一种针对半结构化大数据的提取统计方法及系统与流程
本发明涉及大数据提取统计领域,尤其涉及一种针对半结构化大数据的提取统计方法及系统。
背景技术:
常用的大数据分析组件,比如hive(一种数据仓库工具),对模型的要求是需要统计的字段必须是单独列。但现实需求中,数据在业务方面也是存在特定要求的,需要是半结构化的数据模型模式。既要满足业务需要又要满足统计需求,在同一个模型中并存就存在很大的冲突。因此一般分析组件是把业务数据单独加载到特定的数据仓库中去处理。这样实际上就导致了数据冗余。在同一个模型(半结构化)的基础下,也可以开发独立的提取统计工具进行处理。但整个过程繁琐,需要经过配置(不同业务场景)、执行和查看等流程,不能像sql查询那样执行命令后自动化处理,同时在执行过程和运行结果的可视化方面也存在缺陷。
技术实现要素:
本发明所要解决的技术问题是针对现有技术的不足,提供一种针对半结构化大数据的提取统计方法及系统,目的在于针对半结构化的大数据操作提供一套完整工具,实现对半结构化大数据的提取统计命令操作和结果处理,可以使业务和分析场景使用统一模型,减少数据冗余,业务数据分析的运维和操作更简便可靠,提高可维护性和自动化可视化水平。
本发明解决上述技术问题的技术方案如下:
一种针对半结构化大数据的提取统计方法,包括以下步骤:
s1,客户端接收用户输入针对半结构化大数据进行提取和统计的操作语句,并将所述操作语句同步到解析转换模块进行处理;
s2,解析转换模块接收所述操作语句,对操作语句进行解析并将解析结果转换成配置规则;
s3,客户端调用应用引擎模块根据所述配置规则生成作业任务,将作业任务提交到底层框架进行处理;
s4,底层框架将作业任务拆分成多个子任务分配到集群上执行,并将执行后获取的结果数据返回给客户端进行展示。
本发明的有益效果是:借助客户端结合底层框架和集群,辅以处理流程,实现对半结构化大数据的提取统计命令操作和结果处理,从而提高可维护性和自动化可视化水平;针对半结构化的大数据操作提供一套完整方法,可以使业务和分析场景使用统一模型,减少数据冗余,业务数据分析的运维和操作更简便可靠。
在上述技术方案的基础上,本发明还可以做如下改进:
进一步,所述s2还包括:所述解析转换模块对操作语句进行解析并将解析结果转换成配置规则后,向客户端发送操作语句转换完成的消息;
所述s3还包括:客户端接收所述s2中解析转换模块发送的操作语句转换完成的消息,在接收到所述转换完成的消息后调用应用引擎模块,根据所述配置规则生成作业任务。
采用上述进一步方案的有益效果是:通过消息模式使客户端简单方便的判断操作语句转换成配置规则是否已经完成,节约系统资源,使客户端能在准确的时机调用应用引擎模块。
进一步,所述方法还包括步骤s5,s5包括:根据用户的选择将本次获取的结果数据备份到集群中。
采用上述进一步方案的有益效果是:备份结果数据使历史统计结果可重用,避免重复获取,提高了运行效率。
进一步,所述s1还包括:客户端在将用户输入的操作语句同步到解析转换模块前,先判断操作语句是否执行过、执行后获取的结果数据是否进行过备份以及该结果数据是否为静态数据,若均为是,则直接使用上次执行操作语句后获取的结果数据的备份,若至少有一项为否,则将用户输入的操作语句同步到解析转换模块。
采用上述进一步方案的有益效果是:对于上次执行过的针对静态数据的操作语句,可以直接调用上次备份过的结果数据,避免重复获取,提高了获取和展示结果数据的速度。
进一步,所述s2还包括:解析转换模块在对操作语句进行解析并将解析结果转换成配置规则后,将该操作语句以及对应的配置规则进行备份,在下次接收到客户端同步过来的相同的操作语句时,不进行解析并直接使用备份中对应的配置规则。
采用上述进一步方案的有益效果是:对相同的操作语句,解析转换模块只进行一次解析,然后将解析后转换成的配置规则进行备份,下次接收到同样的操作语句只需要在备份中获取对应的配置规则,不要再次进行解析转换的过程,节约了占用的资源和运行时间,提高了整体效率。
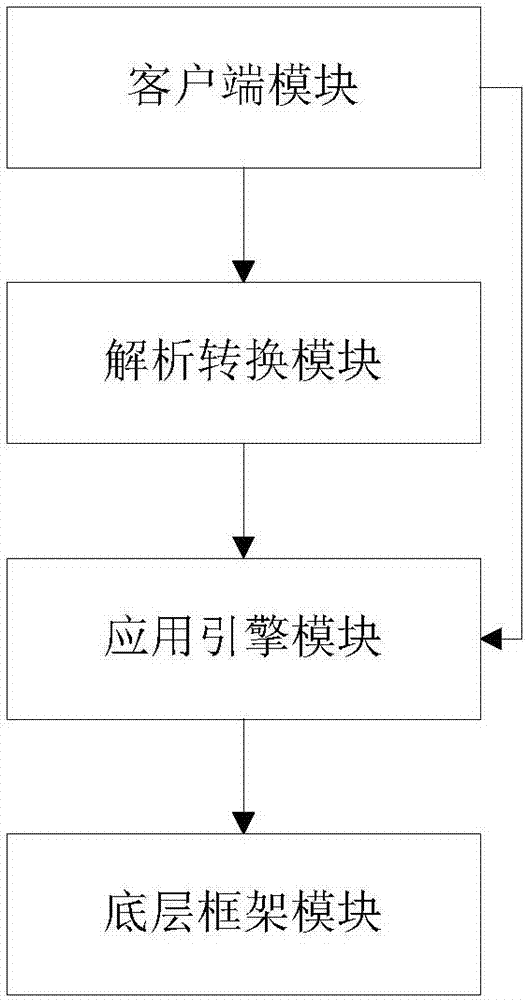
一种针对半结构化大数据的提取统计系统,所述系统包括:
客户端模块,用于用于接收用户输入的针对半结构化大数据进行提取和统计的操作语句,并将所述操作语句同步到解析转换模块,在解析转换模块完成对操作语句的解析转换后调用应用引擎模块获取结果数据,在应用引擎模块获取结果数据完成后将获取的结果数据进行展示;
解析转换模块,用于接收所述操作语句,对操作语句进行解析并将解析结果转换成配置规则;
应用引擎模块,用于接收到客户端模块的调用后,根据解析转换模块产生的配置规则生成作业任务,将作业任务提交到底层框架模块进行处理并获取底层框架模块返回的结果数据,将获取到的结果数据返回给客户端模块;
底层框架模块,用于将应用引擎模块提交的作业任务拆分成多个子任务分配到集群上执行,并将执行获得的结果数据返回给应用引擎模块。
本发明的有益效果是:借助客户端模块、解析转换模块和应用引擎模块,结合底层框架和集群,辅以处理流程,实现对半结构化大数据的提取统计命令操作和结果处理,从而提高可维护性和自动化可视化水平;针对半结构化的大数据操作提供一套完整系统,可以使业务和分析场景使用统一模型,减少数据冗余,业务数据分析的运维和操作更简便可靠。
在上述技术方案的基础上,本发明还可以做如下改进:
进一步,所述客户端模块还用于接收所述解析处理模块发送的操作语句转换完成的消息,在接收到所述转换完成的消息后调用所述应用引擎模块,所述应用引擎模块根据所述配置规则生成作业任务;
所述解析转换模块还用于在对操作语句进行解析并将解析结果转换成配置规则后,向客户端模块发送操作语句转换完成的消息。
采用上述进一步方案的有益效果是:通过消息模式使客户端模块简单方便的判断操作语句转换成配置规则是否已经完成,节约系统资源,使客户端模块能在准确的时机调用应用引擎模块。
进一步,所述客户端模块还用于根据用户的选择将本次获取的结果数据备份到集群中。
采用上述进一步方案的有益效果是:备份结果数据使历史统计结果可重用,避免重复获取,提高了系统的运行效率。
进一步,所述客户端模块在将用户输入的操作语句同步到解析转换模块前,先判断操作语句是否执行过、执行后获取的结果数据是否进行过备份以及该结果数据是否为静态数据,若均为是,则直接使用上次执行操作语句后获取的结果数据的备份,若至少有一项为否,则将用户输入的操作语句同步到解析转换模块。
采用上述进一步方案的有益效果是:对于上次执行过的针对静态数据的操作语句,可以直接调用上次备份过的结果数据,避免重复获取,提高了获取和展示结果数据的速度。
进一步,所述解析转换模块还用于所述解析转换模块还用于在对操作语句进行解析并将解析结果转换成配置规则后,将该操作语句以及对应的配置规则进行备份,在下次接收到客户端模块同步过来的相同的操作语句时,不进行解析并直接使用备份中对应的配置规则。
采用上述进一步方案的有益效果是:对相同的操作语句,解析转换模块只进行一次解析,然后将解析后转换成的配置规则进行备份,下次接收到同样的操作语句只需要在备份中获取对应的配置规则,不要再次进行解析转换的过程,节约了系统资源和运行时间,提高了系统效率。
附图说明
图1为本发明实施例1中一种针对半结构化大数据的提取统计方法的流程图;
图2为本发明实施例2中一种针对半结构化大数据的提取统计系统的框图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
实施例1
如图1所示,一种针对半结构化大数据的提取统计方法,包括以下步骤:
s1,客户端接收用户输入针对半结构化大数据进行提取和统计的操作语句,并将所述操作语句同步到解析转换模块进行处理;
s2,解析转换模块接收所述操作语句,对操作语句进行解析并将解析结果转换成配置规则;
s3,客户端调用应用引擎模块根据所述配置规则生成作业任务,将作业任务提交到底层框架进行处理;
s4,底层框架将作业任务拆分成多个子任务分配到集群上执行,并将执行后获取的结果数据返回给客户端进行展示。
具体的,客户端负责用户交互,用户先登录客户端,客户端自动展示客户端的版本和支持的命令列表等信息。输入帮助命令,可以展示各类型语句(即操作语句,sql执行语句)的用法。
整个方法基于hadoop平台(hadoop是一个由apache基金会所开发的分布式系统基础架构),hadoop平台做为源数据和结果数据的实际物理存储而存在,其中用来保存源数据和结果数据的是hdfs(即hadoop分布式文件系统)和hbase(一种基于hadoop平台的非关系型数据库),hadoop平台同时也提供分布式协调服务。应用引擎模块(包括查询引擎和统计引擎)负责根据解析转换后的配置规则生成作业,提交到yarn(yetanotherresourcenegotiator,另一种资源协调者,即是一种资源管理和作业调度/监控的工具)上执行,产生结果数据。其中底层框架基于hadoop平台中的mr2.0框架(mapreduce2.0,一种软件架构,用于大规模数据集的并行运算,字面含义为:映射与归纳),应用引擎模块是基于mr2.0框架的应用,应用引擎模块提交的作业任务是mapreduce作业,由底层框架中基于hadoop平台的yarn进行管理,拆分成多个子任务在hadoop集群中运行。
客户端获取的结果数据给用户时,如果结果数据量超过阀值,则只展示部分,并提供命令在解析转换模块查看。
本发明借助客户端结合底层框架和集群,辅以处理流程,实现对半结构化大数据的提取统计命令操作和结果处理,从而提高可维护性和自动化可视化水平;针对半结构化的大数据操作提供一套完整方法,可以使业务和分析场景使用统一模型,减少数据冗余,业务数据分析的运维和操作更简便可靠。
进一步,所述s2还包括:所述解析转换模块对操作语句进行解析并将解析结果转换成配置规则后,向客户端发送操作语句转换完成的消息;
所述s3还包括:客户端接收所述s2中解析转换模块发送的操作语句转换完成的消息,在接收到所述转换完成的消息后调用应用引擎模块,根据所述配置规则生成作业任务。
具体的,客户端在将用户输入的操作语句同步到解析转换模块后,等待并判断是否成功完成解析转换处理(即是否收到解析转换模块发送的操作语句转换完成的消息),成功完成解析转换处理后调用相应的应用引擎模块获取结果数据。
该改进中,通过消息模式使客户端简单方便的判断操作语句转换成配置规则是否已经完成,节约系统资源,使客户端能在准确的时机调用应用引擎模块。
进一步,还包括步骤s5,s5包括:根据用户的选择将本次获取的结果数据备份到集群中。
具体的,客户端在将获取的结果数据展示给用户时,提供界面供用户输入命令,让用户确认是否备份结果数据,并根据用户的选择完成本次操作。
该改进中,备份结果数据使历史统计结果可重用,避免重复获取,提高了运行效率。
进一步,所述s1还包括:客户端在将用户输入的操作语句同步到解析转换模块前,先判断操作语句是否执行过、执行后获取的结果数据是否进行过备份以及该结果数据是否为静态数据,若均为是,则直接使用上次执行操作语句后获取的结果数据的备份,若至少有一项为否,则将用户输入的操作语句同步到解析转换模块。
具体的,客户端在将用户输入的操作语句同步到解析转换模块前,判断发现操作语句以前执行过、用户对相应的结果数据进行过备份并且相应的结果数据是静态数据,则直接使用上次运行后备份的结果数据,避免重复。
该改进中,对于上次执行过的针对静态数据的操作语句,可以直接调用上次备份过的结果数据,避免重复获取,提高了获取和展示结果数据的速度。
进一步,所述s2还包括:解析转换模块在对操作语句进行解析并将解析结果转换成配置规则后,将该操作语句以及对应的配置规则进行备份,在下次接收到客户端同步过来的相同的操作语句时,不进行解析并直接使用备份中对应的配置规则。
该改进中,对相同的操作语句,解析转换模块只进行一次解析,然后将解析后转换成的配置规则进行备份,下次接收到同样的操作语句只需要在备份中获取对应的配置规则,不要再次进行解析转换的过程,节约了占用的资源和运行时间,提高了整体效率。
实施例2
如图2所示,一种针对半结构化大数据的提取统计系统,包括:
客户端模块,用于接收用户输入的针对半结构化大数据进行提取和统计的操作语句,并将所述操作语句同步到解析转换模块,在解析转换模块完成对操作语句的解析转换后调用应用引擎模块获取结果数据,在应用引擎模块获取结果数据完成后将获取的结果数据进行展示;
解析转换模块,用于接收所述操作语句,对操作语句进行解析并将解析结果转换成配置规则;
应用引擎模块,用于接收到客户端模块的调用后,根据解析转换模块产生的配置规则生成作业任务,将作业任务提交到底层框架模块进行处理并获取底层框架模块返回的结果数据,将获取到的结果数据返回给客户端模块;
底层框架模块,用于将应用引擎模块提交的作业任务拆分成多个子任务分配到集群上执行,并将执行获得的结果数据返回给应用引擎模块。
具体的,客户端模块负责用户交互,用户先登录客户端模块,客户端模块自动展示客户端的版本和支持的命令列表等信息。输入帮助命令,可以展示各类型语句(即操作语句,sql执行语句)的用法。
整个系统运行在hadoop平台上(hadoop是一个由apache基金会所开发的分布式系统基础架构),hadoop平台做为源数据和结果数据的实际物理存储而存在,其中用来保存源数据和结果数据的是hdfs(即hadoop分布式文件系统)和hbase(一种基于hadoop平台的非关系型数据库),hadoop平台同时也提供分布式协调服务。应用引擎模块(包括查询引擎和统计引擎)负责根据解析转换后的配置规则生成作业,提交到yarn(yetanotherresourcenegotiator,另一种资源协调者,即是一种资源管理和作业调度/监控的工具)上执行,产生结果数据。其中底层框架模块是基于hadoop平台中的mr2.0框架(mapreduce2.0,一种软件架构,用于大规模数据集的并行运算,字面含义为:映射与归纳)的模块,应用引擎模块是基于mr2.0框架的应用,应用引擎模块提交的作业任务是mapreduce作业,由底层框架模块中基于hadoop平台的yarn进行管理,拆分成多个子任务在hadoop集群中运行。
客户端模块获取的结果数据给用户时,如果结果数据量超过阀值,则只展示部分,并提供命令在解析转换模块查看。
本发明借助客户端模块、解析转换模块和应用引擎模块,结合底层框架和集群,辅以处理流程,实现对半结构化大数据的提取统计命令操作和结果处理,从而提高可维护性和自动化可视化水平;针对半结构化的大数据操作提供一套完整系统,可以使业务和分析场景使用统一模型,减少数据冗余,业务数据分析的运维和操作更简便可靠。
进一步,所述客户端模块还用于接收所述解析处理模块发送的操作语句转换完成的消息,在接收到所述转换完成的消息后调用所述应用引擎模块,所述应用引擎模块根据所述配置规则生成作业任务;
所述解析转换模块还用于在对操作语句进行解析并将解析结果转换成配置规则后,向客户端模块发送操作语句转换完成的消息。
具体的,客户端模块在将用户输入的操作语句同步到解析转换模块后,等待并判断是否成功完成解析转换处理(即是否收到解析转换模块发送的操作语句转换完成的消息),成功完成解析转换处理后调用相应应用引擎获取结果数据。
该改进中,通过消息模式使客户端模块简单方便的判断操作语句转换成配置规则是否已经完成,节约系统资源,使客户端模块能在准确的时机调用应用引擎模块。
进一步,所述客户端模块还用于根据用户的选择将本次获取的结果数据备份到集群中。
具体的,客户端模块在将获取的结果数据展示给用户时,提供界面供用户输入命令,让用户确认是否备份结果数据,并根据用户的选择完成本次操作。
该改进中,备份结果数据使历史统计结果可重用,避免重复获取,提高了系统的运行效率。
进一步,所述客户端模块在将用户输入的操作语句同步到解析转换模块前,先判断操作语句是否执行过、执行后获取的结果数据是否进行过备份以及该结果数据是否为静态数据,若均为是,则直接使用上次执行操作语句后获取的结果数据的备份,若至少有一项为否,则将用户输入的操作语句同步到解析转换模块。
具体的,客户端模块在将用户输入的操作语句同步到解析转换模块前,判断发现操作语句以前执行过、用户对相应的结果数据进行过备份并且相应的结果数据是静态数据,则直接使用上次运行后备份的结果数据,避免重复。
该改进中,对于上次执行过的针对静态数据的操作语句,可以直接调用上次备份过的结果数据,避免重复获取,提高了获取和展示结果数据的速度。
进一步,所述解析转换模块还用于所述解析转换模块还用于在对操作语句进行解析并将解析结果转换成配置规则后,将该操作语句以及对应的配置规则进行备份,在下次接收到客户端模块同步过来的相同的操作语句时,不进行解析并直接使用备份中对应的配置规则。
该改进中,对相同的操作语句,解析转换模块只进行一次解析,然后将解析后转换成的配置规则进行备份,下次接收到同样的操作语句只需要在备份中获取对应的配置规则,不要再次进行解析转换的过程,节约了系统资源和运行时间,提高了系统效率。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!