自适应增强的机器学习的制作方法
本发明涉及自适应增强的“AdaBoost”类型的机器学习算法。
背景技术:
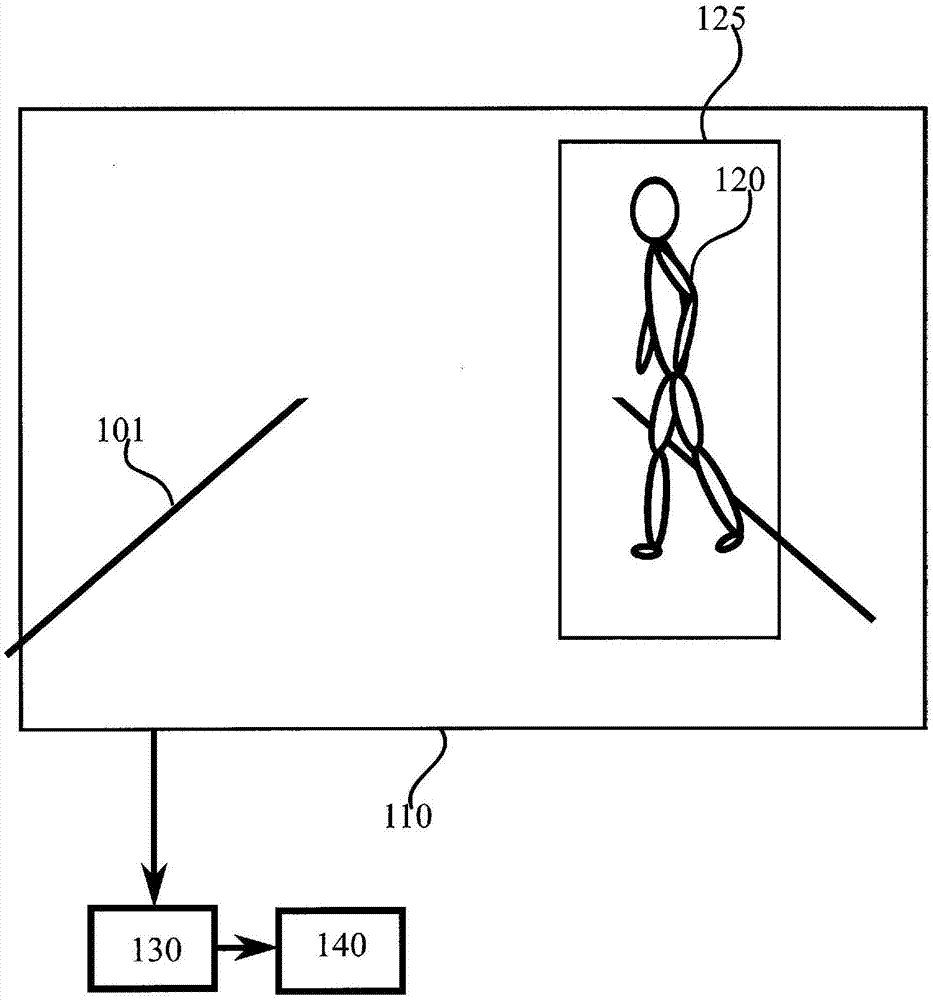
:机器学习和机器识别发现了若干应用,例如机场的自动护照控制,其中人脸的数字图像可以与存储在护照中的表征人脸的生物信息进行比较。机器识别的另一个示例是手写或打印的文档文本识别,以例如呈现可搜索的书籍内容。另一个示例是行人识别,其中最终自动驾驶汽车由此能够意识到行人在前方并且汽车可以避免撞到行人。除了视觉识别之外,口语可以是机器识别的主题。当口语被识别出时,可以随后将其输入到解析器以向数字个人助理提供命令,或者可以将其提供给机器翻译程序,从而获得与口语相对应的另一种语言的文本。机器识别技术采用为此目的而设计的算法。例如,神经网络可以被用于实现机器视觉应用。众所周知的机器视觉算法是Viola-Jones对象检测框架。机器识别算法可以包括处理功能,在识别图像时,这样的处理功能可以包括例如过滤(诸如形态过滤)、阈值处理、边缘检测、模式识别和对象尺寸测量。自适应增强或AdaBoost是一种通用框架,其中几种类型的学习算法被一起使用,以改善整个AdaBoost算法的性能。在将它们用作AdaBoost的子算法的上下文中,这种学习算法可以被称为弱分类器。技术实现要素:本发明由独立权利要求的特征限定。一些具体实施例在从属权利要求中被限定。根据本发明的第一方面,提供了一种装置,包括:存储器,被配置为存储要被机器识别的数据;至少一个处理核,被配置为使用该数据运行自适应增强机器学习算法,其中多个学习算法被应用,其中特征空间被划分为区间,其中失真函数被应用于特征空间的特征,并且其中失真函数的一阶导数不是常数。第一方面的各种实施例包括来自以下项目符号列表中的至少一个特征:·每个学习算法在不同的区间上操作·至少一个处理核被配置为将特征空间进行划分,使得区间的至少一个子集的大小均匀·至少一个处理核被配置为将特征空间进行划分,使得所有区间的大小均匀·至少一个处理核被配置为将特征空间进行划分,使得任何两个区间之间没有重叠·至少一个处理核被配置为在将失真函数应用于特征之后将特征空间划分为区间·在自适应增强机器学习算法中,每个区间被独立地处理·至少一个处理核被配置为将特征空间划分为256个区间·至少一个处理核被配置为在自适应增强机器学习算法中确定学习算法之一作为每次迭代中的最优分类器·至少一个处理核被配置为在自适应增强机器学习算法中确定最终输出作为多个学习算法中的每个学习算法的输出的加权和·失真函数的类型为·自适应增强机器学习算法包括训练阶段·该装置被配置为将自适应增强机器学习算法应用于以下中的至少一个的识别:口语对话、人脸、行人、文本和文档根据本发明的第二方面,提供了一种方法,包括存储要被机器识别的数据,使用该数据运行自适应增强机器学习算法,其中多个学习算法被应用,其中特征空间被划分为区间,其中失真函数被应用于特征空间的特征,并且其中失真函数的一阶导数不是常数。第一方面的各种实施例包括来自以下项目符号列表中的至少一个特征:·每个学习算法在不同的区间上操作·特征空间被划分,使得区间的至少一个子集的大小均匀·特征空间被划分,使得所有区间的大小均匀·特征空间被划分,使得任何两个区间之间没有重叠·在将失真函数应用于特征之后,发生将特征空间划分为区间·自适应增强机器学习算法,每个区间被独立地处理·特征空间被划分为256个区间·在自适应增强机器学习算法中,确定学习算法之一作为每次迭代中的最优分类器·在自适应增强机器学习算法中,确定最终输出作为多个学习算法中的每一个的输出的加权和·失真函数的类型是·自适应增强机器学习算法包括训练阶段·将自适应增强机器学习算法应用于以下中的至少一个的识别:口语对话、人脸、行人、文本和文档根据本发明的第三方面,提供了一种装置,包括用于存储要被机器识别的数据的部件,以及用于使用该数据运行自适应增强机器学习算法的部件,其中多个学习算法被应用,其中特征空间被划分为区间,其中失真函数被应用于特征空间的特征,并且其中失真函数的一阶导数不是常数。根据本发明的第四方面,提供了一种非瞬态计算机可读介质,其上存储有计算机可读指令的集合,当由至少一个处理器执行时,计算机可读指令使得装置至少:存储要被机器识别的数据,以及使用数据运行自适应增强机器学习算法,其中多个学习算法被应用,其中特征空间被划分为区间,其中失真函数被应用于特征空间的特征,并且其中失真函数的一阶导数不是常数。根据本发明的第五方面,提供了一种计算机程序,其被配置为使得根据第二方面的方法被执行。附图说明图1示出了能够支持本发明的至少一些实施例的示例系统;图2示出了被划分的特征空间中的分类器响应;图3示出了能够支持本发明的至少一些实施例的示例装置;图4示出了示例失真函数;图5示出了使用失真函数的特征空间的失真;图6示出了传统的AdaBoost方法和隐式非均匀划分的AdaBoost方法之间的差异,以及图7是根据本发明的至少一些实施例的方法的流程图。具体实施方式在AdaBoost算法中,特征空间可以被划分为均匀大小的区间或非均匀的区间。虽然均匀划分成相同大小的区间并不总是最优的,但是使用不均匀的划分,其中区间具有不同的大小,涉及更复杂的处理。当使用均匀划分时,失真函数可以被应用于特征,以获得比在非均匀划分的情况下更加简单的处理,但是具有非均匀划分的至少一些益处。例如,失真函数可以包括拉伸函数。在本发明的一些实施例中,使用失真函数导致均匀划分处理,其结果与使用非均匀划分等同。在术语上,使用失真函数可以被称为隐式非均匀划分。图1示出了能够支持本发明的至少一些实施例的示例系统。图1具有道路101的视图110,行人120在道路101上行走。尽管在这里结合图1在检测行人方面进行了描述,但是本发明不限于此,但是如本领域技术人员将理解的,本发明还更一般地适用于视觉、音频或其他类型的数据中的机器识别。例如,取决于所讨论的实施例,自行车识别、手写识别、面部识别、交通标志识别、语音识别、语言识别、手语识别和/或垃圾邮件识别可以从本发明中受益。在图1中,道路101由相机130成像。相机130被配置为至少部分地捕获覆盖道路的视图110。相机130可以被配置为预处理从包括在相机130中的图像捕获设备(诸如电荷耦合设备CCD)获得的图像数据。预处理的示例包括减少到黑白、对比度调整和亮度平衡以增加捕获图像中存在的动态范围。在一些实施例中,图像数据也被缩放到适合于馈送到图像识别算法(诸如AdaBoost)的比特深度。预处理可以包括对感兴趣的区域的选择,诸如区域125,例如,用于馈送到图像识别算法中。预处理可以本质上不存在或受限制。相机130可以安装在例如被配置为自己驾驶的汽车中。可替换地,相机130可以被安装在设计成由人类驾驶员驾驶的汽车中,但是如果汽车看起来即将撞到行人或动物,则提供警告和/或自动刹车。来自相机130的图像馈送可以被提供给图像识别算法140。物理上,图像识别算法140可以与相机130在相同的设备中操作,或者,它可以驻留在另一个设备中。在一些实施例中,图像识别算法140被布置在不同的计算节点中,该计算节点可以包括云计算节点、服务器或其他合适的设备。例如,相机130可以输出图像馈送,其可以包括图像帧。图像帧可以是数字的和/或矩形的。图像帧可以被提供给滤波器级,滤波器级基于图像帧获得包括从图像帧提取的特征的过滤数据集。滤波器级可以包括多个滤波器,每个滤波器被设计用于执行任务,诸如边缘检测、阈值处理、特征波长分析、获得高斯导数和/或类似任务。例如,滤波器级可以包括至少一个神经网络层。滤波器层可包括至少一个伽伯(Gabor)滤波器或Gabor小波滤波器。例如,特征可以包括通过从图像帧过滤而提取的至少一个矩阵或至少一个数值向量。在要识别的输入数据不是视觉数据的情况下,输入数据可以包括例如从模拟-数字转换器获得的数字样本的矢量。例如,模拟-数字转换器可以从麦克风获得模拟馈送,并且从模拟馈送生成样本。总之,如上所述,其他形式的数据也可以是机器识别的主题。例如,加速计或旋转传感器数据可以用于检测人是走路、跑步还是跌倒。在将失真特征提供给采用特征空间的均匀划分的AdaBoost算法之前,特征可以通过将失真函数应用于特征被修改,失真函数可以包括拉伸函数。特征空间可以包括至少一个矢量矩阵的线性空间,在该线性空间中特征作为数值存在。图2示出了被划分的特征空间中的分类器响应。区间(bin)1至10被布置在三个水平轴中的每一个上,其中j对区间和相应的分类器进行索引。在该图的最上部,垂直轴上的W+j表示落入区间j中的值为+1的样本数目,并且在图2的中间部分中的垂直轴上的W-j表示落入区间j中的值为-1的样本数目。图2的上部和中部是直方图。该图的下部表示分类器响应cj,其中cj=1/2*ln(W+j/W-j)。图2的最下部示出了分类器的分类器响应,其中对于特征域划分弱分类器,样本的分类由样本落入哪个区间确定。虽然在示意图中示出为10个区间,但是在实际实施例中,区间的数目可以是例如128、256或512。区间可以被称为块。总的来说,每个学习算法(即分类器)在不同的区间上操作。通过在不同的区间上操作,意味着样本的分类由样本落入哪个区间中确定。分类器可以基于不同的数学原理,或者,一些或所有分类器可以是相同基础算法的实现。学习算法的输出,即分类器,被组合成表示增强分类器的最终输出的加权和。图3示出了能够支持本发明的至少一些实施例的示例装置。图示的是设备300,其可以包括例如计算设备,诸如服务器、节点或云计算设备。处理器310被包括在设备300中,处理器310可以包括例如单核或多核处理器,其中单核处理器包括一个处理核,而多核处理器包括一个以上处理核。处理器310可以包括一个以上的处理器。处理核可以包括例如由安谋国际(ARMHoldings)制造的Cortex-A8处理核或由高级微设备公司(AdvancedMicroDevicesCorporation)生产的Steamroller处理核。例如,处理器310可以包括至少一个高通骁龙和/或英特尔酷睿处理器。处理器310可以包括至少一个专用集成电路ASIC。处理器310可以包括至少一个场可编程门阵列FPGA。处理器310可以是用于执行设备300中的方法步骤的部件。处理器310可以至少部分地由计算机指令配置以执行动作。设备300可以包括存储器320。存储器320可以包括随机存取存储器和/或永久存储器。存储器320可以包括至少一个RAM芯片。例如,存储器320可以包括固态、磁性、光学和/或全息存储器。存储器320可以至少部分地可由处理器310访问。存储器320可以至少部分地包括在处理器310中。存储器320可以是用于存储信息的部件。存储器320可以包括处理器310被配置为执行的计算机指令。当被配置为使处理器310执行某些动作的计算机指令被存储在存储器320中时,并且设备300整体被配置为使用来自存储器320、处理器310和/或其可以是被认为被配置以执行所述特定动作的至少一个处理核心的计算机指令,在处理器310的指导下运行。存储器320可以至少部分地包括在处理器310中。存储器320可以至少部分地在设备300外部但是可以由设备300访问。存储器320中的计算机指令可以包括多个应用程序或过程。例如,机器学习算法(诸如具有其分类器的AdaBoost算法)可以在一个应用程序或过程中运行,相机功能可以在另一个应用程序或过程中运行,并且机器学习步骤的输出可以被提供给另一个应用程序或者过程,其可以包括汽车驾驶过程,例如,响应于在相机视图中识别行人而使刹车动作被触发。设备300可以包括发送器330。设备300可以包括接收器340。发送器330和接收器340可以被配置为分别根据至少一个通信标准发送和接收信息。发送器330可包括一个以上的发送器。接收器340可包括一个以上的接收器。例如,发送器330和/或接收器340可以被配置为根据无线局域网WLAN、以太网、通用串行总线USB和/或用于微波接入的全球互操作性WiMAX标准来操作。可选地或另外地,可以使用专有通信框架。设备300可以包括用户界面UI360。UI360可以包括显示器、键盘、触摸屏,被布置成通过使设备300振动来向用户发信号的振动器、扬声器和麦克风中的至少一个。用户可以能够经由UI360操作设备300,例如以配置机器学习参数和/或开启和/或关闭设备300。处理器310可以配备有发送器,该发送器被布置为经由设备300内部的电引线从处理器310输出信息到设备300中包括的其他设备。这种发送器可以包括串行总线发送器,其被布置成例如经由至少一个电引线将信息输出到存储器320以便存储在其中。作为串行总线的替代,发送器可以包括并行总线发送器。同样地,处理器310可以包括接收器,其被布置成经由设备300内部的电引线从设备300中包括的其他设备接收处理器310中的信息。这样的接收器可以包括串行总线接收器,其被布置为例如经由至少一个电引线接收来自接收器340的信息用于在处理器310中处理。作为串行总线的替代,接收器可以包括并行总线接收器。设备300可以包括图3中未示出的其他设备。例如,在设备300包括智能电话的情况下,它可以包括至少一个数字相机。一些设备300可以包括后置摄像头和前置摄像头,其中后置摄像头可以用于数字摄影,而前置摄像头用于视频电话。设备300可以包括指纹传感器,该指纹传感器被布置成至少部分地认证设备300的用户。在一些实施例中,设备300缺少至少一个上述设备。处理器310、存储器320、发送器330、接收器340和/或UI360可以以多种不同方式由设备300内部的电引线互连。例如,前述设备中的每一个可以单独连接到设备300内部的主总线,以允许设备交换信息。然而,如技术人员将理解的,这仅是一个示例,并且取决于实施例,可以选择互连至少两个前述设备的各种方式而不脱离本发明的范围。图4示出了示例失真函数。图4的失真函数具有以下形式其中xc表示由该失真函数产生的拉伸效果的中心。被拉伸的特征空间的区域在图中示意性地表示为410。如果没有执行失真,则函数将具有一般形式f(x)=x,并且它将具有常数一阶导数。在本例中,点xc周围的特征被展开,区域410外的特征在剩余的特征空间中被压缩。通常,失真函数可以单调递增,例如非线性递增,意味着一阶导数不是常数。通常,当特征空间被缩放为具有维度1时,失真函数可以满足f(0)=0和f(1)=1,以防止特征被拉伸到特征空间之外。通常,失真函数可以用于拉伸特征空间的第一部分并压缩特征空间的第二部分。第二部分可以被设置在第一部分的两侧。加权训练误差被定义为在具有域划分弱分类器的经典AdaBoost中的加权训练误差,参考R.E.Schapire和Y.Singer:“使用置信度预测的改进的增强算法”,机器学习,37(3):297-336,1999。令S=[(x1,y1),...,(xm,ym)]为训练样本的序列,其中每个实例xi属于一个特征空间或实例空间X,并且每个标签yi属于二进制标签空间Y={+1,-1}。一般来说,AdaBoost是一个迭代过程,其中在每次迭代t中计算最优弱分类器ht(x)。最终输出是强分类器它将弱分类器与最优权重αt相结合。每次迭代的目标是计算一个弱分类器给定训练样本的序列S以及{1,…,m}上的分布D,即S的索引上的分布D。可以通过最小化加权训练误差Zt来获得弱分类器。这里参考R.E.Schapire和Y.Singer的“Improvedboostingalgorithmsusingconfidence-ratedpredictions”,MachineLearning,37(3):297-336,1999):通过将αt折叠成ht,Zt和H可以分别表示为以及为了简化注释,在下面我们省略了ht、Dt和αt的下标t。可以通过域划分来实现Zt的最小化,参见例如R.E.Schapire和Y.Singer的“Improvedboostingalgorithmsusingconfidence-ratedpredictions”,MachineLearning,37(3):297-336,1999。特别地,每个弱分类器可以与X的划分相关联成不相交的块X1,….,XN,并且h(x)=h(x′)适用于所有x,x′∈Xj。h(x)的响应仅取决于给定样本x落入哪个块Xj。更具体地说,h(x)等于落入具有标签+1的块j中的样本的加权分数与落入具有标签-1的块j中的样本的加权分数的比率的函数。和被分别定义为以及使用和并且对于x∈Xj令cj=h(x),Zt可以被计算为:计算关于cj的Zt的导数并使其为零,得到最优解:将(8)代入(7)得到图5以图形方式支持该函数的效用。在图5中,虚线曲线分别是和的连续版本。用于计算和的块j中的样本数目是有限的,而对于在虚线曲线中计算它是无限的。在图5的上部中,虚线曲线在块#5处相交。所以对于j=1,...,5,对于j=6,...,9,并且对于j=1,...,4,对于j=5,...,9,因此,训练误差Zt(参见等式9)为:现在采用f(x;xc)来拉伸具有块#5内的中心xc的特征。因为f(x;xc)在xc附近具有大斜率,所以图5中的块#5被分散为块#4,#5和#6。相应地,在图5上部中的变为在图5下部中的和用a表示图2(a)中的分别用a1、a2和a3表示图的下部中的和然后我们有:a=a1+a2+a3(11)同时,在图5上部中的W-5变为在图5下部中的和用b表示图5上部中的分别用b1、b2和b3表示图5下部中的和然后我们有:b=b1+b2+b3(12)对应于图5的上部的训练误差Zt,即等式9,可以被重写为:对应于图5的下部的训练误差Z′t可以被表示为:可以证明(参见定理1的证明):Z′t<Zt(15)不等式15表明应用拉伸函数f(x;xc)降低了训练误差。更一般地说,我们有以下定理。定理1.考虑加权分数分别为和的块j。对应于块j的训练误差Zt为令xc为块j内的点。使用单调递增函数f(x-xc),块j的被拉伸到加权分数为a1,…,an(这里)的n个块。同样,相同块j的被拉伸到加权分数为b1,…,bn(这里)的n个块。对应于拉伸直方图的训练误差Z′t是然后拥有:证明.事实是以及因此,它等同于证明或者这里,不等式20是已知的柯西-布尼亚科夫斯基-施瓦茨(Cauchy-Buniakowsky-Schwarz)不等式。图5示出了使用失真函数的特征空间的失真,如上面已经简要讨论的。在图5的顶部示出了在使用失真函数x'=f(x)失真之前的特征空间区间。通过使用f(x)拉伸,直方图W-5被扩展到图的下部中的W-4,W-5和W-6。通过使用f(x)拉伸,直方图W+5被扩展为W+4,W+5和W+6。与图2类似,图5是示意性的,因为预计本发明的实际实施例中的直方图在形状上更复杂。在下文中,算法将被描述,其中训练阶段首先被描述,然后是测试阶段。拉伸函数f具有确定哪个部分将被扩展以及哪个部分将被缩小或压缩的参数xc。令xo为块j的中心,其中和之间的差值最小。图2表明令xc←xo是合理的。还可以在与xo相邻的区域中搜索,并且输出xc作为具有最小训练误差Zt的一个。值得注意的是,当直方图复杂或未找到最优xc时,拉伸一种特征可能不会改善分类性能。因此,在我们的算法的一些实施例中,如果不导致较低的训练误差,则拉伸不被应用。该算法被总结在以下算法中:测试阶段:值得注意的是,在训练阶段中,特征可以被f拉伸,然后,随后,加权分数和可以分别被计算。假设x?是一个在测试阶段要被分类的样本。一种策略是由f映射x?(结果用x′?表示,x′?=f(x?;xc),确定x′?属于哪个块,并且然后根据和来计算分类器响应ht,其中索引x′?所属的块。Δdlarge代表映射域中的块宽度或步长,并且代表向上取整函数,例如向无穷大取整。假设特征在[0,1]范围内,并且块的数目是N(典型值是N=256),那么Δdlarge=1/N。总的来说,由于拉伸函数,所提出的隐式非均匀域划分方法具有比经典域划分方法更少的加权训练误差和测试误差。INRIA行人数据集被用于显示加权训练误差。可以看出,所提出的方法的加权训练误差稳定地低于DP-AdaBoost的加权训练误差。因此,可以得出结论,拉伸函数对降低加权训练误差起着积极作用。差异在图6中被示出,其中虚线曲线对应于经典域划分AdaBoost,并且虚线曲线对应于所提出的隐式非均匀域划分INDP-AdaBoost。在图6中,Caltech行人数据集被用于比较测试误差。图6比较了采用ACF特征时所提出的INDP-AdaBoost与DP-AdaBoost的ROC曲线。对于ACF特征,参见P.Dollar,R.Appel,S.Belongie和P.Perona:“Fastestfeaturepyramidsforobjectdetection”,PAMI,36(8):1532-1545,2014。可以看出INDP-AdaBoost在所有操作点上都优于DP-AdaBoost。特别地,INDP-AdaBoost和DP-AdaBoost的对数平均不命中率分别为41.97%和44.51%。所提出的方法优于传统方法2.54%。图7是根据本发明的至少一些实施例的方法的流程图。所示方法的阶段可以在被布置为执行AdaBoost算法的设备中执行,例如,通过这种设备的控制设备。阶段710包括存储要被机器识别的数据。阶段720包括使用该数据运行自适应增强机器学习算法,其中多个学习算法被应用,其中特征空间被划分为区间,其中失真函数被应用于特征空间的特征。最后,阶段730包括其中失真函数的一阶导数不是常数。应当理解的是,所公开的本发明的实施例不限于本文公开的特定结构、处理步骤或材料,而是延伸至其等同物,如相关领域的普通技术人员将认识到的。还应当理解的是,本文采用的术语仅用于描述特定实施例的目的,而不是限制性的。贯穿本说明书对一个实施例或实施例的提及意味着结合该实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。因此,贯穿本说明书在各个地方出现的短语“在一个实施例中”或“在实施例中”不一定都指代相同的实施例。在使用术语(例如大约或基本上)参考数值的情况下,还公开了精确的数值。如本文所使用的,为方便起见,可以在共同列表中呈现多个项目、结构元素、组成元素和/或材料。但是,这些列表应该被解释为好像列表中的每个成员都被单独标识为一个独立且唯一的成员。因此,这种列表的任何个别成员不应仅仅根据其在一个共同组中的陈述而被解释为同一列表中任何其他成员的事实上的等同物而没有相反的指示。另外,本发明中的各种实施例和示例可以与其各种组件的替代物一起在此被提及。应当理解的是,这些实施例、示例和替代方案不应被解释为彼此的事实上的等同物,而是应被视为本发明的单独和自主的表现。此外,所描述的特征、结构或特性可以在一个或多个实施例中以任何合适的方式被组合。在前面的描述中,提供了许多具体细节,诸如长度、宽度、形状等的示例,以提供对本发明实施例的透彻理解。然而,相关领域的技术人员将认识到,可以在没有一个或多个具体细节的情况下或者利用其他方法、组件、材料等来实践本发明。在其他情况下,众所周知的结构、材料或操作未被示出或详细描述以避免模糊本发明的各方面。虽然前述示例在一个或多个特定应用中说明了本发明的原理,但是对于本领域普通技术人员来说显而易见的是,在不脱离本发明的原理和概念的情况下,可以在不运用创造性能力的情况下对形式、用法和实施细节进行多种修改。因此,除了通过下面提出的权利要求之外,并不意图限制本发明。动词“包括”和“包含”在本文中被用作开放限制,其既不排除也不要求也存在未记载的特征。除非另有明确说明,否则从属权利要求中所述的特征可相互自由组合。此外,应该理解的是,在整个本文件中使用“一个”,即单数形式,并不排除多个。工业实用性本发明的至少一些实施例在优化机器识别方面找到工业应用,例如,减少自动驾驶车辆中的交通事故。参考符号列表110视图101道路125感兴趣的区域120行人130相机140图像识别算法300–360图3的设备的结构410被拉伸的特征空间的区域710–730图7的方法的阶段引用列表[1]R.Abiantun和M.Savvides.Dynamicthree-binrealAdaBoostusingbiasedclassifiers:anapplicationinfacedetection.InProc.IEEEIntl’Conf.Biometrics:Theory,Applications,andSystems,2009。[2]Z.Fu,D.Zhang,X.Zhao和X.Li.Adaboostalgorithmwithfloatingthreshold.InACAI,2012。[3]R.E.Schapire和Y.Singer.Improvedboostingalgorithmsusingconfidence-ratedpredictions.MachineLearning,37(3):297-336,1999。[4]WenJ和XiongY.SmoothingLUTclassifiersforrobustfacedetection.InICIST,2013。[5]Y.Hanai和T.Kuroda.FacedetectionthroughcompactclassifierusingadaptiveLook-Up-Table.InICIP,2009。[6]C.Huang,H.Ai,T.Yamashita,S.Lao和M.Kawade.Incrementallearningofboostedfacedetector.InICCV,2007。[7]P.Sharma,C.Huang和R.Nevatia.Unsupervisedincrementallearningforimprovedobjectdetectioninavideo.InCVPR,2012。[8]Z.Li和YZhao.Pedestriandetectioninsingleframebyedgelet-LBPpartdetectors.InAVSS,2013。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1