基于词袋模型的全景图像拼接方法与流程
本发明属于计算机视觉和数字图像处理领域。
背景技术:
图像拼接技术是计算机视觉和数字图像处理领域的一个重要分支,它是将两幅以上的具有部分重叠的图像进行无缝拼接从而得到较高分辨率或宽视角图像的技术。图像拼接中两个最为关键环节为图像配准和图像融合。对于图像融合技术,现阶段方法在耗时和融合效果方面差别不大,已趋于成熟。但是对于图像配准,由于其配准时间及效果直接影响到图像拼接的速度和成功率,所以图像配准一直是当前图像拼接方面研究的热点。常见的图像配准方法都是基于sift或者是surf特征描述图像的,这些特征描述子的优点在于旋转不变性,尺度不变性以及不易受光照影响,现阶段的研究开始关注brief,orb以及brisk等二进制特征,因为其需要更少的存储空间以及计算的快速性。但是现阶段的图像拼接方法大都是基于帧对帧的比较方法,这种方法在图像数目较少时可以收到很好的效果,但是,随着图像数目的增加,这种方法在实时性要求较高时就不适用。
技术实现要素:
本发明的目的是提出一种适用于实时性要求较高的基于词袋模型的全景图像拼接方法,技术方案如下。
一种基于词袋模型的全景图像拼接方法,包括下列步骤:
1)准备已经训练好的orb词袋树;
2)对于待拼接图像数据集里的图像i,进行orb特征提取,将图像i中提取的特征描述子按照汉明距离从orb词袋树的根节点开始逐级向下到达叶子节点,遍历完所有的特征之后,在词袋树中存储该图像所有特征的正向索引,设k为上一插入到拼接结构图的关键帧,通过正向索引对两幅图像进行特征搜索,建立特征之间的对应,从而得到两幅图像间特征的对应;
3)根据得到的两幅图像之间特征的对应,得到两幅图像之间的单应性矩阵khi;
4)利用随机抽样极大似然估计算法来最小化二次投影误差和排除外点,进而得到对应图像对的内点集;
5)根据得到的内点集计算图像的边界矩阵,通过边界矩阵计算图像的重叠百分比;
6)根据计算的重叠百分比,计算对应图像对之间的重叠koi=min(ok,oi),如果内点的数目大于阈值τin并且重叠koi大于阈值τov,那么图像i作为潜在的关键帧保存,如果待拼接数据集中下一帧图像与关键帧k得到的内点数目和重叠不满足上述两个阈值,则将图像i作为关键帧加入到拼接结构图;
7)当图像i作为关键帧加入到拼接结构图中时,需要与之前的关键帧通过单应性矩阵建立联系,即图像i为拼接结构图的第k+1关键帧,则khi就表示为khk+1,则第k+1关键帧的单应性矩阵mhk+1表示为:mhk+1=mhkkhk+1,其中,mhk表示第k关键帧的单应性矩阵,m是为保证关键帧之间的对齐而定义的一个通用关键帧;
8)检测回环,新加入的关键帧图像i,与拼接结构图之前所有的关键帧图像进行检索匹配:新加入关键帧图像的orb特征进入词袋模型,按照汉明距离从词袋树的根节点开始逐级向下到达叶子节点,计算每个叶子节点也就是词袋树中每个词在图像i中出现的频率tf,将新加入关键帧图像的所有特征,在词袋树中做检索,得到每个词的值,将这些值构成图像的描述向量;设新加入关键帧图像和与其匹配的上一关键帧图像的描述向量分别为ν1和ν2,两幅关键帧图像的相似度分数计算公式表示为:
得分越高表示这两幅关键帧图像的相似度越高,由此可以得到新加入关键帧图像与之前关键帧图像的相似程度,从而可以得到一个从高到低关键帧相似度列表,这些关键帧图像即为有可能与新加入关键帧图像形成回环的关键帧。
9)根据关键帧相似度列表顺序,计算这些关键帧与新加入关键帧的单应性矩阵,如果通过单应性矩阵得到的内点数目大于一个固定的阈值,那么相应的连接关系就成为拼接结构图的一部分,即为形成回环;
10)优化单应性矩阵,采用光束法平差减小由单应性矩阵所造成的误差,误差函数ε为:
其中
11)图像拼接结构图的融合。
本发明主要优点及特色体现在如下几个方面:
1、目前图像拼接算法中图像配准都是基于sift或者是surf特征描述图像的,得益于这些特征的尺度、旋转不变性以及不易受光照影响,但是这些特征的提取需要的时间过多,造成算法的实时性达不到要求,此外图像配准为基于帧对帧的匹配,也会增加配准时间。本发明提出的基于词袋模型的检索结构,采用orb特征描述子。实验表明,基于词袋模型的图像配准方法在同样得到配准效果的同时,可以显著减少算法时间。
2、目前图像拼接算法大都基于单线程的算法,算法各个部分之间有着明显的顺序性和耦合性,本发明的算法可以采用多线程架构,实现算法不同部分的同时执行,实现在保证拼接效果的基础上,可以有效的缩短算法时间。
附图说明
图1是本发明基于词袋模型的多线程图像拼接算法的流程图;
图2是valldemossa数据集的图像拼接图;
图3是valldemossa数据集的拓扑结构图;
图4是odemar数据集的图像拼接图;
图5是odemar数据集的拓扑结构图。
具体实施方式
本发明提出基于词袋模型的多线程全景图像拼接技术,结合实例及附图详细说明如下:
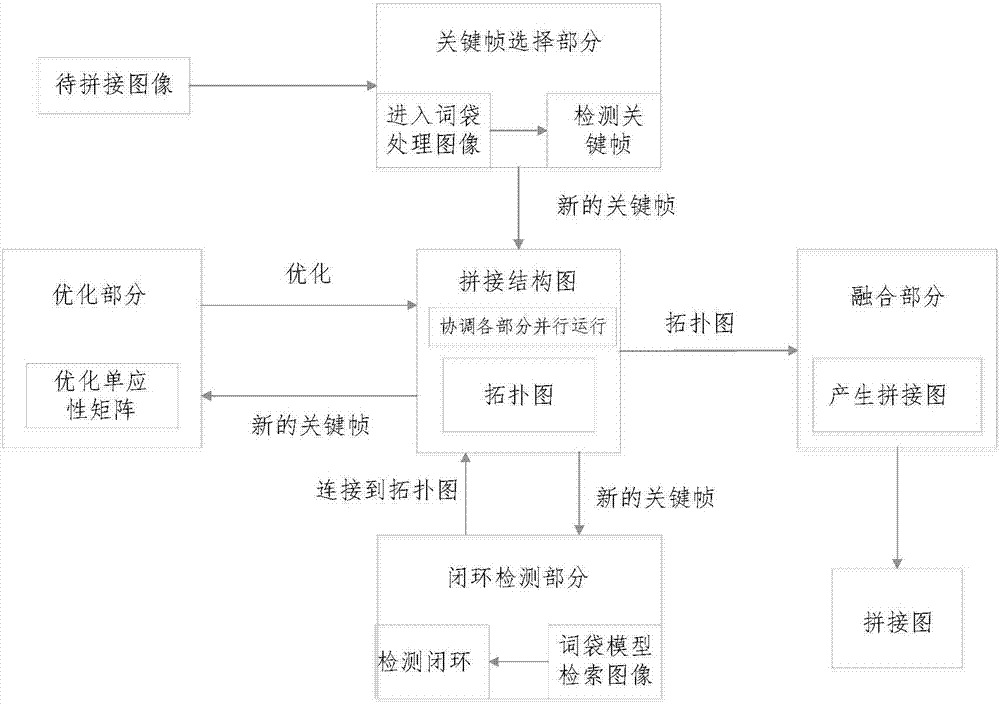
本发明算法的整体框架如图1所示,系统分为四部分且这四部分可并行运行,这种并行的设计可以减少各个部分之间的耦合性,从而减少算法运行的时间。这四个部分通过一个称为拼接结构图的结构相连接,这个结构用来估计拼接环境的拓扑结构,同时用于协调各个部分之间的关系,保证实时性。
拼接结构图部分是本发明方法的一个重要组成部分,其中的拓扑图代表着拼接环境的拓扑结构,以及统一不同部分之间运行的机制。环境的拓扑结构表示参与图像拼接的图像及其之间的联系。在本发明中,拓扑结构的数学模型是无向图的形式,其中节点代表着最终拼接中所选择的图像,连接线代表着它们之间的重叠部分,在本发明中,被选择的图像称为关键帧。为了产生最终的拼接图,需要选取关键帧,即为拼接图像帧。
系统其他部分和拼接结构图的建立是同步进行的,关键帧部分描述输入图像,进入词袋检索结构处理图像以及决定图像为关键帧,是否为最终拼接结构图像的组成部分;闭环检测部分在检测匹配图像对后可以建立当前帧与所匹配关键帧的联系,形成回环;优化部分通过光束法平差调整单应性矩阵,来减少误匹配造成的误差;优化之后的拼接结构图进入融合部分产生最后的拼接图。具体实施方案如下:
7)构建词袋树,dbow2库利用一个大的图像数据库,离线训练好了orb库和sift库,供大家使用。在本发明中,使用的是dbow2库中已经训练好的orb词袋树。
8)对于待拼接图像数据集里的图像i,进行orb特征提取,将图像i中提取的特征描述子按照汉明距离从orb词袋树的根节点开始逐级向下到达叶子节点,遍历完所有的特征之后,在词袋树中存储该图像所有特征的正向索引。k为上一插入到拼接结构图的关键帧,通过正向索引对两幅图像进行特征搜索,建立特征之间的对应,从而得到两幅图像间特征的对应;
9)根据得到的两幅图像之间特征的对应,得到两幅图像之间的单应性矩阵khi;
10)利用随机抽样极大似然估计算法来最小化二次投影误差和排除外点,进而得到对应图像对的内点集;
11)根据得到的内点集计算图像的边界矩阵,通过边界矩阵计算图像的重叠百分比;
12)根据计算的重叠百分比,计算对应图像对之间的重叠koi=min(ok,oi),如果内点的数目大于阈值τin并且重叠koi大于阈值τov,那么图像i作为潜在的关键帧保存,如果待拼接数据集中下一帧图像与关键帧k得到的内点数目和重叠不满足上述两个阈值,则将图像i作为关键帧加入到拼接结构图;
7)当图像i作为关键帧加入到拼接结构图中时,需要与之前的关键帧通过单应性矩阵建立联系,则第k+1关键帧的单应性矩阵mhk+1表示为:mhk+1=mhkkhk+1,其中m是为了保证关键帧之间的对齐而定义的一个通用关键帧,拼接结构图中各个关键帧的单应性矩阵mhk+1,mhk都是与关键帧m建立的;
8)检测回环,新加入的关键帧图像i,与拼接结构图之前所有的关键帧图像进行检索匹配:新加入关键帧图像的orb特征进入词袋模型,按照汉明距离从词袋树的根节点开始逐级向下到达叶子节点,计算每个叶子节点也就是词袋树中每个词在图像i中出现的频率tf,在词袋树中每个叶子节点都存储了反向索引,即为存储了到达叶子节点的图像id和词在图像描述向量中的值,将新加入关键帧图像的所有特征,在词袋树中做检索,得到每个词的值,将这些值构成图像的描述向量;设新加入关键帧图像和与其匹配的上一关键帧图像的描述向量分别为ν1和ν2,两幅关键帧图像的相似度分数计算公式表示为:
得分越高表示这两幅关键帧图像的相似度越高,由此可以得到新加入关键帧图像与之前关键帧图
像的相似程度,从而可以得到一个从高到低关键帧相似度列表,这些关键帧图像即为有可能与新加入关
键帧图像形成回环的关键帧。
9)根据关键帧相似度列表顺序,计算这些关键帧与新加入关键帧的单应性矩阵,如果通过单应性矩阵得到的内点数目大于一个固定的阈值,那么相应的连接关系就成为拼接结构图的一部分,即为形成回环;
10)优化单应性矩阵,关键帧图像之间都是通过单应性矩阵进行联系的,然而单应性矩阵存在着误差,需要进行优化,采用光束法平差减小由单应性矩阵所造成的误差,误差函数ε为:
其中
11)图像拼接结构图的融合。
融合是拼接算法的最后一步,用于产生最后的无缝拼接图,这一部分是opencv库中stitching的应用,包括缝和线技术以及曝光补偿,在本发明中,这一部分根据之前产生的拼接结构图可以即时形成最终的无缝拼接图,即最终的实验效果图。
为了验证本发明方法的有效性和实时性,本发明选用两组数据集。valldemossa数据集,此数据集采集于西班牙的港口城市valldemossa的水下环境,包含201张320×180的图片,是由相机俯视拍摄的,此数据集包含有一个大的闭环;odemar数据集,此数据集为由miquelmassot-campos采集的水下环境,包含64张480×270的图片,是由相机仰视拍摄的,此数据集没有包含大的闭环。实验结果如下:
1.得到的valldemossa数据集的拼接图如图2所示,环境的拓扑估计如图3所示,拓扑图含有76帧关键帧。得到odemar数据集的拼接图如图4所示,环境的拓扑结构图如图5所示,拓扑图含有22帧关键帧。
2.此组实验为对比试验,由本发明的方法与采用orb特征的单线程拼接方法的比较,依然选用这两组数据集,得到的实验数据如表1所示,可以看到,在二次投影误差差别不大的情况下,算法的时间得到了很大的改善。
表1是本发明的实验数据与基于orb特征的单线程图像拼接算法的数据对比;
表1。
- 还没有人留言评论。精彩留言会获得点赞!