一种最优点个数约束的数据流处理系统多目标优化方法与流程
本发明涉及一种用于数据流处理系统的多目标优化方法,尤其涉及一种最优点个数约束的数据流处理系统多目标优化方法,属于计算机应用技术以及实时大数据分析领域。
背景技术:
近年来涌现出大量实时性大数据分析应用,比如社交网络动态分析、智能交通数据分析、大规模数据中心监控、基因数据分析等。这类应用不但数据量大而且数据持续快速产生或更新,要求数据分析系统持续并实时的返回或更新分析结果,我们称之为实时大数据(big&fastdata)分析。此类应用对实时大数据分析系统具有迫切需求,需要系统对响应延迟、吞吐率方面给出量化保证。实时大数据分析系统的多目标优化对于提供有服务质量保障的实时大数据分析云服务、为国家关键行业及重要监控应用提供实时大数据分析平台及优化框架具有重要意义。
目前,实时大数据分析应用中用户对响应延迟以及吞吐率的要求,依赖于历史经验,由it人员为数据流处理系统中的分析作业手工配置合适的执行计划,缺乏对实时大数据分析响应延迟和吞吐率的量化保证;即使经验丰富的it人员也不能保证配置了较优的执行计划,从而导致分析作业运行效率低下,无法满足上层应用对实时性的要求。
已有的基于权重加和的多目标优化方法虽然解决了在一定条件约束下凸目标函数的响应延迟和吞吐率的帕累托最优问题,但不能解决凹目标函数情况的帕累托最优问题;另外基于权重加和的多目标优化方法返回给用户的解密度不等、难以解释且不具有代表性,用户实际上需要在帕累托曲线上有代表性的一组解。因此,基于权重加和的多目标优化方法不能满足it人员交互场景下的多目标优化。实际应用中迫切需要一种在给定了帕累托最优点个数约束的情况下,选取给定数量的一组具有典型代表意义的帕累托最优解。
本方法针对实时大数据中两个重要的指标——响应延迟和吞吐率,而设计的多目标优化方法。基于给定的响应延迟和吞吐率模型,构建多目标优化方法,从而保证选取最优的执行计划。
技术实现要素:
针对已有的基于权重加和的多目标优化方法中没有考虑用户在部署使用时在响应延迟和吞吐率上存在取舍的情况,而造成帕里托最优解随机的缺陷,提出了一种最优点个数约束的数据流处理系统多目标优化方法。
本发明要解决的技术问题是:针对数据流处理系统多目标优化问题,能够避免帕累托最优解随机的缺陷,高效地得到一组用户给定数量且具有典型代表意义的帕累托最优解,为用户在响应延迟和吞吐率上提供选择空间。
本发明的目的是通过下述技术方案实现的:
一种最优点个数约束的数据流处理系统多目标优化方法,根据用户所指定的响应延迟的上下界以及吞吐率的上下界,给出不确定区域面积;基于缩小不确定区域面积这一目标,将不确定区域一分为二,继续探测面积最大的不确定区域,直到迭代上限,进而高效地得到一组具有典型代表意义的帕累托最优解,且最大化的降低了整体的不确定区域面积,为用户在响应延迟和吞吐率上提供选择空间。
一种最优点个数约束的数据流处理系统多目标优化方法,包括如下步骤:
步骤1:输入当前响应延迟的上界、当前响应延迟的下界以及帕累托最优点个数上限,初始化当前迭代步数、不确定区域集合以及初始化最终探测结果组;
其中,当前响应延迟的上界,记为lupper;当前响应延迟的下界,记为llower;帕累托最优点个数上限,记为stepmax;当前迭代步数,记为stepnow,初始化为0,表达式为公式(1);不确定区域集合,记为setarea,初始化为空集合,表达式为公式(2);最终探测结果组,记为plan,初始化为空集合,表达式为公式(3):
stepnow=0;(1)
步骤2:分别根据步骤1的当前响应延迟的上界和当前延迟的下界计算当前吞吐率的上界和下界,具体为:
步骤2.1:根据当前响应延迟的上界计算当前吞吐率的上界,具体通过如下公式(4)计算:
其中,当前吞吐率的上界,即tupper,s.t.代表约束;c代表具体系统配置;λ代表实时的输入数据率;γ(c,λ)代表具体系统的参数配置c和实时的输入数据率λ条件下的吞吐率;ψ(c,λ)代表具体系统的参数配置c和实时的输入数据率λ条件下的响应延迟;公式(4)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于当前响应延迟的上界lupper的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(4)中的
步骤2.2:根据当前响应延迟的下界计算当前吞吐率的下界,具体通过如下公式(5)计算如下:
其中,当前吞吐率的下界,记为tlower,公式(5)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于当前响应延迟的下界llower的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(5)中的
步骤3:分别根据当前响应延迟的上界和当前响应延迟的下界计算当前的探测响应延迟、最大探测吞吐率以及最大探测吞吐率的具体系统配置,具体为:
步骤3.1:根据lupper和llower,计算当前探测响应延迟,记为lmiddle,具体通过如下公式(6)计算:
lmiddle=(llower+lupper)/2;(6)
步骤3.2:根据步骤3.1计算出的当前探测响应延迟计算当前探测响应延迟的最大探测吞吐率和最大探测吞吐率的具体系统配置,分别记为tmiddle、cmiddle,具体通过如下公式(7)计算:
其中,公式(7)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于等于当前探测延迟lmiddle的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(7)中的
步骤4:计算当前探测结果组,并与最终探测结果组合并;
其中,最终探测结果组,记为plan;步骤4,具体为:
步骤4.1:根据当前的探测响应延迟lmiddle、最大探测吞吐量tmiddle以及最大探测吞吐率的具体系统配置cmiddle,计算当前探测结果组,记为planmiddle,具体通过如下公式(8)计算:
planmiddle={(lmiddle,tmiddle,cmiddle)};(8)
步骤4.2:将当前探测结果组planmiddle与最终探测结果组plan合并,具体通过如下公式(9)计算:
plan=plan∪planmiddle;(9)
步骤5:根据当前的响应延迟的上界和当前的响应延迟的下界、吞吐率的上界和吞吐率的下界、探测响应延迟以及最大探测吞吐率tmiddle,分别计算当前左半部分和右半部分的不确定区域面积;
其中,当前的响应延迟的上界,即lupper;和当前的响应延迟的下界,记为llower;吞吐率的上界,即tupper;吞吐率的下界,即tlower;探测响应延迟,即lmiddle以及最大探测吞吐率,即tmiddle;步骤5,具体为:
步骤5.1:根据当前的响应延迟的下界llower和探测响应延迟lmiddle以及当前的吞吐率的下界tlower和最大探测吞吐率tmiddle,计算当前左半部分的不确定区域面积,记为ualeft,具体通过如下公式(10)计算:
ualeft=(lmiddle-llower)×(tmiddle-tlower);(10)
步骤5.2:根据当前的响应延迟的上界lupper和探测响应延迟lmiddle以及当前的吞吐率的上界tupper和最大探测吞吐率tmiddle,计算当前右半部分的不确定区域面积,记为uaright,具体通过如下公式(11)计算:
uaright=(lupper-lmiddle)×(tupper-tmiddle);(11)
步骤6:根据步骤5输出的当前左半部分和右半部分的不确定区域面积计算所对应的不确定区域,并将不确定区域存储在不确定区域集合中;
其中,不确定区域集合,即setarea;步骤6,具体为:
步骤6.1:通过如下公式(12)和(13)计算当前左半部分和右半部分的不确定区域面积所对应的不确定区域,分别记为arealeft和arearight:
arealeft={(llower,lmiddle,tlower,tmiddle,ualeft)};(12)
arearight={(lmiddle,lupper,tlower,tmiddle,uaright)};(13)
其中,在arealeft与arearight的一般结构体area中,第一个参数为不确定区域的响应延迟下界,记为area.llower,第二个参数为不确定区域的响应延迟上界,记为area.lupper,第三个参数为不确定区域的吞吐率下界,记为area.tlower,第四个参数为不确定区域的吞吐率下界,记为area.tupper,第五个参数为不确定区域的面积,记为area.ua;
步骤6.2:将左半部分不确定区域arealeft和arearight存储在不确定区域集合setarea中,具体通过如下公式(14)计算:
setarea=setarea∪arealeft∪arearight;(14)
步骤7:在步骤6输出的不确定区域集合中,寻找不确定区域面积最大的不确定区域,并将此不确定区域面积最大的不确定区域从不确定区域集合中移除,具体为:
步骤7.1:在不确定区域集合setarea中,寻找不确定区域面积最大的不确定区域,记为areamax,具体通过如下公式(15)计算:
其中,area代表不确定区域并属于不确定区域集合setarea;上式反映的是,在不确定区域集合setarea中,寻找不确定区域面积areaua最大的不确定区域areamax;
步骤7.2:将不确定区域面积最大的不确定区域areamax从不确定区域集合setarea中移除,具体通过如下公式(16)计算:
setarea=setarea-areamax;(16)
步骤8:将当前迭代步数加1,即通过公式(17)修正:
stepnow=stepnow+1;(17)
其中,当前迭代步数,即stepnow;
步骤9:判断是否达到帕累托最优点个数上限,决定是否继续进行迭代探测;
其中,帕累托最优点个数上限,即stepmax;步骤9,具体为:
步骤9.1:若当前迭代步数stepnow小于帕累托最优点个数上限stepmax,则用不确定区域面积最大的不确定区域areamax来更新当前响应延迟的下界llower和上界lupper,当前吞吐率的下界tlower和上界tupper,具体通过公式(18)到公式(21)进行更新;再跳至步骤3:
llower=areamax.llower;(18)
lupper=areamax.lupper;(19)
tlower=areamax.tlower;(20)
tupper=areamax.tupper;(21)
步骤9.2:若当前迭代步数stepnow大于或等于帕累托最优点个数上限stepmax,则终止迭代,并返回最终探测结果组plan,即为数据流处理系统多目标优化的一组具有典型代表意义的帕累托最优解;
至此,从步骤1到步骤9,完成了一种最优点个数约束的数据流处理系统多目标优化方法。
有益效果
本发明一种最优点个数约束的数据流处理系统多目标优化方法,与其他多目标优化方法相比,具有如下有益效果:
1.本发明所提方法基于响应延迟的上下界,基于帕累托最优点与约束最优化解的关系,使用有限步数来确定探测深度;
2.本发明所述方法基于缩小不确定区域面积这一目标,通过贪心的方法每次探测不确定区域面积最大的部分,提高探测具有典型代表意义帕累托最优解的效率;
3.本发明所述方法能够在用户指定的响应延迟或吞吐率范围内,返回一系列有意义且具有代表性的帕里托最优解,确保用户能在该范围内接受想要的最优解;
4.本发明所述方法,适用于不同的实时大数据分析系统多目标优化场景中,应用范围广,实用性强,易于推广;
5.本发明所述方法,只针对数据本身进行处理,能够得到一组具有典型代表意义的帕累托最优解,而不受限于数据的来源,适用于对所有的工程应用中的数据的处理。
附图说明
图1为本发明“一种最优点个数约束的数据流处理系统多目标优化方法”中的本方法及实施例1中的流程示意图;
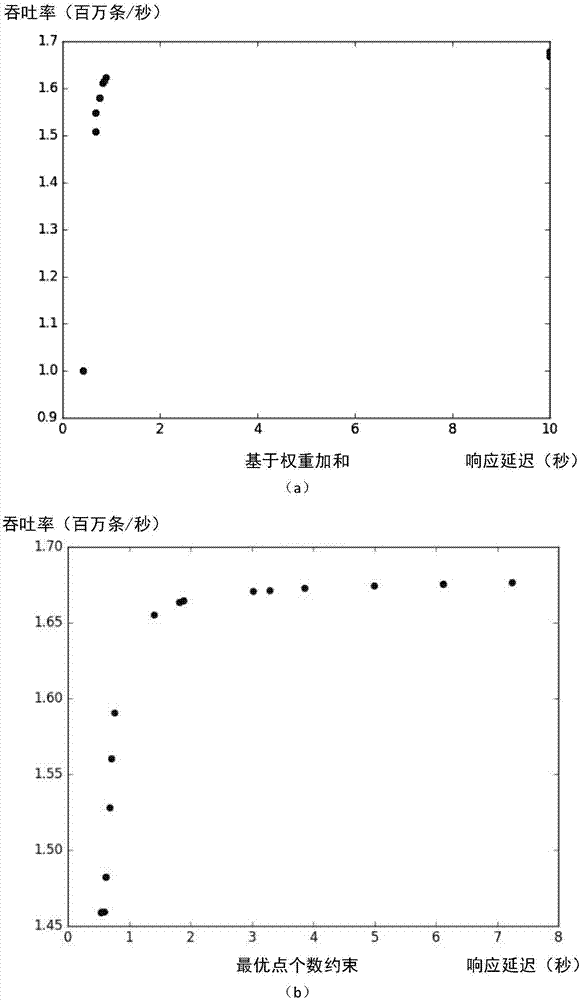
图2为本发明“一种最优点个数约束的数据流处理系统多目标优化方法”实施例1中的本方法与权重加和的实验对比图。
具体实施方式
下面根据附图及实施例对本发明进行详细说明,但本发明的具体实施形式并不局限于此。
实施例1
本实施例阐述了将本发明“一种最优点个数约束的数据流处理系统多目标优化方法”应用于具体的实时大数据分析系统apachesparkstreaming场景下的流程。
图1为本方法的算法流程图以及本实施例的流程图。从图中可以看出,本方法包含如下步骤:
步骤a:当前响应延迟的上界lupper被初始化为10.0,当前响应延迟的下界llower被初始化为0.5,帕累托最优点个数上限stepmax被初始化为20,当前迭代步数stepnow被初始化为0,表达式为公式(1),不确定区域集合setarea被初始化为空集合,表达式为公式(2);最终探测结果组plan被初始化为空集合,表达式为公式(3):
步骤b:分别根据步骤a的当前响应延迟的上界10.0和下界0.5,分别计算当前吞吐率的上界和下界,具体为:
步骤b.1:根据当前响应延迟的上界10.0,计算当前吞吐率的上界tupper为1677367.1230139078,具体通过如下公式(22)计算:
其中,当前吞吐率的上界,即tupper,s.t.代表约束;c代表具体系统配置;λ代表实时的输入数据率;γ(c,λ)代表具体系统的参数配置c和实时的输入数据率λ条件下的吞吐率;ψ(c,λ)代表具体系统的参数配置c和实时的输入数据率λ条件下的响应延迟;公式(22)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于当前响应延迟的上界lupper的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(22)中的
步骤b.2:根据当前响应延迟的下界0.5,计算当前吞吐率的下界tlower为1288034.188034188,具体通过公式(23)计算如下:
其中,当前吞吐率的下界,记为tlower,公式(23)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于当前响应延迟的下界llower的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(23)中的
步骤c:分别根据当前响应延迟的上界10.0和下界0.5,计算当前的探测响应延迟lmiddle、最大探测吞吐率tmiddle以及最大探测吞吐率的具体系统配置cmiddle,具体为:
步骤c.1:根据当前响应延迟的上界10.0和下界0.5,计算当前探测响应延迟lmiddle为5.25,具体通过如下公式(24)计算:
lmiddle=(llower+lupper)/2=(10.0+0.5)/2=5.25;(24)
步骤c.2:根据步骤c.1计算出的当前探测响应延迟5.25,计算当前探测响应延迟的最大探测吞吐率tmiddle和最大探测吞吐率的具体系统配置cmiddle,分别为1674561.0772396186、c1,具体通过如下公式(25)计算:
其中,公式(25)反映的是给定输入数据率λ,在满足响应延迟ψ(c,λ)小于等于当前探测延迟lmiddle的一组具体系统的参数配置c中,寻求能使吞吐率γ(c,λ)最大化的具体系统配置c,即公式(25)中的
步骤d:计算当前探测结果组planmiddle,并与最终探测结果组plan合并。
步骤d.1:根据当前的探测响应延迟5.25、最大探测吞吐量1674561.0772396186以及最大探测吞吐率的具体系统配置c1,计算当前探测结果组planmiddle为{(5.25,1674561.0772396186,c1)},具体通过如下公式(26)计算:
步骤d.2:将当前探测结果组{(5.25,1674561.0772396186,c1)}与最终探测结果组plan合并,具体通过如下公式(27)计算:
步骤e:根据当前的响应延迟的上界10.0和下界0.5、吞吐率的上界1677367.1230139078和下界1288034.188034188、探测响应延迟5.25以及最大探测吞吐率1674561.0772396186,分别计算当前左半部分和右半部分的不确定区域面积。
步骤e.1:根据当前的响应延迟的下界0.5和探测响应延迟5.25以及当前的吞吐率的下界1288034.188034188和最大探测吞吐率1674561.0772396186,计算当前左半部分的不确定区域面积ualeft为183600.2723725793,具体通过如下公式(28)计算:
步骤e.2:根据当前的响应延迟的上界10.0和探测响应延迟5.25以及当前的吞吐率的上界1677367.1230139078和最大探测吞吐率1674561.0772396186,计算当前右半部分的不确定区域面积uaright为13328.71742787275,具体通过如下公式(29)计算:
步骤f:根据步骤e输出的当前左半部分和右半部分的不确定区域面积计算所对应的不确定区域,并将不确定区域存储在不确定区域集合setarea中。
步骤f.1:计算当前左半部分和右半部分的不确定区域面积所对应的不确定区域,分别为{(0.5,5.25,1288034.188034188,1674561.0772396186,183600.2723725793)}、{(5.25,10.0,1674561.0772396186,1677367.1230139078,13328.71742787275)},计算公式如下:
其中,在arealeft与arearight的一般结构体area中,第一个参数为不确定区域的响应延迟下界,记为area.llower,第二个参数为不确定区域的响应延迟上界,记为area.lupper,第三个参数为不确定区域的吞吐率下界,记为area.tlower,第四个参数为不确定区域的吞吐率下界,记为area.tupper,第五个参数为不确定区域的面积,记为area.ua。
步骤f.2:将左半部分不确定区域
{(0.5,5.25,1288034.188034188,1674561.0772396186,183600.2723725793)}和
{(5.25,10.0,1674561.0772396186,1677367.1230139078,13328.71742787275)}
存储在不确定区域集合setarea中,通过如下公式(32)计算:
步骤g:在步骤f输出的不确定区域集合setarea中,寻找不确定区域面积最大的不确定区域,并将其从不确定区域集合setarea中移除。
步骤g.1:在不确定区域集合setarea中,寻找不确定区域面积最大的不确定区域为areamax为{(0.5,5.25,1288034.188034188,1674561.0772396186,183600.2723725793)},具体通过公式(15)计算;
其中,area代表不确定区域并属于不确定区域集合setarea;上式反映的是,在不确定区域集合setarea中,寻找不确定区域面积areaua最大的不确定区域areamax。
步骤g.2:将不确定区域面积最大的不确定区域{(0.5,5.25,1288034.188034188,1674561.0772396186,183600.2723725793)}从不确定区域集合setarea中移除,具体通过如下公式(33)计算:
步骤h:将当前迭代步数加1,即通过公式(34)修正:
步骤i:判断是否达到帕累托最优点个数上限20,决定是否继续进行迭代探测。
步骤i.1:若当前迭代步数1小于帕累托最优点个数上限20,则用不确定区域面积最大的不确定区域
{(0.5,5.25,1288034.188034188,1674561.0772396186,183600.2723725793)}
来更新当前响应延迟的下界llower为0.5和上界lupper为5.25,当前吞吐率的下界tlower为1288034.188034188和上界tupper为1674561.0772396186,具体通过公式(35)到公式(38)进行更新;再跳至步骤c:
步骤i.2:若当前迭代步数1大于或等于帕累托最优点个数上限20,则终止迭代,并返回最终探测结果组plan,即为数据流处理系统多目标优化的一组具有典型代表意义的帕累托最优解;
至此,从步骤a到步骤i,完成了本实施例一种最优点个数约束的数据流处理系统多目标优化方法。
本方法与权重加和的实验对比图如图2所示。其中,横坐标代表响应延迟(秒),纵坐标代表吞吐率(百万条/秒),图中的点代表某响应延迟下所能取得的最大吞吐率,即帕累托最优解。图2(a)表示,权重加和方法,图2(b)表示本方法。从图2中可以看出,权重加和的帕累托最优解集中于小部分的区域内,不能表示响应延迟与吞吐率在整个空间内的分布情况,不能提供给用户一组具有典型代表意义的帕累托最优解;本方法的解集在整个空间内分布均匀,能为用户提供响应延迟与吞吐率的多种最优选择,即能提供给用户一组具有典型代表意义的帕累托最优解。
实施例2
将实施例1中的具体的实时大数据分析系统apachesparkstreaming改成其他实时大数据分析系统如apachestorm、googledataflow等,即本发明所提出的多目标优化方法不受限于数据的来源,适用于对所有的工程应用中的数据的处理。
上述实施方式中未述及的有关技术内容采取或借鉴已有技术即可实现。
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!