基于最小匹配距离与随机采样一致性的错误匹配去除方法与流程
本发明涉及数字图像处理领域及计算机视觉领域,具体涉及一种基于最小匹配距离与随机采样一致性的错误匹配去除方法
背景技术:
特征点匹配是数字图像处理和计算机视觉领域中一个基本但却很重要的问题。有着十分广泛的应用,如图像配准与拼接、物体识别、运动目标的检测与跟踪和视觉同步定位与地图构建等。然而在图像的获取和特征提取阶段,由于各种原因不可避免的会产生一定程度的噪声。这使得一些原本准确的特征点之间的关系变得难以确定,进而在特征匹配时产生一些错误的匹配对。这些错误的匹配不仅会影响图像间运动关系的计算,使后续的操作得不到理想的效果,甚至可能导致整个视觉系统的崩溃。所以在特征点匹配阶段,如何有效消除错误的匹配是一个值得考虑的问题。
目前对于错误匹配的去除方法主要有两种,一种简单的做法就是统计出所有匹配对的匹配距离,计算出所有匹配距离中的最小匹配距离,然后将匹配距离大于最小匹配距离一定倍数的匹配对去除,这种方法的优点在于简单高效,缺点在于如果倍数设置的过大,则将漏掉一些错误匹配,如果倍数设置的过小,虽然可以去除绝大多数错误匹配,但也可能将一些正确的匹配对去除,结果导致筛选出的特征点太少而无法满足后续处理的要求。另外一种广泛使用的去除错误特征匹配的方法为随机采样一致性算法,该算法是对于包含噪声的数据样本进行去噪的算法,它通过不断的迭代过程来计算嘈杂数据中所包含的模型并选取符合模型的样本。这种方法的优点在于其计算的模型和筛选出的数据样本较为准确,但算法执行的时间复杂度与原始数据集中样本数量成正相关性,因而对于样本数量较大、初始噪声较多的场合,随机采样一致性算法无法满足实时性的要求。
综上所述,目前对于特征匹配这一环节中的错误匹配问题,现有的去除错误匹配方法无法同时兼顾准确性与实时性,而将最小匹配距离方法与随机抽样一致性算法相融合可以有效的解决这一问题。
技术实现要素:
针对当前去除特征匹配中的错误匹配算法无法同时兼顾准确性与实时性的问题,本发明对去除错误匹配的方法进行了改进,提供了一种基于最小匹配距离与随机采样一致性的错误匹配去除方法。对相邻两帧图像分别提取特征点,通过匹配算法对特征点进行特征匹配得到匹配数据集合。首先使用最小匹配距离法先去除掉一些较为明显的错误匹配,这样可以在一定程度上减少随机抽样一致性算法在迭代过程中所要计算的数据量,从而加快算法的收敛速度,快速求出可信赖的描述模型以及其对用的局内点。
实验表明,这种算法可以利用最小匹配距离方法所具有的简单高效的特点,有效地避免了后续随机抽样一致性算法对一些无效的错误匹配点进行反复迭代计算,在保证准确性的同时有效的提高了整个去除错误匹配过程实时性,由于该方法兼顾了实时性和准确性,所以其应用的场合更加普遍,这使得基于最小匹配距离与随机采样一致性去除错误匹配方法具有明显的优势。
本发明的技术方案是这样实现的:首先计算出所有匹配对之间的匹配距离,去除匹配距离大于最小匹配距离一定倍数的匹配对,并将保留下来的匹配对作为随机采样一致性算法的初始匹配数据集合,不断地重复随机取点、评估模型和统计局内点的过程,迭代一定次数后,将取得局内点最多的那次迭代所计算的函数模型作匹配数据集合可信赖的描述模型,符合模型的点作为筛选后的局内点。
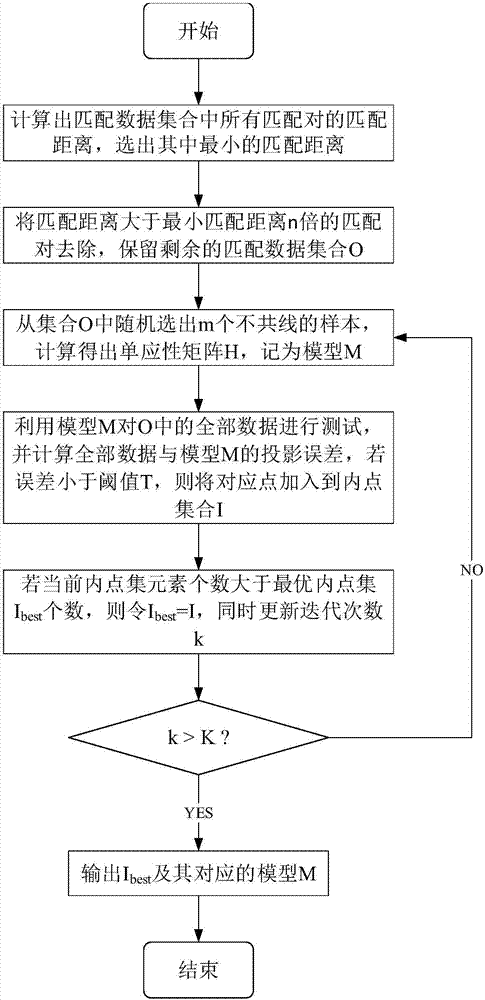
基于最小匹配距离与随机采样一致性的错误匹配去除方法,包含如下步骤:
步骤一:计算出所有匹配对的匹配距离,选出其中最小的匹配距离;
通常,特征之间的相似性通过计算对应特征描述子之间的距离来度量,而特征之间的相似程度越高,对应的特征描述子之间的匹配就越小。常使用的匹配距离计算方法有欧氏距离(euclideandistance)和汉明距离(hammingdistance)。sift特征描述子和surf特征描述子之间的匹配距离往往通过欧氏距离来表示。对于orb特征,由于其特征描述符为一个固定长度的字符串,因此使用汉明距离来表示对应特征间的匹配距离更加方便。假设从相邻两帧图像得到了各自的图像特征点集合x和y:
x={xi|i=1,2,......,n}(1)
y={yi|i=1,2,......,n}(2)
那么两个特征点的xi和yi的欧氏距离dij可由式(3)表示:
式中
步骤二:将匹配距离大于最小匹配距离n倍的匹配对去除,保留剩余的匹配数据集合;
倍数的设置需要根据实际的需求来确定,如果倍数设置的过大,则将漏掉一些错误匹配,如果倍数设置的过小,虽然可以去除绝大多数错误匹配,但也可能将一些正确的匹配对去除,结果导致筛选出的特征点太少而无法满足后续处理的要求。本发明中,不宜将倍数设置过小,这里取n=6。在这一步骤中只需去除一些较为明显的错误匹配即可,这样不仅可以降低匹配数据集合的数据量,同时可以提高匹配数据集合中正确匹配点的比例。在减少计算量的同时,准确性可以得到明显的提高。
步骤三:从上一步的匹配集合中随机选出m个不共线样本,计算得出单应性矩阵h,记为模型m;
m的值应为可以确定模型参数的最小值,假设x和x′为从相邻两帧图像中随机选出的特征点集合。那么单应性矩阵的h可以通过如下公式来计算:
x′=hx(4)
将计算求得的单应性矩阵记为模型m。
步骤四:计算其余所有匹配点到m的距离,将距离小于阈值的匹配点存入内点集合i中;
将步骤三得出模型m视为此时的估计模型,利用模型m对匹配数据集合中的其余点进行测试,并计算其余全部数据与这个模型的投影误差ε。
如果某一特征点对应的投影误差小于事先给定的阈值t,就将该点对应的加入到此模型对应的内点集i中。
步骤五:若当前i中的元素数量大于最优内点集合ibest中元素的数量,就令ibest=i,并且对迭代次数k进行更新;
统计每个模型对应的内点集合中内点的个数,将内点数最多的内点集合i作为最优内点集合,而此最优内点集合对应的模型作为最优模型。最优模型意味着有最小的代价函数。代价函数定义为:
其中hij为h矩阵第i行第j列对应的元素。
步骤六:若迭代次数大于k,则退出;若迭代次数小于等于k,则将迭代次数加上1之后返回步骤三;对k进行更新的公式为:
其中,p表示置信度,通常为0.995,w表示内点所占百分比,m表示计算模型时需要的最小样本数目。
步骤七:输出最大内点数对应的模型参数以及此时的内点集,该集合即视为匹配正确的特征点对。
本发明方法充分考虑了错误数据样本对随机采样一致性算法去除错误匹配过程中的速度与准确性的影响,通过使用最小匹配距离方法对匹配数据集合进行预处理,有效提高去除错误匹配过程的准确性与实时性,可以为后续的处理流程提供可靠的特征匹配点,对于一些对实时性要求较高的场合,基于最小匹配距离与随机采样一致性的错误匹配去除方法要明显优于传统的错误匹配去除方法。
附图说明
图1本发明具体实施方式的方法流程图;
图2本发明具体实施方式的原始匹配数据集合;
图3本发明具体实施方式的最小匹配距离方法去除错误匹配效果(n较小);
图4本发明具体实施方式的最小匹配距离方法去除错误匹配效果(n较大);
图5本发明具体实施方式的随机采样一致性算法去除错误匹配效果;
图6本发明具体实施方式的基于最小匹配距离与随机采样一致性去除错误匹配方法去除错误匹配效果(最终效果);
具体实施方式
下面结合附图对本发明的具体实施作详细说明。
本实施方式的方法,软件环境为windows7系统,仿真环境为microsoftvisualstudio2012,流程如图1所示:
步骤一:计算出所有匹配对的匹配距离,选出其中最小的匹配距离;
其中原始摄像头的型号是kinectv1,获取到的彩色图像的分辨率为640*480,提取的特征为orb特征,匹配方式为bruteforce算法,由此获得的原始匹配数据集如图2所示。
从图2的原始匹配数据效果图中可以发现,除了一些正确的匹配对(由平行直线连接的匹配对),还存在许多错误的匹配对(由交叉直线连接的匹配对)。图2中匹配对的数目为500,计算出的所有匹配对之间的最小汉明距离为9。
步骤二:将匹配距离大于最小匹配距离倍的匹配对去除,保留剩余的匹配数据集合;
首先选择一个相对较小的倍数,使n=2,则通过最小距离匹配去除错误匹配后的结果如图3所示。从图3可以看出,虽然去除了错误匹配,但同时也去除掉了一部分正确的匹配,处理后剩余的匹配数目为16,可以看出保留的特征点的数量明显不足。
随后选择一个相对较大的倍数,使n=6,则通过最小具体匹配去除错误匹配后的结果如图4所示。从图4可以看出,较之图2已经去除了一大部分错误匹配,但是结果仍保留少许错误匹配(交叉的之线),此时剩余的匹配数目为272。
步骤三:从上一步的匹配集合中随机选出m个不共线样本,计算得出单应性矩阵h,记为模型m;
从步骤二n=6情况下筛选出的匹配对中随机抽取m=4个匹配对,由公式(4)计算出单应性矩阵h,h为一个3×3的矩阵,如下:
将此变换矩阵记为模型m。
步骤四:计算其余所有匹配点到m的距离,将距离小于阈值的匹配点存入内点集合i中;
计算n=6情况下所有筛选出的特征点到m的距离。如若某一点到m的距离小于阈t=8.0,则将该点加入到内点集i中。
步骤五:如若当前i中的元素数量大于最优内点集合ibest中元素的数量,就令ibest=i,并且对迭代次数k进行更新;
步骤六:如迭代次数大于k,则退出;否则,迭代次数要加上1,之后返回步骤三;
步骤七:输出最大内点数对应的模型参数,以及此时的内点集,该集合即视为匹配正确的特征点对。
图5所示为单一使用随机采样一直算法筛选出的内点集合,此时筛选出的匹配数目为166,图6为本发明算法处理得到的内点集合此时筛选出的匹配数目为216,本发明算法保留了更多的正确匹配对,同时耗费的时间更少。
综上,基于最小匹配距离与随机采样一致性的错误匹配去除方法实现了高效的去除错误匹配过程。该方法在保证实时性和准确性的同时,有效避免了特征点较少以及错误匹配无法去除干净的情况,对于数据量较大视觉系统中,本发明具有明显的优势。
- 还没有人留言评论。精彩留言会获得点赞!