用于人脸识别的基于LBP特征的结构型稀疏表示分类方法与流程
本发明涉及一种稀疏表示的分类算法,特别涉及一种用于人脸识别的基于lbp特征的结构型稀疏表示分类方法,属于人脸识别领域。
背景技术:
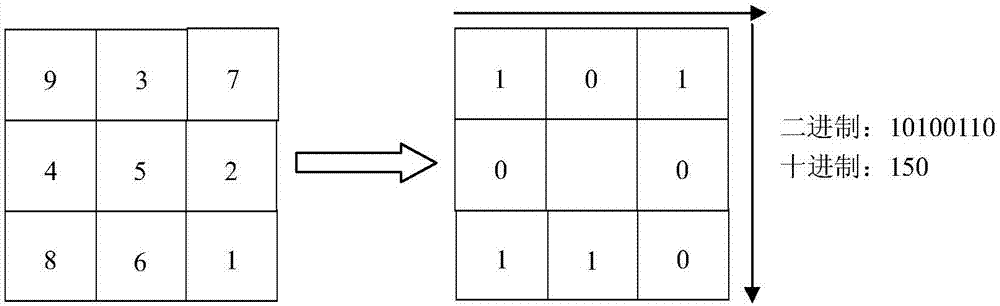
:在过去相当长时间的研究中,稀疏表示最初是被用来解决诸多信号处理领域的问题,比如图像去噪、图像压缩和图像恢复等。近年来经过广大研究者的探索,发现在模式识别领域,稀疏表示由于其高效性可以很好的用来解决图像分类识别的问题。如何定义图像的稀疏表示,就是对这个图像采用基于稀疏性的最逼近的表示,同时保证其简约性。稀疏表示具有判别性,意味着其可以选择最为稀疏的一种表示系数来很好的表达原始图像,正是因为这个特性,在人脸识别领域,稀疏表示的应用非常成功。在基于稀疏表示的分类方法(src)中,我们从训练样本集中通过学习得到一个过完备字典,训练样本即该字典中的原子,同一个线性子空间中包含某一类别的所有训练样本。稀疏表示的目的是想让某类的测试样本只由与其同类的训练样本来线性表示,换言之就是在稀疏表示的系数矩阵中,只有与测试样本同类别的训练样本的表示系数不为零,其他均为零。这样一来的传统的基于稀疏表示的分类算法(src),具体为:给定样本数据集z,其中训练样本共有k类,并且第i类样本的数量为ni,定义zij∈rm表示属于第i类样本集的第j个样本,特征向量的维数为m,则所有的第i类样本可以表示为样本集将所有k类的样本集ai组合起来,得到字典矩阵a:a=[a1,a2,…,ak]∈rm×n(1)测试样本y可以用字典矩阵a线性表示为:y=ax∈rm(2)上式(2)中是系数向量,要想达到稀疏表示的效果,系数向量x要满足这样的条件,即除了与测试样本y同类别的训练样本所对应的系数不为零之外,其余项均为零。因此我们只需要求解出线性方程组y=ax的系数,就可以判断出测试样本y的所属类别。通过添加约束条件,将该稀疏表示问题转化为求解l0范数最小化问题,就可以获得最具稀疏性的系数解,优化模型如公式(3)所示:上式(3)中||·||0求得是系数向量x中非零元素的个数,也即一个l0范数。但是通过大量学者的研究我们可以得知,上述优化问题是一个经典的np难题,并不能轻易的求得稀疏解。而根据压缩感知理论,可以用l1范数最小化问题来代替求解上述优化问题,当然前提是要满足系数x足够稀疏的条件,此时公式(3)的求解可以转化为公式(4):上式是一个标准的凸优化求解问题,在实际操作中,都是转化为公式(5)的形式来求解,其中ε是允许存在的误差:在判定测试样本的类别时,假定对于不同的样本类别i,存在映射关系δi:其中δi(x)是表示系数x中第i类的表示系数,测试样本只采用第i类的表示系数来近似表示为yi:yi=aδi(x)(7)这样一来我们就可以得到逼近残差ri(y),也即所谓的用来衡量对测试样本的稀疏逼近程度的重构误差,由公式(9)可以求得:ri(y)=||y-aδi(x)||2(8)重构误差ri(y)的值越小的类别,就表明该类别的样本与测试样本越相似,因为重构误差的大小代表的就是对测试样本逼近程度的大小,所以判定具有最小重构误差的类别即为测试样本的类别,具体表达如公式(9)所示:对于上述传统的src算法来说,样本的局部性相较于其稀疏性一样是极其重要的,局部特征是一种非常有用的特征信息,而在经典的src算法中,使用的是样本的全局特征,并没有充分利用样本的局部特征。同时传统的src算法存在一个潜在的问题,由于训练字典中包含了大量的不同类别的训练样本,测试样本就可以能会由来自不同类别的测试样本表示得到,对于算法的分类识别效果自然会产生较大影响。所以在使用src算法进行分类识别时,需要充分考虑样本的局部特征和训练字典的分块结构性。技术实现要素:本发明所要解决的技术问题是提供一种用于人脸识别的基于lbp特征的结构型稀疏表示分类方法(lbp-ssrc),该方法首先考虑到充分利用原始样本的局部特征,从原始样本集中提取出样本的lbp直方图特征,然后考虑到训练字典的分块结构型,设计两种结构型稀疏表示分类算法模型(ssrc),将提取的lbp特征输入到ssrc算法模型中,进行下一步的分类识别任务。通过在公共的ar人脸库上的对比实验,证明了所提算法相比较于传统的基于稀疏表示的分类算法,能有效的提高识别率。本发明为解决上述技术问题采用以下技术方案:本发明提供一种用于人脸识别的基于lbp特征的结构型稀疏表示分类方法,包括以下具体步骤:步骤1,分别提取原始样本集中训练样本和测试样本图像的lbp特征;步骤2,构建结构型稀疏表示算法模型;步骤3,将步骤1中提取的训练样本和测试样本的lbp特征输入到结构型稀疏表示分类算法模型中,根据结构型稀疏表示算法模型的输出,得到测试样本的分类结果。作为本发明的进一步技术方案,步骤1中测试样本图像的lbp特征的提取方法包括如下步骤:1)将测试样本图像y划分成16×16的小区域,记为y={y1,y2,…,yn},其中,n表示划分的小区域数目;2)分别对yi进行lbp编码,得到每个小区域的lbp编码图,记为其中,i=1,2,…,n;3)分别对进行直方图统计,即统计每个lbp编码值的频率,得到直方图统计特征向量lbp(yi),并作归一化处理;4)将所有小区域的直方图统计特征向量串联得到整幅测试样本图像的lbp特征矩阵:lbp(y)=[lbp(y1),lbp(y2),…,lbp(yn)]。作为本发明的进一步技术方案,步骤1中训练样本图像的lbp特征的提取方法包括如下步骤:1)将训练样本图像d划分成16×16的小区域,记为d={d1,d2,…,dn},其中,n表示划分的小区域数目;2)分别对di进行lbp编码,得到每个小区域的lbp编码图,记为其中,i=1,2,…,n;3)分别对进行直方图统计,即统计每个lbp编码值的频率,得到直方图统计特征向量lbp(di),并作归一化处理;4)将所有小区域的直方图统计特征向量串联得到整幅测试样本图像的lbp特征矩阵:lbp(d)=[lbp(d1),lbp(d2),…,lbp(dn)]。作为本发明的进一步技术方案,lbp的编码值通过以下公式获得:其中,pi是中心像素pc周围相邻的像素值,2p是像素差权重系数。作为本发明的进一步技术方案,步骤2中构建结构型稀疏表示算法模型为:其中,x表示稀疏表示系数向量,x={x1,x2,…,xn}。作为本发明的进一步技术方案,步骤2中构建结构型稀疏表示算法模型为:其中,其中,x表示稀疏表示系数向量,x={x1,x2,…,xn}。作为本发明的进一步技术方案,步骤3中训练样本和测试样本的lbp特征输入到上述结构型稀疏表示分类算法模型中,得到稀疏表示系数向量x;然后根据每类系数xi和lbp(di)计算lbp(y)的残差,就判定测试样本属于残差最小的那类,分类公式为:本发明采用以上技术方案与现有技术相比,具有以下技术效果:附图说明图1是本发明提出的用于人脸识别的基于lbp特征的结构型稀疏表示分类算法的实现流程图。图2是lbp编码的基本原理示意图。具体实施方式下面结合附图对本发明的技术方案做进一步的详细说明:如图1所示,本发明所述的用于人脸识别的基于lbp特征的结构型稀疏表示分类算法,包括以下步骤:1)提取原始样本集的中训练样本和测试样本图像的lbp直方图特征。给定一个中心像素pc,lbp的编码值可以通过公式(1)获得:其中,pi是中心像素pc周围相邻的像素值,2p是像素差权重系数。lbp描述子的邻域窗口定义为3×3,将中心点像素值设为阈值,通过将周围8个相邻的像素点值与其对比得到一个8位的二进制编码,再转化为十进制数就得到了中心点的lbp编码值,该lbp值能够很好的反应样本图像的局部信息。图2是lbp编码的基本原理。lbp的基本思想是通过计算所有像素点的lbp编码值,用其替换原来对应位置的像素值,就可以得到一幅全新的lbp编码图像。在人脸识别领域,并不是直接用lbp编码图像来进行分类识别,而是通过对lbp编码图像作直方图统计,统计lbp编码值在每个数值上出现的频率,将所得结果作为特征向量输入到算法模型中进行分类识别。由于对整个图像进行lbp编码的直方图统计特征分类效果不是很好,所以想到可以对原始样本图像进行划分,得到不同的子区域,再用lbp对这些子块进行编码,然后分别作直方图统计,得到各子区域的直方图统计特征,通过对样本图像的分块操作可以更好的反应样本图像的局部信息。以测试样本图像为例,lbp特征的提取步骤如下:(1)将样本图像y划分成16×16的小区域y={y1,y2,…,yn},其中,n表示划分的小区域数目;(2)分别对yi进行lbp编码,得到每个区域的lbp编码图(3)分别对进行直方图统计,即统计每个lbp编码值的频率,得到直方图统计特征向量lbp(yi),并作归一化处理;(4)将所有区域的直方图统计特征向量串联得到整幅样本图像的lbp特征矩阵lbp(y)=[lbp(y1),lbp(y2),…,lbp(yn)]。2)设计结构型稀疏表示算法模型(ssrc)。相较于传统的src算法,传统的src算法并没有考虑字典中的分块结构性,因此,我们可以求解公式(2)来实现比src算法更好的分类:其中,xi表示稀疏表示系数向量,d表示字典矩阵,y是测试样本,i(·)是一个指示函数,即当变量为真取1,为假取0,q≥1。解决公式(2)的最优化问题的目的,就是寻找重构测试样本所需的最少的非零系数块。上式是一个np难题,其求解是相当困难的,而类似于src算法的求解,我们可以通过用l1松弛来代替解决上式的优化问题:当q≥1时,公式(3)是一个凸优化问题,当q=1时,上式的凸优化问题和src算法是一致的,因此在适当的条件下,可以将src算法的凸优化问题看作是一种结构型稀疏恢复方法,即测试样本的稀疏表示通过最小化非零系数块来获得。我们也可以考虑通过最小化非零重构向量的方式来进行分类,如公式(4)所示:当q≥1时通过l1松弛转化为下面的凸优化问题:3)将lbp特征输入到结构型稀疏表示分类算法模型p1或p2中,通过求解l1范数最小化问题,就可以得到稀疏表示系数向量x,然后根据每类系数xi和字典di计算测试样本y的残差,哪一类的残差最小,就判定y属于那类,分类公式如下:将本发明所述的两种基于lbp的ssrc算法模型lbp-p1和lbp-p2在ar人脸库上进行实验,并将传统的src算法、lbp-src算法以及ssrc算法的两种模型p1和p2作为对比算法,来验证所提算法的有效性。ar人脸库中包含126个人的4000多张人脸图像,每个人的人脸图像为26张,从中选取100个人的所有26张人脸图像进行对比实验。对于每个人的所有样本图像,我们随机选取其中13张作为训练样本,剩余的作为测试样本。每种方法我们都进行20次随机实验,表1给出了每种算法的平均识别率。表1ar库上所有算法的平均识别率方法平均识别率(%)src89.55lbp-src90.73p190.48p291.27lbp-p192.35lbp-p293.72由表1可以看出,lbp-ssrc的两种模型lbp-p1以及lbp-p2在ar库上的识别性能都要优于其他四种对比方法,其中识别性能最好的是基于lbp特征的最小化非零重构向量模型p2的lbp-p2,比其他方法的识别率至少要高出1.37%(93.72%-92.35%),通过以上的实验数据对比,充分验证了我们在该研究方向上的工作是有意义的。以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1