难看,从而得到答案。
Step3:就本问题而言,显然web-QA是不合适的。因为web-QA没有“我”的资料,所以在web-QA就不会查询答案。
本发明公开一种机器人,包括如上述任一所述的一种问答系统。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!