一种基于位置的社交大数据信息最大化方法与流程
本发明涉及一种社交大数据影响力研究技术,特别涉及基于位置信息的在线社交网络信息最大化方法。
背景技术:
随着互联网的发展和移动终端的普及,在线社交网络得到飞速的发展与关注。社交网络信息最大化的研究具有很实际的现实意义,利用社交大数据中的友好关系与特征来进行口碑营销和“病毒式传播”越来越成为研究的重点,它在市场营销、广告发布等方面有十分重要的应用。现有的信息传播模型和信息最大化技术大多只针对了一般的社交网络中的友好关系,而没有与具体的实际联系起来,只是利用了在线社交网络上用户之间的友好关系,只要激活,就会去影响周围的好友,而没有考虑用户被激活后是否会和好友去分享,如果不分享那信息便不会得到传播。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于位置的社交大数据信息最大化方法,该方法针对基于位置的社交网络,挖掘社交大数据中用户签到的位置信息,对信息传播过程进行建模,考虑了用户愿意分享传播的可能性以及距离对于用户行为的影响,提供了一种基于位置的在线社交网络中信息最大化的方法。这里的信息最大化是指,给定一个需要传播的信息和种子节点的数目,根据所设计的方法选出种子节点激活他们(比如优惠券或者是免费样品),让他们利用社交网络去进行信息的传播,去影响他们的朋友,被激活的朋友再去影响朋友的朋友,使得最后被影响的人数最多。
本发明的目的通过以下的技术方案实现:一种基于位置的社交大数据信息最大化方法,包括如下步骤:
s1、信息传播过程建模;给定一个目标位置,用户被激活的概率与用户在实际生活中去目标位置的激活概率有关系;当一个节点被激活时,它会尝试影响未激活的邻居节点的概率为激活概率;对于一个邻居,一个用户只有一次机会去影响,而且这些尝试之间是相互独立的,即节点对邻居节点的激活不会受到其它节点的影响;
s2、用户行为分析;用户所有签到地点去到目标位置的概率和,表示用户去到目标位置的概率来分析用户的行为;
s3、计算所有用户的影响力,选出第一个种子节点;影响用户的影响力三个因素:节点的度数、用户从任一签到地点去到目标位置的概率、用户的分享概率;计算出所有的用户的影响力之后,对所有用户的影响力进行排序,选择影响力最大的那个节点作为第一个种子节点;
s4、修改选中以及受影响的节点的影响力,选出所有种子节点。
优选的,步骤s1中信息传播过程建模:
给定一个目标位置,用户被激活的概率与用户在实际生活中去目标位置的概率pw有关系,当一个节点v被激活时,它会尝试影响未激活的邻居节点w,激活概率为pw,对于一个邻居,一个用户只有一次机会去影响,而且这些尝试之间是相互独立的,即v对w的激活不会受到其它节点的影响。信息传播过程为:
(1)给定初始的活跃节点集合s,当在时刻t节点v被激活并成功分享后,它就获得了一次对它的邻居节点w产生影响的机会,成功的概率为pw,是用户在实际生活中去目标位置的概率,会根据签到的位置信息计算得到,其自身独立不受其它节点的影响。
(2)若w有多个邻居节点都是新近被激活并成功分享的节点,那么这些节点将以任意顺序尝试激活节点w。如果节点v成功激活节点w,那么在t+1时刻,节点w转为活跃状态。
(3)在t+1时刻,节点w以一定的概率去分享这个信息,若分享成功将对其它节点未激活的邻居节点产生影响,重复上述过程。
在上述传播过程中,在t时刻无论节点v是否能成功激活它的邻居节点,在以后的时刻中,v本身虽然仍保持活跃状态,但它已经不再具备影响力,即在t时刻被激活的节点,已经尝试激活它自身的邻居节点后,在t+1时刻仍然处于活跃状态,但它本身已经不能去激活其它任何节点,这一类节点成为无影响力的活跃节点。当网络中不存在有影响力的活跃节点时,即没有新的节点被激活,传播过程结束。
优选的,步骤s2中用户行为分析具体步骤为:
s2.1、数据预处理:社交网络中用户的签到信息中包含了用户每次签到的时间和位置信息,从这些数据中提取有效信息,包括用户、时间、经度、纬度;
s2.2、计算每个用户相邻两次签到地点的距离;将数据集中用户的签到数据进行预处理后,对每个用户的签到分别按照时间进行排序,然后计算出每个用户每相邻向次签到的位置之间的距离;
s2.3、统计每个距离在整个用户签到数据中所占的比例,得到距离概率图;
s2.4、计算所有用户去到目的位置的概率,表示用户去到目标位置的概率来分析用户的行为。
优选的,步骤s3中计算所有用户的影响力,选出第一个种子节点具体步骤为:
从社交大数据中,对数据文本进行处理,提取出每个用户以及相邻的用户,得到代表社交网络中用户之间友好关系的邻接矩阵。一个用户相邻的用户越多,即它所在的那一行元素中1的数目比较多,代表它的朋友越多,能够去影响的人也就越多。同时,每个用户都有一个去到目标位置的概率,代表了在距离的影响下用户去目标位置的可能性,这个概率越大,说明这个用户越容易被影响。一个用户被激活后,它会以一定的概率去分享(比如发微博,或者单独找朋友进行推荐分享),如果分享成功,才会去影响它的邻居,如果不成功,那么后面的状态,虽然它一直处于活跃状态,但是在后面的过程中无法对它的邻居产生影响。这里度量用户的影响力主要考虑前面提到的三个因素:节点的度数,所有邻居去到目标位置的概率和用户的分享概率。计算出所有的用户的影响力之后,对所有用户的影响力进行排序,选择影响力最大的那个节点作为第一个种子节点。
优选的,步骤s4中对于已经选为种子节点的用户,在后续的节点选择中,这些节点将不会再参与,所以将它的影响力置为0。当一个节点被激活后,它的邻居节点会被影响(可能被激活,也可能不被激活)。如果v被激活了,那么这个激活节点的邻居w的影响力就会发生变化,因为邻居v已经处于激活状态,这个就不属于节点w的影响力之内了。所以,当一个节点被激活后,它的邻居的影响力会发生变化,不能再包含对已经激活节点的影响。同时,被激活节点的邻居的邻居的影响力也会发生变化,因为被激活节点可能改变它邻居节点的状态。修改了选中节点以及受影响的节点的影响力之后,重新对所有节点的影响力进行排序,选择影响力最大的节点加入种子节点的集合,不断重复上述步骤,知道选出指定数目的种子节点。
优选的,社交网络既可以是有向的社交网络,也可以是无向的社交网络。当社交网络中的朋友关系具有方向性时(即可能出现a是b的朋友,而b不是a的朋友),那么在实施时用户的度就是用户的出度,即他是多少人的朋友,若社交网络中的朋友关系是无向的,那么就是他的朋友的数量。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明主要利用了社交网络中用户的签到的位置信息,考虑了距离对于用户行为的影响,对于目标信息是一个具体地点时,距离对用户的行为是有很大的影响的。在对用户行为进行分析的时候,利用了统计的思想,对所有用户的历史签到信息都进行了考虑。
2、本发明的社交网络信息传播模型更加的贴近具体的实际情况,对于给定一个具体位置(信息),结合了距离对于用户行为影响的实际因素,充分挖掘了特定社交网络中的有效信息来分析用户行为。
3、本发明不仅考虑了用户的度(即用户所拥有朋友的数量)、愿意分享的可能性以及邻居节点到目标位置的概率,还考虑了已经激活的节点对其他节点的影响力的改变,每一次选出一个种子节点后都会改变受影响节点的影响力,一步一步选出所需数目的种子节点集合。所以本发明在基于位置的社交大数据信息最大化的效率和有效性方面都具有很大的优势。
附图说明
图1为本发明的信息传播模型的传播过程图;
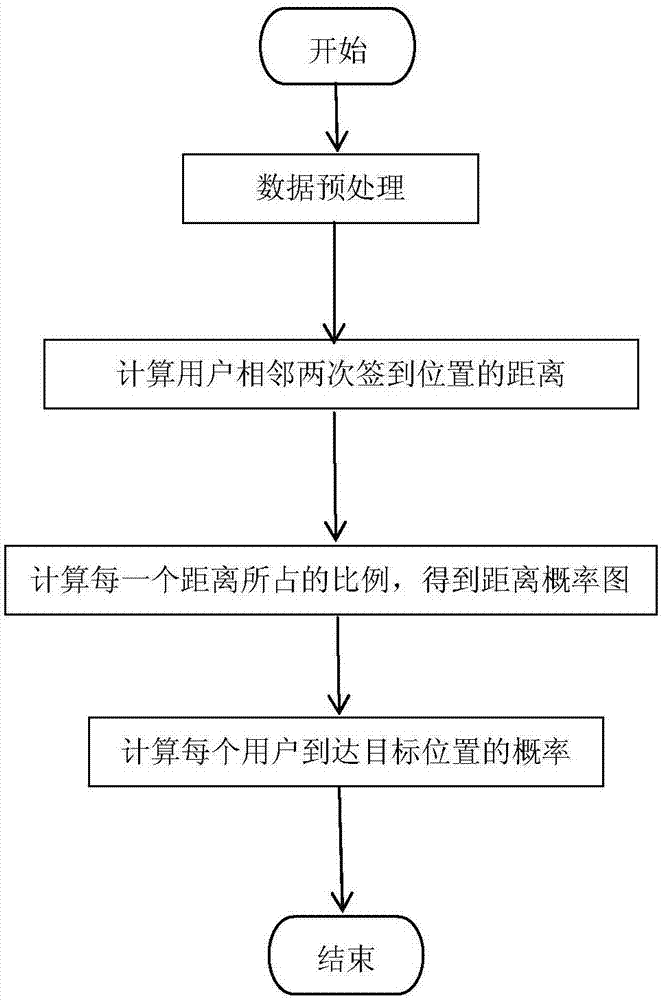
图2为本发明的社交网络数据集中签到的距离概率的统计分析的流程图;
图3为本发明的方法的流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
该方法主要针对基于位置的社交网络,挖掘其中用户签到的位置信息,对信息传播过程进行建模,对用户行为进行分析,选择出有效的种子节点集合,使得信息(具体的一个位置信息)通过在线社交网络得到最大化的传播,使最多的用户去到目标位置。该方法主要描述了对社交网络信息传播进行建模,用户行为分析,计算影响力选出第一个种子节点和修改影响力选出所以种子节点这四个方面的流程步骤。此实施例的数据集是snap(stanfordnetworkanalysisplatform)提供的基于位置的社交网络数据集brightkite。
如图1所示,描述的是给定一个目标位置信息,信息在社交网络中通过好友关系传播的过程。对信息在社交网络中的传播过程进行建模,来模拟用户之间是如何来相互影响进行信息的传播。当目标信息是一个具体的位置的时候,激活的节点会以一定的概率(利用签到的次数来计算)来选择是否分享给朋友。如果分享成功,那就会去影响它的邻居节点,影响成功,则会继续前面的过程,分享不成功则节点依然处于活跃状态,但是不能再影响相关的用户。当社交网络中不再有人被激活的时候,就结束信息的传播。信息传播模型的传播过程图具体步骤如下:
1、节点被激活。社交网络中的为激活状态的用户被选为种子节点或者被邻居节点成功影响。被选为种子节点时商家会通过一定的手段(赠品或者优惠的方式)去激活他们,被邻居节点激活的则是依赖社交网络中的朋友关系进行激活的。
2、用户尝试分享。根据用户的签到次数计算用户愿意分享的概率,用户会以这个概率去选择将信息分享给周围的朋友。
3、邻居节点以一定的概率被影响。用户分享信息给邻居节点后,邻居节点会根据距离的影响选择是否被激活。
如图2所示,描述的是对社交网络数据集中用户签到的距离概率统计的流程图。对用户行为进行分析时,主要要利用社交网络中用户的历史签到信息来进行统计分析,主要包括以下的步骤:
1、数据预处理。一般数据集中用户的签到数据是以文本方式给出,同时具有一些我们不需要的信息。进行用户的行为分析,主要需要用户每次签到的时间,经度和纬度。
2、计算每个用户相邻两次签到地点的距离。将数据集中用户的签到数据进行预处理后,对每个用户的签到分别按照时间进行排序,然后计算出每个用户每相邻向次签到的位置之间的距离。
3、统计每个距离在整个用户签到数据中所占的比例,得到距离概率图。以横轴代表距离,以纵轴代表距离在整个数据集中的比例绘制图例。对图中数据进行分析,得到距离与概率的数学公式。对于给定一个具体的距离,可以得到用户是否前往的概率。
4、计算各个用户去到目的位置的概率。给定一个具体的位置(经度和纬度),计算用户去到该位置的概率时,考虑用户每次的签到地点与目标位置的距离,根据得到的距离概率公式,计算出用户每次签到的地点到达目标位置的概率,那么一个用户去到目标位置的概率就是他从每次签到的地方去到目标位置的概率之和。最后计算出每个用户分别去到目标位置的概率作为他们被影响时成功被激活的概率。
如图3所示,其中描述的是选择种子节点集合的流程图。
1、计算所有节点的影响力。对社交网络的文本进行处理,提取出社交网络关系图的邻接矩阵,计算出每个用户的度,即用户在社交网络中朋友的数量,再根据用户的签到次数来计算每个用户愿意分享的概率(或者可以系统随机产生)。用户的影响力通过下面的标准来计算:度数*用户愿意分享的概率*所有邻居去到目标位置的概率和。
2、选出第一个种子节点。对所有节点的影响力进行降序排序,得到影响力最大的那个节点,作为第一个种子节点。
3、修改受影响的节点的影响力。当选择了一个种子节点的时候,那么它就可能被激活,然后去影响周围的节点,会改变相关用户的影响力。需要改变影响力的节点的主要是被激活节点的邻居节点以及邻居的邻居节点。为了排序的方便,这里把已经选为种子节点的用户影响力置为零,在后续所以节点排序时将不会再选到已经被选的节点。
被激活节点邻居节点的影响力在度数上以及所有邻居去到目标位置的概率和中都需要减去被激活节点的那一部分。当节点被激活后,它的邻居节点便无法再影响它并激活它,所以被激活节点的邻居节点的影响范围不包含被激活的节点了。
被激活的节点如果成功影响了它的朋友,那么与此朋友连接的节点就无法再去激活这个朋友,那么此朋友连接的节点的影响力就受到了影响。所以,需要计算被激活节点的邻居节点被激活节点成功影响的概率,在所有相关的节点的影响力中减去可能的这一部分影响力。
4、选出所有的种子节点。当选中的种子节点的数目没有达到预期时,加入新的种子节点后,不断的修改受影响的种子节点的影响力,并对未加入种子节点集合的节点影响力进行排序,不断选出影响力最大的加入种子节点集合,直到选出所有的种子节点。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!