一种流式数据处理自适应速率控制方法与流程
本发明属于计算机应用技术领域,涉及一种流式数据处理自适应速率控制方法。
背景技术:
当前,随着技术的发展,数据量日益增加,“大数据”技术已经渗透到各行各业。目前,许多设备都会收集大量的数据,并希望对数据及时处理从而发掘其中的价值。例如智能手机、传感器、物联网设备、社交网络和在线事务系统产生的数据都需要不断的收集,通过实时的对数据进行分析,从而实现快速响应。因此,如何提升数据实时分析处理的能力也成为一个十分重要的问题。
当前一些主流的大数据实时处理框架有Spark,Storm,Flink等。Spark Streaming是对Spark核心API的扩展,它是按照一定的时间间隔将任务分成一系列短小的批处理作业进行处理。Storm是以单条记录为粒度进行处理的流式处理系统,拥有良好的实时性。Flink和Spark类似,其核心是流式数据流引擎,为数据流上的分布式计算提供了数据分发、通信和容错。但是和Spark Streaming相比,Storm的吞吐量较低,且实现复杂的统计需求较为困难。Flink的批处理和流式处理是两个独立的模块,无法进行结合。Spark Streaming因为使用Micro-batch处理数据,可以达到较高的吞吐率,在满足秒级的实时性要求同时可以达到较高的效率。
流式处理系统需要良好的实时性,并且在处理突发任务时能保证系统的稳定。通常,流式处理架构通过以下几种方式保证系统的实时性和稳定性:1.当处理的负载超过系统处理能力上限时,通过丢弃部分数据降低工作负载;2.动态资源管理;3.动态批次大小。但是丢弃数据通常会造成计算结果不准确,动态资源 管理为了针对数据处理洪峰需要更多的硬件资源,动态批次大小使得运行延迟变得不确定。
集群的状态不是一成不变的,因而人为设置的静态数据处理速率上限可能是不准确的,太小可能造成在处理突发的速率增加时无法充分利用计算资源,太大则可能导致系统接收过多的数据,造成计算集群的高延迟,从而导致系统不稳定。
技术实现要素:
针对现有技术中存在的问题,本发明提供了一种海量数据的流式处理自适速率控制方法。该方法基于常用的数据汇总消息队列和流式数据分布式计算框架,根据当前计算集群的情况,通过预分片的方式调整数据处理的并行度,并通过自适应实时速率控制方法动态调整集群当前处理数据的数量,使得每一批输入数据的处理时间和批次间隔保持一致,保证计算集群的稳定性,降低数据流式处理的延迟。
用户可以利用本技术提供的方法实现如下功能:海量数据的实时接收和预处理;数据的实时处理;数据预分片及数据处理的并行化调整;实时处理数据数量的动态调整;处理结果输出到数据库中。
本发明的技术方案:
一种流式数据处理自适应速率控制方法,步骤如下:
第一步,数据接收和分区缓存
流式数据处理系统接收的数据,其格式由用户定义。要求一条完整的数据为一行,或者使用无歧义的特殊分隔符对数据进行分割。使用通用的消息队列作为数据源对数据进行汇总,并对数据按照分区规则将数据保存到消息队列中的某个分区中。本步骤使得消息队列中各个分片中的数据数量较为均匀,消息 队列中的数据供之后的步骤读取计算。
第二步,数据预分片
从消息队列中读取数据前,将消息队列中单个数据分片映射到多个流式数据处理集群的分片中,映射的数量根据集群虚拟核心数量进行设置;避免了之后在计算集群中对数据进行重新分片以及task发送到工作节点的消耗。预分片方式在将数据获取推迟到计算时进行,从而将原来的数据读取、重新分片、task连同分片发送到工作节点进行计算,这三个步骤整合为在计算时对按照分片规则分片的数据进行读取并计算。
分片的数量决定了系统能达到的最大的并行度,从而影响端到端延迟。方法在任务开始时确定了分片的数量,当集群的各个工作节点的性能差距不大时,可以设置分片数量为集群可用虚拟核心的整数倍,这样可以保证任务可以平均分配到每一个CPU核心上,避免正常运行过程中出现某个节点空闲的情况,从而充分利用硬件资源。
通过本步骤,系统得到了消息队列和流式数据处理集群之间分片的映射关系,之后数据读取按照该映射关系确定每一条数据的流向。
第三步,处理速率实时反馈控制
从消息队列中读取数据,并根据当前的数据处理速率上限确定最多可以从消息队列中读取的数据数量,避免读取的数据数量超过计算集群的最大处理能力;实时速率控制器的处理速率上限计算方法如下:
3.1)通过慢启动的方式开始进行调整,初始的数据处理速率上限设置为消息队列的每个分片每秒获取n条数据,50<n<1000;
3.2)第一批完成后,对以后每一批按照以下的步骤对数据处理速率上限进行计算;
3.2.1)在批次开始时,提交当前批次的开始时间t_batchst给速率控制器;
3.2.2)在批次完成时,提交当前批次的处理结束时间t_batched,处理该批次用时t_proclast,,该批次在批次队列中的等待时间t_waitlast,该批次处理数据的数量elemnumlast;
3.2.3)在当前批次提交时,对当前批次的数据处理速率上限进行计算,分为以下三种情况:第一种情况,在当前批次提交时,上一批次执行完成,且上一批次数据的处理时间与流式数据批处理集群的批次间隔t_interval相差大于松弛参数prelx;第二种情况,当前批次提交时,上一批次执行完成,且上一批次数据的处理时间位于t_interval-prelx和t_interval之间,prelx=min(50,t_interval×0.05);第三种情况,当前批次提交时,上一批次尚未完成。
第一种情况和第三种情况都基于PID控制算法对数据处理速率上限计算:
newRate=latesRate-Kp×error-Ki×historicaiError-Kd×dError (1)
其中,latestRate为最新处理完成批次的数据处理速率上限;Kp为比例系数,取值为1;error为数据处理速率的估计误差;Ki为积分系数,取值为0.2;historicalError为数据处理速率的累积误差;Kd为微分系数,为了减小噪声数据对系统的影响,取值为0;dError为偏差速率变化率;
数据处理速率的估计误差error为:
其中,elemnumlast为最新处理完成的批次处理数据的数量;t_proclast为最新处理完成的批次处理的时间;Kblock为阻塞系数,阻塞系数取值0.3;blockTime为估计的处理时间增加值;当为第一种情况时,blockTime取值为0,此时由公 式(2)计算得到的结果为数据处理速率的估计误差;当为第三种情况时,blockTime计算如公式(3)所示:
blockTime=max(t_interval-(submit_time-t_batchst),brelx) (3)
其中,t_interval为批次提交的间隔;submit_time为任务的提交时间;在批次间隔大于1000ms时,brelx=50ms,当批次间隔小于1000ms时,brelx=t_interval×0.05;
数据处理速率的累积误差historicalError的计算如公式(4)所示:
其中,t_waitlast为最新处理完成的批次在批次队列中等待的时间;当为第一种情况时,blockTime取值为0;当为第三种情况时,blockTime计算如公式(3)所示;processingRate表示最新处理完成批次的数据处理速率,其计算如公式(5)所示:
偏差速率变化率dError的计算如公式(6)所示:
其中,latestError表示前一个处理完成批次的速率估计误差,delaySinceUpdate表示前一个处理完成批次和最近完成批次之间经过的时间,其计算方式如公式(7)所示:
delaySinceUpdate=lastProcessingEndTime-latestTime (7)
第二种情况,使用最新处理完成批次的数据处理速率上限latestRate作为当前批次的数据处理速率上限newRate;
进一步地,如果最新完成的三个批次的处理时间都位于t_interval-prelx和t_interval之间时,则使用公式(8)对速率上限进行计算:
其中rlast表示最新完成批次的处理速率,r2nd-last表示倒数第二个完成批次的处理速率,r3rd-last表示倒数第三个完成批次的处理速率。
第四步,数据的读取和实时处理。流式数据批处理集群按照计算好的数据处理速率上限和预分片规则对数据进行读取。在预分片的过程中,只是获取了当前批次需要从消息队列各个分片中获取数据的partition ID、起始偏移量和终止偏移量。数据只有在流式数据批处理集群开始处理时才进行读取。在本批次数据处理完成之后,将结果实时输出到数据库中。
进一步地,所述的第一步的数据接收和分区缓存的具体方法为:
消息队列中包含多个主题的信息,一个主题为一类消息,每个主题将被分成多个分区。为了避免数据倾斜,消息队列在接收到数据后,按照分片规则将数据缓存到消息队列的某个分区中。数据分区的流程如图3所示。
消息队列从数据源中接收数据。在接收到数据后,按照以下方法对数据发送到哪个消息队列的分区进行计算:
partNum=MD5(key)mod numPartition
其中key表示数据的ID,如果数据没有ID,则以随机数来替代,MD5(key)表示数据key的MD5值,numPartition表示消息队列分区的数量。消息队列将数据按照partNum指示的ID保存在消息队列指定的分区中,等待消费者对数据进行读取。
进一步地,所述的第二步的预分片的具体方法为:
1)流式数据处理集群以批次的时间间隔为周期,获取消息队列的分片信息; 对于每一个批次,计算集群都需要获取消息队列中的n个数据分片,则消息队列中数据分片信息表示为s_partition=(s_partitioni|i=1...n);对于当前批次,消息队列每一个分片s_partitioni的信息包括:分片所属的主题topic、消息队列分片的唯一ID、当前批次需要获取的数据在消息队列指定分片中的起始位置start_offset、当前批次需要获取的数据在消息队列指定分片中的终止位置end_offset。
2)流式数据处理集群将批次信息提交到批次消息队列中;在集群没有开始对数据进行处理之前,即前一批次的数据尚未处理完成时,数据并未真正读到计算集群中,提交的只有消息队列的分片的信息。
3)根据当前批次的消息队列分片信息计算流式数据处理集群的分片对应消息队列中哪一个分片的哪一部分数据。
3.1)计算消息队列中分片的数量source_num和流式数据处理集群中空闲虚拟核心的数量core_num的最小公倍数为spark_num,并由此得到每一个消息队列分片需要映射到的流式数据批处理集群的分片数量为map_num=spark_num/source_num。
3.2)计算消息队列和流式数据处理集群分片的映射关系;对消息队列中当前批次的每一个分片的信息s_partition=(s_partitioni|i=1...n)进行处理;获取当前分片s_partitioni中数据的数量elem_num=end_offset-start_offset+1,将当前批次消息队列一个分片中的数据平均分配到map_num个流式数据处理集群的分片中,每一个流式数据处理集群分片中的数据量为each_num=elem_num/map_num;若当前批次数据源分片中的数据无法被map_num整除,则先计算多余出来的数据的条数为left_num=elem_num%map_num,在每一个消息队列分片对应的map_num个流式 数据处理集群分片中前left_num个数据分片中的数据数量为eachnum+1,其余map_num-left_num个分片中数据量为eachnum。
进一步地,所述的第四步的数据读取和实时处理的具体方法为:
1)对消息队列中每一个分片中进行处理,若分片中未处理的数据量小于newRate×tinterval÷s_partition,则直接读取该分片的所有剩余未处理数据,否则,该分片读取数据数量为newRate×tinterval÷s_partition。
2)消息队列的单个分片对应流式数据处理集群的多个分片,由于预分片已经实现了这种一对多的映射,因此流式数据处理集群在将数据读取到集群的工作节点之后,每一个流式数据处理集群的分片生成一个任务,并且在工作节点本地执行,执行结束后将结果保存到下游数据库中。
进一步地,所述的消息队列为Kafka、Flume、Kinesis或者其他适用于流式数据处理的消息队列。
进一步地,所述的流式批处理计算框架为Spark、Flink或者其他适用于流式数据计算的框架。
本系统由消息队列,海量流式数据,流式数据计算框架,数据分区,数据预分片算法,自适应实时速率控制算法组成。其中消息队列用于对多个数据源的数据进行汇总收集,用于支持海量数据的实时汇总分发以及数据暂存。其上游可以是多个数据服务器,下游为数据实时计算框架。流式数据计算框架从上游数据队列接收数据,并按照一定的时间间隔将任务分成若干个小的批处理作业,从而实现准实时的数据处理。
系统实时接收数据进行处理,数据分区在消息队列的数据生产者端实现,方法以每一条数据的ID为依据对分区进行计算;数据预分片算法根据消息队列的分区数和流式数据处理集群的虚拟核心数量确定分片关系;自适应实时速率 控制算法由Scala实现,通过控制器实时跟踪当前计算集群任务处理状态,确定数据处理速率上限值。
本发明的有益成果:本发明通过将数据分区、预分片、自适应实时速率控制和流式数据处理框架结合,对海量数据进行实时处理。本发明有如下优点:1)低延迟:通过对数据预分片提升数据处理的并行度,每条数据直接由计算该条数据的节点进行读取,避免了计算集群先接收数据之后再进行重新分片造成的网络带宽消耗、磁盘读写消耗以及任务分发的延迟。2)高稳定性:根据计算集群实时的处理状态,动态调整流入计算集群的数据量,使得数据处理时间和批次间隔保持一致,从而保证计算集群任务队列中的任务能按时完成,避免突发数据量增加导致的队列阻塞。3)应用:大数据技术逐步深入到各个行业中,面对持续大量的数据流,实时数据处理系统需要快速响应处理。本发明适用于多种基于批次的流式数据处理系统,应用范围广泛。
附图说明
图1是本方法采用的系统架构图。
图2是本方法的整体处理流程图。
图3是本方法的数据分区示意图。
图4是流式批处理系统的数据处理流程。
图5(a)是重新分片的数据流向示意图。
图5(b)是预分片方法的数据流向示意图。
图6展示了批次队列的详细结构和不同阶段所执行的操作。
图7展示了自适应速率控制器的整体结构。
图8是repartition方式和预分片方式的处理延迟示意图。
图9是流式数据的生成速率。
图10是本方法的排队延迟图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
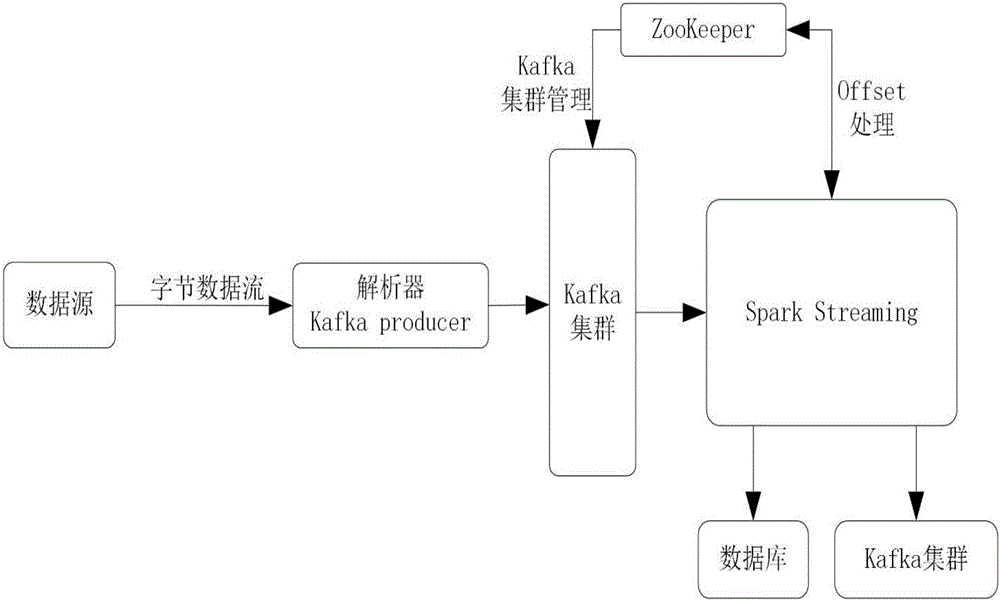
系统架构如图1所示。系统可以使用多种数据源,发送的字节数据流通过解析器进行解析,系统使用Kafka作为消息队列对数据进行汇总缓存。数据源中解析得到的数据通过Kafka的producer发送到Kafka集群。系统使用Spark Streaming对数据进行流式处理。Kafka集群作为Spark Streaming的上游数据源,Spark Streaming持续拉取数据进行计算。Zookeeper对当前处理数据的偏移量进行记录,数据库和下游Kafka集群用于输出结果的管理。
本方法的处理流程如图2所示。数据源持续产生大量的数据,首先解析数据并通过数据分区规则将数据汇总到Kafka消息队列集群中,提供给后续计算集群读取。读取数据时根据预分片算法得到的分片结果对数据进行读取。读取数据的数量由当前消息队列中拥有的数据量和数据处理速率上限共同决定。数据处理速率上限由基于PID的自适应实时速率控制算法计算,通过周期读取集群的当前状态和批次计算的信息来保证计算的准确性。在数据处理结束后将数据输出存储到下游数据库。
首先数据源持续大量的产生数据,Kafka消息队列接收数据后对数据进行解析,并按照给定的数据分区方法计算数据的分区,并提交到Kafka集群中指定的partition中,数据分区的过程如图3所示。数据分区之后,数据源中的数据缓存到Kafka集群的多个partition中,用于下游计算集群拉取处理。
接下来Spark Streaming从Kafka消息队列中拉取数据并将数据组织为批次提交到批次队列。图4为流式批处理系统的创建处理流程。批次生成器从Kafka消息队列接收数据,并按照一定的时间间隔将数据组织为批次,一个批次有多个分片,批次生成之后放在批次队列中。Streaming processor按先后顺序从批次队列中获得一个批次进行处理,之后将处理结果输出。
方法在将数据组织为批次并提交到批次队列时,提交的实际上为批次的信息,而数据在批次队列中之前的批次都处理完之后才进行读取并处理。批次中每一个分片的信息通过预分片的方式来进行计算。图5(a)为传统的数据接收架构,没有采用预分片的方式。使用Direct方式接收数据,Kafka的分片和Spark的分片数量是一一对应的。因此在数据接收之后为了增加并行性,需要重新分片。图5(b)是预分片方式的数据接收架构。Spark集群按照预分片规则对数据进行接收,一个Kafka分片中的数据被平均分配到了多个Spark Streaming的分片中。
流式批处理系统由于是一种准实时的数据处理系统,数据不会在提交之后立刻被执行,而是一小段时间内的多条数据组成一个批次,按照批次对数据进行处理。因此数据处理的过程分为三个阶段,分别为批次提交、批次开始处理、批次处理完成。图6解释了在批次处理的不同阶段,分别需要进行的操作。以batch1到batch3的提交为例进行分析。首先批次按照固定的时间间隔进行提交,因此首先执行第一步:batch2提交时根据上一批次的执行情况计算速率上限,但是batch2在提交之后并未立刻开始执行,而是等到batch1完成之后,才开始执行第二步:batch1完成,接收并处理批次2。在第一步开始经过了batch interval之后,执行第三步:batch3提交时根据上一批次的执行情况计算速率上限。从batch2提交到batch3提交经过的时间就是batch interval。之后当batch2完成时,batch3开始接收并处理。
在每次批次提交时,该批次的数据处理速率上限已经由速率控制模块计算确定。图7解释了自适应速率控制模块的设计结构。速率控制器仍然基于Spark Streaming设计实现。Spark的Job生成器从数据源接收数据,生成Spark Streaming需要处理的Job。Job生成器在生成Job时获取速率控制器计算的速率上限,并将Job发送给Job处理器。Job处理器按顺序处理Job,并且将batch的信息发送给速率控制器。速率控制器使用批次的统计信息,利用自适应速率控制算法计算数据处理速率上限,并将信息反馈给Spark的Job生成器。用于控制下一批的数据数量。在执行期间,速率控制器一直监听Job的处理情况,在batch 提交时、batch开始时、batch完成时分别获取控制器需要的不同阶段的batch统计数据。
对于本发明对性能的提升,该部分说明预分片方法和重新分片方法处理相同数量数据所需的时间对比。图8展示了预分片方式和重新分片repartition方式的处理延迟。集群限定每个partition每秒读取数据量上限为40000条数据,提交batch的时间间隔限定为4秒,不进行速率反馈控制使得每一批接收的数据量始终保持最大值。限定数据locality优先级改变的时间间隔为100毫秒。采用原始的Spark Streaming数据接收方法,每个批次执行的时间平均为7秒,其中数据接收的时间约为3秒,数据处理的时间约为4秒。预分片的方法接收并处理数据,每个批次执行的时间平均为5秒,包括数据接收和数据处理的时间。
图9表示了数据源生成模拟数据的速率。数据源生成数据的速率以10秒为周期,每个周期前半部分生成60万条数据。这个数据量超过了Spark Streaming的平均处理速率,用于模拟数据量突然增加的情形。
图10用于评估本方法对性能的提升。Spark Streaming计算的批次间隔为1秒,每一条数据计算的时间复杂度为线性时间复杂度。对于原始的控制算法和自适应实时速率控制算法进行对比,对比主要为排队延迟scheduling delay,表示每个batch在队列中等待前一个batch完成处理所等待的时间;
sdelay=t_batchst-submit_time
其中sdelay表示scheduling delay,t_batchst表示批次开始时间,
submit_time表示批次提交时间。
Scheduling delay由平均106.18毫秒降低到62.89毫秒。
- 还没有人留言评论。精彩留言会获得点赞!