基于分布式互联平台的一省多地调控综合模型拼接方法与流程
本发明涉及电力系统仿真培训领域,尤其涉及一种基于分布式互联平台的一省多地调控综合模型拼接方法。
背景技术:
“十三五”期间,国家电网公司特高压电网进入全面快速发展阶段,骨干网架逐步形成,包含辽宁电网在内的我国电网互联更加紧密、电网特性由区域模式转为总体模式、电网运行的整体性增强、局部故障可能演变成更大范围的故障,特高压电网的新特性对特特高压电网调控运行人员的协同运行管理能力提出了更高的要求。
辽宁省调及下辖的多个地调已经部署智能电网调度技术支持系统(d5000系统),并部署了调控培训仿真系统,辽宁电网一省多地电网调控模型拼接,将实现辽宁省地电网模型的源端维护、全局共享,可快速的构建省地电网大模型,将为辽宁省地电网调控一体化联合反事故演习奠定基础,从而保障电网的安全稳定运行,提高各级电网调控人员协调处理事故的能力。
关于省地模型拼接方法多是从linux平台获取省地电网模型文件,基于windows平台的软件进行模型拼接合成,而后再将拼接好的省地大模型上传至linux平台上。拼接过程中,现有方法通常按各省地管辖范围进行边界设备(主变)拆分处理。对于待拼接的省、地电网模型,具有220kv主变模型的变电站是其关口变电站,其他非关口变电站直接拷贝全站模型到拼接实时库。对于关口变电站,220kv及以上设备模型从省网模型中获取,110kv及以下模型从地区电网模型获取;在模型拼接过程需要修改地区电网220kv主变高压侧连接点,使其编号与省网该主变高压侧编号一致。
目前,针对省地电网模型拼接的方法多采用基于windows平台的软件进行,同时将220kv变压器作为省地模型拼接的关口,缺点为:
(1)从linux平台获取省地电网模型文件,基于windows平台的软件进行模型拼接合成,而后再将拼接好的省地大模型上传至linux平台上,这种在两种平台之间转换完成模型拼接,效率比较低,而且从网络安全性考虑,也不宜在两种平台之间频繁转换。
(2)现有方法通常按各省地管辖范围进行边界设备(主变)拆分处理,采用220kv变压器作为省地模型拼接的关口,220kv电压等级取省网模型,110kv电压等级取地区模型,在模型拼接过程需要修改地区电网220kv主变高压侧连接点,使其编号与省网该主变高压侧编号一致,设备拆分的处理过程相对繁琐一些。
(3)从容错性角度看,现有软件对于一些冗余记录没有进行过滤处理,导致部分垃圾记录直接影响软件的下一步进行。
技术实现要素:
针对背景技术中的问题,本发明的目的是利用分布式互联平台,根据省调模型和多个地调模型文件完成一省多地大模型的拼接。旨在通过一省多地大模型的拼接,实现一省多地的调控运行人员能够分别利用各自的智能电网调控一体仿真系统进行省地的联合反事故演习,构建一个与实际电网高度一致的全范围、全过程、全场景的数字模拟环境。
为了实现上述目的,本发明提出如下技术方案:
一种基于分布式互联平台的一省多地调控综合模型拼接方法,所述方法包括如下步骤:
(1)校验省地模型文件;
(2)去掉重复的设备id,去掉重复的连接点号;
(3)根据id号去重过程形成地调新旧id的对照文件,同时进行图形转换;
(4)根据省地模型文件各设备表的中文名称进行模糊匹配,生成省地设备对照文件;
(5)省地模型合并;
(6)关口潮流对应;
(7)大模型的检查修正。
进一步地,所述步骤(1)又包括如下步骤:
(1.1)校验省地模型文件是否为模型拼接指定的cime文件格式;
(1.2)校验省调模型文件各表的列数和地调模型文件各表的列数是否一致;
(1.3)检验省地模型文件是否包含所需的各表。
进一步地,所述cime文件格式如下:
表头:<表英文名::dts>;
英文标识:以“@”开头,后接各字段英文标识,以空格区分开;
中文名称:以“//”开头,后接各字段中文名称,以空格区分开;
表内各记录:以“#”开头,后接各字段的值,以空格区分开;
表尾:</表英文名::dts>;
所述英文标识各列、中文名称各列、表内各记录的各列是严格对应的。
进一步地,所述步骤(1.2)校验过程会给出提示信息,告知地调厂站表格式与省调厂站表的格式不符。
进一步地,步骤(1.3)中所述各表的表头为“<表英文名::dts>”,表尾为“</表英文名::dts>”,依照此对模型文件各表进行检查,校验是否含有模型拼接必需的各表,如果缺少必需的设备表,此步校验过程会给出提示信息。
进一步地,所述步骤(2)又包括如下步骤:
(2.1)去掉重复的设备id:对于省地模型文件的同一张设备表,若设备id号有重复的,则省调设备id号保持不变,地调设备id号进行替换;综合考虑省调模型文件和地调模型文件的该设备表,假设该设备表的最大记录id为id_max,则第一个与省调设备id有冲突的地调设备id替换为id_max+1,后续与省调设备id冲突的地调设备id在此基础上依次加1;
(2.2)去掉重复的连接点号:遍历省地模型文件中所有连接点号,并记录最大的连接点号nd,对于省地模型文件有重复的连接点号,省调设备连接点号保持不变,地调设备连接点号在nd的基础上依次加1进行整体替换;
所述替换方法与步骤(2.1)中设备id替换方法相同。
进一步地,所述步骤(3)又包括如下步骤:
(3.1)在id去重过程中,省调id保持不变,地调id进行了去重替换,此时把替换前后的设备id保存并生成对照文件;
所述对照文件以表为单位,每张表为3列,分别为“序号、替换前的设备id、替换后的设备id”;
(3.2)根据地调新旧id对照文件进行厂站图的转换,将厂站图g文件中的旧id替换为新id,以此完成图形转换过程。
进一步地,在所述步骤(4)中,根据交流线段端点表的厂站id和电压类型id找到对应的厂站名称“法库”,电压类型“220kv”,在厂站名称和电压类型一致的前提下,对设备中文名称“电法一线”进行省地设备的模糊匹配生成对照文件;
生成的省地设备对照文件共四列,四列分别为省调设备id,省调设备名称,地调设备id和地调设备名称。
进一步地,在所述步骤(5)中,省地模型合并包括:
(5.1)电压类型表的合并:对于同一电压类型的,但省地id号不相同的,此时以省调的记录为准;
省地拼接大模型的电压类型表中,保留上述省调记录,裁掉地调记录;
对于只在省调模型有的记录或是只在地调模型有的记录,一般为220kv及以下的电压类型,直接增加到大模型中;
(5.2)其他各表的合并:
主要原则:在省调模型基础上进行省地模型的裁剪和地调模型的添加;
除交流线段表外的各表:将对照文件出现的厂站,删掉含有省调厂站的所有记录,替换为含有地调厂站的记录;
交流线段表:在对照文件出现的厂站,将省调厂站id替换为地调厂站id。设备id仍采用省调的;
交流线段端点表:修正各记录的线段id,通过与交流线段表的中文名称进行匹配,并通过厂站id进行校验,对地调记录进行线段id的替换;
增加地调110及以下厂站的各表记录。
进一步地,在所述步骤(6)中,厂站的关口潮流对应,主要是考虑主变下送潮流:
首先根据“dts供电区域信息表”与“dts设备与供电区域关系表”统计各供电区域所包含的所有主变,然后对省调各供电区域所包含的所有主变的有功功率和无功功率分别进行加和,同时对地调供电区域所包含的所有主变的有功功率和无功功率也分别进行加和,形成此供电区域负荷的有功比和无功比,即:
负荷有功比=省调供电区域有功和/地调供电区域有功和
负荷无功比=省调供电区域无功和/地调供电区域无功和拼接大模型中各负荷的潮流值如下:
负荷有功=地调模型中该负荷有功*负荷有功比*有功修正系数
负荷无功=地调模型中该负荷无功*负荷无功比*无功修正系数
其中,有功修正系数和无功修正系数初值为1,其值也可通过界面进行设置修改。
进一步地,所述步骤(7)对厂站的设备中的开关、刀闸、接地刀闸的遥信值与省调模型中这些设备的遥信值进行对比检查,对于遥信值状态不一致的设备或是只在省调模型出现的设备或是只在地调模型出现的设备,通过输出日志文件进行记录,经确认后,可根据需要考虑按照省调设备的遥信状态进行修正或保持原来状态。
本发明的有益效果为:
(1)基于linux平台,可随时进行省地模型拼接,从省地侧获取多个地调的模型,逐一添加到省地模型中形成大模型,然后再通过调度数据网,利用分布式互联平台分发到各参与演习的地调中。这种基于linux平台的模型拼接方法避免了跨平台转换的不方便,同时也提高了模型拼接的效率。
(2)充分利用了分布式互联平台,便于模型的获取和分发,同时也将模型拼接与d5000平台更好的进行融合,充分体现了智能电网调控系统的一体化功能。
(3)以省调模型为基础,交流线段表采用省调模型,其他各表以厂站为单位进行设备模型的整体裁剪与添加,简化了拼接过程。
(4)从容错性角度考虑,现有方法对于一些冗余记录进行了自动过滤处理,并通过日志文件的形式进行记录,便于后续根据日志文件进行模型的修正与排除,同时也不会使得冗余模型记录干扰模型拼接过程的进行。
附图说明
图1是本发明的技术方案主要步骤示意图。
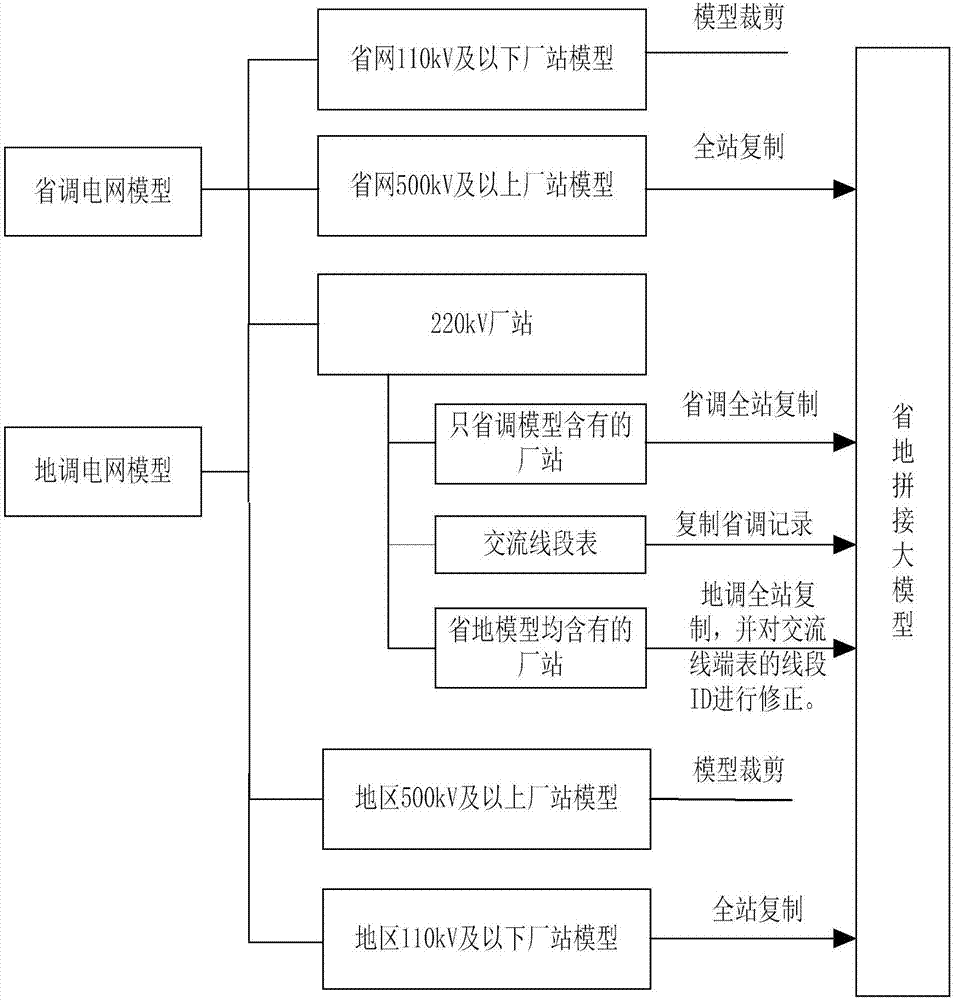
图2是本发明的省地模型拼接示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明的具体实施方案作详细的阐述。这些具体实施方式仅供叙述而并非用来限定本发明的范围或实施原则,本发明的保护范围仍以权利要求为准,包括在此基础上所作出的显而易见的变化或变动等。
图1是本发明的技术方案主要步骤示意图。
图2是本发明的省地模型拼接示意图。
如图1所示,本发明的技术方案包括以下步骤:
步骤1:校验省地模型文件:
1.1校验省地模型文件是否为模型拼接指定的cime文件格式。
各表格式如下:
表头:<表英文名::dts>;
英文标识:以“@”开头,后接各字段英文标识,以空格区分开;
中文名称:以“//”开头,后接各字段中文名称,以空格区分开;
表内各记录:以“#”开头,后接各字段的值,以空格区分开;
表尾:</表英文名::dts>
其中,英文标识各列、中文名称各列、表内各记录的各列是严格对应的。以厂站表的一条记录做为示例,如下所示:
模型拼接所需的各表及各表的字段格式见附录1。
1.2校验省调模型文件各表的列数和地调模型文件各表的列数是否一致。
进行省地模型文件的拼接,首先要保证省地模型文件的各表的名称及各表的字段要一致,如若不一致,拼接而成的文件就不可用。如下表所示,地调的厂站表比省调的厂站表少一列,这样拼接出来的模型就会有问题,所以此步校验过程会给出提示信息,告知地调厂站表格式与省调厂站表的格式不符,避免影响模型拼接的进行。
1.3检验省地模型文件是否包含所需的各表
各表的表头为“<表英文名::dts>”,表尾为“</表英文名::dts>”,例如厂站表,表头为“<substation::dts>”,表尾为“</substation::dts>”;依照此对模型文件各表进行检查,校验是否含有模型拼接必需的各表,如厂站表、电压等级表、断路器表等设备表,如果缺少必需的设备表,此步校验过程会给出提示信息。
此步骤是对省地模型文件的校验过程,对拼接过程中的每一步的模型问题都会给出提示,避免将局部错误数据拼接到大模型中,为后面的拼接工作做准备。
步骤2:去掉重复的设备id,去掉重复的连接点号:
2.1去掉重复的设备id:对于省地模型文件的同一张设备表,若设备id号有重复的,则省调设备id号保持不变,地调设备id号进行替换。综合考虑省调模型文件和地调模型文件的该设备表,假设该设备表的最大记录id为id_max,则第一个与省调设备id有冲突的地调设备id替换为id_max+1,后续与省调设备id冲突的地调设备id在此基础上依次加1。
例如:省调模型文件厂站表最大记录id为113997365920137902,地调模型文件厂站表最大记录id为113997367262314941,则综合考虑省地模型文件厂站表id_max为113997367262314941;若地调a厂站与省调某厂站id有冲突,则a厂站id将替换为113997367262314942,后续与省调有冲突的厂站id依次替换为113997367262314943,113997367262314944,......。
2.2去掉重复的连接点号:遍历省地模型文件中所有连接点号,并记录最大的连接点号nd,对于省地模型文件有重复的连接点号,省调设备连接点号保持不变,地调设备连接点号在nd的基础上依次加1进行整体替换。方法与设备id替换的方法相同。
步骤3:根据id号去重过程形成地调新旧id的对照文件,同时进行图形转换:
3.1在id去重过程中,省调id保持不变,地调id进行了去重替换,此时把替换前后的设备id保存并生成对照文件。对照文件文件以表为单位,每张表为3列,分别为“序号、替换前的设备id、替换后的设备id”。
地调新旧id对照文件格式如下:
3.2根据地调新旧id对照文件进行厂站图的转换,将厂站图g文件中的旧id替换为新id,以此完成图形转换过程。
步骤4:根据省地模型文件各设备表的中文名称进行模糊匹配,生成省地设备对照文件:
生成的省地设备对照文件共四列,四列分别为省调设备id,省调设备名称,地调设备id,地调设备名称,具体形成过程如下:
根据交流线段端点表的厂站id和电压类型id找到对应的厂站名称“法库”,电压类型“220kv”,在厂站名称和电压类型一致的前提下,对设备中文名称“电法一线”进行省地设备的模糊匹配生成对照文件,格式如下:
步骤5:省地模型合并:
5.1电压类型表:省地此表合并的过程中需注意,对于同一电压类型的,但省地id号不相同的,此时以省调的记录为准。例如:
省地拼接大模型的电压类型表中,保留上述省调记录,裁掉地调记录。
对于只在省调模型有的记录或是只在地调模型有的记录(一般为220kv及以下的电压类型),直接增加到大模型中。
5.2其他各表:500kv厂站以省调为主,220kv及以下厂站以地调为主,220kv在对照文件出现的,此部分厂站是省地同时含有的厂站,在合并模型过程主要处理此部分厂站信息。
(1)主要原则:在省调模型基础上进行省地模型的裁剪和地调模型的添加。
(2)除交流线段表外的各表:将对照文件出现的厂站,删掉含有省调厂站的所有记录,替换为含有地调厂站的记录。
(3)交流线段表:在对照文件出现的厂站,将省调厂站id替换为地调厂站id。设备id仍采用省调的。
(4)交流线段端点表:修正各记录的线段id,通过与交流线段表的中文名称进行匹配,并通过厂站id进行校验,对地调记录进行线段id的替换。
(5)增加地调110及以下厂站的各表记录。
步骤6:关口潮流对应:
220kv厂站的关口潮流对应,主要是考虑主变下送潮流。首先根据“dts供电区域信息表”与“dts设备与供电区域关系表”统计各供电区域所包含的所有主变,然后对省调各供电区域所包含的所有主变的有功功率和无功功率分别进行加和,同时对地调供电区域所包含的所有主变的有功功率和无功功率也分别进行加和,形成此供电区域负荷的有功比和无功比,即:
负荷有功比=省调供电区域有功和/地调供电区域有功和
负荷无功比=省调供电区域无功和/地调供电区域无功和拼接大模型中各负荷的潮流值如下:
负荷有功=地调模型中该负荷有功*负荷有功比*有功修正系数
负荷无功=地调模型中该负荷无功*负荷无功比*无功修正系数
其中,有功修正系数和无功修正系数初值为1,其值也可通过界面进行设置修改。
步骤7:大模型的检查修正:
由于220kv厂站的所有设备均以来自地调,即220kv的设备(开关、刀闸、接地刀闸、交流线端、母线等)均与地调模型一致,故此步骤对这些设备中的开关、刀闸、接地刀闸的遥信值与省调模型中这些设备的遥信值进行对比检查,对于遥信值状态不一致的设备或是只在省调模型出现的设备或是只在地调模型出现的设备,通过输出日志文件进行记录,经确认后,可根据需要考虑按照省调设备的遥信状态进行修正或保持原来状态。日志文件的格式如下:
省地模型拼接完成后,需上传至指定路径进行潮流计算检查,若潮流收敛,且总功率与原有省调模型总功率近似,即完成省地模型拼接过程。
附录1:
- 还没有人留言评论。精彩留言会获得点赞!