视频中运动目标的跟踪方法及装置与流程
本发明涉及视频跟踪技术领域,特别是涉及一种视频中运动目标的跟踪方法及装置。
背景技术:
随着信息技术的蓬勃发展,计算机视觉技术在视频跟踪领域的应用越来越广泛,尤其在体育赛事视频分析中,通过计算机视觉跟踪运动目标进行体育赛事分析能够大大减少人工成本,提高分析准确度。近年来基于在线机器学习的跟踪算法得到了快速发展,如在线boosting算法、“跟踪-检测-学习”算法、以及基于压缩感知的跟踪算法等,然而,上述各种基于在线机器学习的运动目标跟踪方法由于需要不断学习新的模型,使得计算复杂度高,影响跟踪效率,且容易产生跟踪漂移问题,跟踪准确性低。
技术实现要素:
基于此,有必要针对传统运动目标跟踪方法存在的跟踪效率低、跟踪准确性低的问题,提供一种快速且准确有效的视频中运动目标的跟踪方法及装置。
一种视频中运动目标的跟踪方法,包括以下步骤:
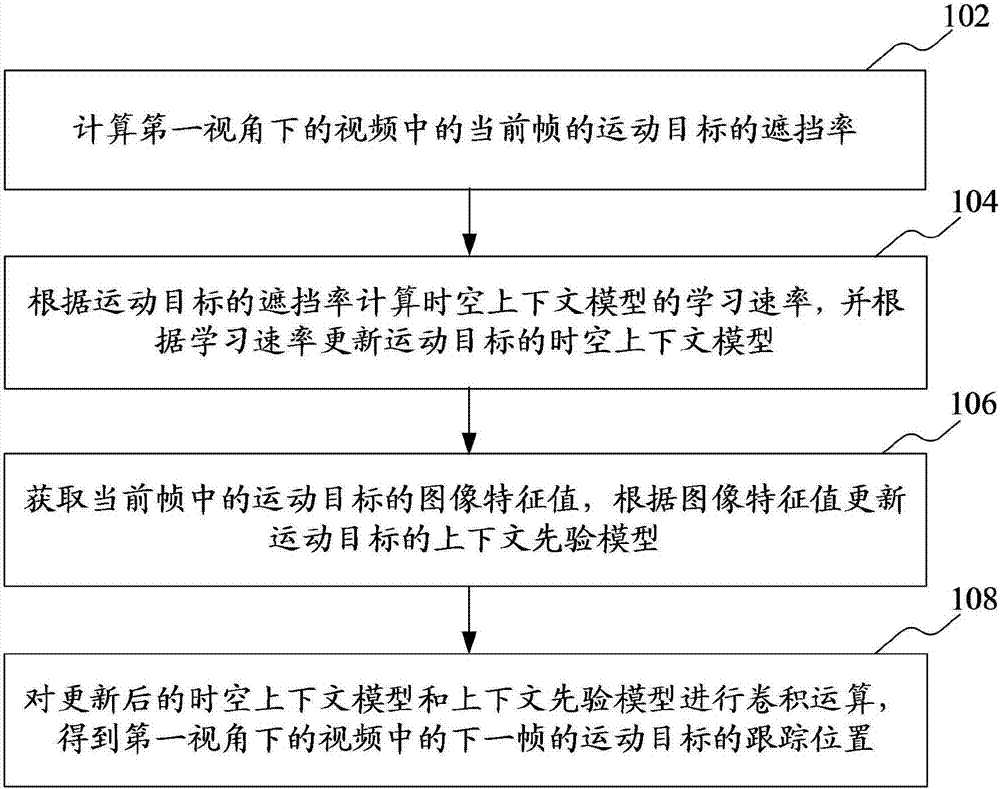
计算第一视角下的视频中的当前帧的运动目标的遮挡率;
根据运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型;
获取当前帧中的运动目标的图像特征值,根据图像特征值更新运动目标的上下文先验模型;
对更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。
上述视频中运动目标的跟踪方法,通过计算第一视角下的视频中的当前帧的运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型;再根据图像特征值更新运动目标的上下文先验模型;根据更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。上述视频中运动目标跟踪方法通过更新运动目标的时空上下文模型上下文先验模型即可实现下一帧运动目标的跟踪定位,只要进行模型更新即可,不需要一直学习新的模型,有效降低了计算复杂度,有效提升跟踪效率,并且,上述视频中运动目标的跟踪方法根据运动目标的遮挡情况动态确定时空上下文模型的学习速率以更新时空上下文模型,能够避免运动目标被其它物体遮挡时学习到错误的模型,有效避免出现跟踪漂移,大大提高跟踪准确性。
在其中一个实施例中,计算第一视角下的视频中的当前帧的运动目标的遮挡率的步骤包括:
检测当前帧的不同的运动目标的跟踪框之间是否包括交点;
当不同的运动目标的跟踪框之间包括交点时,计算不同的运动目标的跟踪框之间重叠部分的长度和宽度,并根据长度和宽度计算运动目标发生遮挡的遮挡面积;
获取预先存储的运动目标的跟踪框面积,计算运动目标的遮挡率为遮挡面积与跟踪框面积的比值。
在其中一个实施例中,采用以下公式计算学习速率:
其中:
e为自然对数;
δs为运动目标的遮挡率;
k、
在其中一个实施例中,获取当前帧中的运动目标的图像特征值的步骤包括:
获取当前帧中的运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度以及在蓝色通道上的颜色强度;
为运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度,及在蓝色通道上的颜色强度赋予相应的颜色强度权重值;
对在每个通道上的颜色强度进行加权求和,得到当前帧中的运动目标的图像特征值。
在其中一个实施例中,上述视频中运动目标的跟踪方法还包括:
提取追踪场地边线区域,建立追踪场地俯视二维模型,将跟踪位置投影至追踪场地俯视二维模型中的第一投影坐标。
在其中一个实施例中,上述视频中运动目标的跟踪方法还包括:
获取第二视角下的视频,并计算在第二视角下的视频中与下一帧对应的视频帧的运动目标的跟踪位置在追踪场地俯视二维模型中的第二投影坐标;
分别将第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率与预设遮挡率阈值进行比较;
当第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率均小于或等于预设遮挡率阈值时,根据第一投影坐标和第二投影坐标计算运动目标在追踪场地俯视二维模型中的目标投影坐标;
当第一视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第二投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标;当第二视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第一投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标。
在其中一个实施例中,选取第二投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标的步骤之后,还包括:根据第二投影坐标对第一投影坐标进行修正;
选取第一投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标的步骤之后,还包括:根据第一投影坐标对第二投影坐标进行修正。
一种视频中运动目标的跟踪装置,包括:
遮挡率计算模块,用于计算第一视角下的视频中的当前帧的运动目标的遮挡率;
时空上下文模型更新模块,用于根据运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型;
上下文先验模型更新模块,用于获取当前帧中的运动目标的图像特征值,根据图像特征值更新运动目标的上下文先验模型;
跟踪模块,用于对更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。
在其中一个实施例中,时空上下文模型更新模块包括:
交点检测子模块,用于检测当前帧的不同的运动目标的跟踪框之间是否包括交点;
遮挡面积计算子模块,用于当不同的运动目标的跟踪框之间包括交点时,计算不同的运动目标的跟踪框之间重叠部分的长度和宽度,并根据长度和宽度计算运动目标发生遮挡的遮挡面积;
遮挡率计算子模块,用于获取预先存储的运动目标的跟踪框面积,计算运动目标的遮挡率为遮挡面积与跟踪框面积的比值。
在其中一个实施例中,学习速率计算模块采用以下公式计算学习速率:
其中:
e为自然对数;
δs为运动目标的遮挡率;
k、
附图说明
图1为一个实施例中视频中运动目标的跟踪方法的流程图;
图2为一个实施例中计算运动目标的遮挡率的流程图;
图3为一个实施例中运动目标的遮挡面积计算原理示意图;
图4为又一个实施例中视频中运动目标的跟踪方法的流程图;
图5为一个实施例中运动目标的时空上下文信息界面显示示意图;
图6为一个实施例中追踪场地俯视二维模型显示示意图;
图7为一个实施例中视频中运动目标的跟踪装置的结构示意图;
图8为一个实施例中时空上下文模型更新模块的结构示意图;
图9为一个实施例中上下文先验模型更新模块的结构示意图;
图10为又一个实施例中时空上下文模型更新模块的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参阅图1,一种视频中运动目标的跟踪方法,包括以下步骤:
步骤102:计算第一视角下的视频中的当前帧的运动目标的遮挡率。
具体地,运动目标的遮挡率表示运动目标被遮挡的程度,根据运动目标发生遮挡的面积计算得到。终端检测运动目标是否发生遮挡,当运动目标发生遮挡时,则计算运动目标的遮挡率;否则,运动目标的遮挡率为0。
步骤104:根据运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型。
具体地,空间上下文模型关注运动目标与其局部上下文的空间位置关系,包括距离和方向关系。视频序列是连续的,时间上的上下文相关性对于跟踪结果也非常重要,每一帧的运动目标的时空上下文模型通过学习速率学习上一帧跟踪目标的时空上下文模型和空间上下文模型得到。当运动目标被其他物体遮挡时,运动目标的外观模型会受到改变,此时运动目标的空间上下文模型可信度降低,本实施例中,通过调整运动目标的时空上下文模型的学习速率以防止学习到错误的模型。具体地,根据运动目标发生遮挡的情况动态确定时空上下文模型的学习速率,并根据学习速率更新第一视角下的视频中的下一帧的运动目标的时空上下文模型。
步骤106:获取当前帧中的运动目标的图像特征值,根据图像特征值更新运动目标的上下文先验模型。
具体地,上下文先验模型反映运动目标当前局部上下文自身的空间构成,与上下文空间的图像特征与其空间位置结构有关,本实施例中,终端获取当前帧中的运动目标的图像特征值,根据图像特征值更新运动目标的上下文先验模型。
步骤108:对更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。
上述视频中运动目标的跟踪方法,通过计算第一视角下的视频中的当前帧的运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型;再根据图像特征值更新运动目标的上下文先验模型;根据更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。上述视频中运动目标跟踪方法通过更新运动目标的时空上下文模型上下文先验模型即可实现下一帧运动目标的跟踪定位,只要进行模型更新即可,不需要一直学习新的模型,有效降低了计算复杂度,有效提升跟踪效率,并且,上述视频中运动目标的跟踪方法根据运动目标的遮挡情况动态确定时空上下文模型的学习速率以更新时空上下文模型,能够避免运动目标被其它物体遮挡时学习到错误的模型,有效避免出现跟踪漂移,大大提高跟踪准确性。
如图2所示,在一个实施例中,步骤102包括:
步骤1022:检测当前帧的不同的运动目标的跟踪框之间是否包括交点。
为了保证运动目标初始位置的准确性,为之后的跟踪打下良好的基础,本实施例中,通过人机交互对第一视角下的视频的第一帧中运动目标的初始位置进行人工标定,人工选定跟踪框,确定各运动目标的初始位置,具体的,本实施例中,跟踪框为矩形框。跟踪过程中,终端实时检测不同的运动目标的跟踪框之间是否包括交点,如果不同的运动目标的跟踪框之间包括交点,则表示运动目标之间发生遮挡,执行步骤1024;否则,运动目标没有发生遮挡,直接得到运动目标的遮挡率为0。
步骤1024:当不同的运动目标的跟踪框之间包括交点时,计算不同的运动目标的跟踪框之间重叠部分的长度和宽度,并根据长度和宽度计算运动目标发生遮挡的遮挡面积。
如图3所示,本实施例中,以跟踪框的左上角为原点,向右为x轴,向下为y轴建立坐标系。完成当前帧跟踪得到运动目标的跟踪位置即能够得到跟踪框的顶点的位置坐标。为便于计算,本实施例选取跟踪框的左上角顶点坐标和右下角顶点坐标进行计算,其中,跟踪框k1的左上角顶点坐标为(minx1,miny1),右下角顶点坐标为(maxx1,maxy1),跟踪框k2的左上角顶点坐标为(minx2,miny2),右下角顶点坐标为(maxx2,maxy2)。跟踪框k1和跟踪框k2包括两个交点,分别为交点e和交点f,根据跟踪框k1的右下角顶点的横坐标和跟踪框k2的左上角顶点的纵坐标可以得到交点e点的坐标为(maxx1,miny2);同理,根据跟踪框k2左上角的横坐标和和跟踪框k1右下角的纵坐标得到交点f的坐标为(minx2,maxy1)。获取到交点e和交点f的坐标后即可计算跟踪框k1和跟踪框k2重叠部分的长度和宽度。其中,计算交点e的横坐标与第二跟踪框k2左上角顶点的横坐标的差值,得到跟踪框k1和跟踪框k2重叠部分的宽度,并计算交点f的纵坐标与第二跟踪框k2左上角顶点的纵坐标之差得到跟踪框k1和跟踪框k2重叠部分的长度。进一步的,计算长度和宽度的乘积即得到运动目标发生遮挡的遮挡面积,遮挡面积soverlap=(maxx1-minx2)*(maxy1-miny2)。
本实施例中,通过计算交点坐标再进一步计算跟踪框之间重叠部分的长度和宽度以计算得到遮挡面积。但是,需要说明的是,以上实施例并不用于对遮挡面积计算的具体限定。如,在其它实施例中,还可以直接通过跟踪框k1的左上角顶点及右下角顶点的坐标和跟踪框k2的左上角顶点及右下角顶点坐标计算遮挡面积。为便于说明,仍以图3为例进行说明,在一个实施例中,定义minx=max(minx1,minx2),即minx为minx1与minx2当中的较大值;同时,定义maxx=min(maxx1,maxx2),maxx为maxx1与maxx2中的较小值;miny=max(miny1,miny2),miny为miny1与miny2中的较大值;maxy=min(maxy1,maxy2),maxy为maxy1与maxy2中的较小值。跟踪过程中,终端根据实时比较minx与maxdx的大小,及miny与maxy的大小,根据比较结果判断跟踪框之间是否发生遮挡并在发生遮挡时计算遮挡面积。具体的,如果minx<maxx并且miny<maxy,则跟踪框k1和跟踪框k2重叠,运动目标发生遮挡,计算遮挡面积为:soverlap=(maxx-minx)*(maxy-miny)。如图3所示,本实施例中,minx=minx2,miny=miny2,maxx=maxx1,maxy=maxy1,遮挡面积soverlap=(maxx1-minx2)*(maxy1-miny2)。
步骤1026:获取预先存储的运动目标的跟踪框面积,计算运动目标的遮挡率为遮挡面积与跟踪框面积的比值。
具体地,步骤1022中,标定运动目标跟踪框后计算并存储跟踪框面积,步骤1024计算得到运动目标的遮挡面积后,终端读取跟踪框面积,计算遮挡面积与跟踪框面积的比值,得到运动目标的遮挡率如下:
其中soverlap为运动目标的遮挡面积,s0为跟踪框面积。
在一个实施例中,步骤104中,采用以下公式计算学习速率:
其中:e为自然对数;δs为运动目标的遮挡率;k、
在一个实施例中,步骤106中,获取当前帧中的运动目标的图像特征值的步骤包括:获取当前帧中的运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度以及在蓝色通道上的颜色强度;为运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度,及在蓝色通道上的颜色强度赋予相应的颜色强度权重值;对在每个通道上的颜色强度进行加权求和,得到当前帧中的运动目标的图像特征值。
具体地,运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度,及在蓝色通道上的颜色强度赋予相应的颜色强度权重值根据不同运动目标在红色通道、绿色通道及蓝色通道上的颜色强度的差异大小确定,颜色强度差异越大,该通道上的颜色强度权重值越大。本实施例中,通过不同运动目标之间的颜色差异确定每个运动目标的颜色特征值以用于上下文先验模型更新,以确保上下文先验模型跟踪准确,进一步提高跟踪准确性。
在一个实施例中,上述视频中运动目标的跟踪方法还包括:提取追踪场地边线区域,建立追踪场地俯视二维模型,将跟踪位置投影至追踪场地俯视二维模型中的第一投影坐标。
通过步骤102至步骤108跟踪得到的运动目标的坐标及位置关系都是在第一视角的摄像机所拍摄得到的原视图中的位置,为了将追踪结果形象化展示以便于跟踪分析,本实施例中,建立一个追踪场地的俯视二维模型同步显示各运动目标的跟踪位置。在该追踪场地俯视二维模型中每个运动目标具有一个目标标识,完成每一帧追踪后,将运动目标的目标标识由上一帧中的相应第一投影坐标移动至与当前确定的跟踪位置对应的第一投影坐标处。
一般的,追踪场地的二维模型图为俯视图,而原视频的拍摄角度一般是带有一定角度的侧视图。本实施例中,根据摄像机所在位置及角度进行视角以及数据尺度上的转换,将运动目标的跟踪位置同步地显示在追踪场地的俯视二维模型上。具体地,本实施例通过齐次变换建立原视频图像与二维模型的转化关系。首先,将二维平面的投影变换表示为齐次坐标下向量与一个3x3矩阵的乘积,即为x’=hx,具体单应变换矩阵表示如下:
由以上单应变换矩阵可知,平面单应变换为八个自由度,求解变换矩阵中的八个未知数即可求得单应变换矩阵,完成目标投影变换。由于一组对应点坐标可由上述矩阵乘式得到两个方程,要求原变换矩阵中所有未知数,需要四组方程,故,若要求得单应变换矩阵,只需知道对应的四组点坐标即可。具体的,本实施例中,通过提取追踪场地边线区域确定追踪场地的四组顶点坐标,以求得变换矩阵,实现二维投影变换。本实施例通过单应变换矩阵计算三维视频图像的二维投影变换,无需获取摄像设备的参数信息,视频分析系统简单易用,转换灵活性高。
在一个实施例中,上述视频中运动目标的跟踪方法还包括:获取第二视角下的视频,并计算在第二视角下的视频中与下一帧对应的视频帧的运动目标的跟踪位置在追踪场地俯视二维模型中的第二投影坐标;分别将第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率与预设遮挡率阈值进行比较;当第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率均小于或等于预设遮挡率阈值时,根据第一投影坐标和第二投影坐标计算运动目标在追踪场地俯视二维模型中的目标投影坐标;当第一视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第二投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标;当第二视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第一投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标。
具体地,第二视角下的视频中下一帧运动目标跟踪位置的确定及跟踪位置在追踪场地俯视二维模型中的第二投影坐标的转换过程及原理均与第一视角下的视频中下一帧运动目标跟踪位置的确定及跟踪位置在追踪场地俯视二维模型中的第二投影坐标的转换相同,在此不予赘述。
在多运动目标追踪场景中,由于目标运动复杂,极其容易出现大面积遮挡甚至完全遮挡的情况,如果两个跟踪框叠加到一起会发生漂移跳变,并且,跟踪过程中当运动目标发生大幅度遮挡时,即使未发生漂移跳变,由于在此视角下无法判断有遮挡关系的物体间的距离,被遮挡物体所获得的坐标信息也是不准确的。因此,本实施例根据运动目标发生遮挡的情况判断第一视角下得到的运动目标的第一投影坐标和第二视角下得到的运动目标的第二投影坐标是否有误,如果某一视角下运动目标发生遮挡的情况较严重,运动目标的遮挡率大于预设遮挡率阈值,则该视角下得到的运动目标的投影坐标错误,选取另一个视角下得到的运动目标的投影坐标作为最终的目标投影坐标;如果两个视角下运动目标的遮挡率都小于或等于预设遮挡率阈值,则两个视角下得到的运动目标的投影坐标均是正确的,此时为第一投影坐标和第二投影坐标赋予权重值,根据第一投影坐标和第二投影坐标进行加权和计算,得到运动目标在追踪场地俯视二维模型中的目标投影坐标,同时根据第一投影坐标和第二投影坐标对对跟踪结果进行优化,确保跟踪准确。
具体地,由于在跟踪过程中,跟踪框的尺寸是固定的,但跟踪的运动目标在摄像机视角下存在近大远小的关系。因此,在一个实施例中,定义界定遮挡情况的预设遮挡率阈值与目标在二维模型上距离摄像机的距离有关,根据运动目标在追踪场地俯视二维模型中距离摄像机的距离计算预设遮挡率阈值,并根据第一视角视频及第二视角视频中运动目标距离摄像机的距离计算第一视角视频中下一帧运动目标的跟踪位置及第二视角视频中下一帧运动目标的跟踪位置的权重。
本实施例通过对不同视角下的视频进行同时追踪,将每个视角下得到的运动目标的跟踪位置均投影到追踪场地俯视二维模型中,并根据运动目标发生遮挡的情况将两个视角下对同一运动目标的跟踪结果统一化,基于双视角的视频追踪对跟踪结果进行优化,确保跟踪准确,大大提高跟踪准确性。
在一个实施例中,选取第二投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标的步骤之后,还包括:根据第二投影坐标对第一投影坐标进行修正;选取第一投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标的步骤之后,还包括:根据第一投影坐标对第二投影坐标进行修正。本实施例中,当某一视角下的跟踪结果有误时,通过另一视角下的跟踪结果对错误的跟踪结果进行修正,并根据修正后的跟踪结果更新时空上下文模型,以确保后续跟踪结果准确,进一步提高跟踪准确性。
进一步地,为了便于理解本发明的技术方案,以下结合图4至图6,以足球视频跟踪为例对上述视频中运动目标的跟踪方法进行详细说明。为便于说明,将两个足球队定义为甲队和乙队,其中,甲队队员在球场俯视二维模型中的球员标识为矩形,乙队队员在球场俯视二维模型中的球员标识为圆形。
一种视频中运动目标的跟踪方法,包括以下步骤:
1)、确定运动目标初始位置,标定运动目标跟踪框。
首先,读取第t帧图像,通过人工标定跟踪框确定第t帧中各球员(即运动目标)的初始位置。具体地,人工标定球员跟踪框时,可采用鼠标选定跟踪框,分别对第一视角下的视频中及第二视角下的视频中第一帧中球员的初始位置进行标定,确定第一视角下的视频中及第二视角下的视频中第一帧中球员的初始位置。进一步的,完成球员初始位置标定后,终端进一步计算并存储每个球员跟踪框的跟踪框面积。
2)、计算当前帧的运动目标的遮挡率。
具体地,分别计算第一视角下的视频中及第二视角下的视频中对应的当前帧的每个球员的遮挡率,根据当前帧中每个球员跟踪框的跟踪框面积和当前球员发生遮挡的遮挡面积计算第一视角下的视频中及第二视角下的视频中对应的当前帧的每个球员的遮挡率,具体运动目标的遮挡率的计算原理及过程已在前述实施例中详细描述,在此不再赘述。
3)、计算时空上下文模型的学习速率,更新时空上下文模型。
时间上的上下文信息是连续帧间的时间关联性,空间上的上下文信息是由跟踪目标与其周围可定范围内的背景图像的组合。利用时空上下文信息对目标进行跟踪首先需要建立跟踪模型,具体地,目标跟踪问题,即为一个目标出现位置的概率问题。令o为要跟踪的目标,x为一个图像上的二维坐标点,p(x|o)表示坐标x在目标o中出现,将目标跟踪转换为了最大置信度的计算问题。
令:
m(x)=p(x|o);公式(4)
则当置信图m(x)取值最大时,所对应的坐标x,即可认为是目标o最可能出现的位置。如图5所示,实线框范围内为目标所在区域,外部虚线框范围内为局部上下文区域。用目标中心位置坐标x*代表目标所在位置,z为局部上下文区域内一点。定义目标x*的局部上下文区域为ωc(x*),并定义此局部区域的上下文特征集合为xc={c(z)=(i(z),z)|z∈ωc(x*)},其中,i(z)为z坐标处的图像特征值。利用全概率公式,以局部上下文特征为中间量,将公式(4)式展开,即可以得到:
其中,p(x|c(z),o)表示当给定目标o和其局部上下文特征c(z)时,目标出现在x点的概率,它为跟踪目标所在位置与其上下文信息的空间关系建立了空间上下文模型。而p(c(z)|o)代表某一上下为文特征c(z)出现在目标o中的概率,是目标o的上下文先验概率,为当前局部上下文的外观先验模型。其中,上下文先验模型表示当通过计算置信图m(x)进行目标位置预测时,所选择的是与上一帧目标所处位置外观相似的上下文,而空间上下文模型则保证了所选择的新目标位置不仅在外观上与原目标相似,且在空间位置上也是具有合理性的,从而在一定程度上避免因其他外观相似的物体出现而形成干扰,避免造成跟踪中的漂移现象。
基于上述,本实施例中,预先对公式(5)中的每一部分进行具体的数学模型建立,具体包括置信图建模、空间上下文模型建模和上下文先验模型建模。
首先,置信图的建模如下:由于视频中第一帧中的目标位置已知(根据对初始帧进行跟踪框标定得到),置信图m(x)应满足距离目标x*位置越近,其置信度越大这一性质。因此,令:
其中,b为归一化常参数;α为尺度常参数,β为函数曲线图像控制常参数。α与跟踪目标的尺寸大小相关,取值范围为1.75~2.75;β取值范围为0.5~1.5。在一个实施例中,α=2.25,β=1。
其次,空间上下文模型p(x|c(z),o)的建模如下:由于空间上下文模型关注的是跟踪目标与其局部上下文的空间位置关系,即包括距离和方向关系,故定义p(x|c(z),o)为一非径向对称的函数:
p(x|c(z),o)=hsc(x-z);公式(7)
其中:x为目标所在位置,z为其局部上下文中某一位置,则即使当有两点z1、z2与目标中心位置x*距离相同时,由于其所处位置不同,hsc(x*-z1)≠hsc(x*-z2),即表明它们对于x*来说,代表着不同的上下文,以有效区分不同的空间关系,防止发生歧义。
最后,上下文先验模型p(c(z)|o)的建模如下:上下文先验模型反映的是当前局部/上下文自身的空间构成,直观地考虑,应与上下文空间的图像特征与其空间位置结构有关。因此,令:
p(c(z)|o)=i(z)ωσ(z-x*);公式(8)
其中,i(z)为局部上下文区域中z点处的图像特征值,ωσ(δ)为权值函数。
具体地,在跟踪过程中,可类比人眼追踪某物的过程,距离跟踪目标越近的上下文区域,可认为是与跟踪目标越相关的,因此重要性越高,而距离跟踪目标越远的上下文区域,可认为是与跟踪目标较为无关的部分,因此重要性较低。据此,定义:
其中,δ为两点间距离,λ为归一化常参数,用于使p(c(z)|o)的取值处于0到1之间,以符合概率函数的定义;σ为尺度参数,与跟踪目标大小相关。
将公式(9)代入公式(8)得到上下文先验模型如下:
也即,将局部上下文的空间构成建模为此区域内各点图像特征值的高斯加权和。
进一步的,本实施例中,完成上述置信图建模、空间上下文模型建模和上下文先验模型建模后,进一步根据上述置信图、空间上下文模型和上下文先验模型更新时空上下文模型:
首先,将公式(5)代入公式(6)、公式(7)及公式(10),得到:
其中,hsc(x-z)为空间上下文模型,即每一帧图像要计算并学习的对象。
根据卷积
公式(11)可变化为:
根据卷积定理,有:
则:
其中,
假定第t帧时,已知目标中心位置
其中,
一般的,在存在多个外观相似的跟踪目标的情境下,当发生遮挡状况时,即目标的外观模型已经发生了较大变化,而此时时空上下文模型仍按照同等的速率学习并更新,便会不断学习到错误模型进而最终丢失跟踪目标。本实施例根据运动目标的遮挡情况动态确定学习速率,学习速率ρ为自动更新的动态值,能够有效防止更新过快而完全丢失历史模型信息。具体来说,当跟踪目标被其他物体遮挡时,目标外观模型会受到改变,进而空间上下文模型可信度降低,需要降低学习速率,以防学习到错误的模型,确保跟踪准确。本实施例中,根据运动目标的遮挡率计算时空上下文模型的学习速率更新上述得到的运动目标的时空上下文模型。具体根据公式(3)计算时空上下文模型的学习速率,在此不予赘述。
4)、获取运动目标的图像特征值,更新运动目标的上下文先验模型。
具体的,通过以下公式计算得到运动目标的图像特征值:
i(x)=w1·ir(x)+w2·ig(x)+w3·ib(x);公式(17)
其中,ir(x)为x处在红色通道上的颜色强度;ig(x)为x处在绿色通道上的颜色强度;ib(x)为x处在蓝色通道上的颜色强度;w1、w2、w3为权值且w1+w2+w3=1。在一个实施例中,两队队服颜色在r通道差异较为明显,将ir(x)赋予较大的权值,w1=0.4,w2=0.3,w3=0.3。
5)、对更新后的时空上下文模型和上下文先验模型进行卷积运算,得到下一帧运动目标的跟踪位置。
具体地,在第t+1帧时,已知其时空上下文模型为更新过后的
则有,当第t+1帧的置信图mt+鯐(x)取最大值时,所对应的x值即认为是第t+1帧中运动目标的中心位置
6)、建立球场俯视二维模型,将第一视角下的视频中下一帧运动目标的跟踪位置投影至球场俯视二维模型中的第一投影坐标,将第二视角下的视频中下一帧运动目标的跟踪位置投影至球场俯视二维模型中的第二投影坐标。
具体地,本实施例中,选取足球比赛场地半场的四个角点作为计算平面单应变换矩阵的四个参考点。首先,通过一系列数字图像处理中的阈值处理技术与霍夫变换直线检测,提取球场边线区域;再将分散的线段进行合并,得到球场边线直线方程并且得到四组标定点坐标,最后,根据四组标定点坐标得到两个视角的转换矩阵,具体球场俯视二维模型如图6所示。
7)、检测第一投影坐标和第二投影坐标是否错误。
具体地,分别将第一视角下的视频中的当前帧球员的遮挡率和第二视角下的视频中的当前帧球员的遮挡率与预设遮挡率阈值进行比较,判断第一投影坐标和第二投影坐标是否错误。如果第一视角下的视频中的当前帧球员的遮挡率大于预设遮挡率阈值,则第一投影坐标错误;如果第二视角下的视频中的当前帧球员的遮挡率大于预设遮挡率阈值,则第二投影坐标错误。如果第一视角下的视频中的当前帧球员的遮挡率和第二视角下的视频中的当前帧球员的遮挡率均小于或等于预设遮挡率阈值,那么第一投影坐标和第二投影坐标都是正确的。本实施例中,预设遮挡率阈值根据球员在球场俯视二维模型中距离摄像机的距离计算得到,其中,球员在球场俯视二维模型中距离摄像机的距离为:
其中,[x,y]为当前帧球员在球场俯视二维模型上的坐标,height,width分别为球场俯视二维模型高度和宽度。
则,预设遮挡率阈值为:
threshold=γe-μ·δd;公式(20)
其中,threshold为预设遮挡率阈值;γ和μ皆为常参数,γ用于调整预设遮挡率阈值变化范围,μ用于调整预设遮挡率阈值变化快慢。
8)、当第一投影坐标或第二投影坐标错误时,选取另一视角的投影坐标作为球员的目标投影坐标。
具体地,第一视角下的视频和第二视角下的视频的拍摄角度不同,在第一视角下拍摄得到的视频中球员发生遮挡,但此时,第二视角下拍摄的视频中球员不会发生遮挡,因此,第一投影坐标和第二投影坐标不会同时发生错误。故,当第一投影坐标错误时,选取第二投影坐标作为球员的目标投影坐标,第t帧跟踪结束。当第二投影坐标错误时,选取第一投影坐标作为球员的目标投影坐标,第t帧跟踪结束。
进一步的,在一个实施例中,当某一视角下的跟踪结果有误时,还通过另一视角下的跟踪结果对错误的跟踪结果进行修正,以确保后续跟踪结果准确。假定第一投影坐标错误,在第一视角下,发生跟踪漂移的被追踪球员由置信图给出的最大似然位置为p1,将第一视角视频向球场俯视二维模型转换的投影矩阵为h1,此时第二视角下,被追踪球员的最大似然位置为p2,将第二视角视频向球场俯视二维模型转换的投影矩阵为h2,则p2在球场俯视二维模型上的第二投影坐标为h2·p2,由于p2为正确跟踪的结果,于是将错误跟踪位置p1更新为正确的跟踪位置在第一视角下的第一投影坐标为:
p1=h1-1·h2·p2;公式(21)
同理,如果第二投影坐标错误,则根据第一投影坐标对第二投影坐标进行修正,具体修正原理与上述第一投影坐标的修正原理相同,不再赘述。完成第一投影坐标或第二投影坐标的修正后,再进一步根据修正后的跟踪结果更新对应视角下的时空上下文模型,确保后续跟踪结果准确。
9)、当第一投影坐标和第二投影坐标都正确时,根据第一投影坐标和第二投影坐标计算球员的目标投影坐标。
当第一投影坐标和第二投影坐标都正确时,通过第一投影坐标和第二投影坐标互相辅助调整确定球员的目标投影坐标,确定目标投影坐标后第t帧跟踪结束。具体地,在经过投影变换后的图像中,在离摄像机较近的地方,球员所处的位置较为清晰,而在离摄像机较远的位置,球员因为发生形变拉伸,所处的具体位置较为模糊。因此,当目标离某一视角下的摄像机越近时,认为在该摄像机所拍摄视频中的跟踪结果更为可靠,即由该视角所得的跟踪结果,在最终确定目标位置时,所占权重越大,故根据目标距离摄像机的距离确定第一投影坐标和第二投影坐标的权重值。
假定在第一视角下,摄影机处于如图6所示位置。定义第一视角下的摄影的位置为原点,乙队队员球员m在球场俯视二维模型上的坐标为posmodel1=[x1y1],则有:
如图6所示,第二视角下的摄像机位于第一视角下的摄像机的对面,第二视角下摄影机所得的对球员m的跟踪结果转换到球场俯视二维模型上的坐标为posmodel2=[x2y2],则球员m距离第二视角下的摄影机的距离为:
其中,width和height分别为球场俯视二维模型的宽度和高度。
则,融合第一投影坐标和第二投影坐标后,球员m在球场二维模型上的最终位置为:posfinal=[xy],
进一步的,在一个实施例中,依据上述步骤(1)至步骤(10),对两个视角下的足球视频进行追踪,追踪操作在pc计算机上实现,硬件环境:中央处理器:intelcorei5、主频为2.5ghz、内存为8gb。编程环境为matlab2014a。两个视角下的原视频为avi格式,每帧图片大小为1696x1080,视频大小约20mb,两个视频长度均约18秒,每秒取30帧,共计约540帧,本实施例中,跟踪速率达到1s/帧,跟踪准确率达到100%。
请参阅图7,一种视频中运动目标的跟踪装置700,包括:
遮挡率计算模块702,用于计算第一视角下的视频中的当前帧的运动目标的遮挡率。
时空上下文模型更新模块704,用于根据运动目标的遮挡率计算时空上下文模型的学习速率,并根据学习速率更新运动目标的时空上下文模型。
上下文先验模型更新模块706,用于获取当前帧中的运动目标的图像特征值,根据图像特征值更新运动目标的上下文先验模型。
跟踪模块708,用于对更新后的时空上下文模型和上下文先验模型进行卷积运算,得到第一视角下的视频中的下一帧的运动目标的跟踪位置。
如图8所示,在一个实施例中,时空上下文模型更新模块704包括:
交点检测子模块7042,用于检测当前帧的不同的运动目标的跟踪框之间是否包括交点。
遮挡面积计算子模块7044,用于当不同的运动目标的跟踪框之间包括交点时,计算不同的运动目标的跟踪框之间重叠部分的长度和宽度,并根据长度和宽度计算运动目标发生遮挡的遮挡面积。
遮挡率计算子模块7046,用于获取预先存储的运动目标的跟踪框面积,计算运动目标的遮挡率为遮挡面积与跟踪框面积的比值。
在其中一个实施例中,学习速率计算模块702采用以下公式计算学习速率:
其中:e为自然对数;δs为运动目标的遮挡率;k、
如图9所示,在一个实施例中,上下文先验模型更新模块706包括:
颜色强度获取子模块7062:用于获取当前帧中的运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度以及在蓝色通道上的颜色强度。
颜色强度权重值选取子模块7064,用于为运动目标在红色通道上的颜色强度、在绿色通道上的颜色强度,及在蓝色通道上的颜色强度赋予相应的颜色强度权重值。
图像特征值计算模块7066,用于对在每个通道上的颜色强度进行加权求和,得到当前帧中的运动目标的图像特征值。
如图10所示,在一个实施例中,视频中运动目标的跟踪装置700还包括:
二维模型投影模块710,用于提取追踪场地边线区域,建立追踪场地俯视二维模型,将跟踪位置投影至追踪场地俯视二维模型中的第一投影坐标。
在一个实施例中,视频中运动目标的跟踪装置700用于获取第二视角下的视频,并计算在第二视角下的视频中与下一帧对应的视频帧的运动目标的跟踪位置在追踪场地俯视二维模型中的第二投影坐标。如图10所示,视频中运动目标的跟踪装置700还包括:
遮挡率比较模块712,用于分别将第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率与预设遮挡率阈值进行比较。
第一目标投影坐标选取模块714,用于当第一视角下的视频中的当前帧运动目标的遮挡率和第二视角下的视频中的当前帧运动目标的遮挡率均小于或等于预设遮挡率阈值时,根据第一投影坐标和第二投影坐标计算运动目标在追踪场地俯视二维模型中的目标投影坐标。
第二目标投影坐标选取模块716,用于当第一视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第二投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标;当第二视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,选取第一投影坐标作为运动目标在追踪场地俯视二维模型中的目标投影坐标。
如图10所示,在一个实施例中,视频中运动目标的跟踪装置700还包括:
投影坐标修正模块718,用于当第一视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,根据第二投影坐标对第一投影坐标进行修正;以及,当第二视角下的视频中的当前帧运动目标的遮挡率大于预设遮挡率阈值时,根据第一投影坐标对第二投影坐标进行修正。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!